


前置内容
相比classic rcu实现,当前最新的内核已用tree rcu 实现,更具有可扩展性,但本质上采用同样的版本号同步跟踪逻辑。所以本文基于2.6.19内核实现的经典rcu 来着重讲述内核 rcu的 cpu 宽限期检测,更易于理解,也不必深挖诸多tree rcu 相关状态变迁逻辑。classic rcu代码量不多,但字段同步,状态迁移,以及实现逻辑还是并不简单。
Per CPU rcu_data结构体解析
passed_quiesc: 表示当前cpu 是否经历过qs停顿态了;在一个宽限期内,我们并不需要知道cpu 经历过几次停顿态,只需要知道当前cpu已经经历过停顿态即可,所以该字段只是一个flag标记而已,记录当前宽限期内该cpu 已经经过了调度切换。
qs_pending: 表示当前cpu 是否在等待qs停顿态。如果当前cpu还未经历停顿态,仍在等待,则qs_pending为1;如果当前cpu 经历过了停顿态,则qs_pending置为0。此字段可以作为全局bitmap的影子变量,从而可以通过检查该cpu 局部变量,而不是检查全局active bitmap,从而避免缓存抖动。
注意这里内核做了两个标记来表示当前cpu是否经历过停顿态,但实际检测当前cpu 状态时主要还是依赖qs_pending。passed_quiesc标记后,会再去标记qs_pending。 为什么需要两个标记:主要是为了在timer 中断中尽早拦截,避免重复触发软中断调度,表示当前已经check 过rcu 调度;而passed_quiesc 用于标记当前cpu已经经过了调度切换。具体可以自己尝试下修改成单标记实现,就会发现该问题。
这两个标记在本地cpu检测到需要启动新的宽限期时(发现本地rdp->quiescbatch 宽限期编号 不等于全局rcp->cur 宽限期编号),则qs_pending置为1, passed_quiesc 置为0
static void rcu_check_quiescent_state(struct rcu_ctrlblk *rcp,
struct rcu_data *rdp)
{
......
if (rdp->quiescbatch != rcp->cur) {
/* start new grace period: */
rdp->qs_pending = 1;
rdp->passed_quiesc = 0;
rdp->quiescbatch = rcp->cur;
return;
}
......
}那么何时标记passed_quiesc呢?:当cpu 发生进程切换,或者时钟中断发现当前不在普通内核上下文时标记。
-
在时钟tick中检测CPU处于用户模式或者idle模式,则表明CPU离开了临界区;
-
在不支持抢占的RCU实现中,检测到CPU有context切换,就能表明CPU离开了临界区
进程切换时标记:
kernel/sched.c:
/*
* schedule() is the main scheduler function.
*/
asmlinkage void __sched schedule(void)
{
......
switch_tasks:
rcu_qsctr_inc(task_cpu(prev)); //将上一个进程设置为已经经过停顿态,置位passed_quiesc为1
......
}时钟中断:
void update_process_times(int user_tick)
{
......
if (rcu_pending(cpu))
rcu_check_callbacks(cpu, user_tick);
----> rcu_check_callbacks {
if (user || (idle_cpu(cpu) && !in_softirq() && hardirq_count() <= (1 << HARDIRQ_SHIFT))) {
rcu_qsctr_inc(cpu);
---->rdp->passed_quiesc = 1;
}
}
.....
}上面只是标记了passed_quiesc 为1,代表当前cpu已经经历了停顿态;而qs_pending还需要清空,以完整标记当前cpu 不再需要等待停顿态了,这是在软中断上下文中回调__rcu_process_callbacks-->rcu_check_quiescent_state来检测实现的:
static void __devinit rcu_online_cpu(int cpu)
{
struct rcu_data *rdp = &per_cpu(rcu_data, cpu);
struct rcu_data *bh_rdp = &per_cpu(rcu_bh_data, cpu);
rcu_init_percpu_data(cpu, &rcu_ctrlblk, rdp);
rcu_init_percpu_data(cpu, &rcu_bh_ctrlblk, bh_rdp);
tasklet_init(&per_cpu(rcu_tasklet, cpu), rcu_process_callbacks, 0UL);
}
static void rcu_check_quiescent_state(struct rcu_ctrlblk *rcp,
struct rcu_data *rdp)
{
......
/* Grace period already completed for this cpu?
