


在许多物理网络的拓扑中,服务器的bond的两个物理口分别上联两台交换机,这样的结构可以提高可靠性,即使部分端口或设备出现故障,也可保障业务的正常转发。在这种拓扑下,服务器在发送ARP请求和应答需要在聚合的所有成员接口网卡进行发送与接收,又叫做“ARP双发”。当前我们的服务器网卡bond模式为802.3ad,出向流量端口的选取根据hash策略决定,因此ARP报文会按照hash算法选择BOND成员网卡中的一个进行发送,这样去堆叠的两台设备ARP表项就不会同步。这时候需要在服务器做对应的适配,使其在发送ARP报文时在所有BOND的成员网卡发送。
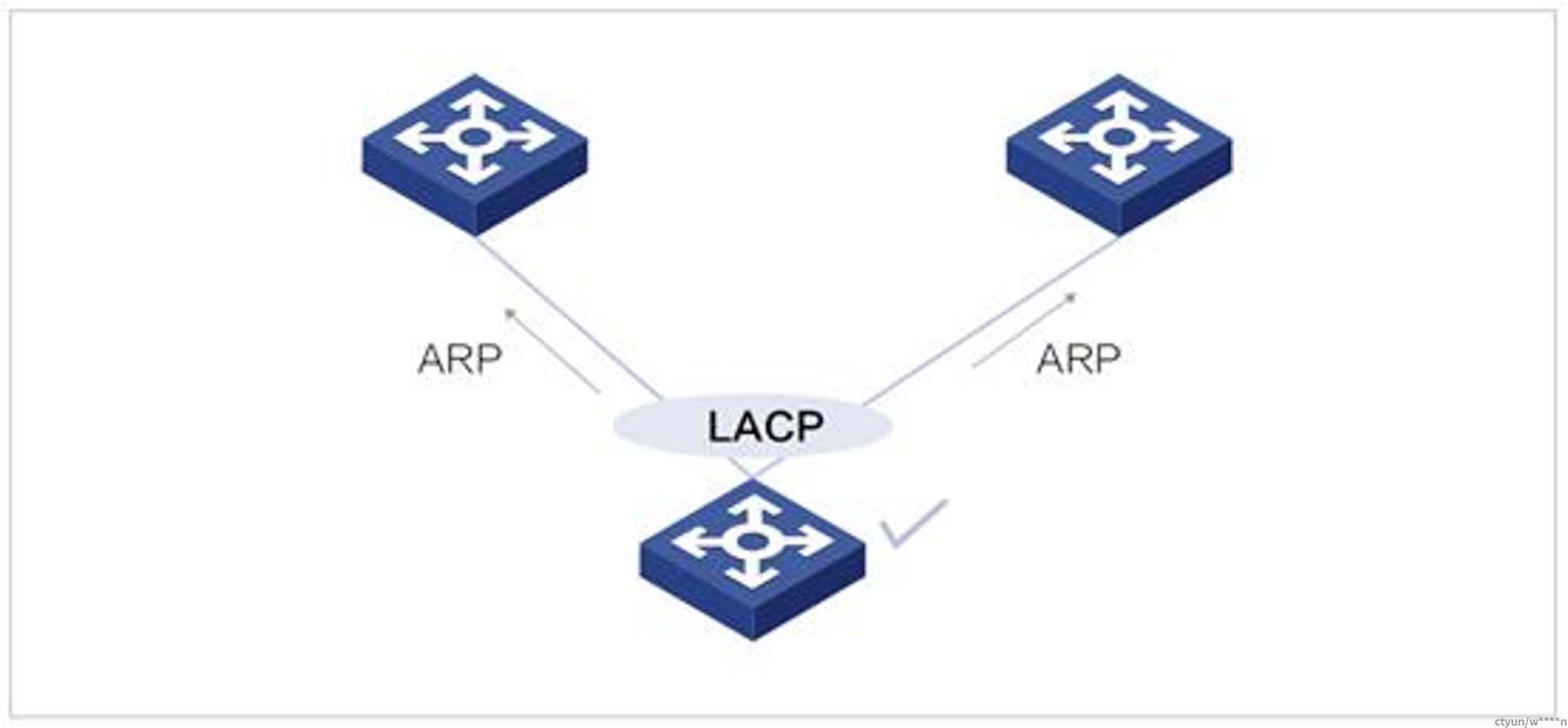
对于不同需要支持arp双发的环境,有着不同arp双发的实现方式,以下将对几种场景分别阐述不同环境下arp双发的实现:
存储网关
