


1、关于StreamPark
Apache StreamPark是一款致力于让流处理更简单的开源组件,通过极大降低学习成本和开发门槛,让开发者只用关心最核心的流式业务开发。 更多详见StreamPark官网(https://streampark.apache.org/docs/intro/)。
Note:虽然streampark极大降低了流式作业的开发管理门槛,但不代表是零门槛,即还是需要使用者简单了点flink的基础知识,如:部署模式、SQL语法、常用配置、connector等。
2、本地安装
2.1 前置工作
2.1.1 配置flink
说明:
- 配置目的:StreamPark创建作业时需要关联flink,如下。

- StreamPark已支持flink 1.12及以上版本,本次选取的组件版本如下
flink: flink-1.14.3-bin-scala_2.12.tgz
StreamPark: apache-streampark_2.12-2.0.0-incubating-bin.tar.gz
# 下载 https://archive.apache.org/dist/flink/flink-1.14.3
# 上传flink-1.14.3-bin-scala_2.12.tgz至/usr/local
# 解压
tar -zxvf flink-1.14.3-bin-scala_2.12.tgz
# 配置环境变量(vim ~/.bashrc),加入以下内容
export FLINK_HOME=/usr/local/flink-1.14.3
export PATH=$FLINK_HOME/bin:$PATH
# 生效环境变量配置
source ~/.bashrc
# 测试(出现:'Version: 1.14.3, Commit ID: 98997ea',则说明配置成功)
flink -v
2.1.2 引入依赖包
引入目的:方便后期接入kafka、mysql数据源。如果不涉及则可以忽略此步。
需要引入的包(注意flink和scala版本):
下载地址: https://mvnrepository.com/
flink-connector-jdbc_2.12-1.14.3.jar、flink-connector-kafka_2.12-1.14.3.jar、
