


概述
HDFS开发主要是通过HDFS Client进行HDFS数据的读写。HDFS应用开发需要使用HDFS Client模块,Client主要包括三种方式:
- Java 提供HDFS文件系统的应用接口,使用Java API进行HDFS文件系统应用开发。
- Shell提供shell命令完成HDFS文件系统的基本操作。
- Kerberos控制应用程序采用密钥文件在盾山Hadoop产品中进行Kerberos安全认证。
本章仅介绍Java应用开发方式。
应用场景
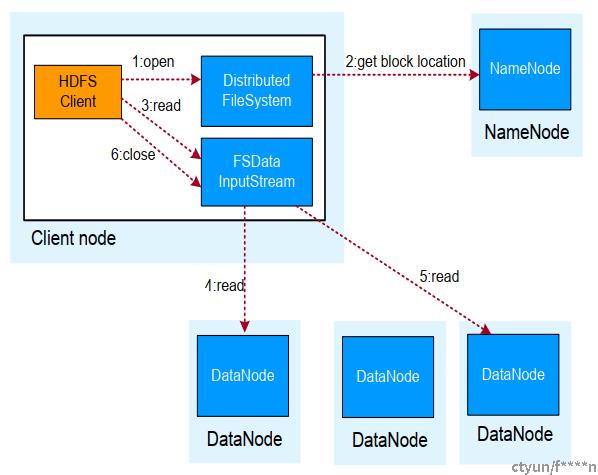
HDFS数据读取流程
- 业务应用调用HDFS Client提供的API打开文件。
- HDFS Client联系NameNode,获取到文件信息(数据块、 DataNode位置信息) 。
- 业务应用调用read API读取文件。
- HDFS Client根据从NameNode获取到的信息, 联系DataNode,获取相应的数据,(Client采用就近原则读取数据)。
- HDFS Client会与多个DataNode通讯获取数据块。
- 数据读取完成后, 业务调用close关闭连接
图 1‑1
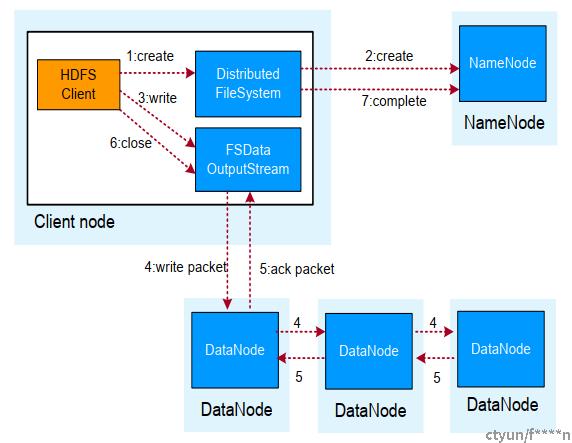
HDFS数据写入流程
- 业务应用调用HDFS Client提供的API创建文件,请求写入。
- HDFS Client联系NameNode,NameNode在元数据中创建文件节点。
- 业务应用调用write API写入文件。
- HDFS Client收到业务数据后,从NameNode获取到数据块编号、位置信息后,联系DataNode,并与需要写入数据的DataNode建立起流水线。完成后,客户端再通过自有协议写入数据到DataNode1,再由DataNode1复制到DataNode2, DataNode3。
- 写完的数据, 将返回确认信息给HDFS Client。
- 所有数据确认完成后, 业务调用HDFS Client关闭文件。
- 业务调用
图 1‑2
Java应用开发
开发流程
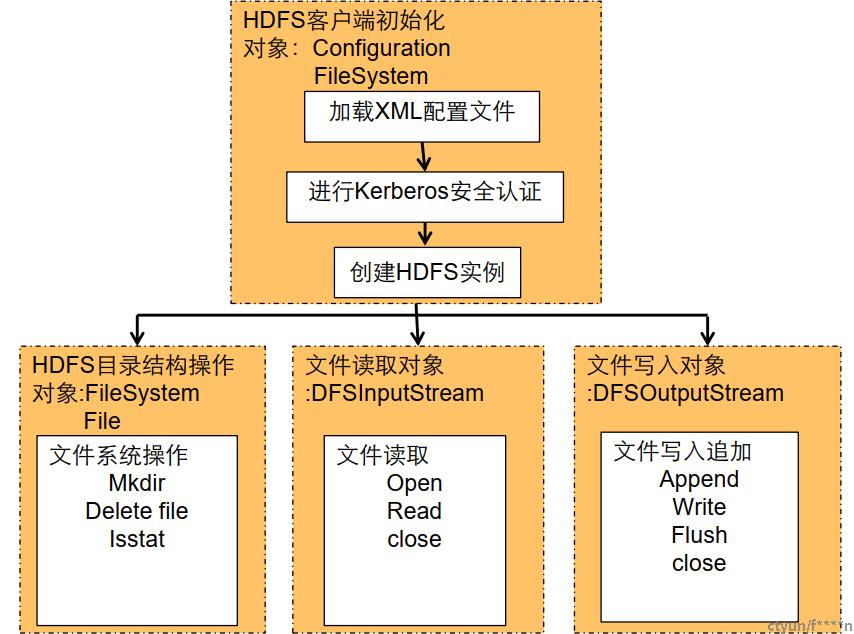
开发流程如下图所示:
图 1‑3
开发示例
初始化
- 初始化配置对象,并加载配置文件。(配置文件包含访问HDFS的必要信息,如IP地址)
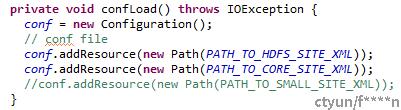
- HDFS安全版本下,配置访问HDFS安全认证的用户,以及keytab文件,进行安全认证和登录。

- 安全认证登录成功后,实例化Filesystem对象。

目录创建
创建目录流程:
- 判断目录路径是否存在;
- 不存在时创建目录。

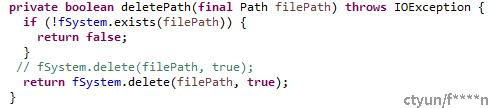
删除目录流程:
- 判断目录路径是否存在;
- 存在时删除目录。
文件读取
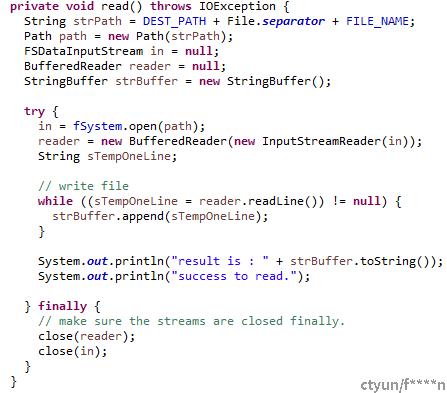
数据读取流程:
- 初始化FSDataInputstream对象。
- 使用FSDataInputStream对象,初始化BufferReader。
- 使用BufferReader.read读取HDFS数据
注意事项
- Java开发时,申请资源需及时释放,如FSDataInputStream、FSDataOutputStream、 BufferedOutputStream、 BufferedReader对象等。
- HDFS不适用于存储大量小文件, 大量小文件的元数据会占用NameNode大量内存
- HDFS中数据的备份数量3份即可, 增加备份数量不能提升系统效率,只会提升系统数据的安全系数;当某个节点损坏时,该节点上的数据会被均衡到其他节点上。
- 如果有多线程进行login的操作,当应用程序第一次登录成功后,所有线程再次登录时应该使用relogin的方式。
