


0. 思考
分享Lex和Yacc的初衷是因为在看PostgreSQL的源码中发现scan.l和gram.y两个文件,为了弄清其具体的含义和使用方法,阅读了书籍和网上分享的资料。
1. 概述
- “.”:匹配任何除\n之外的单个字符。
- “$”:匹配行结束符。
-
“^":匹配一行的开始。
-
“\":转义字符,例如正则表达式\$被用来匹配美元符号而不是行尾。
-
“[ ]":匹配括号中的任何一个字符,例如[a-z]将匹配从a到z的任何一个字符。
-
“+":匹配1个或多个正好在它之前的那个字符,例如正则表达式9+匹配9、99、999等。
-
“?":匹配0或1个正好在它之前的那个字符,或匹配前面的正则表达式0次或1次。
-
“|":匹配前面的正则表达式或随后的正则表达式,例如cow | pig | sleep可以匹配cow、pig、sleep中任何一个。
-
“{ }":当括号中包含1个或者2个数字时,指示前面的模式被允许匹配多少次,例如A{1,3},匹配A1次到3次。
2.2 词法分析的工作
词法分析的主要工作是利用正则表达式在给定字符序列中进行模式匹配,通常正则表达式写在一个后缀为”.l“的文件(Lex文件)中,通过Lex命令可以从Lex文件生成一个包含有扫描器的C语言源代码,其他源代码可以通过调用该扫描器来实现语法分析。
事实上,每一个正则表达式代表一个有限状态自动机(FSA)。我们可以用状态和状态之间的转换来代表一个FSA,其中包括一个开始状态以及一个或多个结束状态或接受状态。
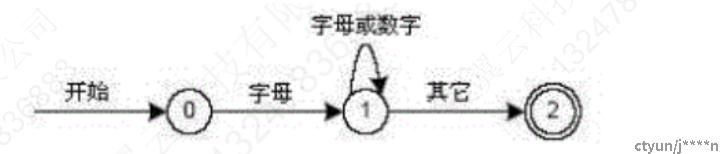
(图片来源:《PostgreSQL数据库内核分析》)
在上图中状态0是开始状态,而状态2是接受状态,当读入字符,就会进行状态转换。当读入第一个字母时,程序转换到状态1。如果后面读入的也是字母或数字,程序就继续保持在状态1;如果不是,程序会转换到状态2,即接受状态。每一个FSA都表现为一个计算机程序,将上图用伪代码实现:
start: goto state0
state0: read c
if c = letter goto state1
goto state0
state1: read c
if c = letter goto state1
if c = digit goto state1
goto state2
state2: accept string分为三段:定义段、规则段和代码段,各段之间由”%%“符号分隔。
- 定义段可以包含任意的C语言头文件、符号说明等,其代码会被直接拷贝到生成的扫描器代码文件中。
- 规则段利用正则表达式来匹配模式,每当成功匹配一个模式,就对应其后”{ }“中的代码,这些匹配规则及动作都会反映到最后生成的扫描器代码文件中。
- 代码段可以是任意的C代码,其中必须调用Lex通过的函数。代码段的内容将会被直接拷贝到生成的扫描器代码文件中。

(图片来源:《PostgreSQL数据库内核分析》)
2.4 Lex示例文件
% {
/* example.l
* 这是一个简单的Lex示例 /*定义段*/
这个段里面可以包含c头文件以及注释
*/
#include <stdlib.h>
% }
% %
[\n \t]; /*规则段*/
-?[0-9]+ {printf("num=%d\n",atoi(yytext));}
.;
% %
main() /*代码段*/
{
yylex();
}上面生成的C程序可以用来识别一个整数,并将其值输出。
生成扫描器代码并编译的命令如下:
lex example.l
cc lex.yy.c-o first-ll
Lex命令从文件”example.l“生成”lex.yy.c“文件,cc命令中的参数-ll用于链接lex库,编译生成的程序名为first。运行first后输入任意字符将会输出结果。
Lex生成的扫描器在成功识别模式后,通过Lex变量存储该模式对应的值,并将其返回给上层调用者(通常是Yacc生成的语法分析器)。
(图片来源:《PostgreSQL数据库内核分析》)
在linux下没有Lex命令,只有flex命令。必须安装flex才能编译.l文件。
跟着书上的示例文件语法实践了一个简单的lex文件。

程序的意思是把遇到7的倍数加3以后输出,如果不是3的倍数则原样输出。
紧接着,用flex命令:flex example.l
这样目录下会生成一个lex.yy.c文件,这是一个c程序
紧接着使用命令:gcc -c lex.yy.c
编译这个文件后,会生成lex.yy.o文件
执行gcc -o parser lex.yy.o -ll,使之与lex库连接,生成可执行文件parser
在执行上条命令时,出现了问题。

