


参数配置是数据库调优重要的一环,数据库管理系统(DBMS)能够实时查看数据库运行策略,通过设置不同的数据库参数,实现对数据库性能的调优。而DBMS是不会一直去关注数据库的参数或者状态值,除非有告警或者调优需求,OtterTune充当了AI助手,能够实时地监控和调整数据库的运行状态。本文介绍OtterTune工具的论文《Automatic Database Management System Tuning Through Large-scale Machine Learning》。
数据库管理系统(DBMS)的配置调优是任何数据密集型应用程序都需要面对的重要课题。从已有的实践来看,这是一项困难的任务,因为DBMS通常有数百个可以配置的选项,这些选项控制着数据库系统的一切细节,例如将多大的内存用于缓存、数据写入外存的频率等等。这些参数通常不是独立的,也没有一个通用的调整方案,要根据应用程序的具体需求进行调整。OtterTune就是为了实现利用人工调参的经验对数据库参数进行动态的精确的调整,实现更优秀的性能。
OtterTune的主要思路是对输入的数据库的状态和参数,利用机器学习模型根据历史负载来生成优化策略,对数据库进行调优。
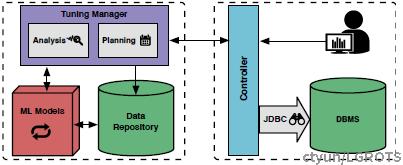
OtterTune的框架如图所示,主要分为服务器端(左)和客户端(右)两部分,客户端负责采集数据库运行状态,调整数据库参数以及将结果可视化给用户。而服务器端则是处理核心,分析收集到的数据库状态参数等信息,在机器学习模型中进行预测和优化,生成新的参数调整策略。
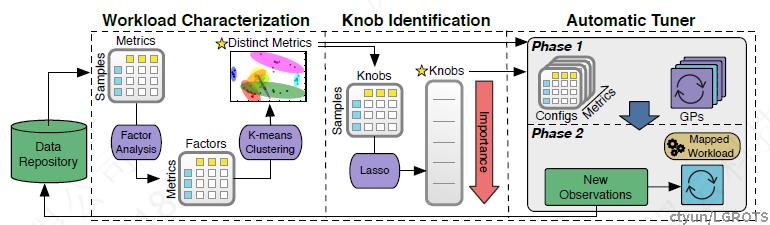
服务器端使用如图所示的机器学习框架进行参数的调优。所有过去的运行结果都存储在数据仓库中,作为AI判断的“记忆”,当新的观测数据传入时,首先与数据仓库中的历史数据一起,经过工作负载表征组件,将DBMS的各项指标和参数配置进行向量化,并采用无监督的KNN网络进行聚类操作,同时去除掉几乎无影响的冗余参数。这样将参数分组后,OtterTune使用Lasso线性回归算法对这些特征进行特征选择,得到对于数据库性能影响较大的参数组和影响较小的参数组。即对各组参数赋予权重。
当得到一个带权重的参数列表后,下一步就是选择优化那些参数,如何从这些参数里面选择一个适当的集合是很难的事情,选太多计算量大,太少则可能没有优化效果。如此,OtterTune通过增量的方式来逐步增加参数范围,这种动态的方式比固化参数集合更加合理。优化的实现主要依靠对历史工作负载的搜索与匹配,首先匹配历史相似的工作负载,匹配的越多,质量就越高。每一个历史工作负载都对应了一套优化参数,同时每一个历史负载都能够与当前负载计算匹配度。在匹配到的历史负载中,利用匹配度作权重,OtterTune通过高斯回归的方式来选择优化效果最大的参数集合。
总结来说,OtterTune对负载进行聚类,利用历史参数进行推荐新参数的优化方式,能够在参数量较大的数据库系统上取得更好的调优效果(虽然这通常是因为参数量过多导致人工调整参数的效率非常低)。随着数据库参数的不断增多,以及数据库状态的复杂化,通过使用这样的简易ML模型进行调参会得到比人工调参更好的结果。但是依靠机器学习仍然有很大的局限性,例如无监督聚类算法的执行效率,推荐优化参数时使用的算法仍然比较传统,无法发挥机器学习的真正能力,以及算法对于GPU运算资源的大量需求,这些都是有待解决的问题。