kafka-clients-2.8.1.jar、mysql-connector-java-8.0.27.jar
cp flink-connector-jdbc_2.12-1.14.3.jar \
flink-connector-kafka_2.12-1.14.3.jar \
kafka-clients-2.8.1.jar \
mysql-connector-java-8.0.27.jar $FLINK_HOME/lib2.1.3 kubernetes RBAC配置
若不采用flink on k8s 相关部署模式(kubernetes-session、kubernetes-application),则可忽略此步;
注意:该步骤强依赖已搭建好的k8s环境
# 创建namespace,成功创建后,就有默认的serviceaccount default
kubectl create namespace flink-dev
# 关联namespace和serviceaccount
kubectl create clusterrolebinding flink-role-binding-flink-dev --clusterrole=edit --serviceaccount=flink-dev:default
# 查看绑定信息
kubectl get clusterrolebinding flink-role-binding-flink-dev -o wide在使用flink on kubernetes相关部署模式提交作业的时候,若未配置好上述RBAC权限,则会出现下面的问题
io.fabric8.kubernetes.client.KubernetesClientException: pods is forbidden: User "system:serviceaccount:XXX:XXXX" cannot watch resource "pods" in API group "" in the namespace "XXX"
2.1.4 下载streampark
- 本次以2.0.0版本为例 https://www.apache.org/dyn/closer.lua/incubator/streampark/2.0.0/apache-streampark_2.12-2.0.0-incubating-bin.tar.gz
- 其他版本下载地址 https://dlcdn.apache.org/incubator/streampark/
2.2 解压安装包
# 解压
tar -zxvf apache-streampark_2.12-2.0.0-incubating-bin.tar.gz
# 移动streampark至/usr/local
mv apache-streampark_2.12-2.0.0-incubating-bin /usr/local/
# 建立软连接
ln -s apache-streampark_2.12-2.0.0-incubating-bin streampark2.3 初始化数据库/表
这里选择mysql数据源
# 数据库schema位置:
/usr/local/streampark/schema/mysql-schema.sql
# 数据库data位置:
/usr/local/streampark/data/mysql-data.sql
# 连接数据库,依次执行上述SQL文件即可2.4 StreamPark配置
配置文件位置: /usr/local/streampark/conf
2.4.1配置mysql数据源
vim application-mysql.yml
spring:
datasource:
username: 数据库用户名
password: 数据库用户密码
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://数据库IP地址:数据库端口号/streampark?useSSL=false&useUnicode=true&characterEncoding=UTF-8&allowPublicKeyRetrieval=false&useJDBCCompliantTimezoneShift=true&useLegacyDatetimeCode=false&serverTimezone=GMT%2B82.4.2 配置应用端口、数据库类型、工作空间等
vim application.yml
主要修改项如下:
server.port=10006 # 10000端口可能会跟其他组件默认端口冲突,比如hive
spring.profiles.active: mysql #[h2,pgsql,mysql]
local: /opt/streampark_workspace
remote: hdfs://hdfscluster/streampark #如果不是采用flink on yarn相关部署模式(yarn-session、yarn-per-job、yarn-application),可忽略此配置2.4.3 配置kerberos.yml
如果不是采用flink on yarn相关执行模式,可忽略此步
vim kerberos.yml
security.kerberos.login.enable=true
security.kerberos.login.principal=实际的principal
security.kerberos.login.krb5=/etc/krb5.conf
security.kerberos.login.keytab=实际的keytab文件
java.security.krb5.conf=/etc/krb5.conf在使用flink on yarn相关部署模式创建作业的过程中,经常会碰到下面的问题
Hadoop environment initialization failed, please check the environment settings
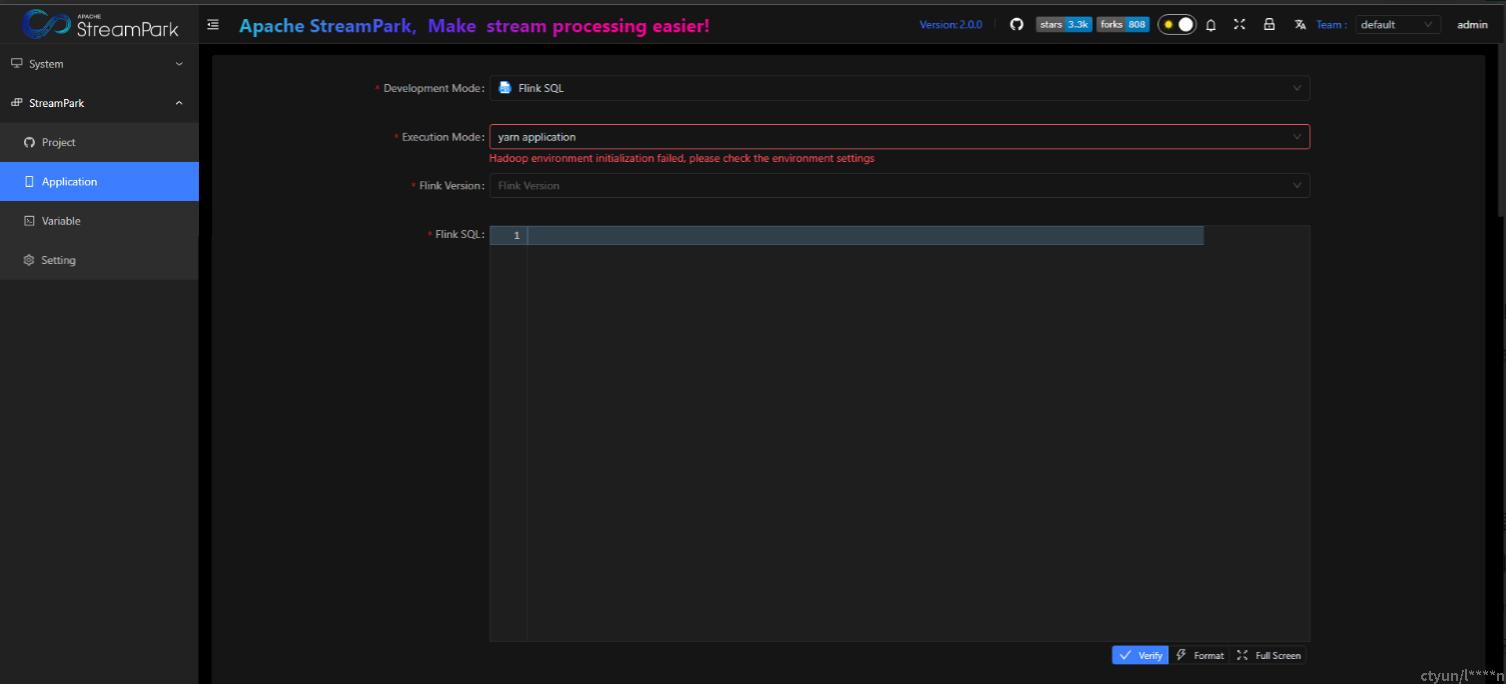
解决思路:如果hadoop集群正常,则看下集群是否开启了kerberos,若开启则需要配置kerberos.yml
2.4.4 引入mysql驱动包
由于Apache 2.0许可与Mysql Jdbc驱动许可的不兼容,用户需要自行下载驱动jar包并放在 $STREAMPARK_HOME/lib 中
下载:https://repo.maven.apache.org/maven2/mysql/mysql-connector-java/
2.5 启动
# 启动
cd /usr/local/streampark/bin
bash startup.sh