原因是因为系统缺少了libfi.a文件。
解决办法:用yum安装flex-devel
但是依旧出现问题。
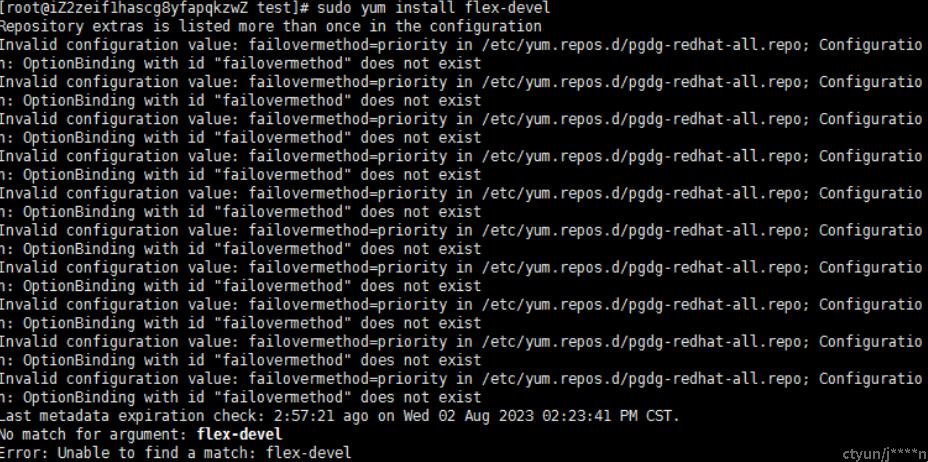
原因可能是因为软件包没有得到支持。
解决办法:通过wget下载flex-devel-2.6.1-9.el8.x86_64.rpm,并安装之后编译不会报错。
创建测试文件data.txt

