背景说明
2020年5月13日下午,国家发展改革委官网发布“数字化转型伙伴行动”倡议。倡议提出,政府和社会各界联合起来,共同构建“政府引导—平台赋能—龙头引领—机构支撑—多元服务”的联合推进机制,以带动中小微企业数字化转型为重点,在更大范围、更深程度推行普惠性“上云用数赋智”服务,提升转型服务供给能力,加快打造数字化企业,构建数字化产业链,培育数字化生态,形成“数字引领、抗击疫情、携手创新、普惠共赢”的数字化生态共同体,支撑经济高质量发展。
企业在数字化转型的过程中,会碰到以下的难点、痛点:
- 集群问题
自建Hadoop集群时,性能需自行优化,无法及时进行组件版本的更新,组件稳定性和兼容性不够可靠;
- 新平台上手问题
商业大数据平台功能多且繁杂,且模块多相互耦合,上手难度大,用不好也用不会,难以发挥效能;
- 异构数据源问题
数据接入和运用的数据源种类多,异构数据源的转换,统一纳管问题;
- 数据孤岛问题
数据不共享、不流通,无法实现跨领域的数据分析与数据创新;
- 数据资产管理问题
缺乏对于库表的统一管理和视图,无法进行统一纳管;缺乏企业数据体系标准和数据规范定义方法论,数据定义不统一,数据无法复用;
- 运营效率问题
缺乏高效的数据运营分析工具,数据运营成本高;数据未服务化,数据拷贝多、口径不一致,数据重复开发,造成资源浪费;
产品发展
天翼云大数据平台 翼MapReduce(简称翼MR)是天翼云推出的一站式开源大数据平台产品,包含数据基础能力底座和翼MR Manager,数据基础能力底座通过对大数据生态组件进行产品化封装,支持海量数据存储、海量数据分析、实时处理等行业应用;翼MR Manager提供提供专业、全面的大数据运维能力,包含:集群服务管理、租户与资源、配置中心、监控与告警、运维自动化、日志管理等功能,提高大数据运维从业人员的工作效率。
从2015年开始,天翼云大数据团队立足于中国电信集团大数据集群的维护管理工作。天翼云大数据研发历经了从CDH消化吸收、开源Hadoop3集成开发、国产化替代升级的阶段。

此外在产品的功能丰富度上,我们栉风沐雨、砥砺前行:
- 技术架构由“灰”变“红”,由“少”变“多”,标志着天翼云大数据平台的自研能力逐步提升

产品能力
数据基础能力底座提供了数据的存储和计算能力,所有和大数据相关的存储和计算功能都基于该模块执行。数据基础能力底座中可用的大数据组件有:分布式存储数据库HDFS、列式存储数据库HBase、数据仓库Hive、数据批量计算引擎MapReduce、通用快速计算引擎Spark、流式计算引擎Flink、数据总线Kafka、OLAP查询引擎Trino、实时数仓Doris、检索分析系统ElasticSearch、文件抓取工具Flume等大数组件。
翼MR Manager主要提供大数据集群运维能力,通过可视化、流程化的方式对大数据集群资源和数据资产进行管理,并支持自动化的运维调度,统一运维监控报警,支持多租户管理,运维自动化等功能,提高大数据运维从业人员的工作效率。运维模块提供集群服务管理,为用户快速掌握环境、集群、主机、组件服务等数据信息;提供运维自动化管理,可以自定义作业模板和自动化运维流水线,灵活管理操作日常集群、组件级别的启动、停止、部署以及配置同步等运维操作,提高大数据运维效率,降低人力成本;提供监控、告警大屏功能,实时展示主机、集群级别的监控报警信息,用户可以及时感知大数据平台整体健康状态;提供HDFS目录浏览器,用户可对HDFS目录实现界面化增、改、查以及权限管理等操作;提供集群资源管理,方便用户对集群队列资源、租户资源等进行日常运维管理。
大数据平台,覆盖客户多场景业务需求:
批量数据处理
HDFS集群负责存储海量日志数据。
YARN集群负责调度离线平台上运行的所有任务。
Hive、Spark、Trino等主流计算框架从数据加工、数据挖掘到数据分析,快速获取数据洞察力。
分析后的数据回写进HDFS集群,为上层数据可视化等产品提供数据支撑
离线数据分析
将海量数据通过导入或者外表等形式引入到OLAP分析引擎里,例如,Trino提供高效、实时和灵活的数据分析能力。
满足用户画像、人群圈选、位置服务、BI报表和业务分析等一系列的业务场景。
流式数据处理
基于SparkSreaming和Flink流式计算框架,对各类业务日志或者消息等实时数据进行分析处理。
相应分析结果同步进HDFS集群存储服务中。
在线查询
基于Web和移动应用程序等生成的PB级别的结构化、半结构化或非结构化数据进行在线分析。
方便客户的Web应用或者数据可视化产品获取分析结果进行实时展示。
湖仓加速联邦分析
支持以外表的形式查询Hive、Iceberg、Hudi、Oracle、MySQL、PostgreSQL等数据库
性能相比Trino有3倍提升,相比Hive有10倍以上提升
应用案例
- 信通院APP监管平台
大数据平台 翼MapReduce助力信通院建设全国APP监管平台,提供移动端APP检测和监测等功能,为用户隐私安全保驾护航。

