


1 训练范式回顾
传统范式:随机初始化训练
BERT之后:先进行模型预训练,再进行微调
T5之后:先进行模型预训练,再进行指令微调
GPT3之后:只进行模型预训练。用prompt进行零样本、少样本推理。
2. 使用prompt-learning后的新训练策略
2.1 同时进行预训练、提示学习,优化所有参数
2.2 在预训练之后,冻结模型参数,对soft prompt进行优化
例如下面这篇文章中,通过60项任务的提示数据微调了1300亿参数的模型,大幅提高了模型的零样本能力
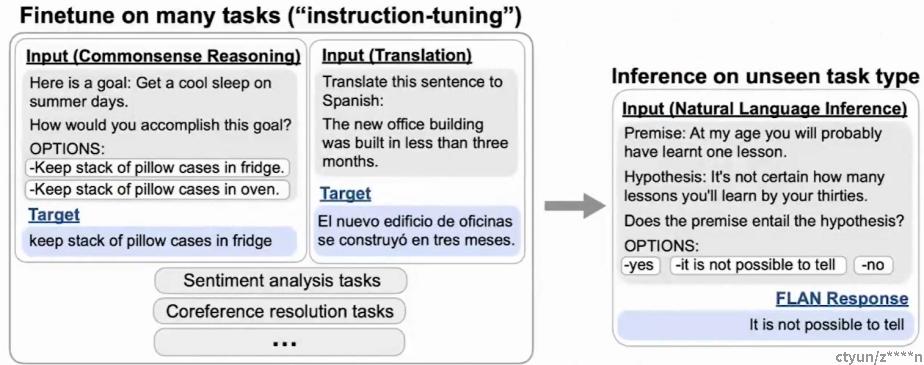
FINETUNED LANGUAGE MODELS ARE ZERO-SHOT LEARNERS.2021
2.3 在预训练过程中加入提示数据,之后进行零样本推理
例如下面这篇文章中,使用人工制作的提示数据来训练编码器-解码器模型。模型在未见过的任务上取得了良好的效果。
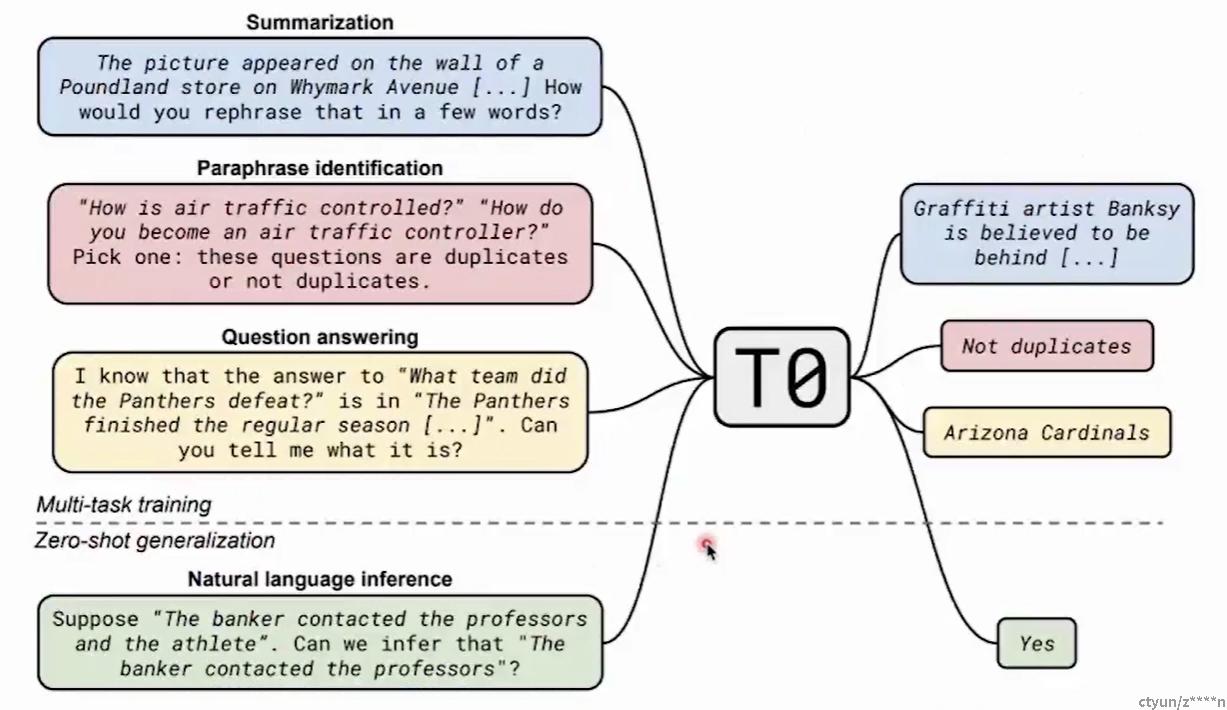
Multitask Prompted Training Enables Zero-Shot Task Generalization.2021.
