


1. Docker的技术基础
一个“Docker容器”,实际上是一个由 Linux Namespace、Linux Cgroups 和 rootfs 三种技术构建出来的进程的隔离环境:
- 通过Linux Namespac实现各种资源的隔离;
- 通过Linux Cgroups 实现对各种资源的管控、以及配额的分派;
- 在Linux中,任何资源事实上均是文件file,通过rootfs实现各种文件系统的聚合或者资源的拼凑,最终形成一个虚拟的运行环境或容器;
直接操作Linux Namespace、Linux cgroup以及rootfs/chroot是很不容易,Docker的Libcontainer对于这些底层的技术进行了高度集成,屏蔽了这些底层技术使用层面上的复杂度、困难度,使得Docker的用户,只需要通过一两条简单的Docker命令,就能启动容器、管理容器。
1.1 Linux Namespac
Linux Namespace是将Linux内核的全局资源做封装,使得每个Namespace都有一份独立的资源,因此不同的进程在各自的Namespace内对同一种资源的使用不会互相干扰。通过Namespace实现各种全局资源的隔离之外,还提供每类资源在宿主机和目标环境中的相互映射关系。
目前Linux内核总共支持以下6种Namespace:
- IPC:隔离System V IPC和POSIX消息队列。
- IPC也就是进程间通信,Linux下有多种进程间通信,比如socket、共享内存、Posix消息队列和SystemV IPC等,每个IPC均会有不同的标识符,进程间通过找到标识符对应的IPC来完成通信。
-
IPC namespace针对的是SystemV IPC和Posix消息队列,维护目标环境中的IPC标识符与宿主机中的全局IPC标识符的一一对应关系;并无论目标环境中的IPC标识符是什么,均会在宿主机中拥有一个唯一的“真实”全局IPC标识符。
-
通过IPC Namespace实现IPC标识符的映射,确保了各个目标环境中的IPC均能正常的工作且互不干涉。
-
Network:隔离网络资源。
- Network Namespace隔离网络资源,每个Network Namespace都有自己的网络设备、IP地址、路由表、/proc/net目录、端口号等。
- 每个Network Namespace会有一个loopback设备,并可以将“宿主机中的虚拟网卡”与“Network Namespace中的网卡”进行一一映射对应。
