


准备docker环境
下载docker desktop官网直接下载即可:

准备安装包
可以直接官网下载:
以hadoop3.3.6、spark3.4.1、jdk11为例:
hadoop:hadoop-3.3.6-aarch64.tar.gz
spark: spark-3.4.1-bin-hadoop3.tgz
jdk11: java11
准备配置文件
ssh
ssh_config
Host localhost
StrictHostKeyChecking no
Host 0.0.0.0
StrictHostKeyChecking no
Host hadoop-*
StrictHostKeyChecking no
UserKnownHostsFile=/dev/null
LogLevel=quiethadoop
core-site.xml
<configuration>
<!-- 指定 hdfs NameNode 的地址 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop-master:9000</value>
</property>
<!-- 指定hadoop数据目录-->
<property>
<name>hadoop.tmp.dir</name>
<value>file:/data/soft/hadoop-3.3.6/data</value>
</property>
<!-- 配置HDFS网页登录使用的静态用户为summer-->
<property>
<name>hadoop.http.staticuser.user</name>
<value>hadoop</value>
</property>
<!-- 授权 -->
<property>
<name>hadoop.proxyuser.hadoop.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.hadoop.groups</name>
<value>*</value>
</property>
</configuration>hadoop-env.sh
export JAVA_HOME=/data/soft/jdk11
export HADOOP_YARN_HOME=$HADOOP_HOME
export HADOOP_SECURE_PID_DIR=$HADOOP_HOME/pids
export HADOOP_PID_DIR=$HADOOP_HOME/pids
export HDFS_NAMENODE_USER=hadoop
export HDFS_DATANODE_USER=hadoop
export HDFS_SECONDARYNAMENODE_USER=hadoop
export YARN_RESOURCEMANAGER_USER=hadoop
export YARN_NODEMANAGER_USER=hadoophdfs-site.xml
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<!--HDFS的副本数,生产一般设为3-->
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<!--自定义namenode,datanode的dir-->
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/data/soft/hadoop-3.3.6/data/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/data/soft/hadoop-3.3.6/data/dfs/data</value>
</property>
</configuration>mapred-site.xml
<?xml version="1.0"?>
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.application.classpath</name>
<value>$HADOOP_HOME/share/hadoop/mapreduce/*:$HADOOP_HOME/share/hadoop/mapreduce/lib/*</value>
</property>
</configuration>slaves
hadoop-master
hadoop-slave1
hadoop-slave2workers
hadoop-master
hadoop-slave1
hadoop-slave2yarn-site.xml
<?xml version="1.0"?>
<configuration>
<!--设置ResourceManager-->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop-master</value>
</property>
<!--指定mapreduce的shuffle-->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!--配置要继承的环境变量-->
<property>
<name>yarn.nodemanager.env-whitelist</name>
<value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_HOME</value>
</property>
<!--启用日志聚合-->
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<!--日志在HDFS上保存时长,设为24小时-->
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>86400</value>
</property>
</configuration>spark
spark-defaults.conf
spark.master yarn
spark.eventLog.enabled true
spark.eventLog.dir hdfs://hadoop-master:9000/spark-event-log
spark.yarn.jars hdfs://hadoop-master:9000/spark-yarn-jars/*spark-env.sh
HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
YARN_CONF_DIR=$HADOOP_HOME/etc/hadoop
SPARK_LOCAL_DIRS=${SPARK_HOME}/tmp启动脚本
start-hadoop.sh
#!/bin/bash
$HADOOP_HOME/sbin/start-all.shstop-hadoop.sh
#!/bin/bash
$HADOOP_HOME/sbin/stop-all.shinit-spark.sh
#!/bin/bash
echo "init spark"
hdfs dfs -test -d /spark-yarn-jars > /dev/null 2>&1
if [ "1" = "$?" ]; then
echo "mkdir spark-yarn-jars"
hdfs dfs -mkdir /spark-yarn-jars > /dev/null 2>&1
fi
hdfs dfs -test -f /spark-yarn-jars/*.jar > /dev/null 2>&1
if [ "1" = "$?" ]; then
echo "uploading jars ..."
