


disruptor介绍
参考文档
https://tech.meituan.com/2016/11/18/disruptor.html
https://www.cnblogs.com/pku-liuqiang/p/8544700.html
https://juejin.cn/post/6844903685609226254
介绍
disruptor是什么
Disruptor 是由英国的外汇交易公司LMAX创造的一个高效队列,它的设计初衷是为了解决内存队列中的延时问题(在性能测试中发现与1/0操作有相同的数量级)。基于Disruptor的系统可以在单线程下支持每秒处理600万订单。在2010年的QCon讲座后,它引起了业界的注意。2011年,企业应用软件专家Martin Fowler专门撰写了一篇长篇文章进行介绍。在同一年,它还获得了Oracle官方的Duke大奖。从数据结构的角度来看,Disruptor是一个支持生产者消费者模式的环形队列,它能在无锁的情况下并行消费,也可以根据消费者间的依赖关系进行有序消费。
Disruptor的设计方案
为了解决队列速度慢的问题,Disruptor引入了以下设计:
-
环形数组结构:使用数组而非链表,避免垃圾回收,并且与处理器缓存机制更加兼容。
-
元素位置定位:采用长度为2的幂次的数组,通过位运算快速定位元素位置。下标按递增顺序排列,不会导致索引溢出。使用长整型(long)索引,即使每秒处理100万个请求,也需要30万年才能用完。
-
无锁设计:每个生产者或消费者线程先申请可操作的数组位置,一旦获得位置,直接在该位置读取或写入数据。无需考虑数组的环形结构。整个过程通过原子变量CAS实现,确保线程操作的安全性。
事件消费模式
- 多个消费者重复消费同一条消息数据
- 多个消费者非重复消费同一条消息数据
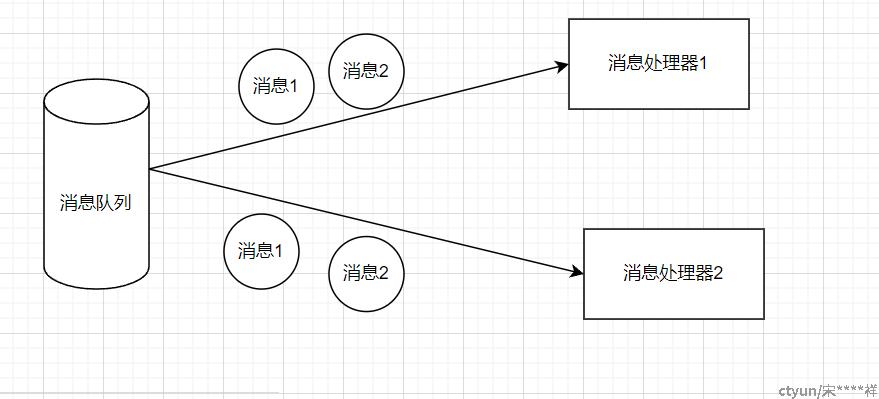
多个消费者重复消费同一条消息数据
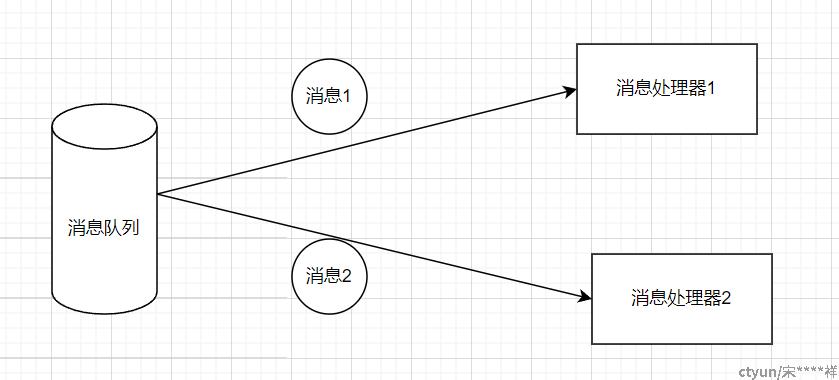
多个消费者非重复消费同一条消息数据
基本使用