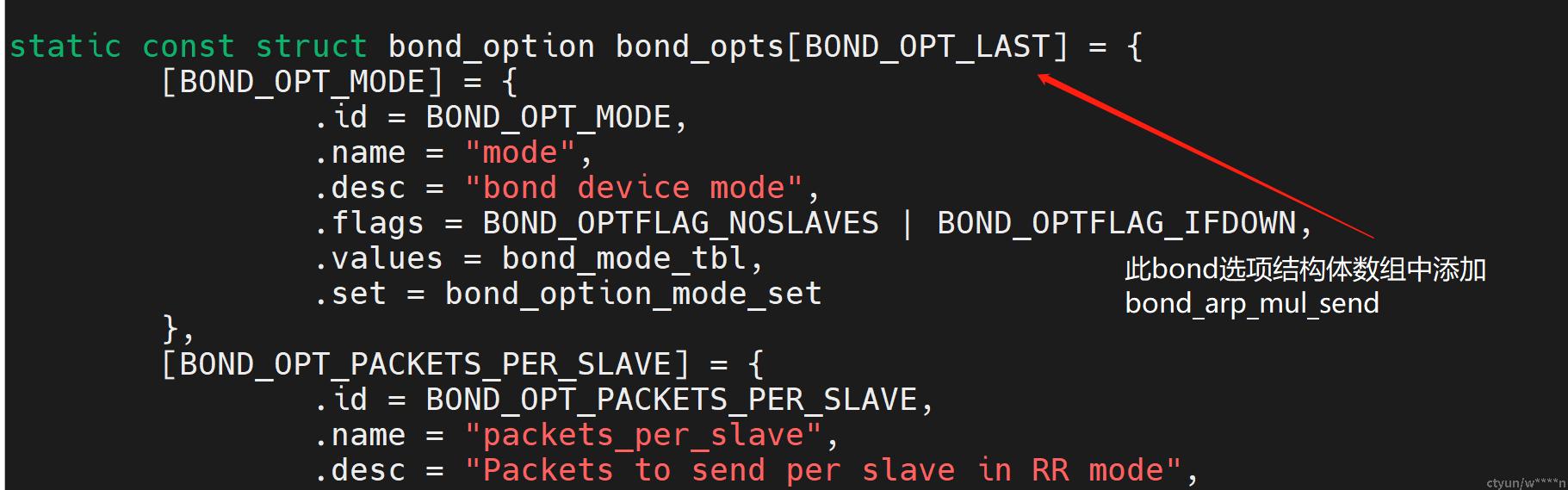
存储网关的主要工作是对rdma流量进行一些qos处理,因此arp报文依靠内核网络协议栈进行收发,该环境下实现arp双发需要对linux kernel进行bond模块下的开发,当前我司内核组已完成arp双发的支持,开关配置:
打开bond arp双发:echo 1 > /proc/net/bond_arp_mul_send
关闭bond arp双发:echo 0 > /proc/net/bond_arp_mul_send
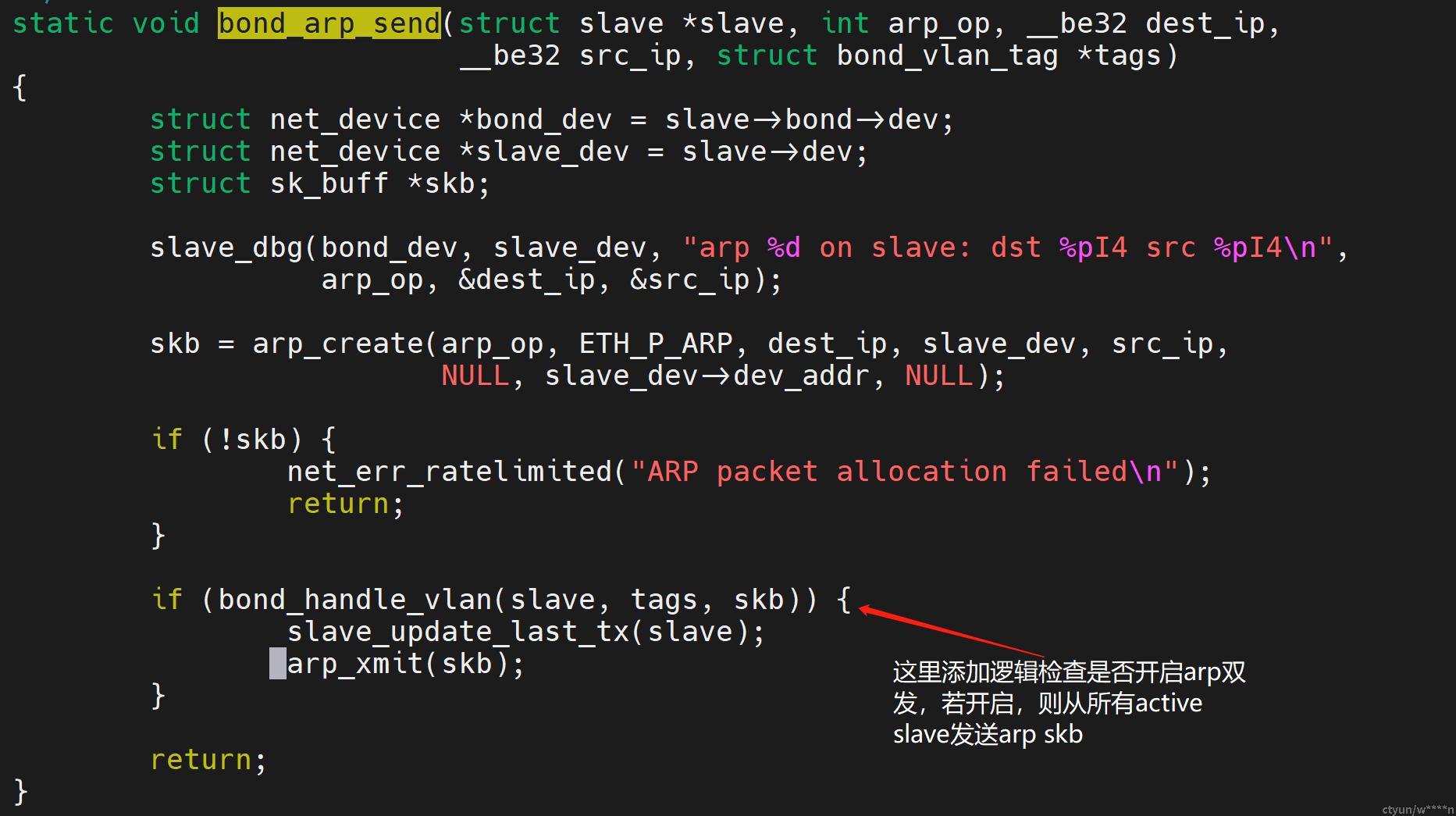
大致实现方式是在kernel的bond_options里添加arp双发的配置开关,而后在bond发送arp函数bond_arp_send里判断,若arp双发配置开启,则将arp报文从所有active状态的slave发送出去。
