在使用 SPDK 的场景中,对于 IO 超时问题的追踪,我们可能会想到添加日志打印进行分析,但是有些问题只有在大 IO 压力下才会出现,这就到了 spdk_trace 表演的时候了。
spdk_trace 是 SPDK 中的一套调试和跟踪框架,原理是在代码中调用到一些关键事件时记录检查点,这些事件信息会写入 /dev/shm 下面的共享内存,这套框架不止能跟踪 IO 超时的问题,它的跟踪能力几乎覆盖了 SPDK 的方方面面,当我们使用 SPDK lib 开发自己的 app 时,强烈建议也在程序的关键路径上使用这套 trace 框架添加一些检查点,会对问题跟踪定位起到很关键的作用。
SPDK 的 trace 默认情况下是未开启的,需要通过 rpc 开启,因为本文讲解 IO 超时问题的分析,所以就打开 bdev 模块的 trace:spdk_rpc.py trace_enable_tpoint_group bdev,开启之后,/dev/shm 下的共享内存中就会记录很多 bdev 相关的事件,但是这些事件并非可读的文本内容,需要通过分析工具进行解析,命令如下:
spdk_trace -t -s <app> -p <pid> -j
其中 app 是 spdk app 的名称,比如 nvmf,-j 表示解析完的数据通过 json 格式输出,便于我们分析。
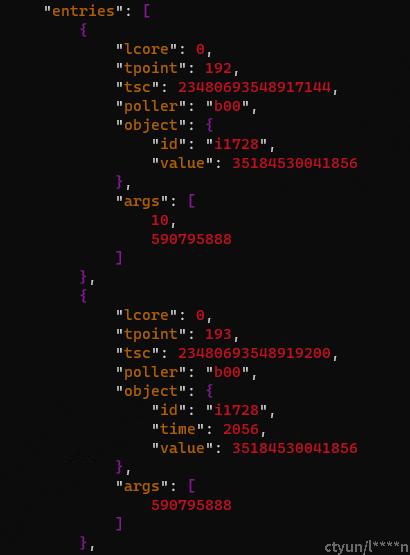
通过下图可以看到,trace 框架跟踪了两种事件,一种是 BDEV_IO_START,事件编号为 192,这种事件是在 IO 提交的时候会记录;另一种是 BDEV_IO_DONE ,事件编号 193,在 IO 完成时会在 IO 的回调函数中记录。
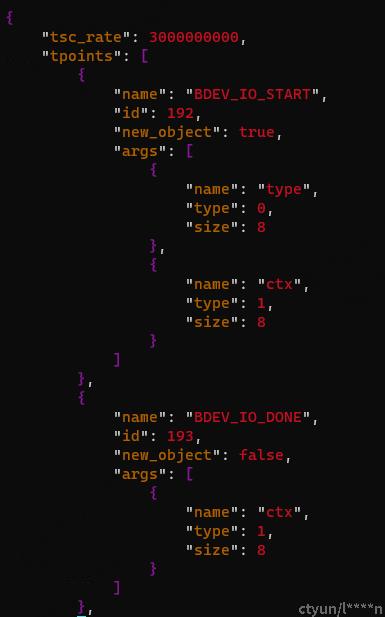
结合下图来看,entries 里面记录很多编号 192 和 193 的事件,记录的信息很多,我们主要通过 id 对应到同一个 IO,然后通过 tsc 计算时间差值就知道这个 IO 的处理过程花了多长时间。当然,最简单的方式还是直接看 193 时间中记录的 time,这里已经帮我们算好了。但是我们自己需要把这个时间换算为以秒为单位的数值,因为上图中给出了 tsc_rate 是 3000000000,所以计算就很简单了。用以下命令就可以找出 IO 处理耗时最多的一个 IO 究竟花了多久:
echo "scale=9;$( spdk_trace -t -s <app> -p <pid> -j | jq .entries[].object.time | sort -nu | tail -n1)/3000000000" | bc