# 查看日志(日志中无报错信息,则说明启动成功)
tail -100f log/streampark.out出现以下标志 && 查看日志无报错信息,则说明启动成功
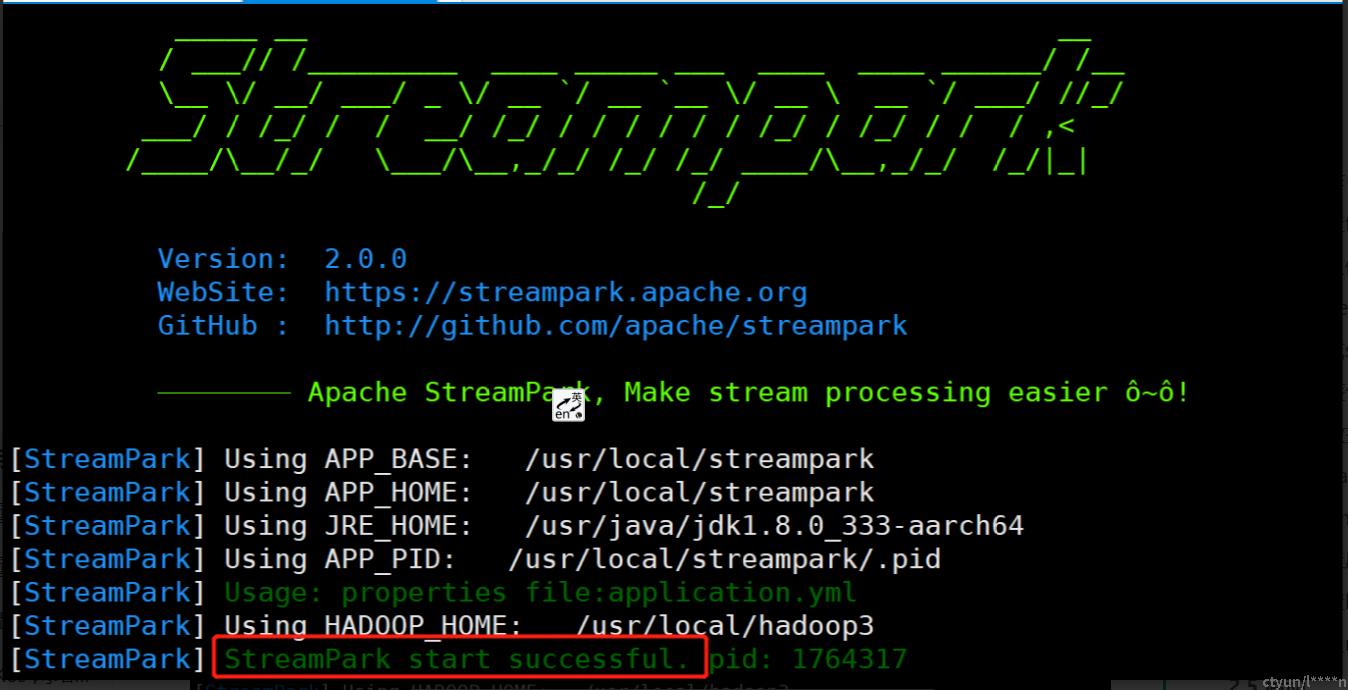
2.6 访问web
# 若访问ok,页面正常打开,则说明部署成功。
http://streampark服务IP:10006/
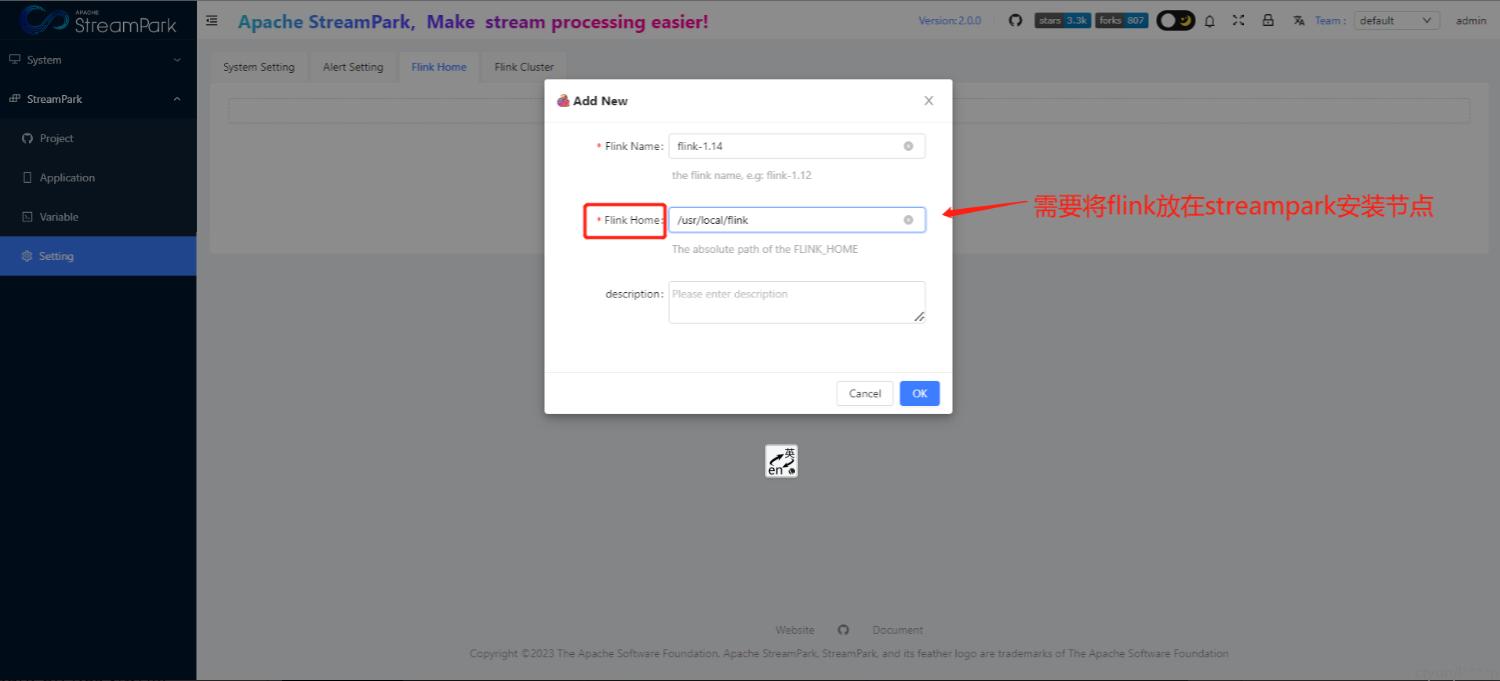
admin/streampark2.6.1 在StreamPark中配置flink
菜单位置:StreamPark-->Setting-->Flink Home-->+ Add New
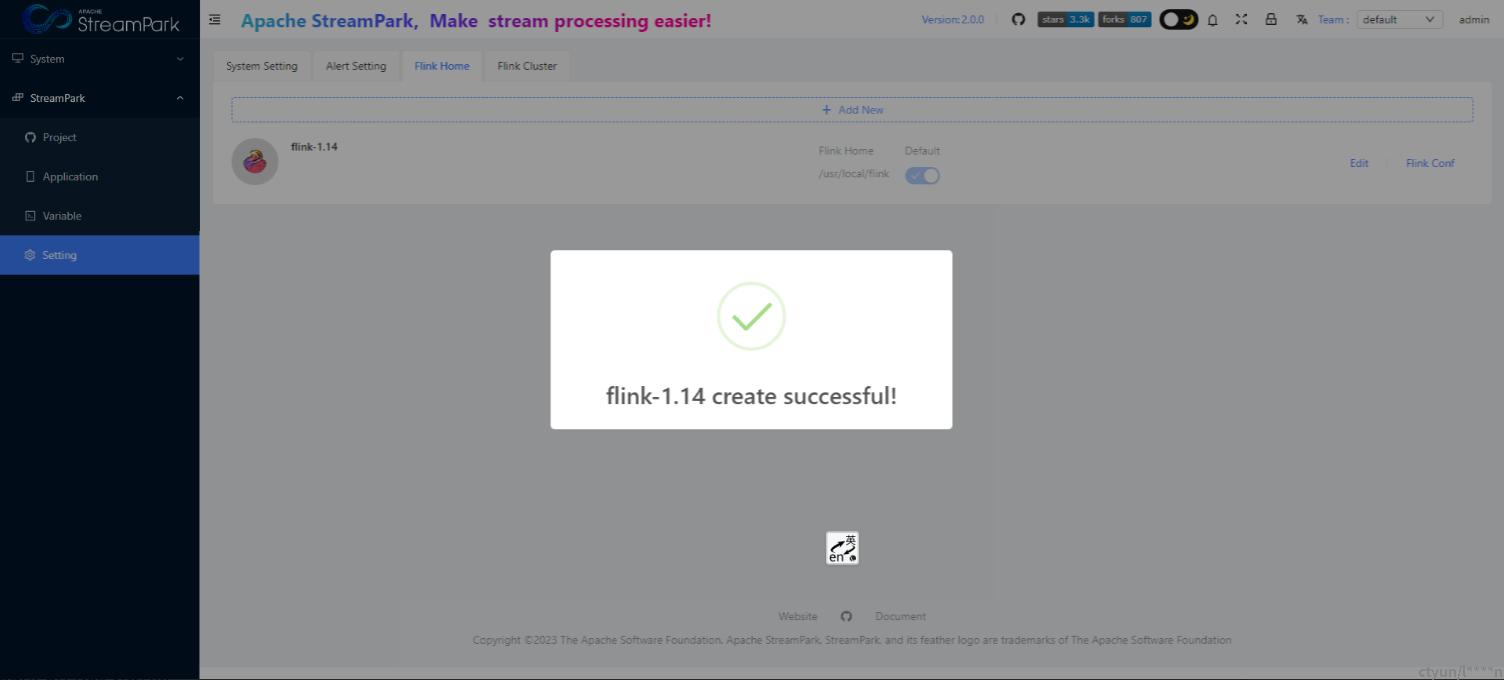
3、StreamPark作业管理流程

上述流程均可在页面操作,无需一般用户关注具体的执行逻辑,如下
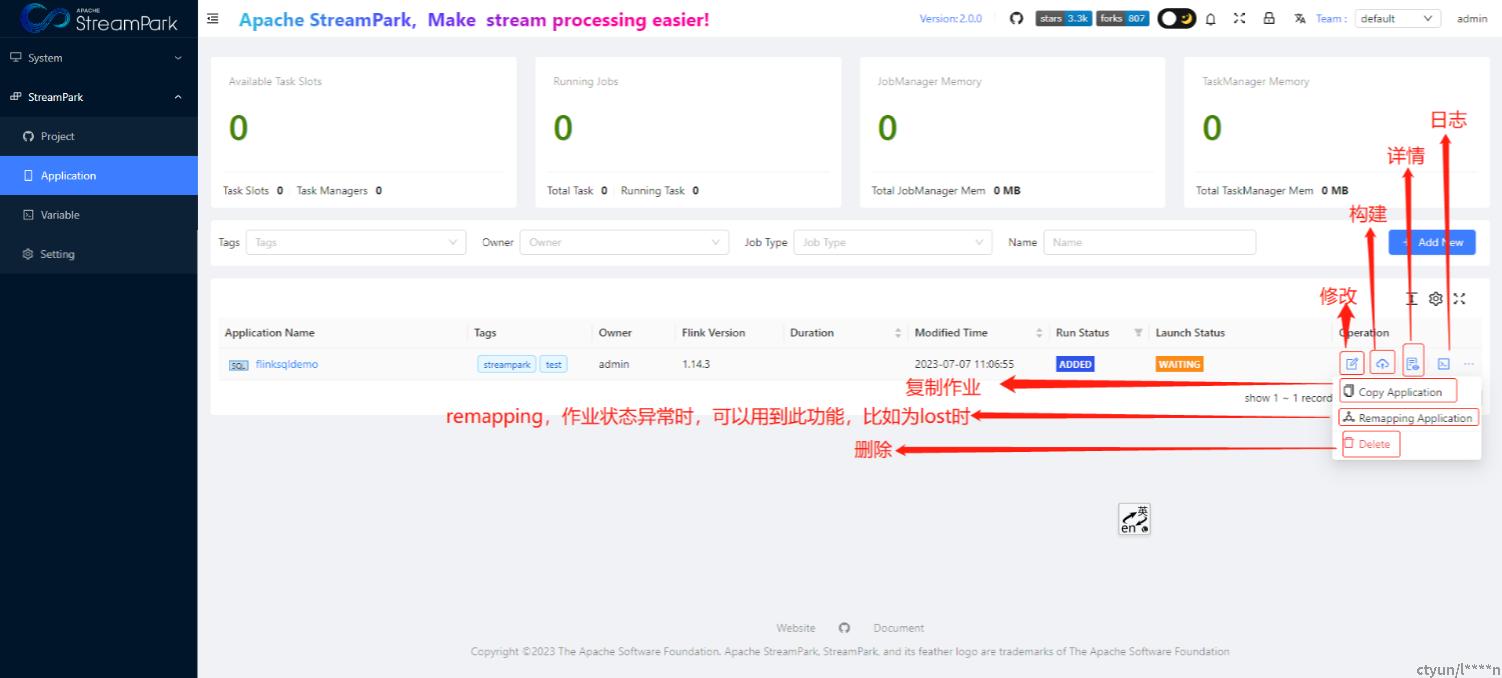
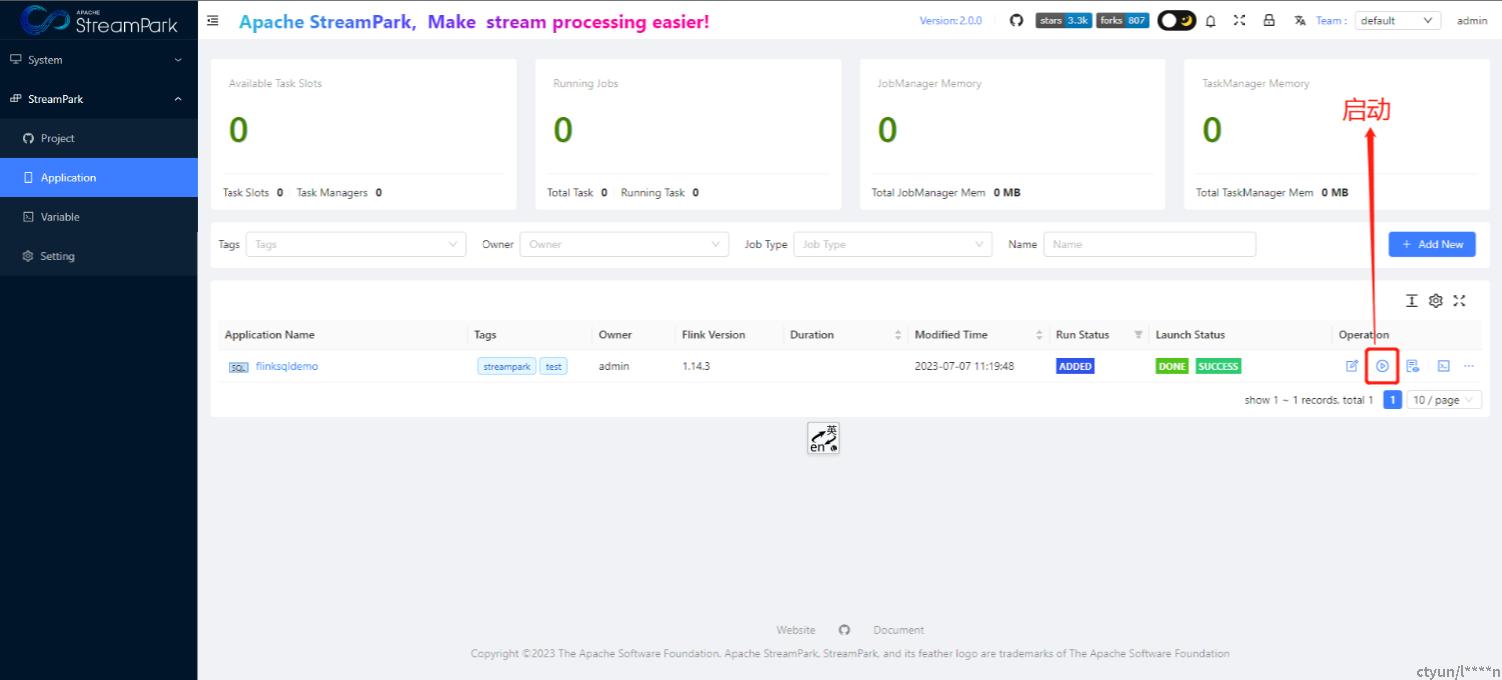
构建作业
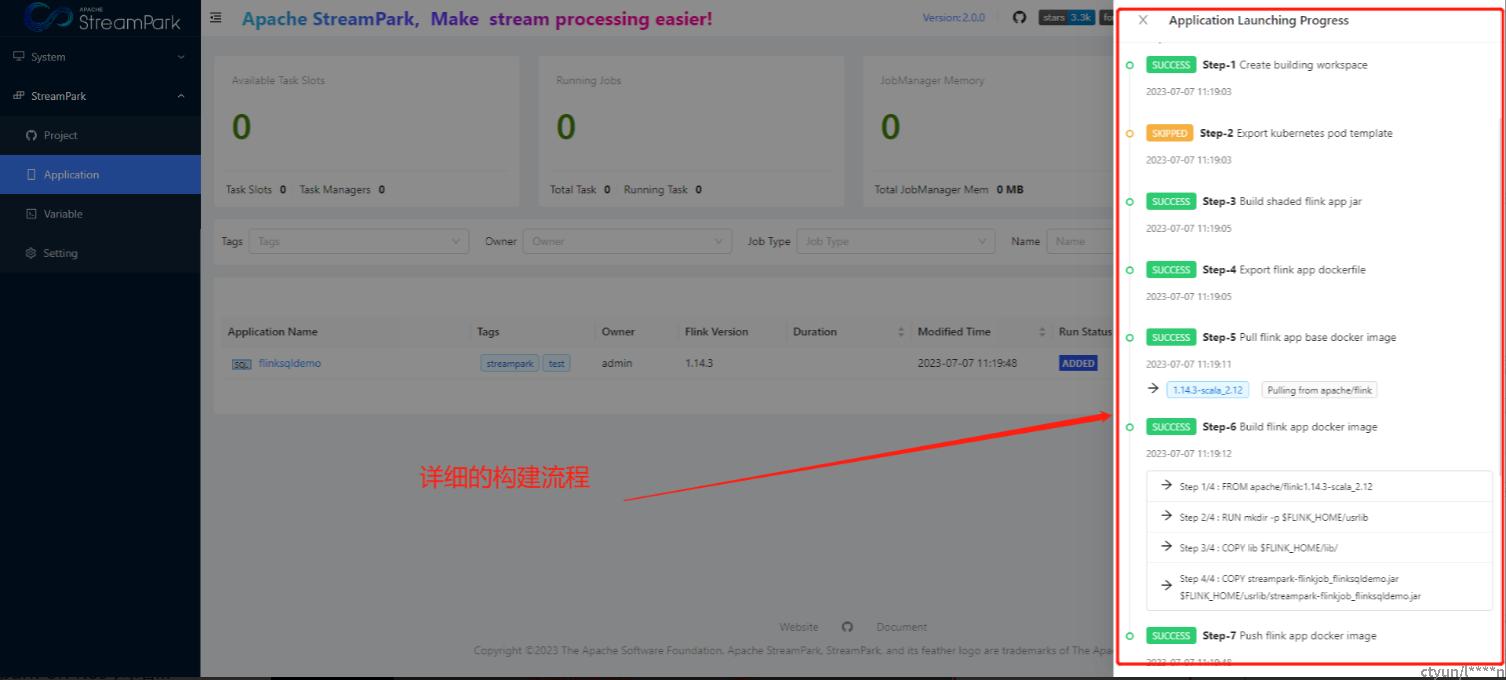
日志信息
注意:目前日志信息查看仅支持flink on k8s相关模式。
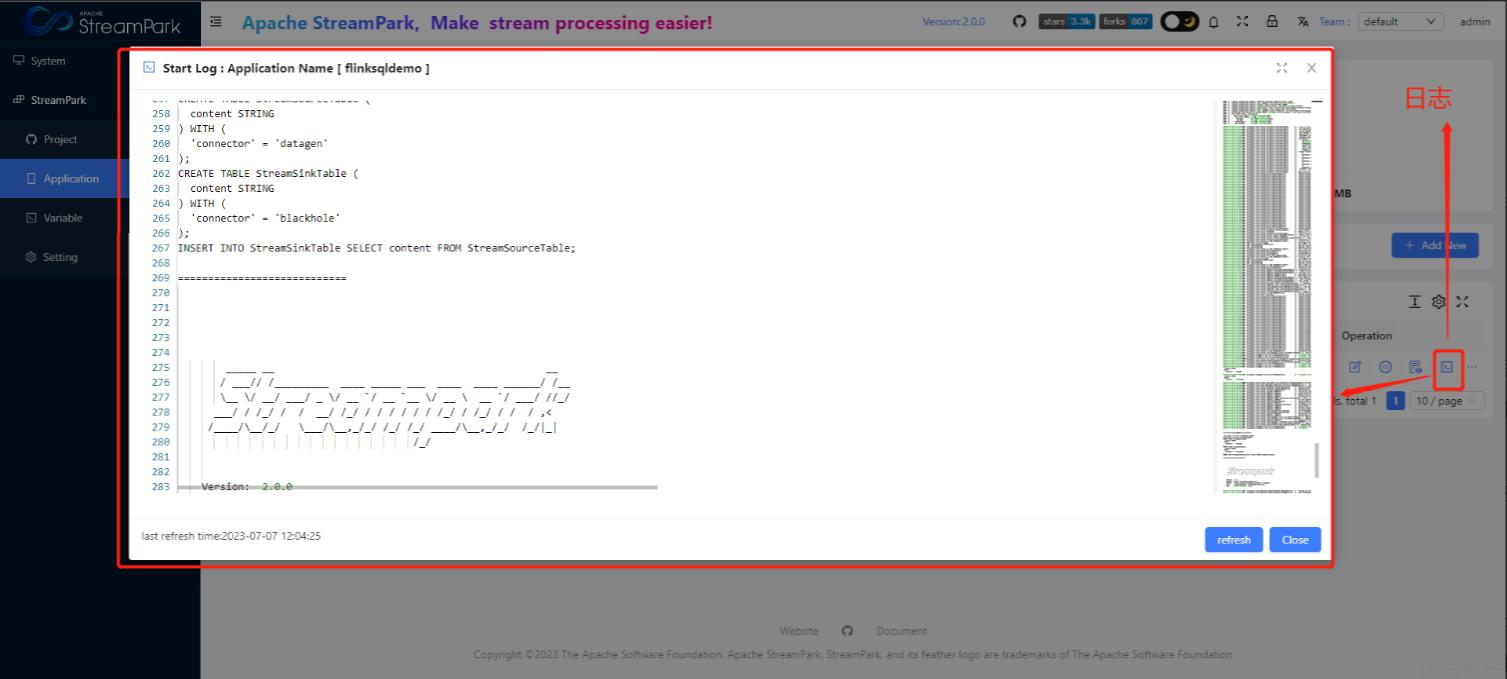
资源监控信息
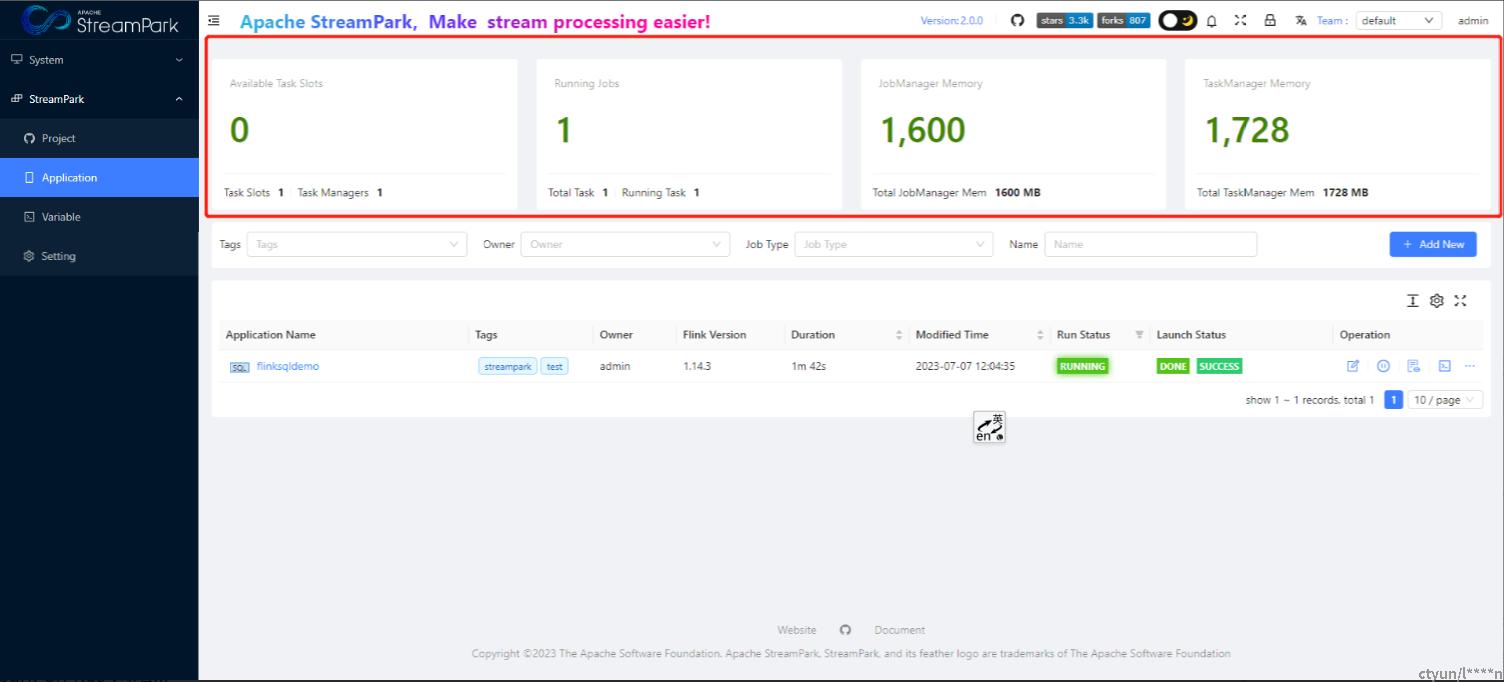
4、案例
4.1 SQL案例
4.1.1 datagen to blackhole
drop table if exists StreamSourceTable;
drop table if exists StreamSinkTable;
CREATE TABLE StreamSourceTable (
content STRING
) WITH (
'connector' = 'datagen'
);
CREATE TABLE StreamSinkTable (
content STRING
) WITH (
'connector' = 'blackhole'
);
INSERT INTO StreamSinkTable SELECT content FROM StreamSourceTable;4.1.2 datagen to print
drop table if exists StreamSourceTable;
drop table if exists StreamSinkTable;
CREATE TABLE StreamSourceTable (
content STRING
) WITH (
'connector' = 'datagen'
);
CREATE TABLE StreamSinkTable (
orgin STRING,
md5 STRING
) WITH (
'connector' = 'print'
);
INSERT INTO StreamSinkTable SELECT content,MD5(content) FROM StreamSourceTable;4.2 Remote模式
这里以standalone-session为例说明,yarn-session和kubernetes-session比较类似:
- yarn-session: https://nightlies.apache.org/flink/flink-docs-release-1.14/docs/deployment/resource-providers/yarn/#session-mode
- kubernetes-session: https://nightlies.apache.org/flink/flink-docs-release-1.14/docs/deployment/resource-providers/native_kubernetes/#session-mode
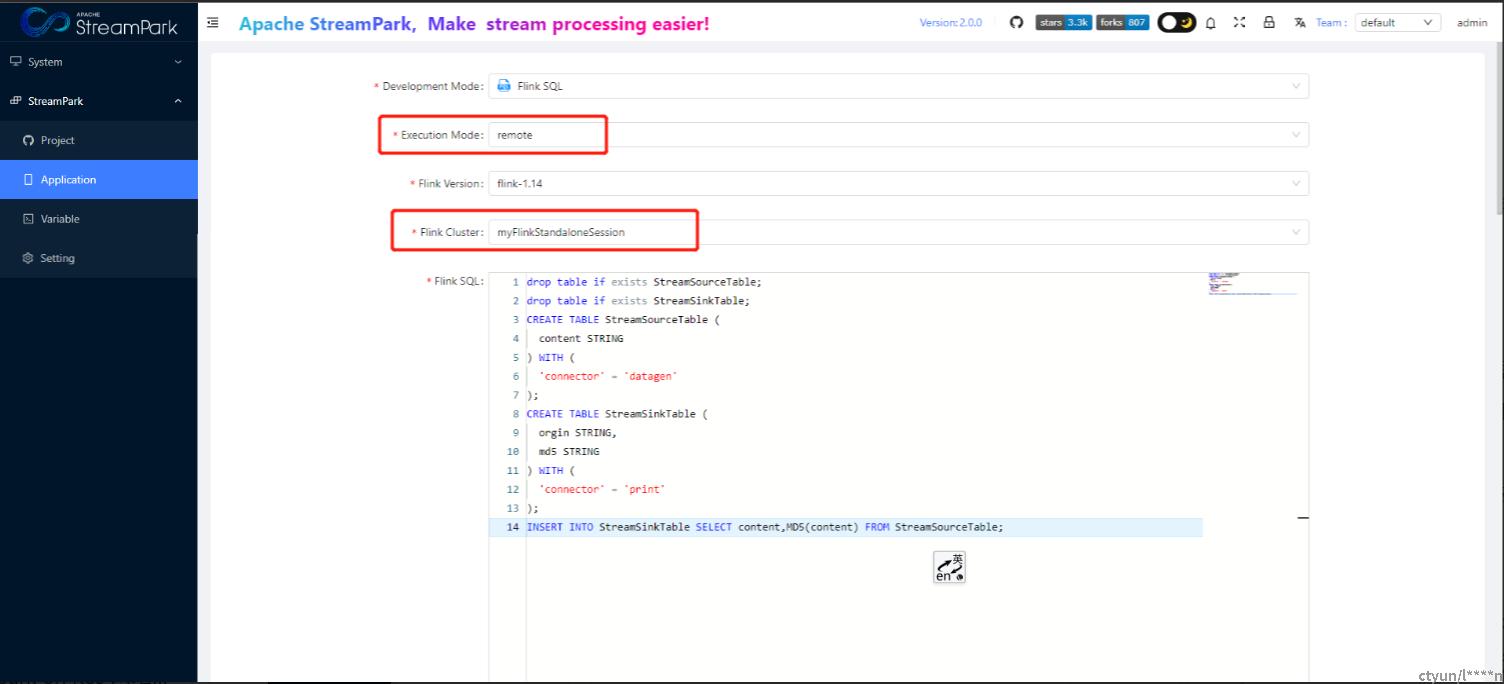
菜单位置:StreamPark-->Setting-->Flink Cluster-->+ Add New
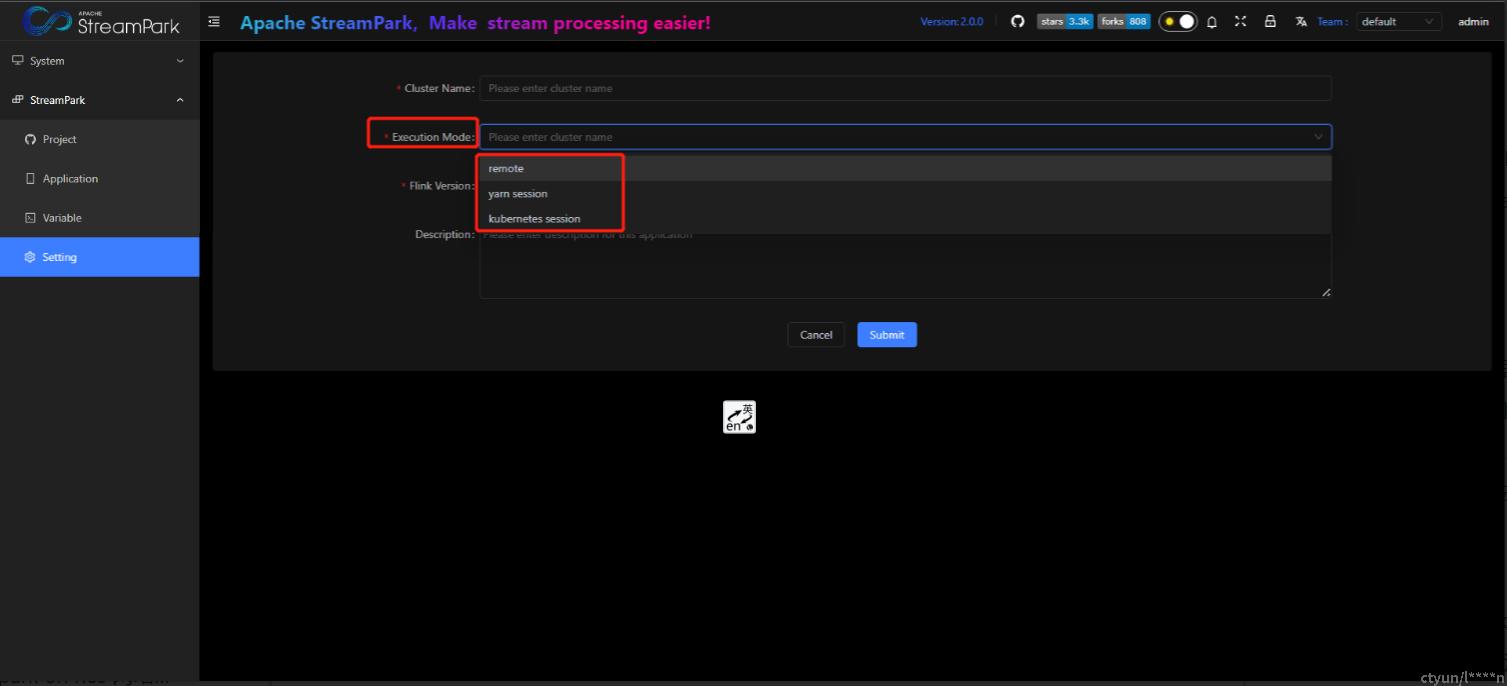
4.2.1 启动 flink standalone session集群
cd /usr/local/flink/bin
bash start-cluster.sh
【可选】测试服务是否正常