hdfs dfs -put ${SPARK_HOME}/jars/*.jar /spark-yarn-jars > /dev/null 2>&1
fi
制作镜像
准备目录
比如big-data
mkdir ~/big-data在big-data下创建pgk、conf目录,将安装包放到pkg下,配置文件放到conf下
准备Dockerfile
FROM centos:7
LABEL maintainer="allen"
RUN useradd -u 6666 hadoop
ADD pkg/* /home/hadoop
# install openssh-server, openjdk and wget
RUN yum install -y openssh-server
RUN yum install -y openssh-clients
RUN mkdir -p /data/soft
WORKDIR /home/hadoop
# set environment variable
ENV SOFT_HOME=/data/soft
ENV JAVA_HOME=$SOFT_HOME/jdk11
ENV PATH=$PATH:$JAVA_HOME/bin
ENV HADOOP_HOME=$SOFT_HOME/hadoop-3.3.6
ENV PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
ENV HADOOP_YARN_HOME=$HADOOP_HOME
ENV SPARK_HOME=$SOFT_HOME/spark3.4.1
ENV PATH=$PATH:$SPARK_HOME/bin:$HADOOP_HOME/sbin
# ssh without key
RUN mkdir /home/hadoop/.ssh
RUN ssh-keygen -t rsa -f /home/hadoop/.ssh/id_rsa -P '' && \
cat /home/hadoop/.ssh/id_rsa.pub >> /home/hadoop/.ssh/authorized_keys && \
chmod 0600 /home/hadoop/.ssh/authorized_keys
RUN mv /home/hadoop/hadoop-* $HADOOP_HOME && \
mv /home/hadoop/jdk* $JAVA_HOME && \
mv /home/hadoop/spark* $SPARK_HOME
RUN mkdir -p $HADOOP_HOME/data/dfs/name && \
mkdir -p $HADOOP_HOME/data/dfs/data && \
mkdir $HADOOP_HOME/logs && \
mkdir $HADOOP_HOME/tmp
COPY conf/* /tmp/
RUN mv /tmp/ssh_config /home/hadoop/.ssh/config && \
mv /tmp/hadoop-env.sh $HADOOP_HOME/etc/hadoop/hadoop-env.sh && \
mv /tmp/hdfs-site.xml $HADOOP_HOME/etc/hadoop/hdfs-site.xml && \
mv /tmp/core-site.xml $HADOOP_HOME/etc/hadoop/core-site.xml && \
mv /tmp/mapred-site.xml $HADOOP_HOME/etc/hadoop/mapred-site.xml && \
mv /tmp/yarn-site.xml $HADOOP_HOME/etc/hadoop/yarn-site.xml && \
mv /tmp/slaves $HADOOP_HOME/etc/hadoop/slaves && \
mv /tmp/workers $HADOOP_HOME/etc/hadoop/workers && \
mv /tmp/spark-env.sh $SPARK_HOME/conf/spark-env.sh && \
mv /tmp/spark-defaults.conf $SPARK_HOME/conf/spark-defaults.conf && \
mv /tmp/start-hadoop.sh /home/hadoop/start-hadoop.sh && \
mv /tmp/stop-hadoop.sh /home/hadoop/stop-hadoop.sh && \
mv /tmp/init-spark.sh /home/hadoop/init-spark.sh
RUN chmod 0600 /home/hadoop/.ssh/config && \
chmod +x /home/hadoop/start-hadoop.sh && \
chmod +x /home/hadoop/stop-hadoop.sh && \
chmod +x $HADOOP_HOME/sbin/start-dfs.sh && \
chmod +x $HADOOP_HOME/sbin/start-yarn.sh && \
chmod +x /home/hadoop/init-spark.sh
RUN rm -rf $HADOOP_HOME/share/doc
RUN chown -R hadoop:hadoop /home/hadoop
RUN chown -R hadoop:hadoop /data/
RUN chown -R hadoop:hadoop /tmp
# format namenode
RUN $HADOOP_HOME/bin/hdfs namenode -format
CMD [ "sh", "-c", "systemctl start sshd;bash"]准备脚本
build-image.sh
#!/bin/bash
echo -e "\nbuild docker hadoop image\n"
sudo docker build -f Dockerfile -t allen/hadoop:1.0 .PS: 为确保docker有执行systemctl的权限,docker run 需要加--privileged,启动命令设为/usr/sbin/init
若还有Failed to get D-Bus connection: No such file or directory异常:
~/Library/Group\ Containers/group.com.docker/settings.json修改"deprecatedCgroupv1"参数为true
build镜像
sh build-image.sh启动容器
准备脚本
rerun-hadoop-container.sh
#!/bin/bash
# 默认启动3节点
N=${1:-3}
sudo docker network create hadoop > /dev/null
sudo docker rm -f hadoop-master &> /dev/null
echo "start hadoop-master container..."
sudo docker run -d \
--privileged \
-p 9870:9870 \
-p 8088:8088 \
-p 8042:8042 \
--net=hadoop \
--name hadoop-master \
--hostname hadoop-master \
das/hadoop:1.0 /usr/sbin/init > /dev/null
i=1
while [ $i -lt $N ]
do
sudo docker rm -f hadoop-slave$i &> /dev/null
echo "start hadoop-slave$i container..."