- 这样,基于Network Namespace实现了每个目标环境的网络资源隔离以及正确的网络通信。
-
Mount:隔离文件系统挂载点。
- Mount namesapce用户隔离文件系统挂载点,每个进程能看到的文件系统都记录在/proc/$$/mounts里。
- 在创建了一个新的Mount Namespace后,进程系统对文件系统挂载/卸载的动作就不会影响到其他Namespace。
- 但这个被Mount Namespace所隔离的文件系统,依然是宿主机的文件系统中的一部分,只是各自有着不同的根目录起始路径,而这些根目录起始路径的映射也由Mount Namespace所管理。
-
PID:隔离进程ID。
- PID Namespace用于隔离进程PID号,这样一来,只需确保同一个Namespace里的进程PID号是唯一就可以,而无需关注不同Namespace里的进程PID或宿主机中的PID是否互相冲突。
- 实际上,“PID Namespace”或“容器”中的任何一个进程,均是宿主机中的一个真实PID,只是各自的PID号不同,而这两个PID号之间的一一映射关系也由PID Namespace维护。
- 在Linux系统中,PID号是1的进程是一个非常特殊的init进程,需要承担一些与该进程无关的、Linux操作系统层面的职能,比如init进程作为“操作系统中”的进程祖宗,需要负责回收所有孤儿进程的资源;另外发送给init进程的任何信号都会被屏蔽,即使发送的是SIGKILL信号,也就是说,在容器内无法“杀死”init进程。
- 由于这种原因,每一个容器必须有一个PID号是1的进程;为了解决这个PID号是1的init进程,不得不引入PID Namespace:一方面解决“PID号是1的init进程”的问题;另外一方面,实现同一个Namespace里,也只能看到本Namespae中的进程PID号。
-
UTS:隔离主机名和域名。
- UTS,UNIX Time-sharing System namespace提供了主机名和域名的隔离。能够使得子进程有独立的主机名和域名(hostname),这一特性在Docker容器技术中被用到:
- 使得docker容器在网络上能被视作一个独立的节点,而不仅仅是宿主机上的一个进程。
- 同时,主机名可以用来代替IP地址,从而在网络上通过主机名访问容器。
-
User:隔离用户ID和组ID。