curl localhost:8081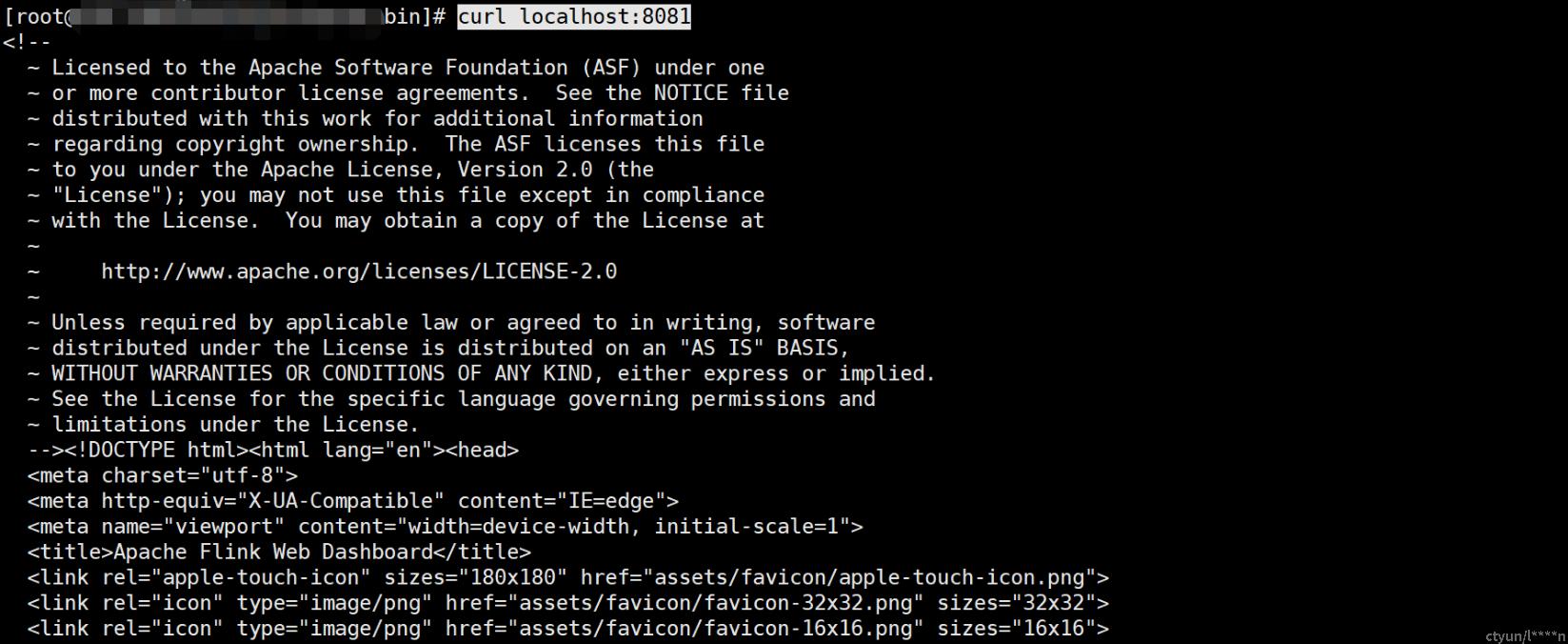
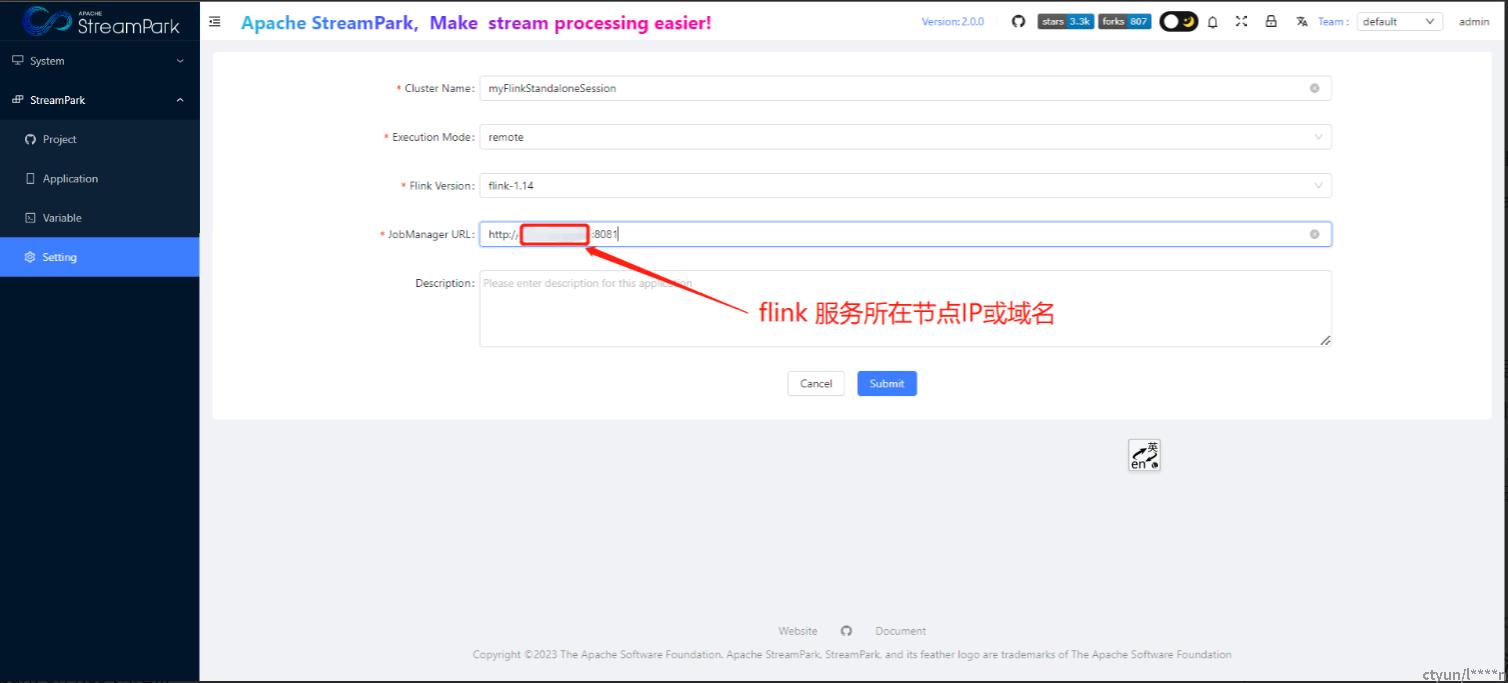
4.2.2 StreamPark配置flink cluster
菜单位置:StreamPark-->Setting-->Flink Cluster-->+ Add New

4.2.3 创建作业
4.2.4 构建作业

4.2.5 启动作业
说明: 该步骤目前强依赖3.1.4

作业首次启动,可不用关注检查点
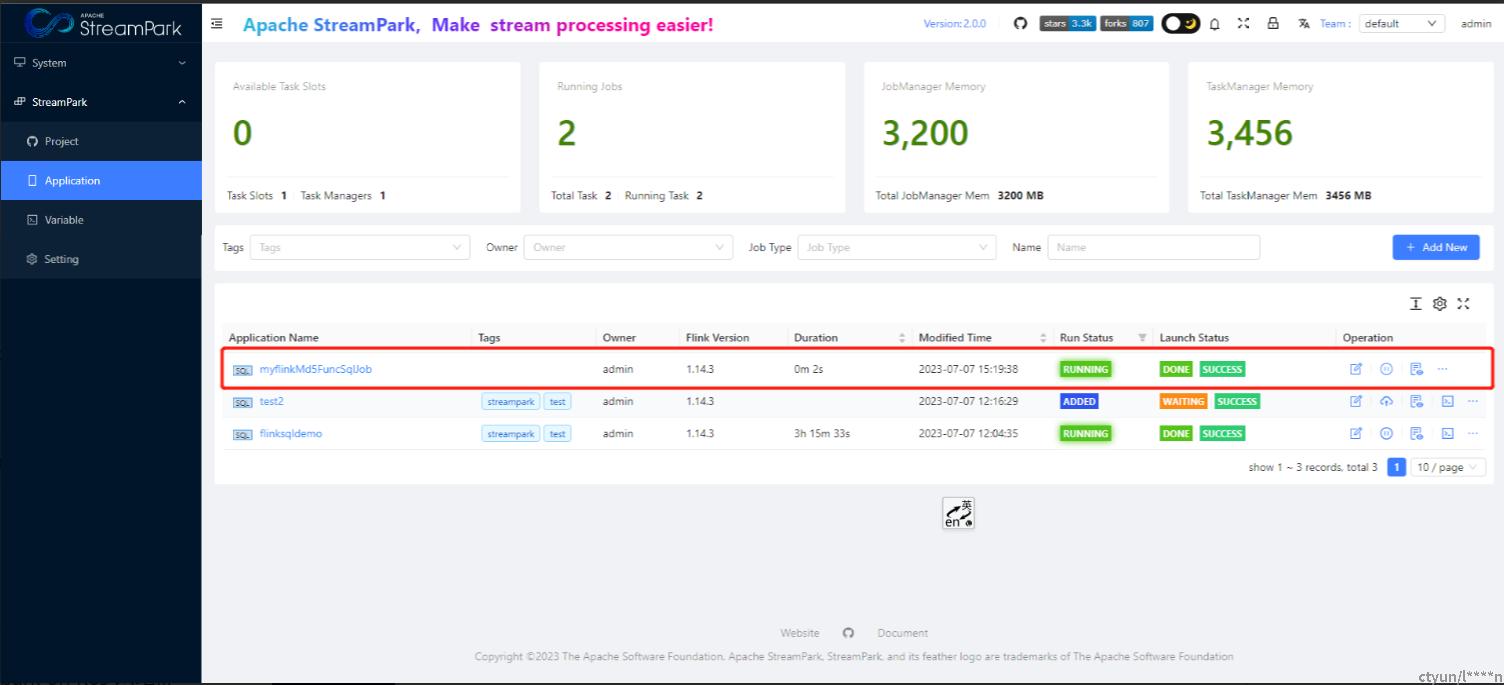
【可选】验证作业是否启动

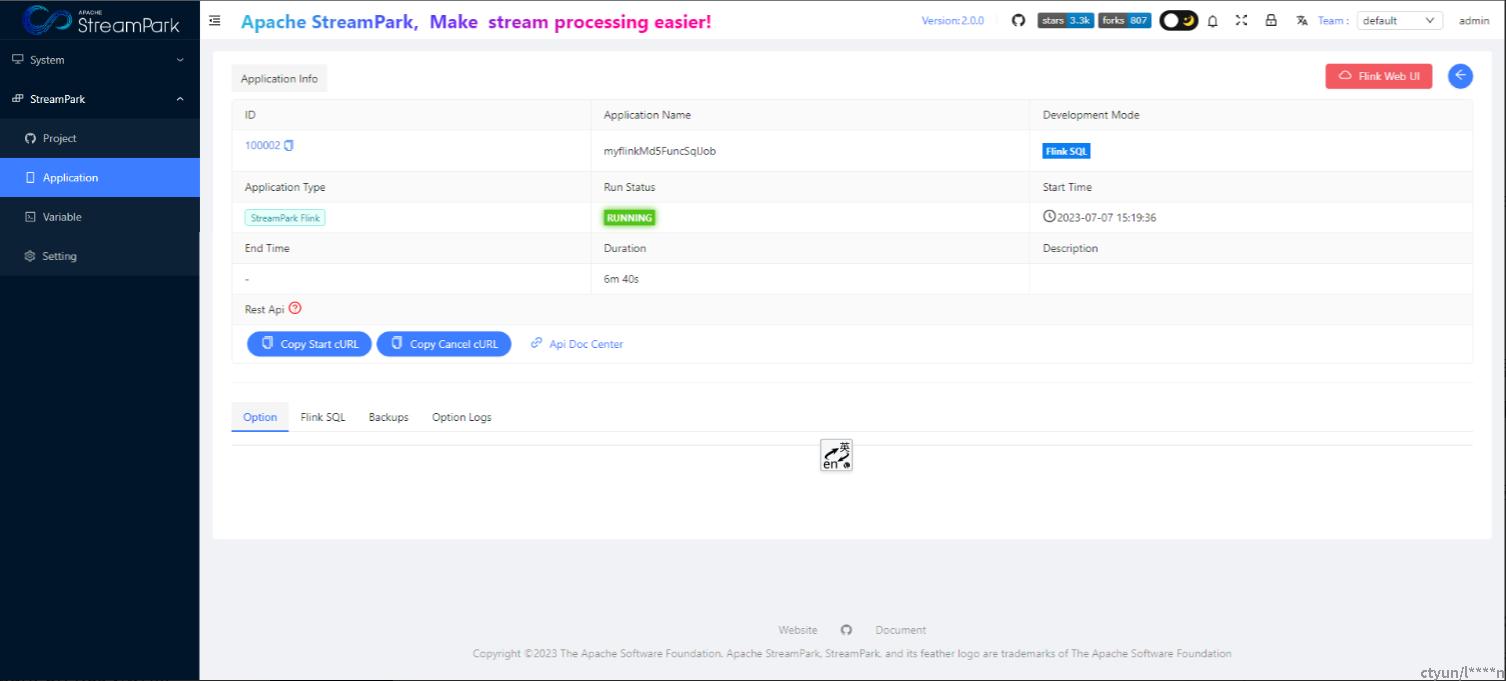
4.2.6 查看作业详情
4.2.7 停止作业
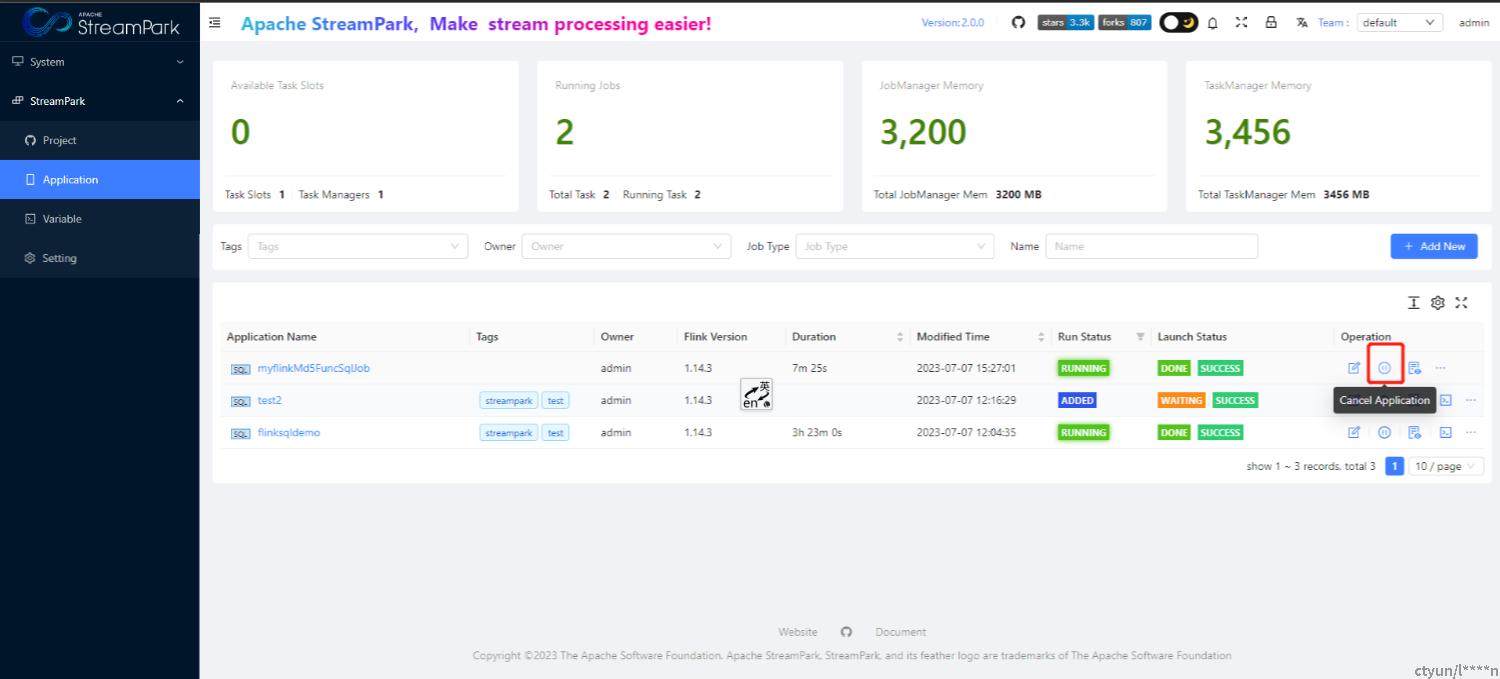
设置检查点
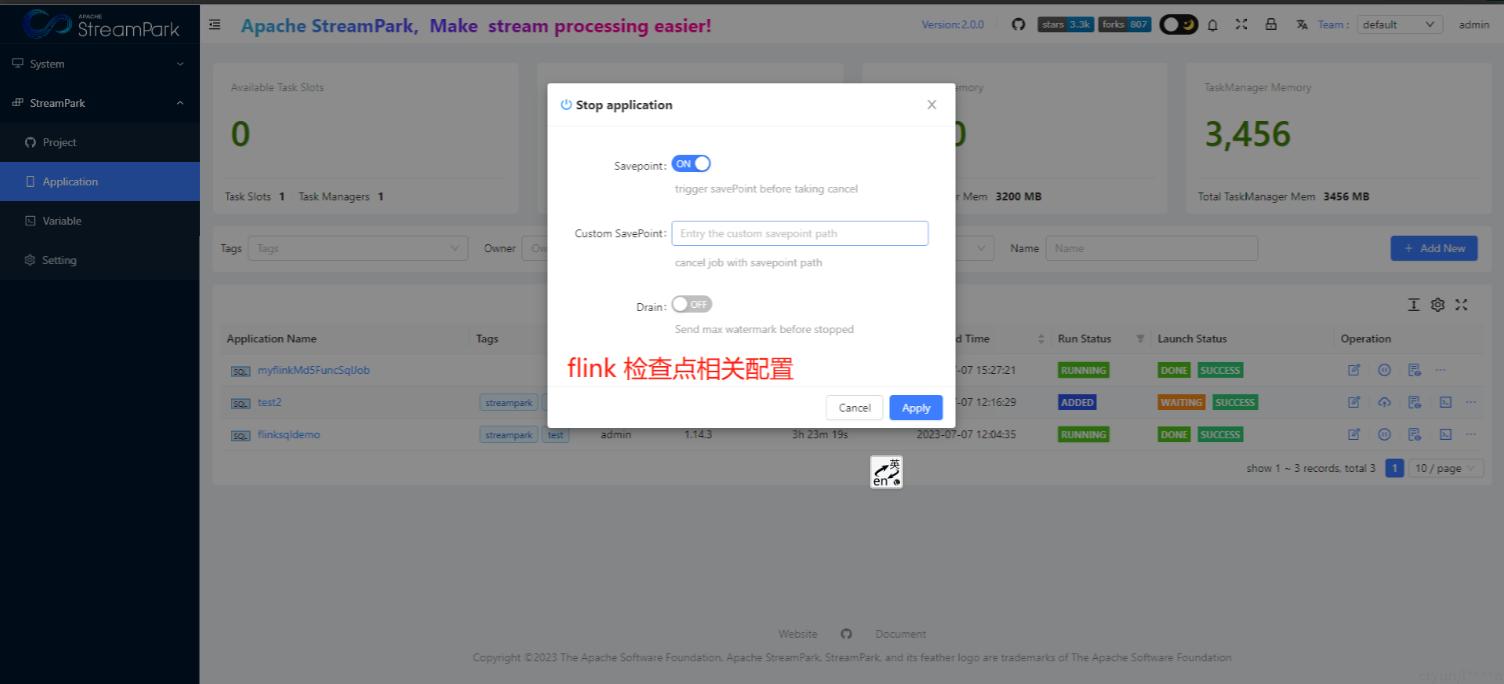
作业停止

【可选】验证作业是否真正停止

4.3 native kubernetes application模式
4.3.1 前置依赖
- StreamPark所在服务器须要有正常的kubernetes和docker服务;
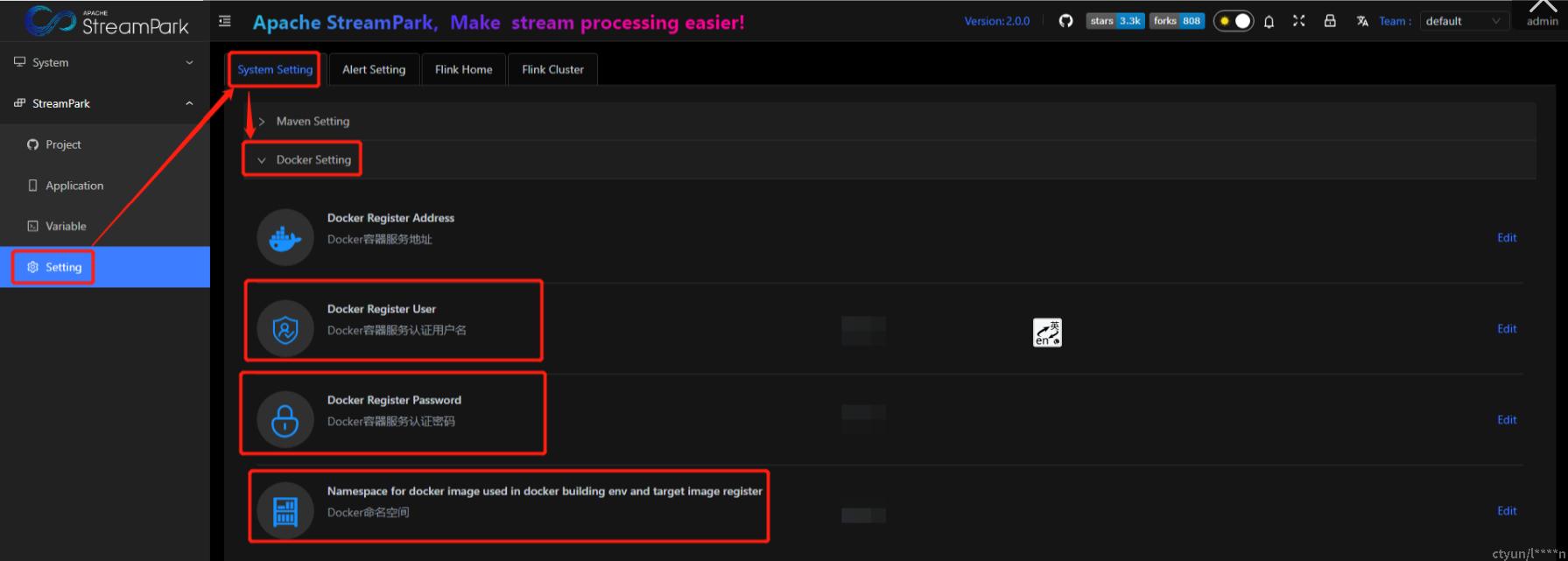
- 注册docker镜像仓库账户,详见 https://hub.docker.com/signup,若有账户则可忽略此步
- StreamPark中配置docker信息
4.3.3 与Remote模式使用区别
通过StreamPark管理native k8s app模式的flink作业流程, 与Remote模式管理作业流程基本一致,只是在作业创建时,有如下区别:
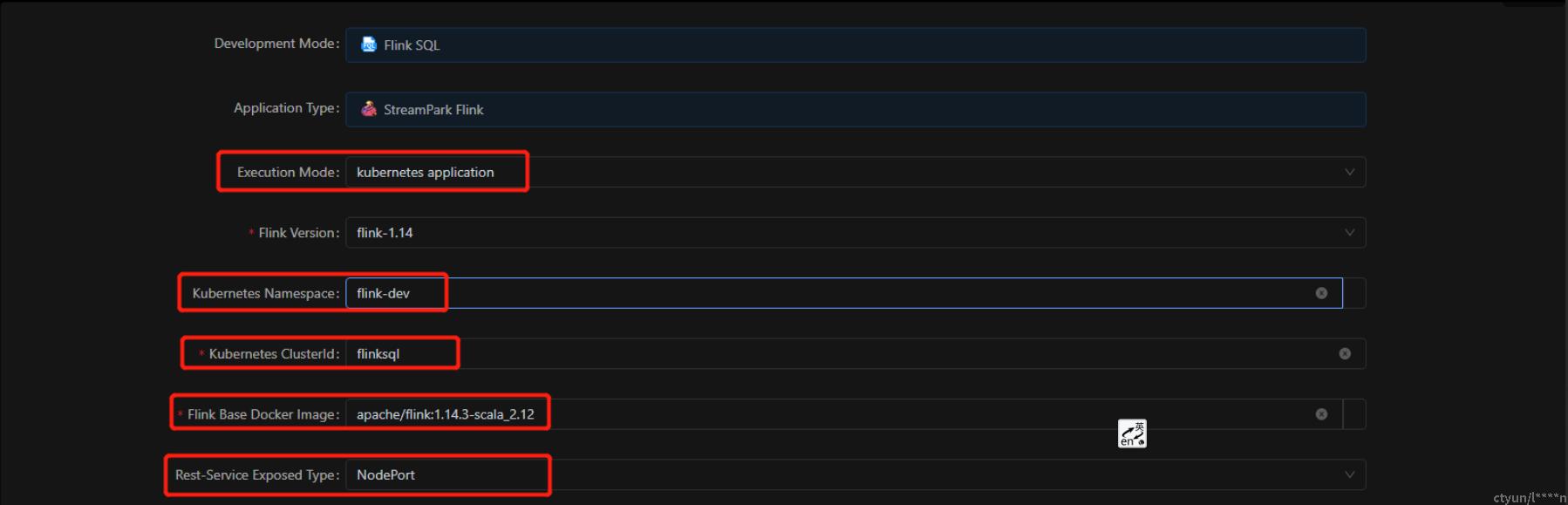
- Execution Mode:kubernetes application
- Kubernetes Namespace:作业需要提交的命名空间
- Kubernetes ClusterId:flink 集群ID,目前在该模式下,clusterId的值会同步至"Application Name"
