在ceph的rgw中,用户数据上传通常有两种常见的方式:
原子上传:这是最基本的对象上传方式。用户直接将完整的对象数据一次性上传到 RGW。客户端向 RGW 发送一个 PUT 请求,携带完整对象的数据,RGW 将该对象数据写入到指定的存储桶中。
分段上传:这种方式主要用于大文件上传和断点续传等场景。这种方式允许用户将大型对象分割成较小的部分(段或块),并分段上传到 RGW。用户先初始化分段上传会话,然后将每个段逐个上传到 RGW。最后,用户完成分段上传,RGW 将合并所有段形成完整的对象。
用户上传的数据,rgw将数据存储在{zone}.rgw.buckets.data这个pool中,其中"{zone}" 是 RGW 的区域(Zone)名,用于区分不同的 RGW 实例或区域。当用户上传对象到 RGW 存储桶时,对象数据将被分割为多个数据块,并分布在 Ceph 存储集群中的不同 OSD(Object Storage Daemon)上。所以一个RGW对象包含一个或多个rados对象。

既然用户的一个对象会被rgw切分成多个数据块进行存储,那么切分的数据块大小为多少呢,rgw又是如何管理用户的rgw对象和底层rados多个对象之间的对应关系?
在介绍这部分之前,我们先介绍另外的几个参数,这些参数涉及到数据分块的大小chunk_size,底层rados中实际对象数据的大小stripe_size,以及用户层对象和底层rados对象之间的对应关系manifest:
-
rgw_max_chunk_size
改宏值表示RGW下发到RADOS集群单个IO的大小,同时决定应用对象分成多个rados对象时首对象的大小,简称分块。
-
rgw_obj_stripe_size
该宏值用来指定当一个对象被分成多个RADOS对象的时候中间对象的大小,简称条带大小。
-
Class RGWObjManifest > 管理用户上传的对象和RADOS对象的对应关系,简称manifest
-
alignment
对象对齐是指对象数据在存储设备上的对齐边界。对齐边界是存储系统用于优化性能和效率的概念。通过将对象的起始位置对齐到特定的边界,可以提高读取和写入数据的效率,减少存储设备的随机访问和碎片化。对于 Ceph RGW 的数据池,默认的对象对齐大小是 4MB。这意味着每个对象的起始位置将被对齐到 4MB 的边界。如果对象的大小不是 4MB 的整数倍,那么对象将占用更多的存储空间来满足对齐要求。
需要注意的是,默认的对象对齐大小可能会根据不同的 Ceph 版本和配置而有所不同。如果您有特定的需求,可以通过配置参数进行调整,以适应特定的应用场景和性能要求。
通常数据分块的大小chuck_size是由配置文件中的rgw_max_chunk_size和pool中的alignment一起共同确定。而底层存储的rados对象大小stripe_size由配置文件中的rgw_obj_stripe_size和pool的alignment一起共同确定。默认的rgw_max_chunk_size,rgw_obj_stripe_size,alignment都是4M。
chunk_size是指每个分块(Chunk)的大小。从代码阅读上看,用户在上传数据过程中,rgw从网络中循环读取数据,一次最多也是读取<=chunk_size的大小。同时每次rgw发送给rados的数据,一次最多也是<=chunk_size的大小。
针对PUT方式上传的数据,最后数据的主要处理流程和其他的OP操作类似,PUT上传落在了类RGWPutObj::execute()函数中。所以我们先着重看一下这个类函数的流程:
void RGWPutObj::execute()
{
...
// create the object processor
//aio 主要用于控制异步IO操作速率的
rgw::AioThrottle aio(store->ctx()->_conf->rgw_put_obj_min_window_size);
using namespace rgw::putobj;
constexpr auto max_processor_size = std::max({sizeof(MultipartObjectProcessor),
sizeof(AtomicObjectProcessor),
sizeof(AppendObjectProcessor)});
ceph::static_ptr<ObjectProcessor, max_processor_size> processor;
//三种上传对象的方式,分片上传,原子上传,append追加上传
rgw_placement_rule *pdest_placement;
multipart_upload_info upload_info;
if (multipart) {//分片上传,S3的接口,默认切割大小是15M(可以修改)
RGWMPObj mp(s->object.name, multipart_upload_id);
//读取之前初始化分片上传过程中写入的对象数据,获取upload_info信息
op_ret = get_multipart_info(store, s, mp.get_meta(), nullptr, nullptr, &upload_info);
pdest_placement = &upload_info.dest_placement;
processor.emplace<MultipartObjectProcessor>(
&aio, store, s->bucket_info, pdest_placement,
s->owner.get_id(), obj_ctx, obj,
multipart_upload_id, multipart_part_num, multipart_part_str);
} else if(append) {//追加上传
...