* qs_pending is checked instead of the actual bitmap to avoid
* cacheline trashing.
*/
if (!rdp->qs_pending) //阻止第二次重复进入
return;
/*
* Was there a quiescent state since the beginning of the grace
* period? If no, then exit and wait for the next call.
*/
if (!rdp->passed_quiesc)
return;
rdp->qs_pending = 0; //表示当前cpu已经经过了停顿态,自此,timer中断中的检测,就可以根据检查该字段:当前宽限期内,该cpu 的rcu 相关逻辑,都不需要进一步处理了
spin_lock(&rcp->lock);
/*
* rdp->quiescbatch/rcp->cur and the cpu bitmap can come out of sync
* during cpu startup. Ignore the quiescent state.
*/
if (likely(rdp->quiescbatch == rcp->cur))
cpu_quiet(rdp->cpu, rcp);
spin_unlock(&rcp->lock);
}这里在设置当前cpu 已经经过停顿态后,会同步去清除全局bit位;同时,如果所有cpu bit位都清空了,则标记当前宽限期已经完成:rcp->completed = rcp->cur; 并尝试开启新的宽限期。
所以这里需要先经过两次检测设置: 调度器上下文切换或者时钟中断检测到上下文变化(设置passed_quiesc),然后再在软中断中发现当前cpu已经经过了停顿态(清空qs_pending),才执行后续的cpu bitmap清空(从而此后直到新宽限期开启前,本地cpu的timer中断中都不需要处理rcu 业务了)及可能的新宽限期开启。
batch: 表示本次被阻塞的写者,即挂在curlist上的回调,需要在哪个gpid 完成之后被激活;
检查:当rcp->completed >= rdp->batch时,表示当前cpu的被阻塞写者,curlist链表中的回调,可以移入donelist,并被执行了。同时,所以timer 中断中,也通过检测当前 rdp->curlist 不为空,且 rcp->completed >= rdp->batch,知道当前cpu 需要进一步进入软中断上下文,依次回调处理各个rcu 回调函数。
更新:该字段的更新,是在发现curlist 为空(即当前正在等待的回调为空)而nxtlist有正在等待的写者,此时会将nxtlist 移入curlist,并将rdp->batch置为rcp->cur+1; 同时,(如果还没开启新的宽限期,即rcp->next_pending为1)则会开启新的gp宽限期等待。
quiescbatch:内核rcu的宽限期开启,并不是广播给所有cpu的,所以各个cpu 都需要通过比较rdp->quiescbatch 与 rcp->cur 来确认当前内核是否开启了新的gp等待,并将全局cur 同步到本地。
此外,因为gp宽限期的开启没有广播给所有cpu,所以需要调用两次rcu_check_quiescent_state:
这两次分别是rcu_pending实现中的两个条件:(rdp->quiescbatch != rcp->cur || rdp->qs_pending) 条件
第一次各个cpu发现全局开启了新的gp,即rdp->quiescbatch != rcp->cur,并主动将全局宽限期gpid 取回到本地:
static void rcu_check_quiescent_state(struct rcu_ctrlblk *rcp,
struct rcu_data *rdp){
if (rdp->quiescbatch != rcp->cur) {
/* start new grace period: */
rdp->qs_pending = 1; //因为开启了新的gp等待,所以当前cpu就重新初始化为等待qs停顿态
rdp->passed_quiesc = 0; //因为开启了新的gp等待,所以当前cpu就重新初始化为还没有经历过qs停顿态
rdp->quiescbatch = rcp->cur; //同步本地cpu的等待gp id为当前全局等待的gp id
return;
}第一次到第二次执行中间,如果当前cpu 还没有经历过qs 停顿态,则会持续检测,并直到经历过,否则会快速检测,快速退出:
void update_process_times(int user_tick)
if (rcu_pending(cpu))
rcu_check_callbacks(cpu, user_tick);
-->tasklet_schedule(&per_cpu(rcu_tasklet, cpu));
-->__rcu_process_callbacks(&rcu_ctrlblk, &__get_cpu_var(rcu_data));
rcu_check_quiescent_state(rcp, rdp); {
/* Grace period already completed for this cpu?
* qs_pending is checked instead of the actual bitmap to avoid
* cacheline trashing.
