


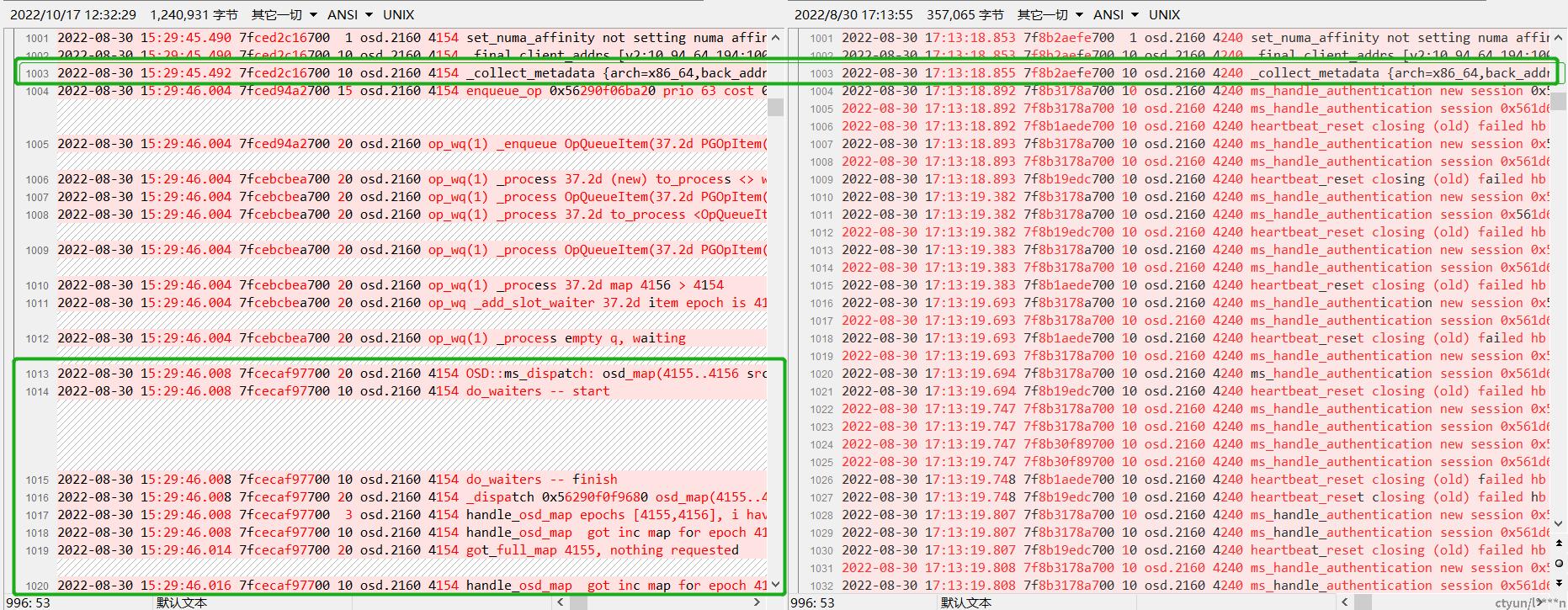
对比osd能正常起来的日志,发现osd卡住是在给mon发了osd boot消息后没有收到回应。左边为起得来的,右边为起不来的。
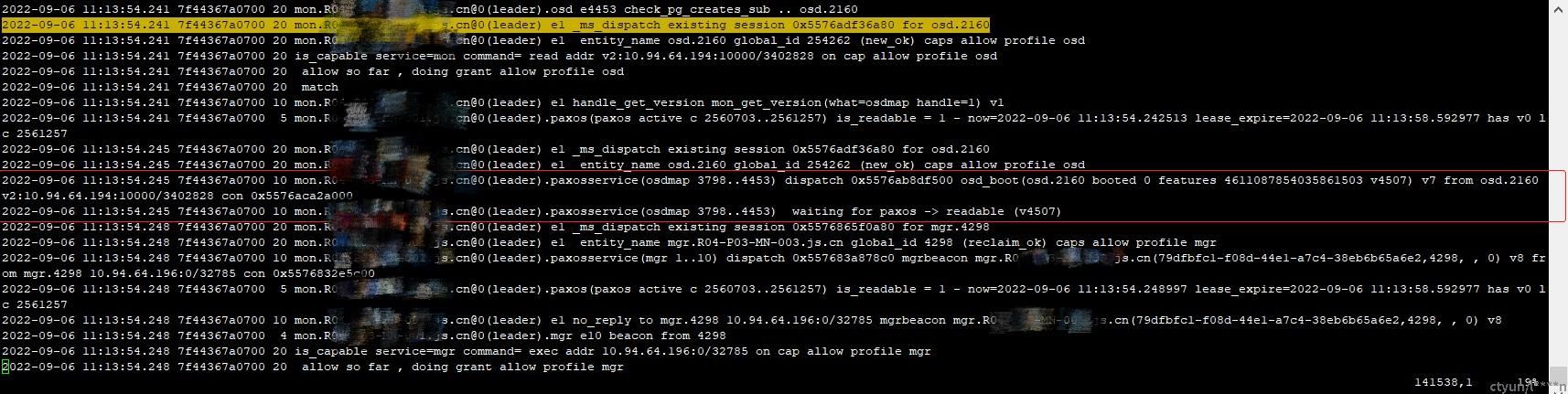
因此再去mon方查看日志,发现了mon收到osd boot消息后,
对应到代码:
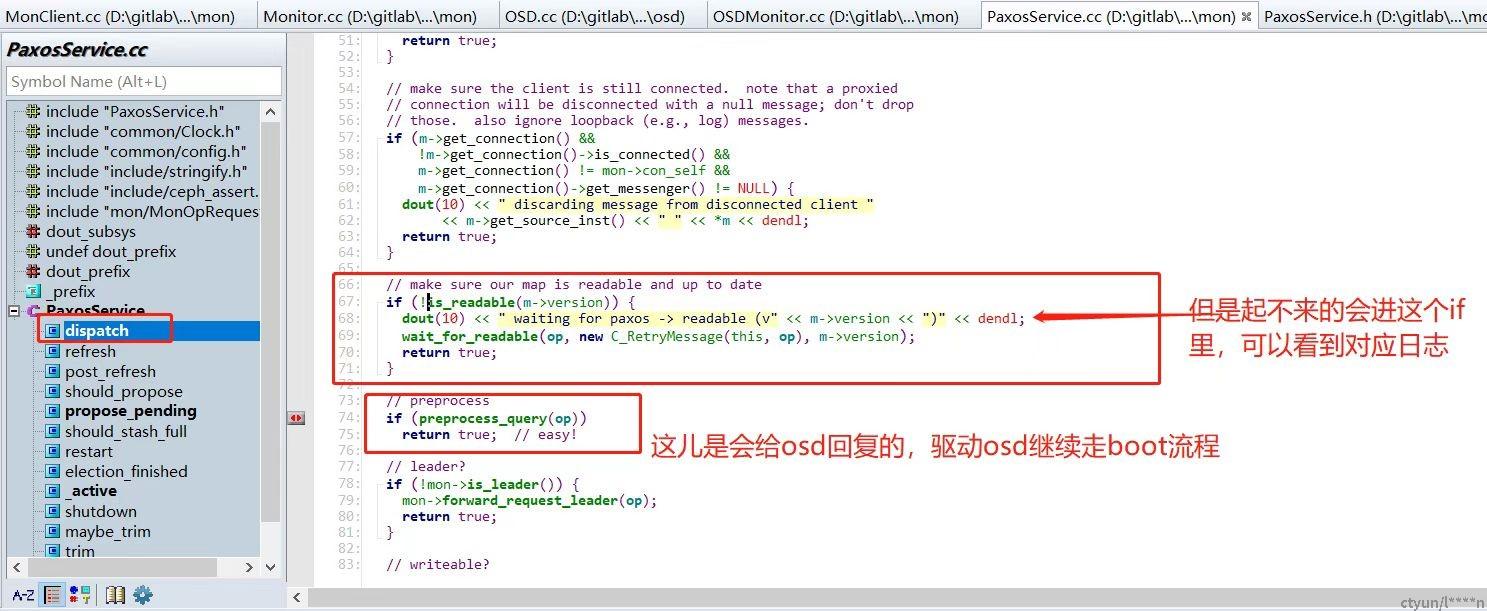
Is_readable的参数ver是osd的最新epoch,get_last_committed()是集群的最新epoch。注释掉判断 (ver>get_last_committed())后,mon会正常给osd回复消息,osd收到消息后会继续在OSD::handle_osd_map里检查版本号差距。
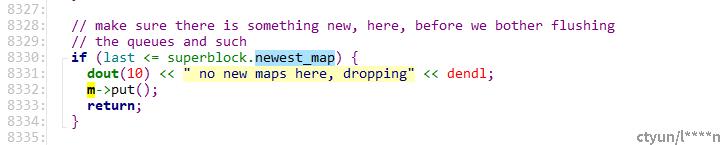
这个判断是不能注释的,因为涉及正常流程的运行。Last是集群最新的epoch,superblock.newest_map是osd最新的epoch。正常流程里osd起来后发现集群epoch last大于自己的epoch就不会进if里,会在后续代码里增长自己的epoch,第二轮若发现仍有差距,会继续追赶,直到集群epoch last==superblock.newest_map,return后驱动osd state: booting -> active。
结论:osd的osdmap epoch大于mon本身就是一种异常,拉高mon的epoch是修复的正确方式。