sudo docker run -d \
--privileged \
--net=hadoop \
--name hadoop-slave$i \
--hostname hadoop-slave$i \
das/hadoop:1.0 /usr/sbin/init > /dev/null
i=$(( $i + 1 ))
done
启动容器
sh rerun-hadoop-container.sh可以在docker desktop上看到

进入hadoop-master,执行:
su hadoop
sh start-hadoop.sh结果如下:
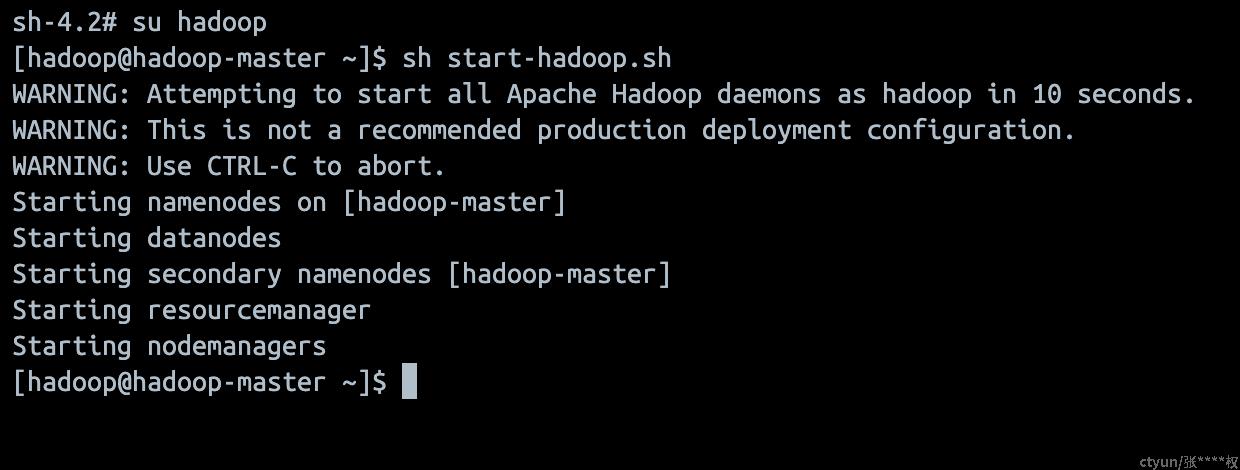
执行:
sh init-spark.sh由于要上传spark的jar到hdfs上,执行需要一段时间,macbook一般也挺快传完的
结果如下:
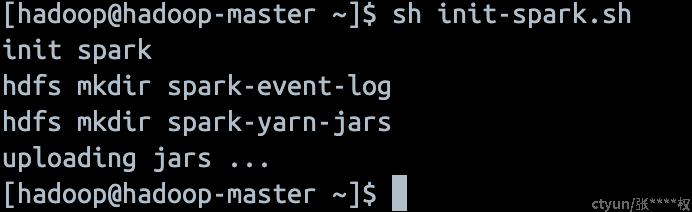
至此,spark on yarn的本地集群就搭建好了,可以跑个example测试一下:
spark-submit --class org.apache.spark.examples.SparkPi \
--master yarn \
--deploy-mode cluster \
--queue default \
$SPARK_HOME/examples/jars/spark-examples*.jar \
10可以在管理页面看到,访问:
127.0.0.1:8088/cluster
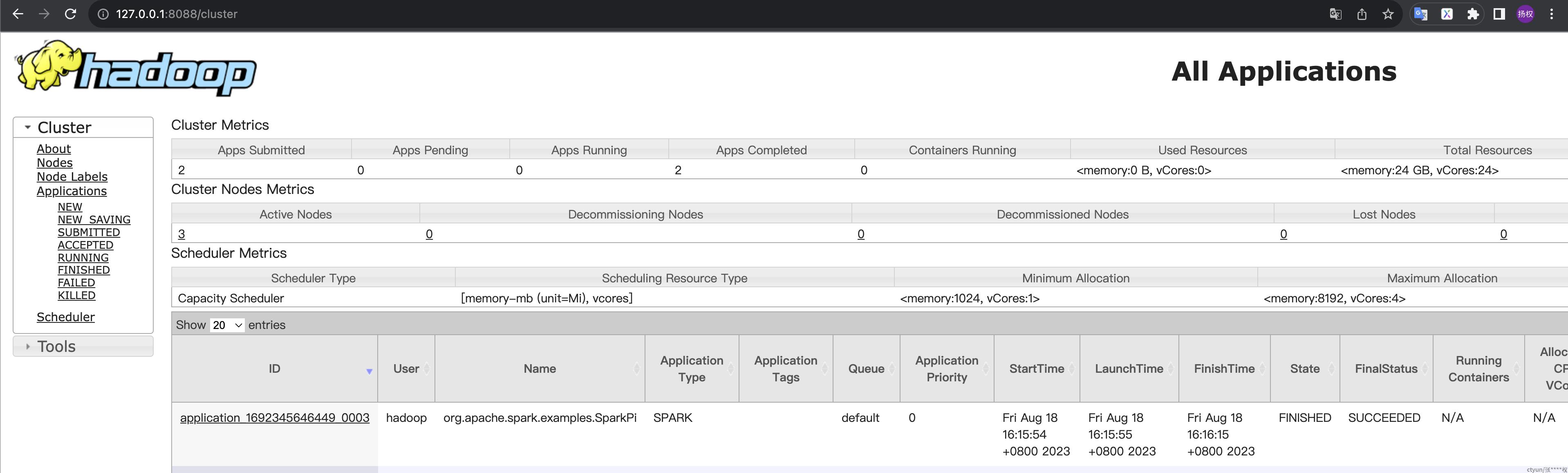
计算pi值的demo,跑起来很快。
想看log日志可以再hdfs上看到: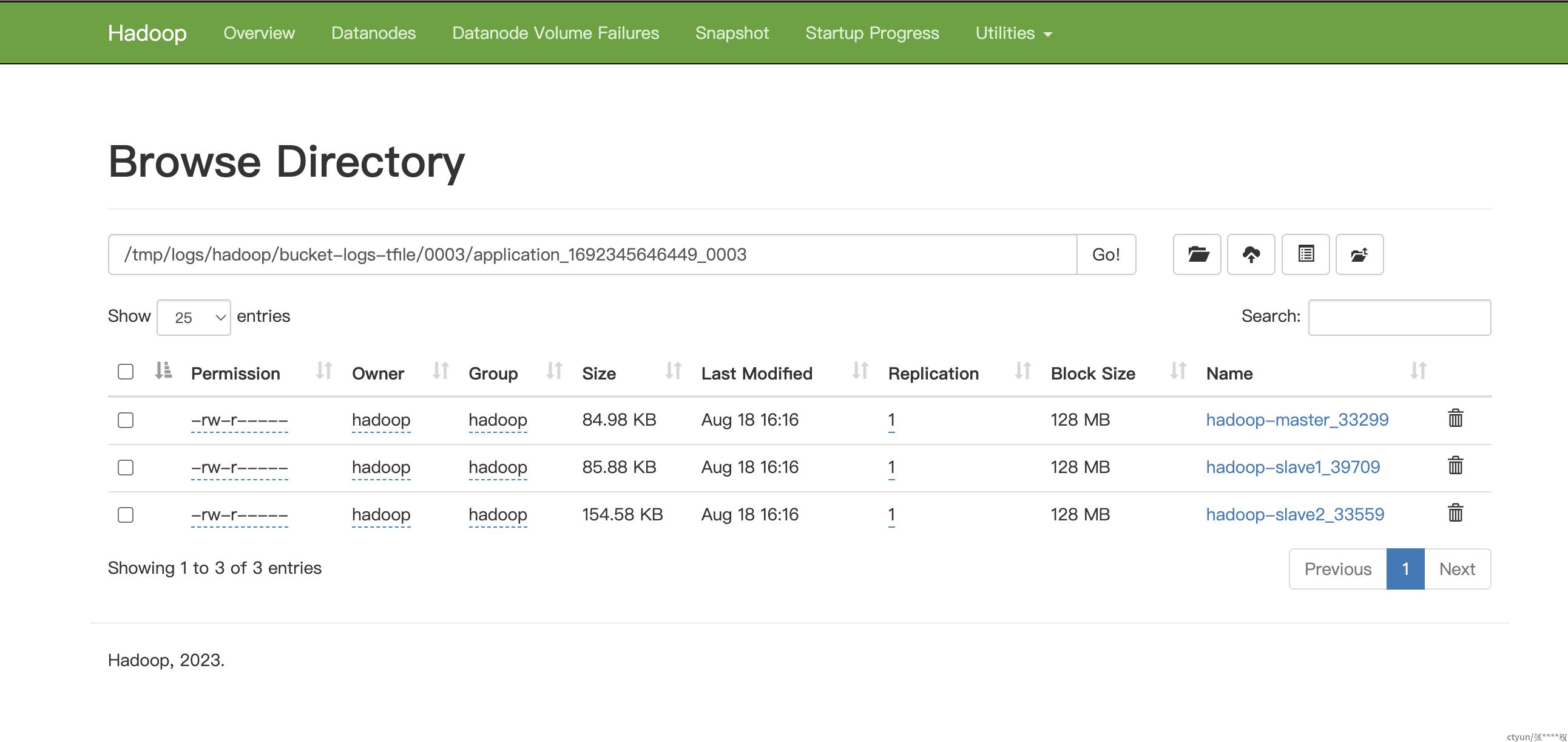
在容器中使用hdfs dfs命令也可以查看:

tail 一下可以看到pi的结算结果值:

