


一、概念
pcc是mlnx cx6-dx网卡开始引入的拥塞控制框架,承载自研拥塞控制算法,当前cx7版本mlnx卡都已经支持pcc框架。
二、需求背景
rdma网络大规模使用dcqcn拥塞控制,会引入大流饿死小流导致时延非常大的问题,甚至是pfc死锁问题。部署网络使用mlnx网卡+自研卡,或者全部是mlnx卡时为解决上述问题,考虑使用pcc拥塞控制框架,开发自研拥塞控制算法。
三、通信流程
mlnx cx4和mlnx cx5网卡使用标准roce的通信流程。使能pcc框架的mlnx网卡的roce通信流程有所变更,多出rtt req和rtt rsp两种类型报文。rtt req和rtt rsp走信令通道,发生拥塞仍然打cnp报文。收到rtt req后,立即回复rtt rsp报文,收到rtt rsp报文立即发送下一个rtt req报文(mlx推荐做法,自研卡此处可自行设计),始终保持网络rtt探测。
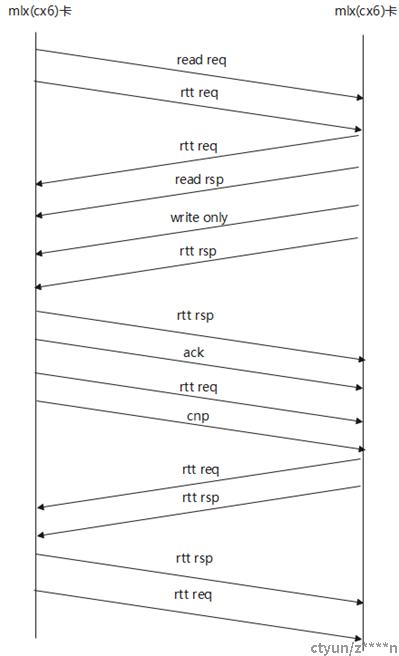
其中rtt req, rtt rsp报文必须与负载payload使用相同的队列收发。确保能够准确的测量出网络当前的rtt。如果pcc框架使用交换机ecn打标信息,判断网络是否发生拥塞。ecn的低水线可以设置低些,保持网络对拥塞的敏感,高水线不影响带宽即可。
四、pcc框架解析
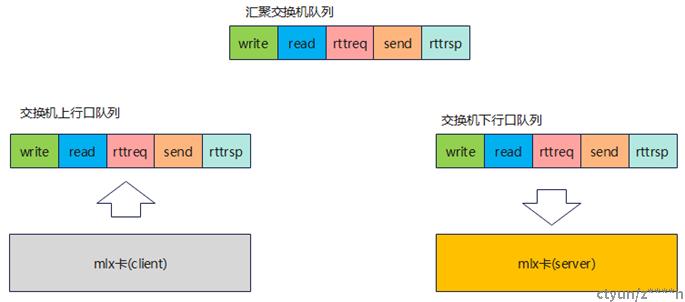
为支持pcc框架,对协议层进行扩展,增加rtt req和rtt rsp报文发送,增加pacing控制(精确控制发包速度)。其中rtt req报文的发送由pcc框架进行控制。协议层向pcc框架传递拥塞信息,作为拥塞控制算法输入。pcc框架向协议层输出rate(当输出的rate为0使,协议层按照默认速度发送),和是否发送rtt req等的控制信息。
cx7版本mlnx卡的pcc框架运行在DPA(可编程数据路径加速器,RiscV的数据面加速引擎)上。
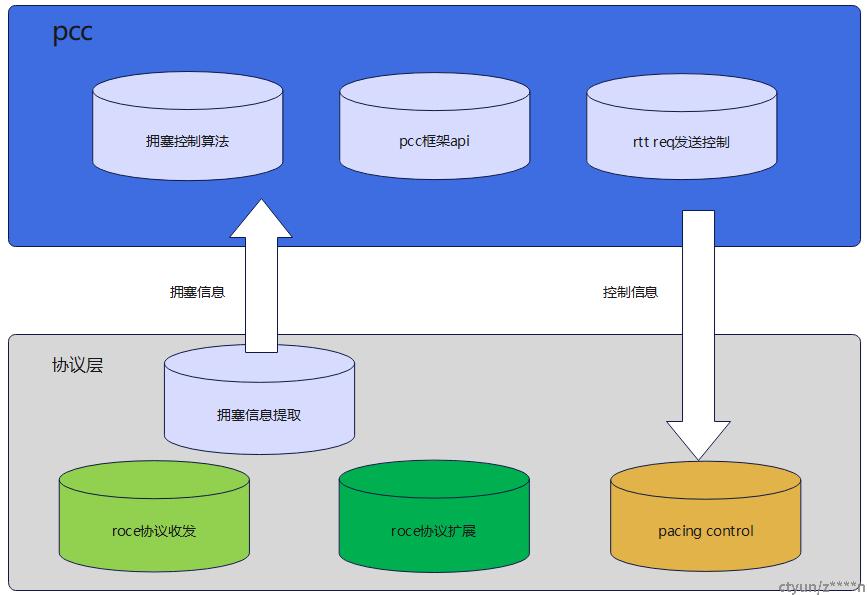
协议层调用pcc框架采用事件驱动的方式。当前包括init,nack,timeout,cnp,rtt,tx,ack等事件。不同事件对应的时刻:init事件对应modify_qp_to_rtr时刻;单次完成roce数据报文发送之后,触发tx事件;收到cnp报文,触发cnp事件;收到rtt rsp报文,触发rtt事件;收到nack报文,触发nack事件。发生超时重传,触发timeout事件;收到响应报文,比如ack, read rsp,触发ack事件。