} else {//原子上传
pdest_placement = &s->dest_placement;//存储策略
processor.emplace<AtomicObjectProcessor>(
&aio, store, s->bucket_info, pdest_placement,
s->bucket_owner.get_id(), obj_ctx, obj, olh_epoch, s->req_id);
}
op_ret = processor->prepare();//正式上传之前,进行一些初始化操作
// no filters by default
DataProcessor *filter = processor.get();
do {
bufferlist data;
len = get_data(data);//读取上传的数据
op_ret = filter->process(std::move(data), ofs);//将收到的数据进行处理
ofs += len;
} while (len > 0);
// flush any data in filters
op_ret = filter->process({}, ofs);//处理最后的数据,把尾部数据写入到rados中去
s->obj_size = ofs;//收到的对象数据大小
op_ret = do_aws4_auth_completion();
//限额校验
op_ret = store->check_quota(s->bucket_owner.get_id(), s->bucket,
user_quota, bucket_quota, s->obj_size);
//桶对象索引更新,因为zone.rgw.buckets.index这个pool种存储了bucket中的对象索引,如果桶中的对象过多,就需要碎片化
op_ret = store->check_bucket_shards(s->bucket_info, s->bucket, bucket_quota);
//写完成,在complete中需要写first_chunk以及meta
op_ret = processor->complete(s->obj_size, etag, &mtime, real_time(), attrs,
(delete_at ? *delete_at : real_time()), if_match, if_nomatch,
(user_data.empty() ? nullptr : &user_data), nullptr, nullptr);
// send request to notification manager
const auto ret = rgw::notify::publish(s, obj.key, s->obj_size, mtime, etag, rgw::notify::ObjectCreatedPut, store);
}
其中写对象数据的过程:
processor->prepare();//正式上传之前,进行一些初始化操作
op_ret = filter->process(std::move(data), ofs);//将收到的数据进行处理
op_ret = filter->process({}, ofs);//处理最后的数据,把尾部数据写入到rados中去
op_ret = processor->complete(s->obj_size, etag, &mtime, real_time(), attrs,
(delete_at ? *delete_at : real_time()), if_match, if_nomatch,
(user_data.empty() ? nullptr : &user_data), nullptr, nullptr);
而上面的processor其实是一个AtomicObjectProcessor类对象,具体的代码细节这里不再阐述。下面主要介绍一下用户通过这种方式上传后的数据处理过程,以及数据在对象存储中的数据组织形式和存储结构。
当使用原子上传一个对象的时候:
-
如果该对象的数据大小<=max_chunk_size的时候,上传的对象对应一个rados对象,同时该rados对象的Name为用户上传的时候指定的对象名。
-
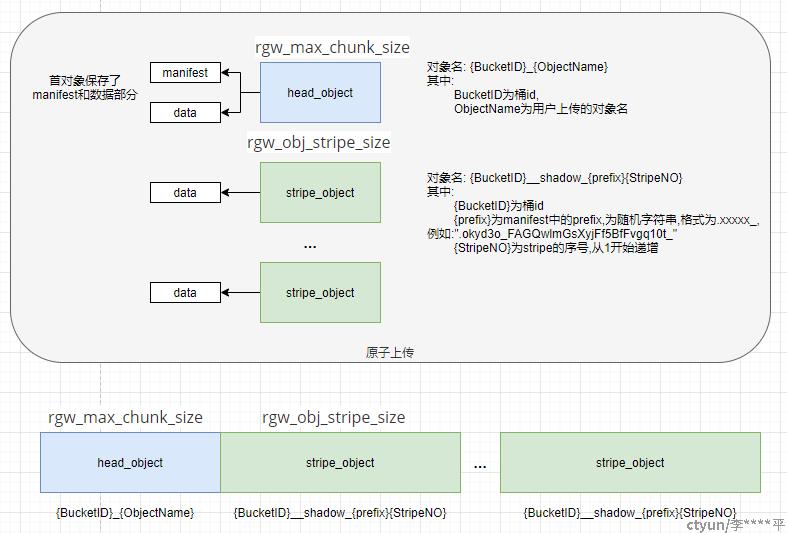
如果上传的对象数据大小>max_chunk_size的时候,上传的对象会被分解为一个大小等于max_chunk_size的首对象HeadObject,多个大小等于stripe_size的中间对象StripeObject,和一个小于等于stripe_size的尾对象StripeObject。其中首对象HeadObject除了保存数据部分,还保存了manifest和其他元数据信息。
他们的命名规则为:
HeadObject: {BucketID}_{ObjectName};
StripeObject: {BucketID}__shadow_{prefix}{StripeNO}
其中:
{BucketID}为桶id;
{ObjectName}为用户上传的对象名;
{prefix}为manifest中的prefix,为随机字符串,格式为.xxxxx_,例如:".okyd3o_FAGQwlmGsXyjFf5BfFvgq10t_";
{StripeNO}为stripe的序号,从1开始递增;
他们的数据组织形式和存储结构如下图所示: