


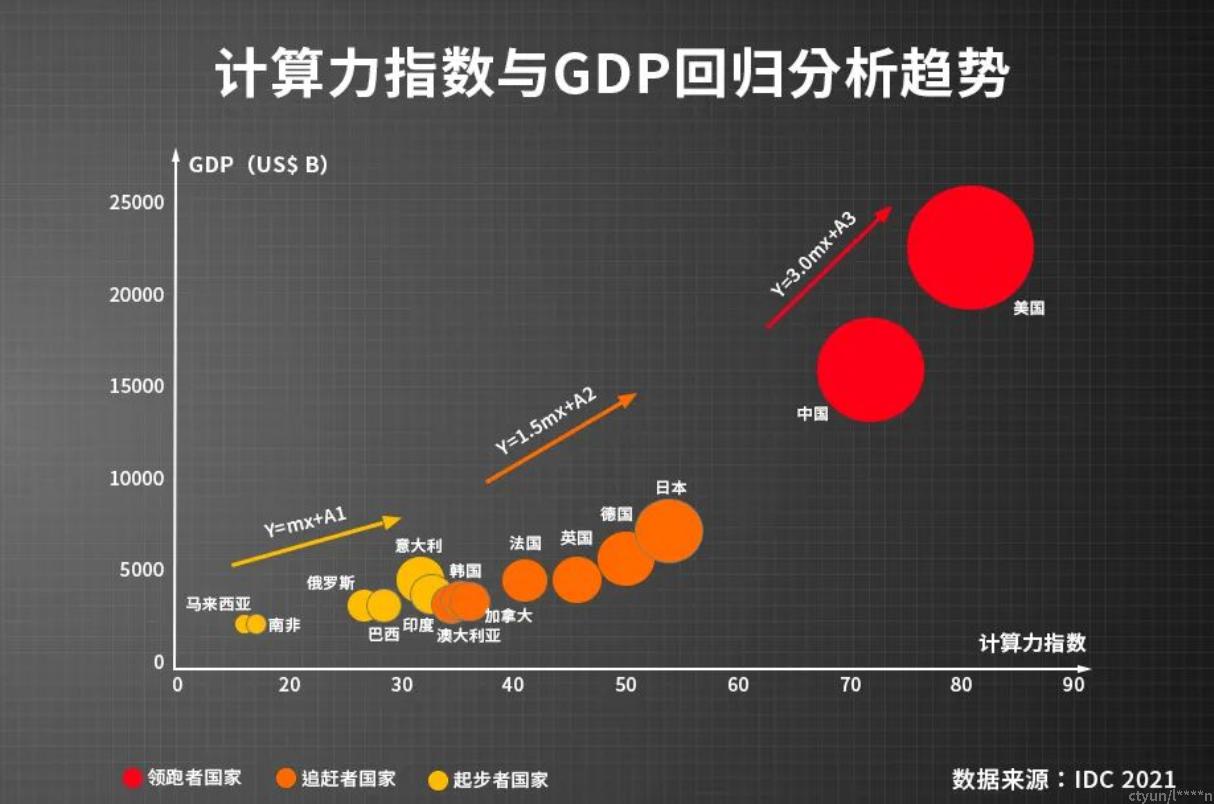
数字经济进入新发展阶段,算力与数据增长齐头并进,算力需求快速扩张,已成为数字经济时代最具活力和创新力的新型生产力。云计算作为算力的关键载体和服务形式,用云量成为衡量数字经济的关键指标。
数字经济时代,算力已渗透到产业及企业生产中,从传统产业的升级到新兴产业的孕育,都需要依靠强劲的算力支撑,需要从软件到硬件全面提升算力、算效问题,缓解当前算力的供需矛盾。
- 关于算力和精度
算力衡量:INT 8表示8位精度,一般行业共识是INT8作为高精度算力的衡量标准,此外还低一点的的INT4和更高的INT16。
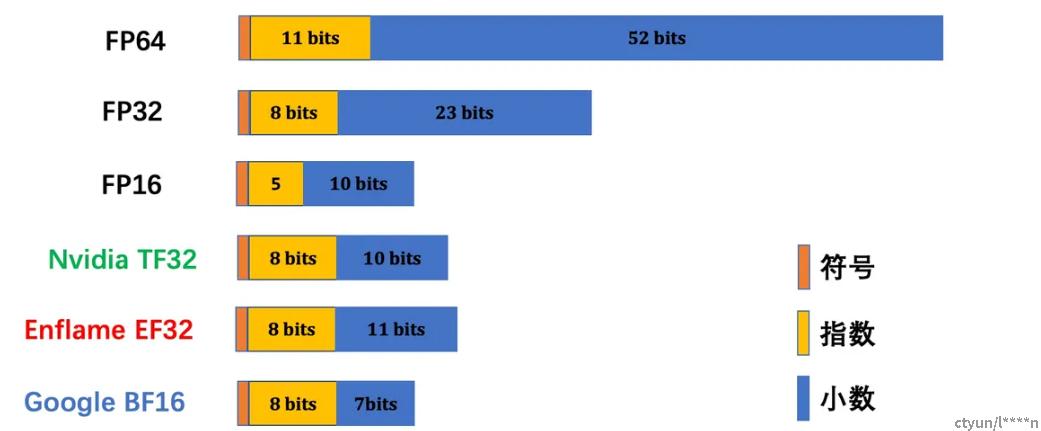
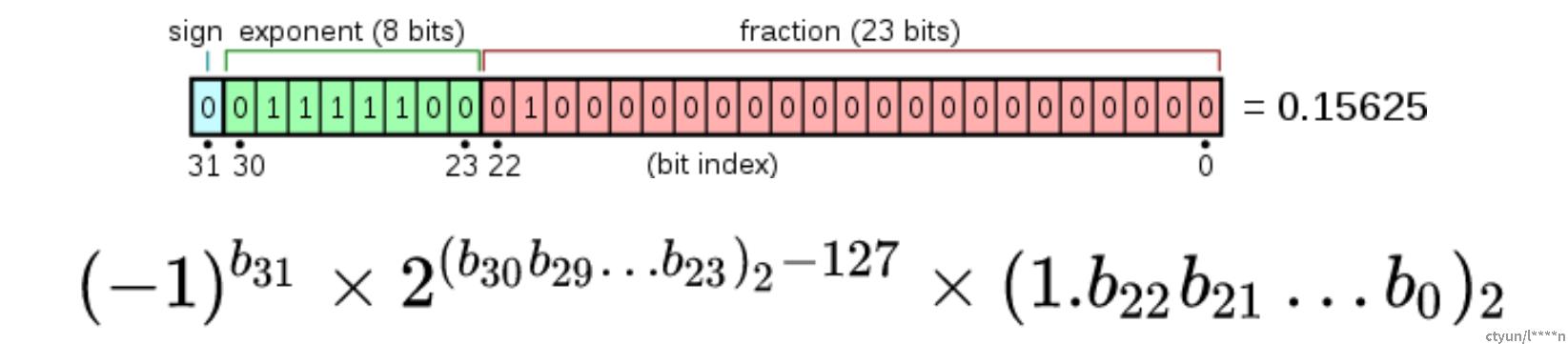
精度衡量:是属于有理数中某特定子集的数的数字表示,在计算机中用以近似表示任意某个实数,小数点可以“浮动”。实数由一个整数或定点数(即尾数/significand/mantissa)乘以某个基数exponent(计算机中通常是2)的整数次幂得到,这种表示方法类似于基数为10的科学计数法。用浮点数来衡量计算机二进制中的数字精度。不同精度的浮点数的指数位和尾数位如下图所示。
在计算中,浮点算术(FP)是使用实数的公式表示作为近似值来支持范围和精度之间的权衡的算术。出于这个原因,浮点计算通常用于需要快速处理时间的非常小和非常大的实数系统。在一般情况下,一个浮点数是具有固定数目的近似表示显著数字(的有效数),并使用缩放指数在一些固定的底座; 缩放的基数通常是 2、10 或 16。有效数是整数,基数是大于或等于 2的整数,指数也是整数。
- FP16= float16 半精度浮点格式。
- FP32 = float32 单精度浮点格式。
- FP64= float64 双精度浮点格式。
- TF32 = TensorFlow-32 英伟达提出的代替FP32的单精度浮点格式。TF32 采用了与半精度( FP16 )数学相同的10 位尾数位精度,这样的精度水平远高于AI 工作负载的精度要求,有足够的余量。同时, TF32 采用了与FP32 相同的8 位指数位,能够支持与其相同的数字范围。这样的组合使TF32 成为了代替FP32 ,进行单精度数学计算的绝佳替代品,尤其是用于大量的乘积累加计算,其是深度学习和许多HPC 应用的核心。