*/
if (!rdp->qs_pending) // 如果当前cpu已经经过了第二次调用,cpu bitmap已经清0,则当前宽限期内,到宽限期结束,都不要再执行什么操作了;
return;
/*
* Was there a quiescent state since the beginning of the grace
* period? If no, then exit and wait for the next call.
*/
if (!rdp->passed_quiesc) //直到检测发现当前cpu经历过了调度切换,才会进入后续流程
return;
rdp->qs_pending = 0;
}即第一次拉取全局gpid 到本地rdp 后,会一直检测当前cpu是否已经经历过qs停顿态的检查,包括在时钟中断中检查当前cpu的上下文,以及在进程调度中设置:
static inline void rcu_qsctr_inc(int cpu){
struct rcu_data *rdp = &per_cpu(rcu_data, cpu);
rdp->passed_quiesc = 1;
}
//时钟中断中调用
void update_process_times(int user_tick)
{
......
if (rcu_pending(cpu))
rcu_check_callbacks(cpu, user_tick);
.......
}
void rcu_check_callbacks(int cpu, int user){
if (user ||
(idle_cpu(cpu) && !in_softirq() &&
hardirq_count() <= (1 << HARDIRQ_SHIFT))) {
rcu_qsctr_inc(cpu); //设置rdp->passed_queisc = 1
rcu_bh_qsctr_inc(cpu);
} else if (!in_softirq())
rcu_bh_qsctr_inc(cpu);
tasklet_schedule(&per_cpu(rcu_tasklet, cpu));
}
//上下文切换时调用
asmlinkage void __sched schedule(void) {
......
rcu_qsctr_inc(task_cpu(prev)); //设置rdp->passed_queisc = 1
......
}第二次实际执行,是在本地cpu经历过qs停顿态后,即此时rdp->passed_quiesc = 1后。在此之前,即便调用该rcu_check_quiescent_state函数,也不会有实际动作。
而真正第二次执行时,是rdp->passed_quiesc = 1而rdp->qs_pending还是1时,即第一次调用rcu_check_quiescent_state后的值。
此次主要是发现当前cpu已经经历过qs停顿,所以将rdp->qs_pending = 0; 标记当前cpu目前已经不需要等待qs状态了。最后将全局cpumask中的对应bit位清0:
static void rcu_check_quiescent_state(struct rcu_ctrlblk *rcp,
struct rcu_data *rdp){
if (rdp->quiescbatch != rcp->cur) {
/* start new grace period: */
rdp->qs_pending = 1;
rdp->passed_quiesc = 0;
rdp->quiescbatch = rcp->cur;
return;
}
/* Grace period already completed for this cpu?
* qs_pending is checked instead of the actual bitmap to avoid
* cacheline trashing.
*/
if (!rdp->qs_pending)
return;
/*
* Was there a quiescent state since the beginning of the grace
* period? If no, then exit and wait for the next call.
*/
if (!rdp->passed_quiesc)
return;
rdp->qs_pending = 0;
spin_lock(&rcp->lock);
/*
* rdp->quiescbatch/rcp->cur and the cpu bitmap can come out of sync
* during cpu startup. Ignore the quiescent state.