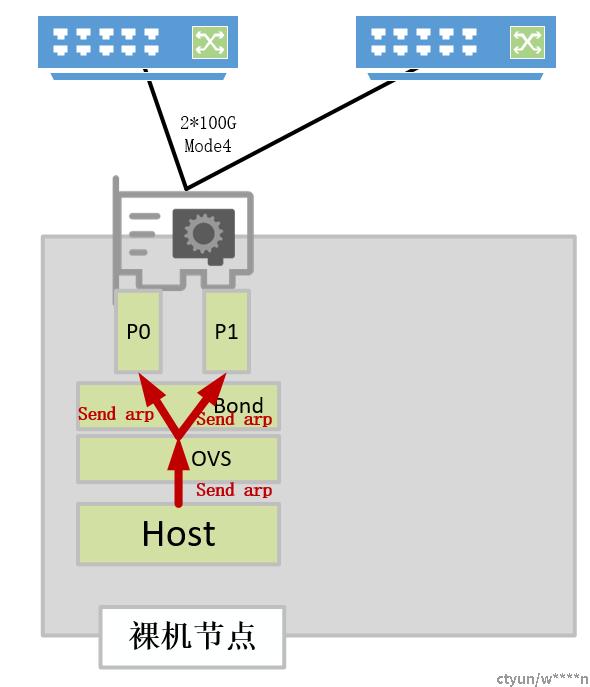
弹性裸金属或DPU云主机(商用卡)
对于弹性裸金属或DPU云主机环境,两个物理口是在内核做好了bond后,将bond的代表口添加到ovs bridge的形式使用,因此实现arp双发需要ovs侧做相应的支持,由于bond以rep口的形式加入到ovs,对于ovs-dpdk而言,该port并不是标准的bond口,同样也不走ovs的bond逻辑,对于这种情况,我们采用固件配置队列亲和性+openflow流表set queue的方案实现arp双发。
队列亲和性
商用卡有两种bond运行模式,队列亲和性模式与哈希模式。在hash模式下,bond发包将根据报文的hash值决定pkt从哪个物理口发送;而在队列亲和性模式下,pkt可根据所在队列决定发送的物理口(偶数队列从p0发送,奇数队列从p1发送),两种模式的固件配置方式如下:
