


1. 背景
客户端缓存是应用自身把需要缓存的数据直接放在内存中, 查询时如果数据已经在内存了则不需要额外查询数据库,直接返回即可。使用客户端缓存不但提供了更佳的客户端性能,也减少了后端服务和数据库的压力,提高系统的整体性能、减低资源成本,也达到了保护后端服务和数据库服务的效果,提高了系统的稳定性。
但正如硬币也有两面, 客户端缓存也会带来的一些问题是,这些问题如果处理不当, 可能导致包括用户体验不佳甚至灾难性的后果。 其中一个最严重的问题是客户端缓存的数据不正确, 数据已经过期或失效了。 触发的场景在分布式应用的服务上尤为容易触发, 可能数据在调用另一个服务的时候,发生了数据变更,这时其他应用服务的旧数据已经失效了,这时客户端如果查到旧数据,可能会出现不可预知的结果。 针对这个场景,一种解决方法是客户端不缓存数据,把数据都放到redis上,这时客户端更新缓存的时候,都是往redis上更新,其他客户端也是从redis上查数据,这样既可以利用REDIS的高性能,也能保证数据的一致性。 这个是通常的redis作为缓存使用的场景。
但REDIS也存在一种缓存数据放在redis的方案。
2. 数据放在REDIS的缓存方案
常见的REDIS缓存的使用场景如下 ,客户端的缓存放到了redis上面,通过redis去更新和查询缓存数据。 这种方式的好处是在分布式场景,程序编写容易, 整体架构比较简单清晰。
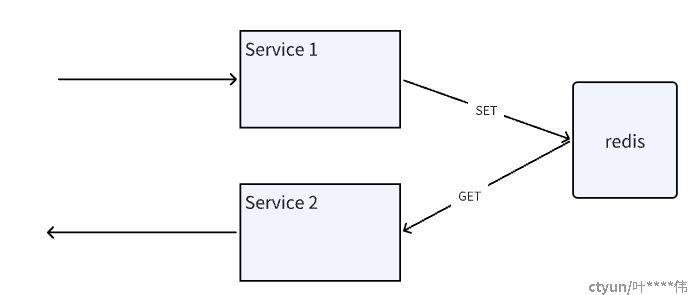
优点:
1. 程序编写容易, 整体架构比较简单清晰
2. 有成熟的生态方案,容易与包括spring等成熟的框架结合使用。
缺点:
1. 性能不是最佳, 中间涉及一层redis的查询。
2. 缓存的压力变大了,一旦redis对接的业务量较大的时候,redis本身就会成为瓶颈
3. 数据放在应用侧和REDIS的缓存方案
这套方案在基于上述方案的基础上,增加redis 缓存数据失效通知 ,让应用侧也可以放心的进行数据缓存,进一步提升性能。
示例图如下:
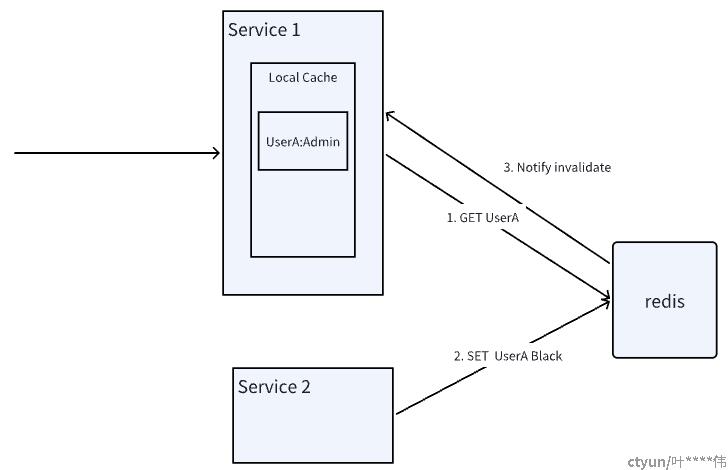
方案的原理:
1. redis客户端先发送client tracking的命令,开启客户端缓存功能。 后续应用普通的从redis上查数据, 并保存在应用内存上。
2. 其他服务去更新缓存的KEY时, redis通过订阅通知的机制,告诉保存缓存的应用服务数据失效了。
3. 这时应用只要把失效的数据从内存上清理就好了。
优点:
1. 性能更佳,应用可以直接返回缓存在本机的数据。
2. 减少redis的命令请求,保护的redis的运行。
缺点:
1. 只有redis 6.0和以后的版本才提供, 也要升级对应的客户端版本
2. 使用了redis的订阅/通知机制,增加了编程难度和系统的复杂性等
3. 不成熟,没有对应的框架和大规模的使用经验。
4. 使用例子
下面是简单描述下具体要怎么操作REDIS: 核心是依赖SUBSCRIBE __redis__:invalidate 订阅失效的key消息, 执行client tracking命令开启KEY的追踪。
4.1 普通模式
1. client 1: 查询当前的连接ID, 并订阅 SUBSCRIBE __redis__:invalidate
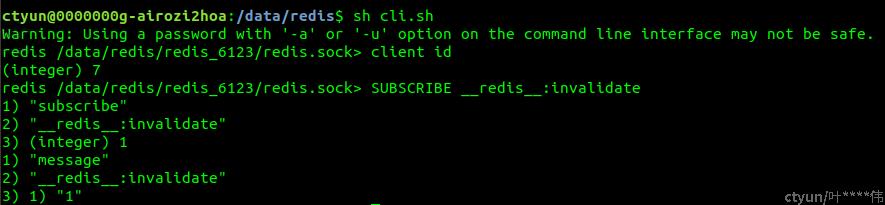
2. client 2 : 开启CLIENT TRACKING, 并把输出的结果转到CLIENT 1(client id等于7),并查询一个key