下面以“单生产者-多消费者-多消费者不重复消费数据”这个demo来展示如何使用disruptor
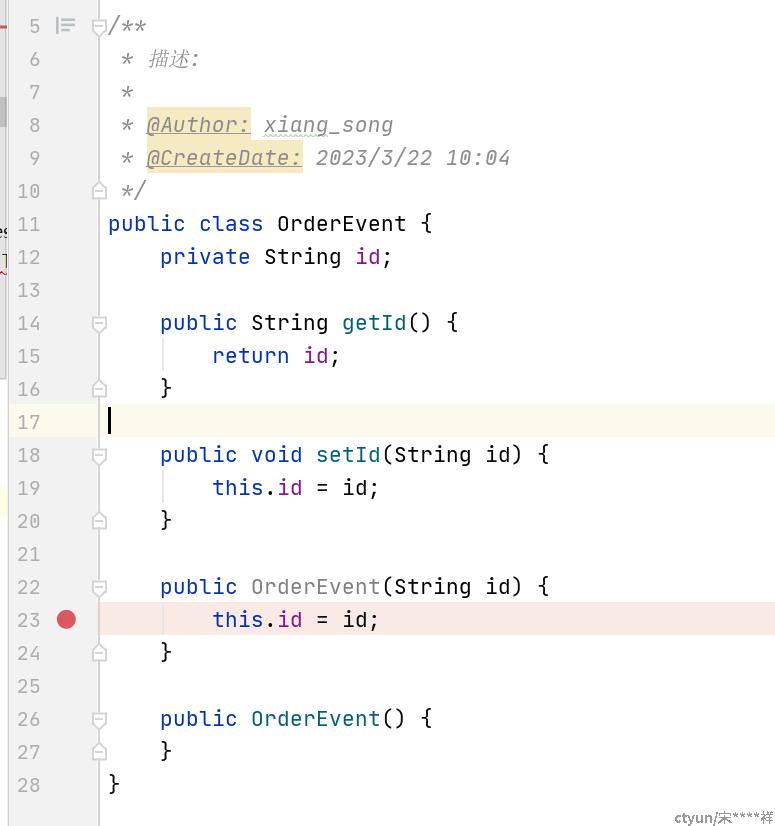
1、创建一个类,这个类表示队列里面存储数据的类型
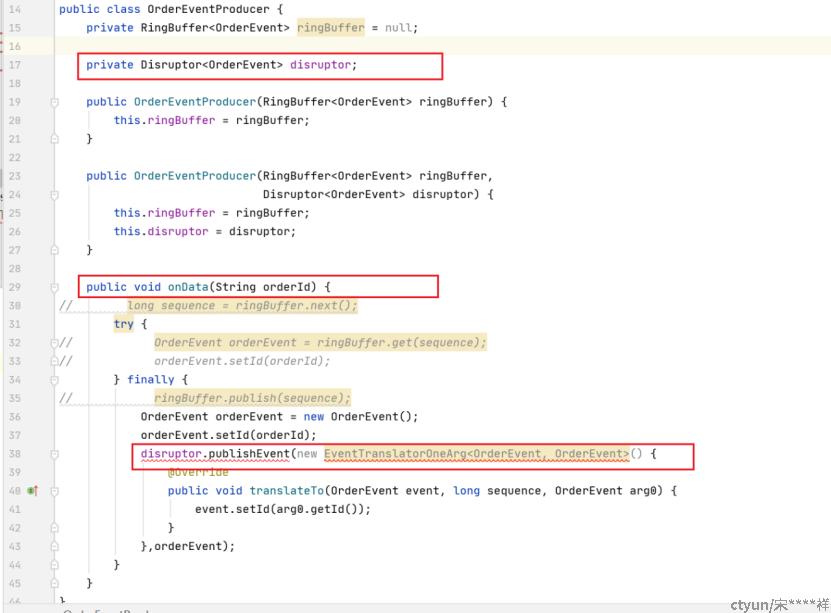
2、创建生产者类,用于生产数据到队列
3、创建消费者类
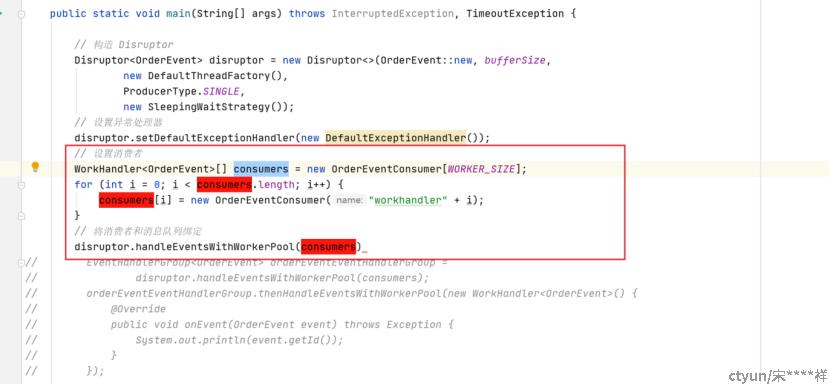
如果是多消费者不重复消费同一条数据则实现WorkHandler接口,并且onEvent为消费数据的逻辑

4、创建Disruptor队列
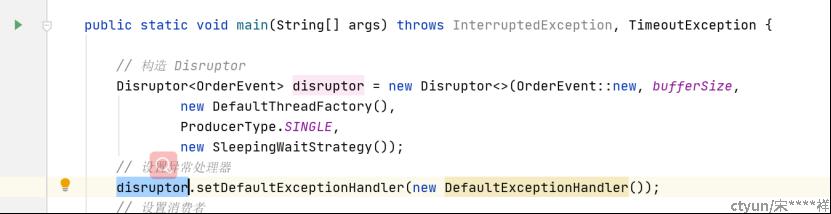
下面解释一下Disruptor的构造参数:
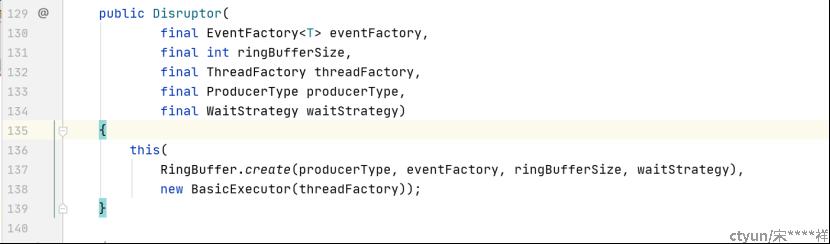
EventFactory:定义队列里面数据是怎么创建的工厂类,因为队列的对象是会全部创建出来的,如何创建取决于EventFactory的定义
ringBufferSize:队列的容量大小,这个值设定了就是固定的,启动Disruptor的时候就会初始化这个数量的元素
ThreadFactory:创建生产消费者线程的工厂类
ProducerType:生产者数量,SINGLE为单生产者,MULTI为多生产者
WaitStrategy:当队列没数据时,消费者线程的处理策略,主要有下面8种
BlockingWaitStrategy:用了ReentrantLock的等待&&唤醒机制实现等待逻辑,是默认策略,比较节省CPU
BusySpinWaitStrategy:持续自旋,JDK9之下慎用(最好别用)
LiteBlockingWaitStrategy:基于BlockingWaitStrategy,在没有锁竞争的时候会省去唤醒操作,但是作者说测试不充分,不建议使用
TimeoutBlockingWaitStrategy:带超时的等待,超时后会执行业务指定的处理逻辑