*/
if (likely(rdp->quiescbatch == rcp->cur))
cpu_quiet(rdp->cpu, rcp);
spin_unlock(&rcp->lock);
}注意这里修改全局cpumask时,需要持有rcp->lock全局锁,在多核场景下锁竞争过大,这也是未来hierachi rcu 引入的原因。
全局rcu_ctrlblk 结构体解析
开启全局gp等待的条件,参见rcu_start_batch 实现,当所有cpu 都经过停顿态后,且rcp->next_pending=1 时就会触发开启新的宽限期。而二者任一状态满足时,都会尝试去调用rcu_start_batch,看另一个条件满足了没,如果都满足则会开启新宽限期:
static void cpu_quiet(int cpu, struct rcu_ctrlblk *rcp)
{
cpu_clear(cpu, rcp->cpumask);
if (cpus_empty(rcp->cpumask)) {
/* batch completed ! */
rcp->completed = rcp->cur;
rcu_start_batch(rcp);
}
}
static void __rcu_process_callbacks(struct rcu_ctrlblk *rcp,
struct rcu_data *rdp)
{
if (rdp->nxtlist && !rdp->curlist) { //有等待的回调函数,而且当前回调都已处理完毕,所以可以开启新的宽限期
local_irq_disable();
rdp->curlist = rdp->nxtlist;
rdp->curtail = rdp->nxttail;
rdp->nxtlist = NULL;
rdp->nxttail = &rdp->nxtlist;
local_irq_enable();
/*
* start the next batch of callbacks
*/
/* determine batch number */
rdp->batch = rcp->cur + 1;
/* see the comment and corresponding wmb() in
* the rcu_start_batch()
*/
smp_rmb();
if (!rcp->next_pending) {
/* and start it/schedule start if it's a new batch */
spin_lock(&rcp->lock);
rcp->next_pending = 1;
rcu_start_batch(rcp);
spin_unlock(&rcp->lock);
}
}只有当有写者阻塞等待着,并从nxtlist移入curlist,并且当前所有的gp等待都完成时,才会开启新的gp等待周期
或者当前所有cpumask都清0后,如果发现next_pending置1,则也会尝试开启新的等待周期。
所以:开启gp等待,需要同时满足:rcp->next_pending && rcp->completed == rcp->cur
next_pending: 表示当前有请求在等待开启新的gp宽限期,等待当前gp处理完成后,如果该字段置位,则会立即开启新的gp等待。系统刚初始化时,curlist 还是空,所以:如果有cpu 挂载回调到rdp 本地链表,则在其timer中断中检查rcu_pending时 if (!rdp->curlist && rdp->nxtlist) 满足要求,所以会在rcu_process_callback 中发现有新请求到来,将next_pending置1,从而开启系统第一个宽限期。
开启gp 等待的第一种情况:在请求到来时置next_pending为1
static void __rcu_process_callbacks(struct rcu_ctrlblk *rcp,
struct rcu_data *rdp)
{
.......
//此时请求到来,移入curlist 开启等待:
if (rdp->nxtlist && !rdp->curlist) {
local_irq_disable();
rdp->curlist = rdp->nxtlist;
rdp->curtail = rdp->nxttail;
rdp->nxtlist = NULL;
rdp->nxttail = &rdp->nxtlist;
local_irq_enable();
/*
* start the next batch of callbacks
*/
/* determine batch number */
rdp->batch = rcp->cur + 1;
/* see the comment and corresponding wmb() in
* the rcu_start_batch()
*/
smp_rmb(); //确保此指令之后的next_pending是从主存中读取的,确保是最新值,
//避免其他cpu已经开启了新的gp而由于缓存原因我们没有立即知道,导致错误再次开启新的gp
if (!rcp->next_pending) {
/* and start it/schedule start if it's a new batch */
spin_lock(&rcp->lock);
rcp->next_pending = 1; //注意这里开始等待开启全局gp后,不一定立即就会开启,而是需要等到rcp->completed==rcp->cur时才会开启新的gp,并将next_pending 清0
rcu_start_batch(rcp);
spin_unlock(&rcp->lock);
}
}
rcu_check_quiescent_state(rcp, rdp);
if (rdp->donelist)
rcu_do_batch(rdp);
}在开启全局gp等待时next_pending清0,表示当前没有需要新开启的gp了,避免其他cpu重复开启:
static void rcu_start_batch(struct rcu_ctrlblk *rcp)
{
if (rcp->next_pending &&
rcp->completed == rcp->cur) {
rcp->next_pending = 0;
/*
* next_pending == 0 must be visible in
* __rcu_process_callbacks() before it can see new value of cur.
*/
smp_wmb(); //确保其他组件或者cpu,一定是先看到next_pending=0 再看到rcp->cur的新值
rcp->cur++;开启gp 等待的第二种情况:当前cpu是最后一个清空全局cpu bitmap的cpu,同步检查下是否需要开启新的宽限期:
completed: 表示当前全局已经完成的gp id,当cpumask中的所有cpu都已经经历过qs停顿态后,标志着当前gp已经完成时:
static void cpu_quiet(int cpu, struct rcu_ctrlblk *rcp){
cpu_clear(cpu, rcp->cpumask);
if (cpus_empty(rcp->cpumask)) {
/* batch completed ! */
rcp->completed = rcp->cur; //当前等待中的gp 已经完成
rcu_start_batch(rcp);
}
}cur :表示当前等待中的宽限期gp id
cpumask: 标记当前哪些cpu已经经历过了qs停顿态; 1代表对应cpu还未经历过qs 停顿态
static void rcu_start_batch(struct rcu_ctrlblk *rcp)
{
if (rcp->next_pending &&
rcp->completed == rcp->cur) {
rcp->next_pending = 0;
/*
* next_pending == 0 must be visible in
* __rcu_process_callbacks() before it can see new value of cur.