- 在Linux中,root用户(用户ID为0)和root组(组ID为0)是一个特殊的用户和组,很多操作的鉴权均离不开;但又不可能直接将宿主机中的root直接作用在容器中。
- User Namespace用来隔离用户资源,比如一个进程在Namespace里的用户和组ID与它在宿主机里的ID可以不一样,这样可以做到:宿主机中的一个的普通用户在某容器(user namespace)中拥有root权限,但是它的特权被限定在容器内(其他namespace下的资源,如文件系统、进程等)。
- 同样,某容器(user namespace)中的用户或组ID,在宿主机中均会有一个相对应的用户和组一一对应,而且由user namespace负责这个一一对应的映射关系。也就是在容器中,某个进程是以root身份在运行;但在宿主机中,真正运行该进程的用户只是一个普通的用户而已。
1.2 Cgroup
Cgroup(control group)是Linux内核的一个功能,用来限制、控制一个进程组群的资源(如CPU、内存、磁盘输入输出等)的可使用额度。防止进程间不利的资源抢占。这样,可以通过分配的CPU时间片数量及磁盘IO宽带大小控制任务运行的速度、效率等。
Cgroups提供了以下功能:
- **限制进程组可以使用的资源数量(Resource limiting )。**比如:memory子系统可以为进程组设定一个memory使用上限,一旦进程组使用的内存达到限额再申请内存,就会触发OOM(out of memory)。
- **进程组的优先级控制(Prioritization )。**比如:可以使用cpu子系统为某个进程组分配特定cpu share。
- **记录进程组使用的资源数量(Accounting )。**比如:可以使用cpuacct子系统记录某个进程组使用的cpu时间
- **进程组隔离(Isolation)。**比如:使用ns子系统可以使不同的进程组使用不同的namespace,以达到隔离的目的,不同的进程组有各自的进程、网络、文件系统挂载空间。
- **进程组控制(Control)。**比如:使用freezer子系统可以将进程组挂起和恢复。
Cgroup 是透过层级式的方式来管理的,会继承父级Cgroup的属性,但会被本级制定的属性进行覆盖。
JDK8u121之前的版本中(Java SE 8u121 and earlier),JVM读取的CPU数以及内存等都是没有考虑到Cgroups的限制。比如JVM中缺省的最大Heap堆栈是宿主机最大内存的1/4,但一个容器所分配到的最大内存可能是远远小于这个最大值,这就导致:由于在容器中的JDK版本太老,而且又没有配置最大Heap堆栈,那么这个容器中的JVM进程就会非常容易的OOM而被容器Kill掉。