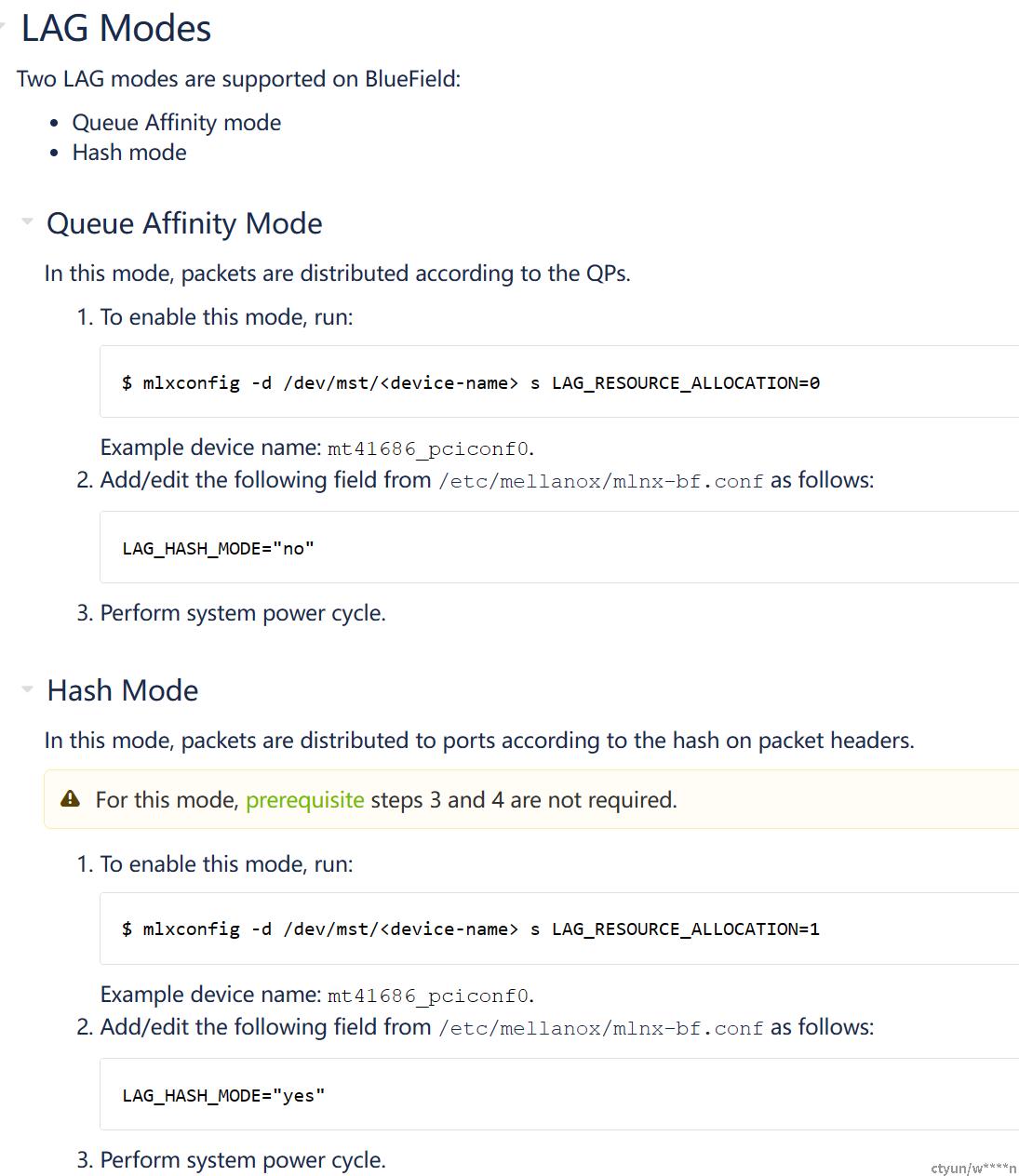
ovs set_queue action
set_queue action是ovs一种可以指定报文发送队列的action,其实现与应用随着openflow协议与datapath类型各有不同,由于当前ovs-dpdk没有datapath侧的实现,我们自研实现了一种dpdk set_queue action datapath的支持,使用示例如下:
ovs-ofctl add-flow br-ext "priority=10000,in_port=LOCAL,arp actions=push_vlan:0x8100,set_field:4397->vlan_vid,set_queue:1,output:bond1,pop_queue,set_queue:2,output:bond1,pop_queue" -Oopenflow13
具体实现patch:
From: wangze <wangz67@chinatelecom.cn>
Date: Mon, 5 Jun 2023 16:12:22 +0800
Subject: [PATCH] add set_queue datapath dpdk support
When doing set_queue action, skb_priority is marked in
userspace, but there is no further processing in datapath
dpdk. This patch add set_queue support in datapath dpdk,
sending skbs with skb_priority from specific queues.