执行程序./parser<data.txt

最后目录列表为
3. Yacc
语法分析的主要工作是从给定模式序列输入中寻找某一特定语法结构。Yacc的工作方式和Lex相似,也是将语法的定义以及一些必要的C语言代码写在一个后缀为“.y“的文件(Yacc文件)中,然后用Yacc命令由该文件生成具有语法分析功能的C语言代码文件。
3.1 Yacc文法
Yacc的文法由一个使用BNF文法(巴克斯范式)的变量描述。例如,数值相乘和相加的文法是:
E->E + E
E->E * E
E->id
上面三个例子代表三个规则(依次为r1,r2,r3)。像E(表达式)这样出现在左边的结构叫非终结符,像id(标识符)这样的结构叫终结符(terminal,由lex返回的标记),它们只出现在右边。这段文法表示,一个表达式可以是两个表达式的和、乘积,或者是一个标识符。
巴克斯范式:
(1) <>内包含的内容为必选项;
(2) []内包含的内容含的内容为可选项;
(3) { } 内包含的为可重复0至无数次的项;
(4) | 表示在其左右两边任选一项,相当于"OR"的意思;
(5) ::= 是“被定义为”的意思;
(6) 双引号“”内的内容代表这些字符本身;而double _quote用来表示双引号。
3.2 Yacc语法规则
result: components { /*
action to be taken in C*/ };3.3 Yacc文件格式
也分为三个段:定义段、规则段和代码段,其中各个段由”%%“符号分隔。
定义段:可以是C代码,如包含头文件和函数声明(”% { ··· % }“中的内容),同时也可以定义Yacc的内部标志等。
规则段:用来表示语法规则,并在每识别一个语法规则后,根据规则后面”{ }“内的代码进行相应的处理操作。
代码段:包括C代码,它将被直接拷贝到生成的C文件中。同样代码段也包含一些Yacc函数和一些Lex传递给Yacc的变量。
3.4 Yacc示例文件
% {
/* calculator.y*/ /*定义段*/
#include <stdio.h>
% }
% token NAME NUMBER
% left '+' '-'
% start statement
% %
statement : NAME '=' expression*/ /*规则段*/
| expression{printf("=%d\n", $1);}
;
expression:expression'+'NUMBER{$$ = $1 + $3;}
| expression'-'NUMBER{$$ = $1 - $3;}
| NUMBER{$$ = $1;}
;
% %
main()
{
do /*代码段*/
{
yyparse();
}
while(!feof(yyin));
}其中,定义段中%token定义标识符,%left指定云算法的优先级,%start表示从标识符开始解析;规则段中$$代表语法表达式的左边结构的值,而$1代表语法表达式右边结构第一个标识符对应的值,针对第12行代码语法表达式说明expression可以由一个expression、”+“号和一个NUMBER构成,如果有一个模式能匹配这个语法规则,则左边expression的值($$)等于右边expression的值($1)加上NUMBER的值($3),中间跳过没有用到的$2指的是”+“号。
可以看出,该yacc文件中的main函数不断地执行yyparse来进行语法分析。yyparse函数识别某种语法结构并进行相应的行为处理。该语法结构是每当识别一个加法表达式时,就把加法两边的数相加;每当识别减法表达式时,就把减号两边的数相减,这样就完成了加减功能。NAME和NUMBER这些符号只是定义,值是由Lex通过变量传给Yacc。Yacc无法单独运行,必须与Lex配合使用。
% {
/* calculator.l*/
#include "y.tab.h"
extern int yylval;
% }
% %
[0-9]+ {yylval=atoi(yytext);return NUMBER;}
[\t];
return 0;
return yytext[0];
% %Lex每识别一个数字,将以标识符NUMBER返回给Yacc(Lex文件第7行),并将它的值传给yylval。而Yacc根据NUMBER标识可以判断yylval中存放的是一个数字,并从yylval读取其值。例如yacc文件中的$1等就是从yylval中取值。
从Lex文件和Yacc文件构建一个计算器程序的命令如下:
yacc -d calculator.y //生成y.tab.c和y.tab.h
lex calculator.l //生成lex.yy.c
cc -o calculator y.tab.c lex.yy.c -ly -ll //编译和链接C文件
最后生成程序名为calculator,识别符号并计算结果返回。
仿照示例文件,结合Lex和Yacc进行使用:
创建一个test.txt文件,test.txt文件的内容是:
ZhangSan=23
LiSi=34
WangWu=43
扫描文本后,希望输出:
ZhangSan is 23 years old!!!
LiSi is 34 years old!!!
WangWu is 43 years old!!!
创建的Lex文件内容:
%{
#include "test.tab.h"
#include <stdio.h>
#include <string.h>
%}
char [A-Za-z]
num [0-9]
eq [=]
name {char}+
age {num}+
%%
{name} { yylval = strdup(yytext); return NAME; }
{eq} { return EQ; }
{age} { yylval = strdup(yytext); return AGE; }
%%
int yywrap()
{
return 1;
}创建的Yacc文件内容:
%{
#include <stdio.h>
#include <stdlib.h>
typedef char* string;
#define YYSTYPE string
%}
%token NAME EQ AGE
%%
file : record file
| record
;
record : NAME EQ AGE {
printf("%s is %s years old!!!\n", $1, $3); }
;
%%
int main()
{
extern FILE* yyin;
if (!(yyin = fopen("test.txt", "r")))
{
perror("cannot open parsefile:");
return -1;
}
yyparse();
fclose(yyin);
return 0;
}
int yyerror(char *msg)
{
printf("Error encountered: %s \n", msg);
}利用Lex扫描text.txt文本,返回token,Yacc根据Lex返回的token,判断这些token是否符合一定的语法,符合则进行相应动作。
紧接着,进行如下命令:
flex test.l
bison -d test.y
生成了test.tab.c、test.tab.h、lex.yy.c文件
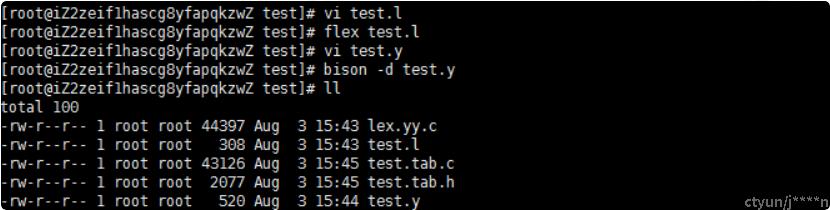
最后通过gcc -o test test.tab.c lex.yy.c -ly -ll命令生成可执行文件test
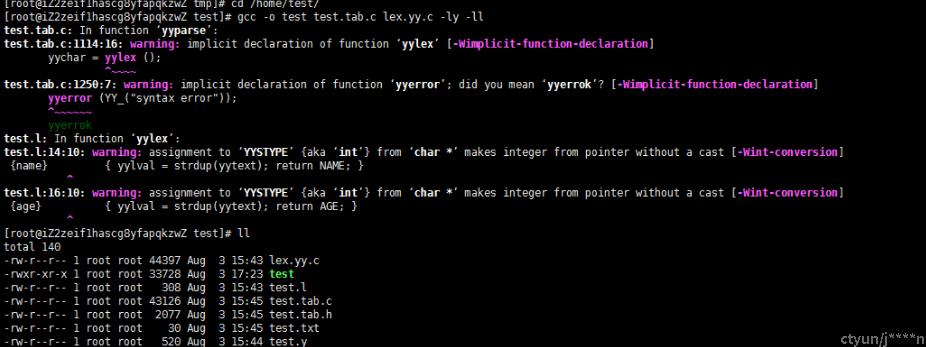
把test.txt文件作为输入,编译运行结果为