1.3 rootfs根文件系统
- 内核是Linux的核心,但文件却是内核与外部交互所采用的的主要工具。这也是为什么在Linux世界内,万物是文件的由来。
- 一套linux体系,只有内核本身是不能工作的,必须要rootfs(etc目录下的配置文件、/bin/sbin等目录下的shell命令,还有/lib目录下的库文件等)相配合才能工作。
- Linux启动的最后一个大步骤就是挂载根文件系统;rootfs是基于内存的文件系统,所有操作都在内存中完成;也没有实际的存储设备,所以不需要设备驱动程序的参与。若系统不能从制定设备上挂载根文件系统,则系统会出错而退出启动。成功之后可以自动或手动挂载其他的文件系统,从而最终形成一个完整的文件系统。
当容器启动之后,为了使容器“像一个”独立的节点,必须先通过rootfs的功能加载容器相关的文件系统,并“拼凑”成一个根文件系统,最后利用chroot命名,将这个拼凑而成的文件系统当中当前容器的根文件系统。
2 Docker容器与虚拟机的区别
虚拟机
传统的虚拟机需要模拟整台机器包括硬件,每台虚拟机都需要有自己的操作系统,虚拟机一旦被开启,预分配给他的资源将全部被占用,每一个虚拟机包括应用,必要的二进制和库,以及一个完整的用户操作系统。
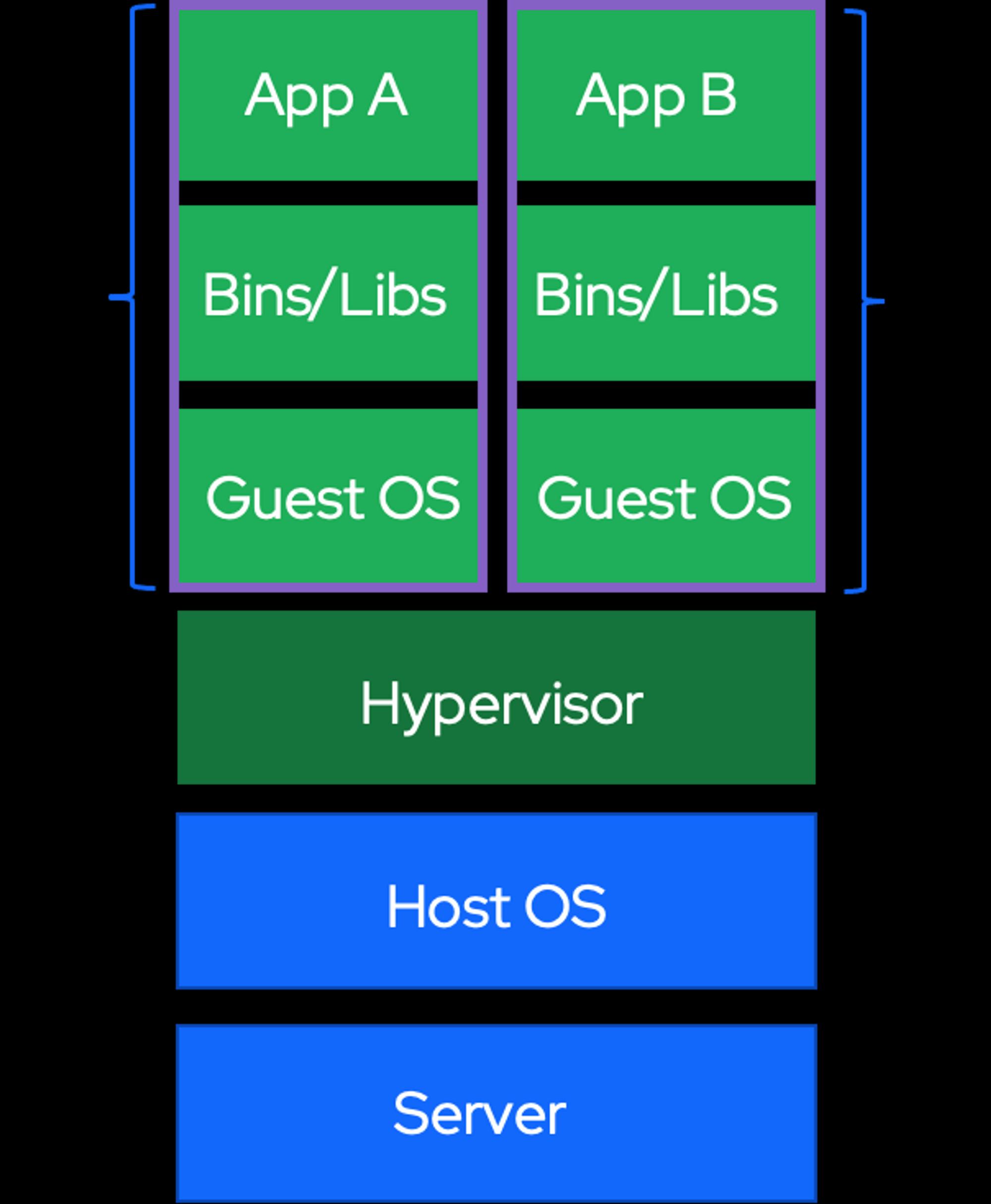
虚拟机有 Hypervisor 层,作为整个虚拟机的核心所在为虚拟机提供了虚拟的运行平台,管理虚拟机的操作系统运行。每个虚拟机都有自己的操作系统、系统库以及应用。
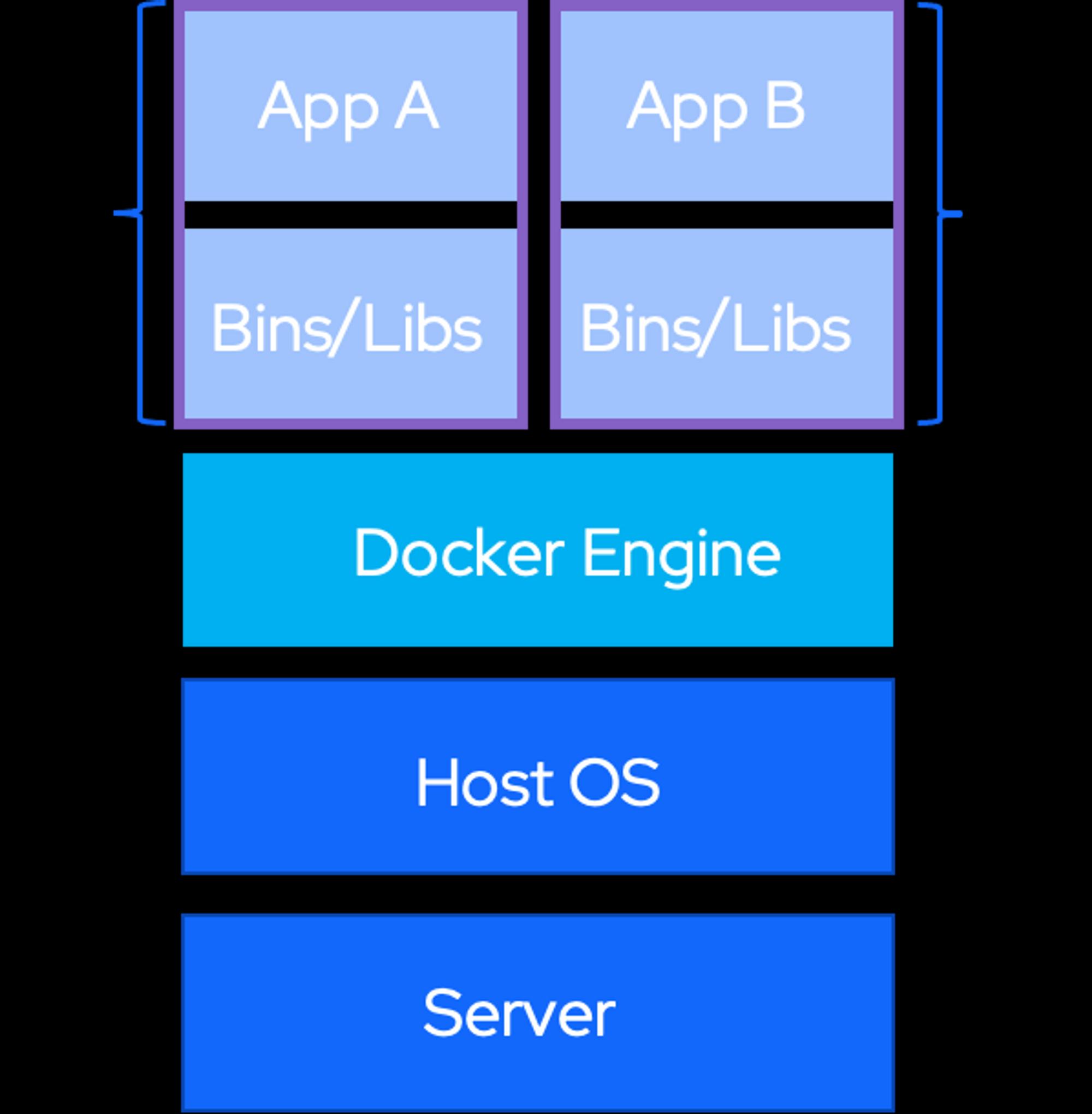
Docker容器
容器技术是和我们的宿主机共享硬件资源及操作系统,可以实现资源的动态分配。 容器包含应用和其所有的依赖包,但是与其他容器共享内核。容器中的进程事实上是直接运行在宿主机操作系统中,通过用户空间技术实现隔离。
容器没有 Hypervisor 这一层,并且每个容器是和宿主机共享硬件资源及操作系统,那么由 Hypervisor 带来性能的损耗,在 linux 容器这边是不存在的。
- **从虚拟化层面来看:**传统虚拟化技术是对硬件资源的虚拟,是个重量级的虚拟化技术;但容器技术是对进程的虚拟,相对而言以更轻量级的虚拟化技术实现进程和资源的隔离。