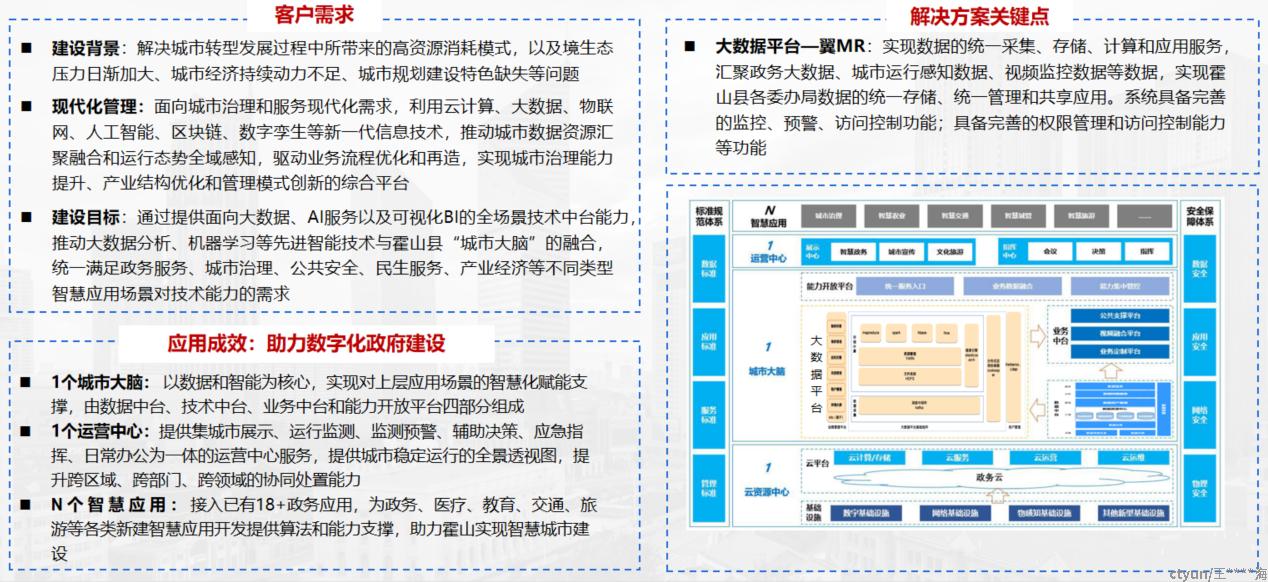
- 霍山城市大脑
大数据平台 翼MapReduce助力霍山建设智慧化城市,构建高性能、高可靠的统一大数据存储分析平台。