- Flink Base Docker Image:flink作业需要的基础镜像
- Rest-Service Exposed Type:flink任务集群rest服务暴漏方式,详见:https://nightlies.apache.org/flink/flink-docs-master/docs/deployment/resource-providers/native_kubernetes/#accessing-flinks-web-ui
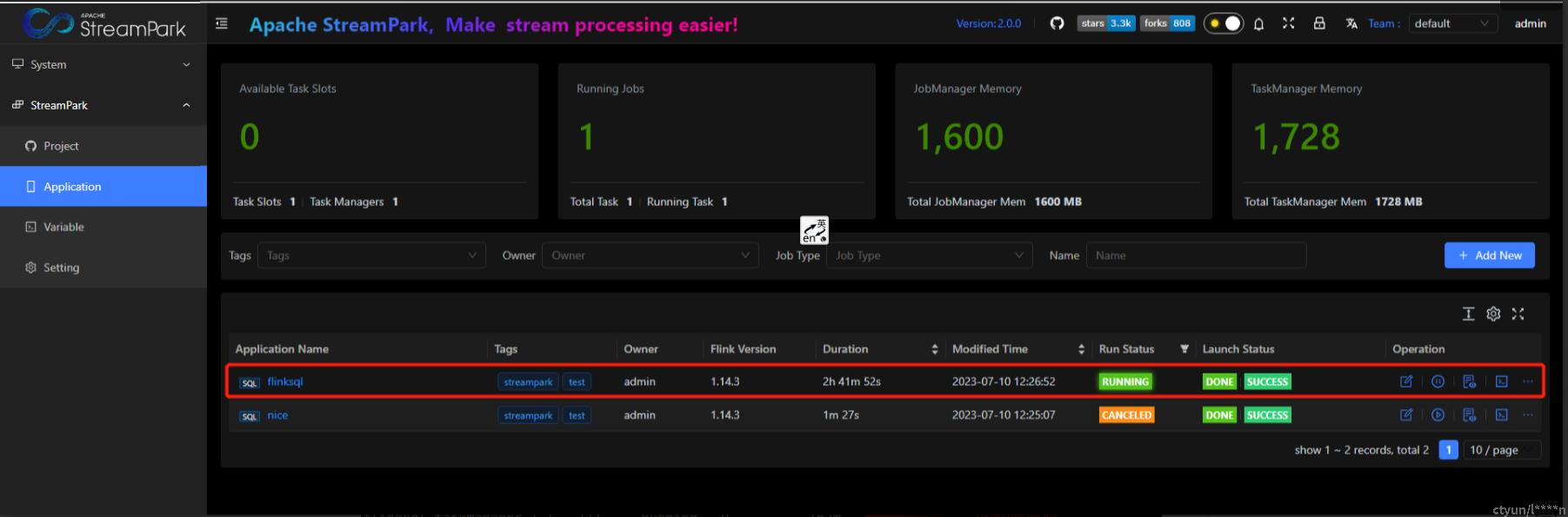
验证flink作业是否正常提交

yarn-application、yarn-per-job部署模式可以参考上述流程。
4.4 JAR类型作业
JAR类型作业,在使用流程方面,与SQL类似,如下:
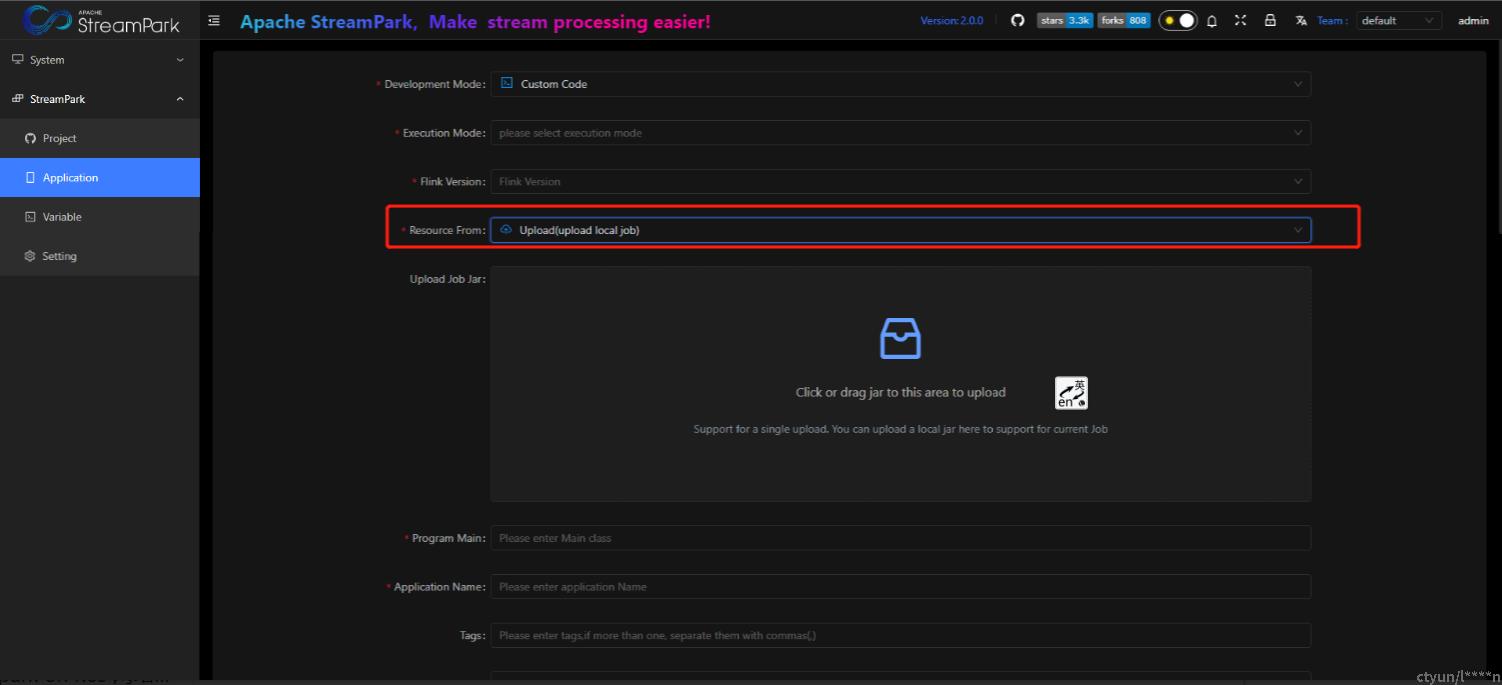
- Development Mode

- Resource From
一个是通过CICD构建的JAR,一个是本地构建的JAR,根据实际情况选择。为了方便说明,这里就选择Upload.
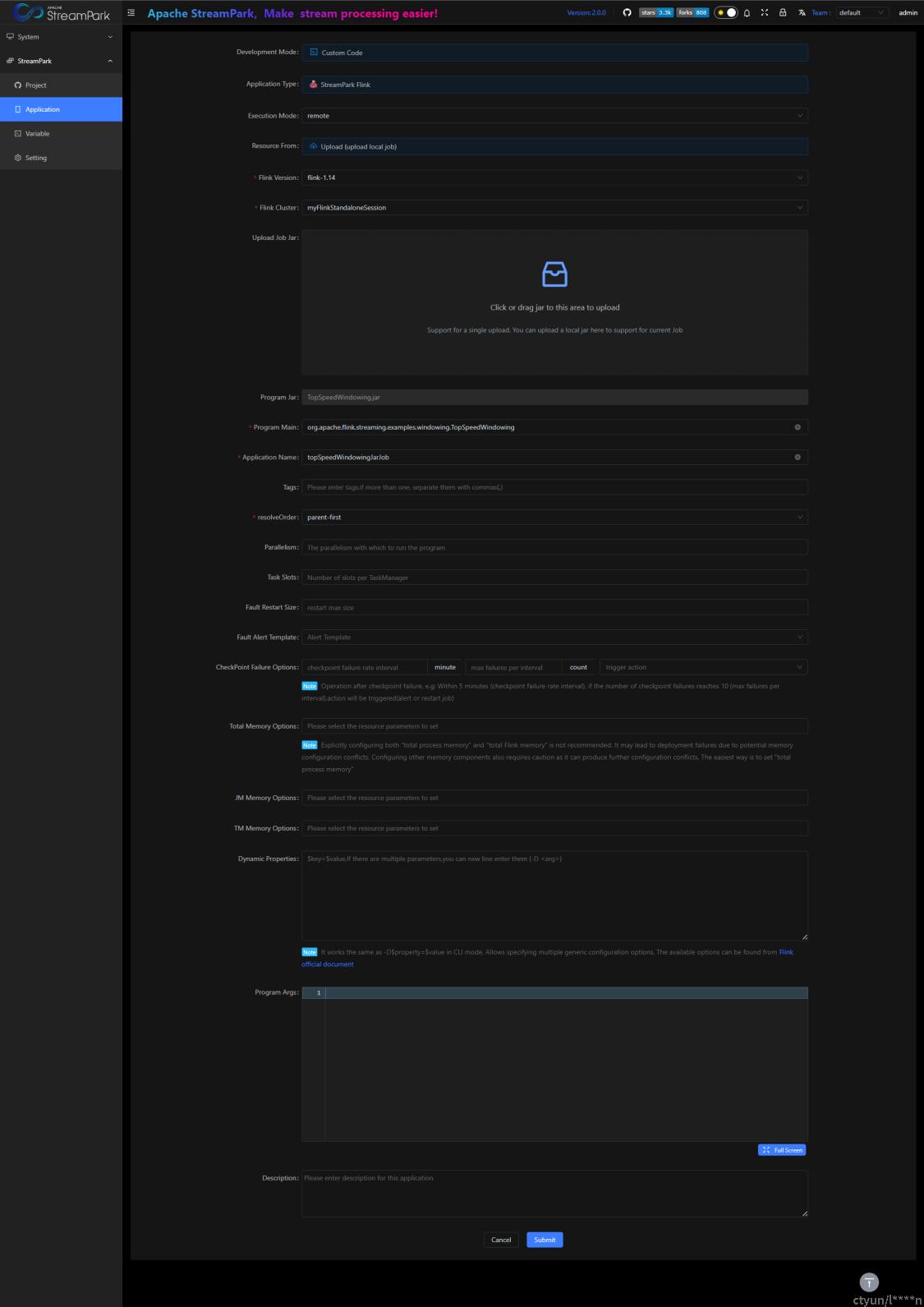
- Program Main
JAR文件的入口类全称
- 示例
这里使用flink官方提供的案例 TopSpeedWindowing.jar
JAR所在位置:$FLINK_HOME/examples/streaming/TopSpeedWindowing.jar
Program Main:org.apache.flink.streaming.examples.windowing.TopSpeedWindowing

5、问题排查思路
使用过程中,由于环境、组件版本、部署模式等方面因素的影响,可能会遇到一些问题,所以跟大家分享下常规的排查思路
- 确认作业配置是否正确;
- 确认集群(standalone/hadoop/kubernetes)状态是否正常;
- 若集群状态正常,则在集群环境使用flink原生命令,测试作业是否可以正常提交;
- 若上述步骤都正常仍存在问题,可以通过issue的方式向社区反馈,建议描述的时候带一些关键信息,如:部署模式、组件版本、问题现象(截图、日志)等。