*/
smp_wmb();
rcp->cur++;
/*
* Accessing nohz_cpu_mask before incrementing rcp->cur needs a
* Barrier Otherwise it can cause tickless idle CPUs to be
* included in rcp->cpumask, which will extend graceperiods
* unnecessarily.
*/
smp_mb();
cpus_andnot(rcp->cpumask, cpu_online_map, nohz_cpu_mask);
rcp->signaled = 0;
}
}RCU 实现中的内存屏障细节
smp_wmb写内存屏障(Store Memory Barrier):在指令后插入Store Barrier,能让写入缓存中最新数据更新写入主内存中,让其他线程可见。强制写入主内存,这种显示调用,不会让CPU去进行指令重排序
smp_rmb读内存屏障(Load Memory Barrier):在指令后插入Load Barrier,可以让高速缓存中的数据失效,强制重新从主内存中加载数据。也是不会让CPU去进行指令重排。
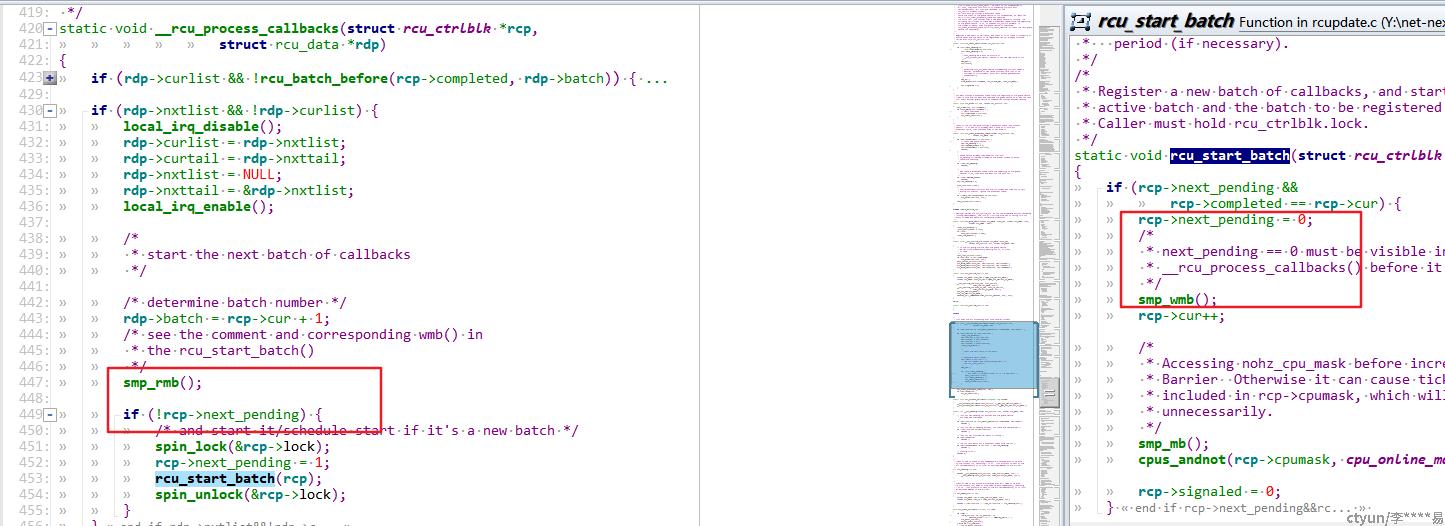
因为__rcu_process_callbacks 是在tasklet中调度的,smp 并行模式,所以会有缓存问题。这里__rcu_process_callbacks在smp_rmb 后读取rcp->next_pending,是为了确保读到的rcp->next_pending是最新的;而rcu_start_batch中smp_wmb,是为了确保刚刚设置的next_pending 会同步写到内存中去。
这样每个cpu 在读取rcp->next_pending字段,都是最新的,即便其他cpu 刚刚设置了next_pending。从而确保不会重入rcu_start_batch()函数。
至此,RCU 宽限期检测相关核心实现函数梳理完毕。
