


一、现象
在生产环境遇到如下现象:
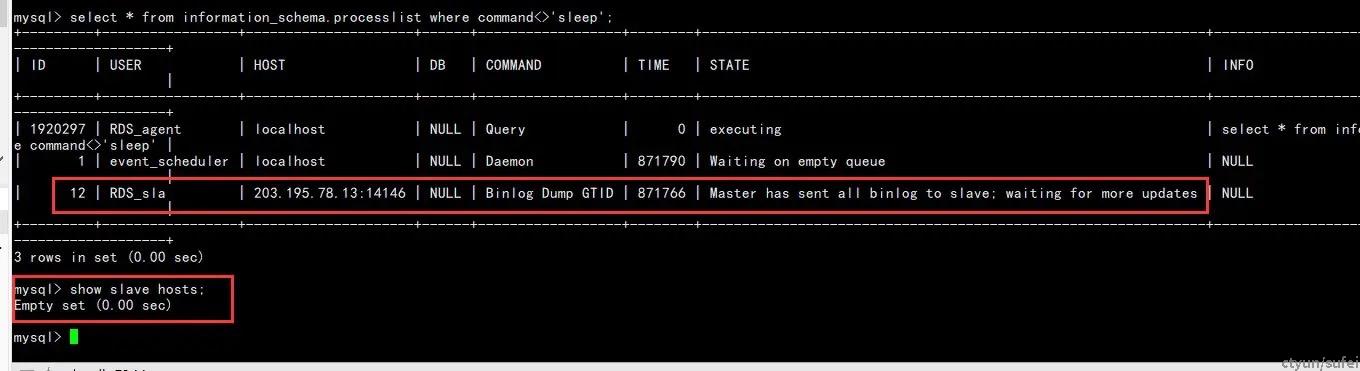
即矛盾的结果:
- 主库的MySQL processlist明明可以看到dump线程,说明有从库在进行dump逻辑;
- show slave hosts为空,即无法从主库查到从库状态;
二、原因分析
根据现象,合理地猜测,存在用户执行了dump_gtid逻辑,也就是复制binlog逻辑,但是该线程不在slave_list列表中。我们知道当一个从库连接到主库执行GTID复制命令时,主要执行以下步骤:
1、执行COM_REGISTER_SLAVE命令,即调用register_slave完成从库注册(也就是插入slave_list列表);
2、执行COM_BINLOG_DUMP_GTID命令,即调用com_binlog_dump_gtid循环发送binlog给从库;
目前现象是,存在dump_gtid命令地执行,但注册列表中没有相关从库信息,存在两种可能:
- 从库没有执行register指令,直接执行dump执行;这个情况可以排除,一般只有在自己模拟从库的程序中才会如此忽略,官方从库逻辑都是先进行register,再进行dump;
- 从库进行了register,但是在某些情况被unregister了,但是dump线程没有被kill。查看unregister情况有如下几种:
1、从库register注册过程中通过server_id查找(即在register_slave函数中),把相同地server_id的旧实例unregister移除;这种情况是避免相同从库在主库存在两个复制线程;
mysql_mutex_lock(&LOCK_slave_list);
unregister_slave(thd, false, false/*need_lock_slave_list=false*/);
res= my_hash_insert(&slave_list, (uchar*) si);
mysql_mutex_unlock(&LOCK_slave_list);
// unregister_slave函数具体如下,其通过server_id进行从库是否相同判断
void unregister_slave(THD* thd, bool only_mine, bool need_lock_slave_list)
{
if (thd->server_id && my_hash_inited(&slave_list))
{
if (need_lock_slave_list)
mysql_mutex_lock(&LOCK_slave_list);
else
mysql_mutex_assert_owner(&LOCK_slave_list);
SLAVE_INFO* old_si;
if ((old_si = (SLAVE_INFO*)my_hash_search(&slave_list,
(uchar*)&thd->server_id, 4)) &&
(!only_mine || old_si->thd == thd))
my_hash_delete(&slave_list, (uchar*)old_si);
if (need_lock_slave_list)
mysql_mutex_unlock(&LOCK_slave_list);
}
}
2、dump_gtid退出发送binlog循环时(即在com_binlog_dump_gtid函数中),这种情况属于复制线程正常推出情况;
mysql_binlog_send(thd, name, (my_off_t) pos, &slave_gtid_executed, flags);
unregister_slave(thd, true, true/*need_lock_slave_list=true*/);
3、THD线程销毁时(即在THD的析构函数中),如果该线程是dump线程,则需要进行unregister,这种情况属于异常推出;
if (rli_slave)
rli_slave->cleanup_after_session();
/*
As slaves can be added in one mysql command like COM_REGISTER_SLAVE
but then need to be removed on error scenarios, we call this method
here.
*/
unregister_slave(this, true, true);
从分析可以看出:后两种情况,最终THD结构都会被销毁,而只有第一种情况,旧slave虽然被unregister,但是其dump线程还存在。哪何时销毁呢?为什么出现了没有销毁的情况呢?
问题1:对于旧slave,何时销毁?
我们可以看到,当新slave在进行dump指令时,会调用kill_zombie_dump_threads(thd);即kill旧的slave线程。
kill_zombie_dump_threads(thd); // kill旧的slave线程
query_logger.general_log_print(thd, thd->get_command(),
"Log: '%s' Pos: %llu GTIDs: '%s'",
name, pos, gtid_string);
my_free(gtid_string);
mysql_binlog_send(thd, name, (my_off_t) pos, &slave_gtid_executed, flags); // 开始发送binlog
unregister_slave(thd, true, true/*need_lock_slave_list=true*/); 问题2:现在的情况,明明调用了kill_zombie_dump_threads,为什么没有销毁呢?
查看kill_zombie_dump_threads函数,如下:
void kill_zombie_dump_threads(THD *thd)
{
String slave_uuid;
get_slave_uuid(thd, &slave_uuid);
if (slave_uuid.length() == 0 && thd->server_id == 0)
return;
Find_zombie_dump_thread find_zombie_dump_thread(slave_uuid);
THD *tmp= Global_THD_manager::get_instance()->
find_thd(&find_zombie_dump_thread);
if (tmp)
{
……
tmp->duplicate_slave_id= true;
tmp->awake(THD::KILL_QUERY);
mysql_mutex_unlock(&tmp->LOCK_thd_data);
}
}
不然看出:在kill dump线程的时候,是通过uuid进行旧slave查找的,这就存在问题了,也就是生产出现的情况,当两个从库server_id相同,所以造成了register覆盖,但是uuid不同,造成旧的slave无法被kill。
三、结论
当两个从库server_id相同,uuid不同时,会造成旧从库无法被删除。修复建议:1、修改源码,使得在两次判断相同从库的逻辑一致;2、生产上,避免server_id相同,uuid不同的实例,同样反之依然,即uuid相同,server_id不同,会造成从库无缘无故被杀。
官方有相关bug报告已久,但并未修复,不知道为何?