LiteTimeoutBlockingWaitStrategy:基于TimeoutBlockingWaitStrategy,在没有锁竞争的时候会省去唤醒操作
SleepingWaitStrategy:三段式,第一阶段自旋,第二阶段执行Thread.yield交出CPU,第三阶段睡眠执行时间,反复的的睡眠
YieldingWaitStrategy:二段式,第一阶段自旋,第二阶段执行Thread.yield交出CPU
PhasedBackoffWaitStrategy:四段式,第一阶段自旋指定次数,第二阶段自旋指定时间,第三阶段执行Thread.yield交出CPU,第四阶段调用成员变量的waitFor方法,这个成员变量可以被设置为BlockingWaitStrategy、LiteBlockingWaitStrategy、SleepingWaitStrategy这三个中的一个
ExceptionHandler:设置消费过程的异常处理器,主要有3类异常要处理:队列启动异常、消息者消费数据异常、队列关闭异常

5、创建多个消费者,并且与队列绑定
6、启动队列进程,开始工作,生产者生产数据
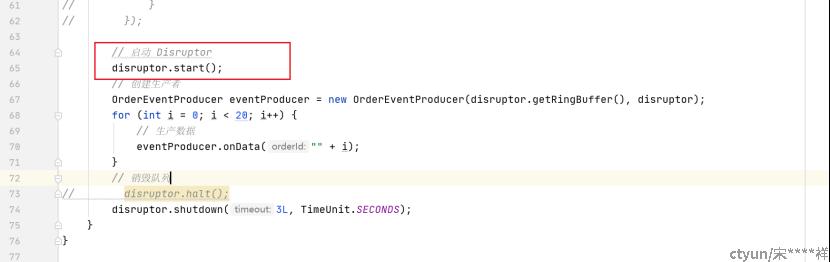
7、关闭队列和生产者消费者线程
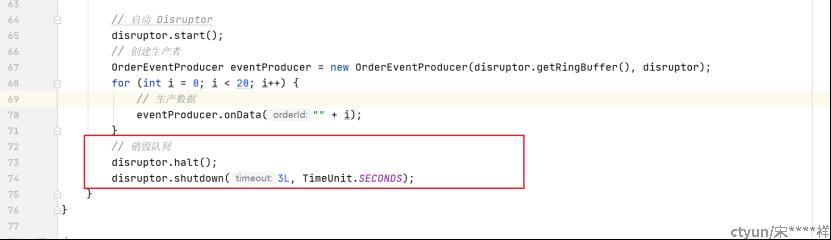
细节说明
- 队列始终有且仅有会存放环形数组容量个数的对象,即便这些元素被消费线程消费了也不会被释放
- 如果队列里面的元素到达了环形数组容量,那么生产者线程就会被阻塞
- 如何消费数据出现异常,在异常处理器里面,异常不能往外抛,否则会导致waiting
- 消费者线程是一开始就确定好有多少个的,而且要全部都运行起来,目前我们是使用线程池动态创建线程,总数控制在corePoolSize内
- disruptor新用法不建议使用线程池了,cloudcanal也没有使用线程池,如果是只有一个disruptor队列的话,生产者和消费者线程都是一开始就启动的,中途也不会销毁,确实可以不需要线程池,但我们dts一个表的迁移就对应一个消息队列,这个表跑完了就要销毁队列和线程,这样看有线程池效率确实高一些