- **从架构来看:**Docker 比虚拟化少了两层,取消了 hypervisor 层和 GuestOS 层,使用 Docker Engine 进行调度和隔离,所有应用共用主机操作系统,因此在体量上,Docker 较虚拟机更轻量级,在性能上与裸机性能差异不大,优于虚拟机。
- **创建、删除、启动:**容器创建、删除、启动快速属于秒级别。虚拟机通常需要几分钟去创建、启动、删除。
- **占用的资源:**docker 需要的资源更少,docker 在操作系统级别进行虚拟化,docker 容器和内核交互。docker 的架构可以共用一个内核与共享应用程序库,所占内存极小。
- 同样的硬件环境,Docker 运行的容器数量远多于虚拟机数量,系统有着更高的利用率。
- Docker容器的镜像大小一般是几百K到几百M级别,但虚拟机一个镜像均是几十到几百G的大小。
- 在运行业务应用进程之外,虚拟机需要另外新起一个完整的操作系统,而容器基本上无需运行其他额外的进程。
- **隔离性:**与虚拟机相比,docker 隔离性更弱,docker 属于进程之间的隔离,虚拟机可实现系统级别隔离。
- 安全性: docker 的安全性也更弱。在特权模式之下运行的Docker 容器,其 root 和宿主机 root 等同;一旦容器内的用户从普通用户权限提升为 root 权限,也就直接具备了宿主机的 root 权限,进而可进行一些对宿主机不安全性的操作。
虚拟机中用户的权限与宿主机中的用户完全是无关的、是属于被硬件隔离。这种隔离技术可以防止虚拟机突破和彼此交互。
- **可管理性、高可用和可恢复性:**docker 容器技术本身对于容器的集中化管理、高可用和可恢复性方面是不太成熟;但Kubernetes作为容器集群管理系统,提供了容器集中化管理、容器高可用和容器可恢复性方面等各方面一整套完整的容器管理解决方案。而虚拟机技术方面,各虚拟机厂商也提供了完备的虚拟机管理能力,比如VMware vCenter。
- **交付、部署、分发:**虚拟机可以通过镜像实现环境交付的一致性,但镜像分发无法体系化;Docker 在 Dockerfile 中记录了容器构建过程,可在集群中实现快速分发和快速部署;
由于容器技术无论是在容器大小上要小一个数量级、还是在运行阶段所占用的内存和资源更小,因而容器化技术很快在系统级别部署上成为运维团队的首选。但容器技术本身是缺乏成熟的容器集中化管理方案,而Kubernetes的横空出世,正好补足了这个短板。