- BF16= Brain Float 16 谷歌大脑提出的一个16位的浮点类型。BF16是对FP32单精度浮点数截断数据,能在16位的空间中,通过降低精度(比FP16的精度还低)的方式,来获得更大的数值空间(Dynamic Range)。BF16的这一特性能在满足一定精度要求的基础上,大大提高深度学习模型的推理速度和部署灵活性。
- 芯片挑战
AI算力进入大模型时代,大模型的实现需要强大的算力来支撑训练和推理过程。各类语言大模型的算力需求呈现指数级增长,受芯片受架构、工艺的限制,增长速度难以与之匹配,因此只能通过云计算服务商将大量的GPU、AI 芯片等互联在一起,完成大规模的运算。
随着CPU制程工艺让单个CPU的核心数接近极限,而爆炸式增长的数据、复杂的算法模型,使得对算力的需求快速提升,普通服务器已无法满足不断增长的算力需求。

当前,AI服务器主要采用CPU+AI加速芯片的异构服务器,比如CPU+GPU、CPU+FPGA、CPU+AISC等组合方式。
- 网络挑战
AI应用正在为ICT基础设施提出越来越多的挑战。首先AI运算相比以往的运算更加复杂,一次智能化识别的背后可能包含着几百个模型的计算。能够承担更复杂的运算任务,显然是AI应用ICT基础设施的第一要务。同时AI运算往往关乎于图像、关乎于视频,其数据量的庞大程度相比以往实现了从线性到张量的跃进。能承担更大的数据通过量才能让AI应用平稳运行。最后AI运算对于ICT基础设施的部署条件要求也更加严苛,以往以太网1‰的丢包率,对于AI应用来说会极大的影响其算力发挥。
这些AI给计算和通信带来改变,同时也给通行的网络环境施加了巨大的负担。无论是智能驾驶这样的巨大数据量任务,还是工业互联网精准的算法模型部署要求,或者AIoT驳杂的运维压力,都给网络环境添加了无数压力:
- 庞大算力需要和复杂的异构计算,需要弹性的网络环境支撑,网络速度跟不上,AI算力也就无的放矢。
- AI任务要求大规模部署和并行计算、海量非结构化数据通过、实时学习、算法在框架层和应用层的精准度一致等等。这些新要求是此前的网络环境中所不具备的,需要新的主动网络优化能力。
- AI时代,企业业务空间增长,并行数据量暴增,直接导致运维工作太过复杂,解放这一压力,也已经刻不容缓。