The enqueue action can be applied to the scenario of
double-sending arp packets, usage:
ovs-ofctl add-flow br-ext "priority=10000,in_port=LOCAL,arp actions=push_vlan:
0x8100,set_field:4397->vlan_vid,set_queue:1,output:bond1,pop_queue,set_queue:2,
output:bond1,pop_queue" -Oopenflow13
Signed-off-by: wangze <wangz67@chinatelecom.cn>
---
lib/dpif-netdev.c | 38 ++++++++++++++++++++++++++++++++------
1 file changed, 32 insertions(+), 6 deletions(-)
diff --git a/lib/dpif-netdev.c b/lib/dpif-netdev.c
index 924f10c..cec756e 100644
--- a/lib/dpif-netdev.c
+++ b/lib/dpif-netdev.c
@@ -6526,6 +6526,28 @@ pmd_perf_metrics_enabled(const struct dp_netdev_pmd_thread *pmd OVS_UNUSED)
#endif
static int
+dp_netdev_pmd_flush_txqs_on_port(struct dp_netdev_pmd_thread *pmd,
+ struct tx_port *p)
+{
+ int i;
+ int output_cnt = 0;
+
+ int n_txq = netdev_n_txq(p->port->netdev);
+
+ for (i = 0; i < n_txq; i++) {
+ if (dp_packet_batch_is_empty(&p->txq_pkts[i])) {
+ continue;
+ }
+ output_cnt += dp_packet_batch_size(&p->txq_pkts[i]);
+ netdev_send(p->port->netdev, i, &p->txq_pkts[i], true);
+ dp_packet_batch_init(&p->txq_pkts[i]);
+ }
+
+ pmd_perf_update_counter(&pmd->perf_stats, PMD_STAT_SENT_PKTS, output_cnt);
+ return output_cnt;
+}
+
+static int
dp_netdev_pmd_flush_output_on_port(struct dp_netdev_pmd_thread *pmd,
struct tx_port *p)
{
@@ -9010,13 +9032,11 @@ dp_netdev_add_port_tx_to_pmd(struct dp_netdev_pmd_thread *pmd,
tx->flush_time = 0LL;
dp_packet_batch_init(&tx->output_pkts);
- if (tx->port->txq_mode == TXQ_MODE_XPS_HASH) {
- int i, n_txq = netdev_n_txq(tx->port->netdev);
+ int i, n_txq = netdev_n_txq(tx->port->netdev);
- tx->txq_pkts = xzalloc(n_txq * sizeof *tx->txq_pkts);
- for (i = 0; i < n_txq; i++) {
- dp_packet_batch_init(&tx->txq_pkts[i]);
- }
+ tx->txq_pkts = xzalloc(n_txq * sizeof *tx->txq_pkts);
+ for (i = 0; i < n_txq; i++) {
+ dp_packet_batch_init(&tx->txq_pkts[i]);
}
hmap_insert(&pmd->tx_ports, &tx->node, hash_port_no(tx->port->port_no));
@@ -11756,6 +11776,7 @@ dp_execute_output_action(struct dp_netdev_pmd_thread *pmd,
}
dp_packet_batch_apply_cutlen(packets_);
#ifdef DPDK_NETDEV
+ dp_netdev_pmd_flush_txqs_on_port(pmd, p);
if (OVS_UNLIKELY(!dp_packet_batch_is_empty(&p->output_pkts)
&& packets_->packets[0]->source
!= p->output_pkts.packets[0]->source)) {
@@ -11775,9 +11796,14 @@ dp_execute_output_action(struct dp_netdev_pmd_thread *pmd,
}
struct dp_packet *packet;
+ int n_txq = netdev_n_txq(p->port->netdev);
DP_PACKET_BATCH_FOR_EACH (i, packet, packets_) {
p->output_pkts_rxqs[dp_packet_batch_size(&p->output_pkts)] =
pmd->ctx.last_rxq;
+ if (packet->md.skb_priority) {
+ dp_packet_batch_add(&p->txq_pkts[packet->md.skb_priority%n_txq - 1],packet);
+ continue;
+ }
dp_packet_batch_add(&p->output_pkts, packet);
}
return true;
--
1.8.3.1
补丁的实现思路:
1. set_queue action将queue值存入报文的md.skb_priority
2. output时根据报文携带的skb_priority将报文放入相应队列的batch
小结
本文对当前已经支持arp双发的两种场景实现方式进行了简述。将来本文将来或对紫金DPU、某些走标准ovs bond逻辑的场景实现arp双发的情况进行补充。欢迎大家对本文内容进行指导与更正。