3. client 3: 修改上面缓存的key

4. client 1: 这时可以看到推送了失效的KEY
注意,redis也有容量限制,不能无限记录所有的key,这时有些旧的key会被驱逐,这些key即使没有被修改,也会通知客户端失效了。
4.2 广播模式
redis的客户端缓存,还有一种Broardcasting模式. 这种模式,并没有KEY数量的限制,但需要指定KEY的前缀。每次如果有匹配的KEY修改了,也会触发订阅通知。这种模式下,即使客户端没有进行任何查询,如果符合条件的KEY修改了也会触发通知。其次 如果注册了大量匹配规则的追候 ,会很消耗redis的CPU性能,导致REDIS的性能下降。 例子如下:
1. Client 1: 查询当前的连接ID, 并订阅 SUBSCRIBE __redis__:invalidate
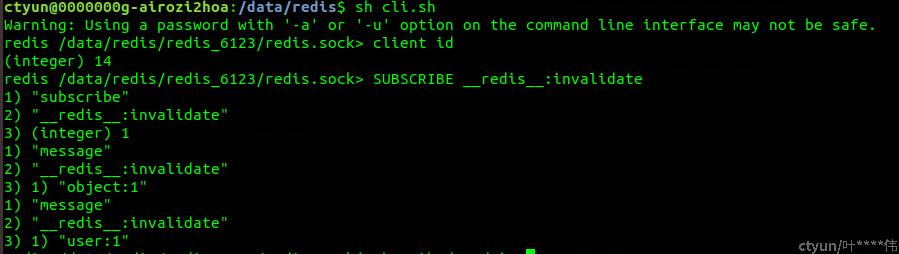
2. Client 2: 开启CLIENT TRACKING, 注册key的prefix , 并把输出的结果转到CLIENT 1(client id等于14)

3. Client 3: 进行key的更新

4. Client 1: 可以看到有发送推送KEY失效的消息,即使Client 2实际没有查询这些key
5. 总结
redis在6.0版本后提供了一种新的客户端缓存技术。 这个技术可以在某些层面缓解了原有方案的性能问题。 但也带来了一些开发的复杂度和限制。
在实际使用的时候,需要进行取舍和实际验证。