五、pcc框架模式
pcc框架具备per-qp和per-dstip两种模式。其中per-qp模式下,每个qp单独接收拥塞信息,单独运行拥塞控制算法,单独控制速度。qp与qp之前的拥塞控制完全隔离,但是会有大量的rtt req和rtt rsp报文产生。
per-dstip模式下,理解成只有一个pcc框架,相同dstip下所有qp收到的拥塞信息全部输入这个pcc框架,pcc框架内执行拥塞控制算法返回速率,相同dstip下所有qp都使用这个速率控制速度。与per-qp模式不同的是,per-qp模式下每个qp都要维护一套rtt req,rtt rsp报文的收发,per-dstip模式下,相同dstip下所有qp共用一份rtt req,rtt rsp报文返回的信息。


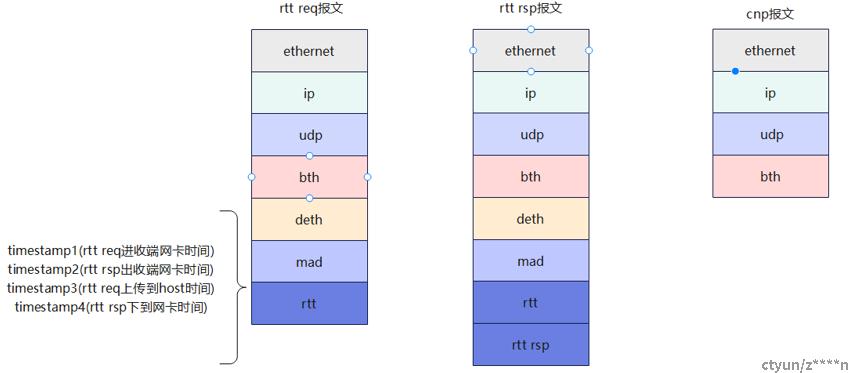
六、报文格式
rtt req和rtt rsp走信令通道。mad头由信令通道(这个程序模块在host侧)处理。rtt req和rtt rsp信息写在rtt头和rtt rsp头中。mad头中有id标识是rtt req报文或者是rtt rsp报文。rtt头携带如图4个时间戳,可计算网络中rtt,也可计算总rtt(pcc框架中调用api返回对应的rtt值)。
七、pcc框架代码
流程运行过程中,pcc框架会调用doca_pcc_dev_user_algo接口,传入算法id(运行过程中选择哪个算法id,有工具可配置)选择对应的算法。因此在pcc框架上开发算子,需要实现类似rtt_template_algo这样的接口插入到doca_pcc_dev_user_algo函数中。
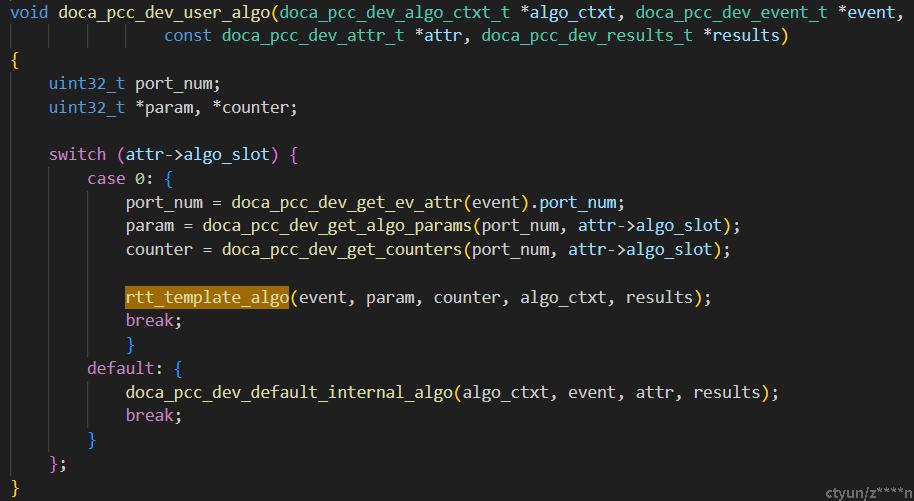
rtt_template_algo函数内再根据事件类型,选择对应的处理函数。当前只是一个模版,事件并没有列全,实际开发中要根据算法设计,实现一个类似的函数,函数内部列出需要处理的事件,并实现事件的处理函数。最终协议层会根据results->rate填的数值进行控速,根据results->req的值决定是否发送rtt req。

