


1 事务基础知识
1.1 ACID事务
事务是访问数据库的一个操作序列。事务的正确执行使得数据库从一种状态转换为另一种状态。这里的“数据库”是广义上的数据服务,包括RDBMS关系型数据库、NoSQL存储(如KV存储),也包含分布式一致性协调组件等数据服务。
事务有4个基本原则,ACID:
- 原子性(Atomicity):事务要么全部被执行,要么全部不执行。如果事务的所有子事务全部提交成功,则所有的数据操作被提交,数据库状态发生变化;如果有子事务失败,则其他子事务的数据操作被回滚,即数据库回到事务执行前的状态,不会发生状态转换;
- 一致性(Consistency):事务的执行使得数据库从一种正确状态转换成另外一种正确状态;
- 隔离性(Isolation):并发执行的多个事务,相互之间互不影响。在事务正确提交之前,不允许把事务对该数据的改变提供给任何其他事务,即在事务正确提交之前,它可能的结果不应该显示给其他事务。
- 持久性(Durability):事务正确提交之后,其结果将永远保存在数据库之中,即使在事务提交之后有了其他故障,事务的处理结果也会得到保存。
1.2 事务并发问题
事务在并发处理时可能面临以下5类问题,顺便我们也看看事务操作的实际例子:
- 第一类丢失更新(Lost Update):回滚丢失。即A事务已提交的更新,被B事务的回滚操作给一同重置到了初始版本。
|
时间 |
事务A:取款 |
事务B:转账 |
|
T1 |
开始事务 |
|
|
T2 |
|
开始事务 |
|
T3 |
查询账户余额=1000 |
|
|
T4 |
|
查询账户余额=1000 |
|
T5 |
|
汇入100,余额=1100 |
|
T6 |
|
提交事务 |
|
T7 |
取出100,余额=900 |
|
|
T8 |
撤销事务 |
|
|
T9 |
余额恢复为1000(丢失更新1) |
|
- 第二类丢失更新(Second Lost Update):覆盖丢失。即A事务已提交的更新,被B事务的提交覆盖为错误值。
|
时间 |
事务A:取款 |
事务B:转账 |
|
T1 |
开始事务 |
|
|
T2 |
|
开始事务 |
|
T3 |
查询账户余额=1000 |
|
|
T4 |
|
查询账户余额=1000 |
|
T5 |
取出100,余额=900 |
|
|
T6 |
提交事务 |
|
|
T7 |
|
汇入100,余额=1100 |
|
T8 |
|
提交事务 |
|
T9 |
|
余额修改为1100(丢失更新2) |
- 脏读(Dirty Read):读到了其他事务还未提交的脏数据,其他事务可能回滚,导致本事务基于无效的值进行操作。
|
时间 |
事务A:取款 |
事务B:转账 |
|
T1 |
|
开始事务 |
|
T2 |
开始事务 |
|
|
T3 |
|
查询账户余额=1000 |
|
T4 |
|
汇入100,余额=1100 |
|
T5 |
查询账户余额=1100(脏读) |
|
|
T6 |
|
撤销事务 |
|
T7 |
取出100,余额=1000 |
|
|
T8 |
提交事务 |
|
|
T9 |
余额修改为1000 |
|
- 不可重复读(Nonrepeatable Read):在事务中两次读同一个数据,值不相等。
|
时间 |
事务A:取款 |
事务B:转账 |
|
T1 |
开始事务 |
|
|
T2 |
|
开始事务 |
|
T3 |
查询账户余额=1000 |
|
|
T4 |
账户余额充足,可以取款 |
查询账户余额=1000 |
|
T5 |
|
转出900,余额=100 |
|
T6 |
尝试取款500,再次查询余额=100,取款失败(不可重复读) |
|
|
T7 |
撤销事务 |
|
|
T8 |
|
提交事务 |
|
T9 |
|
余额修改为100 |
- 幻读(Phantom Read):在事务中两次读同一数据集,得到的结果不同,多了或少了数据。
|
时间 |
事务A:后台管理 |
事务B:柜台开户 |
|
T1 |
开始事务 |
|
|
T2 |
|
开始事务 |
|
T3 |
累加所有账户总金额SUM(M) |
|
|
T4 |
|
新开账户 |
|
T5 |
获取所有账户总数M+1(幻读) |
…… |
|
T6 |
计算账户平均存款额SUM(M)/(M+1),幻读造成分母错误。 |
|
|
T7 |
…… |
|
1.3 事务隔离级别
在数据库事务理论中,有以下4个等级的事务隔离级别,强度逐级递增,性能开销也越来越大:
- 读未提交RU(Read Uncommitted):能够读取到没有被提交的数据,最低级别,相当于没有隔离。所以很明显这个级别的隔离机制无法解决脏读、不可重复读、幻读中的任何一种。
- 读已提交RC(Read Committed):能够读到那些已经提交的数据。能避免脏读,但无法解决幻读、不可重复读。
- 可重复读RR(Repeatable Read):事务内两次读相同数据,保证读到相同的值。可防止脏读、不可重复读,无法防止幻读。
- 串行化(Serializable):最高级别的事务隔离。完全解决所有事务并发问题。
不同事务隔离级别所能解决的问题见下表:
表 3 不同事务隔离级别解决的并发问题
|
隔离级别 |
脏读 |
不可重复读 |
幻读 |
丢失更新1 |
丢失更新2 |
|
读未提交RU |
未解决 |
未解决 |
未解决 |
解决 |
未解决 |
|
读已提交RC |
解决 |
未解决 |
未解决 |
解决 |
未解决 |
|
可重复读RR |
解决 |
解决 |
未解决 |
解决 |
解决 |
|
串行化Serializable |
解决 |
解决 |
解决 |
解决 |
解决 |
1.4 事务隔离的实现
实现事务隔离的一般机制就是加锁。注意这里的锁并不是单纯解决线程安全问题的线程互斥锁——我们认为最基础的线程安全问题,在数据库设计时已经充分考虑了。例如的每个Put/Get操作,必定是线程安全的——本章节中的所有锁,都特指确保事务原子性的数据锁。
- 悲观锁:认为所有数据都可能被其他事务修改,所有需要读写的地方都主动加锁。
- 乐观锁:假设数据很少冲突,所以只在更新提交前检查数据是否已被事先修改,类似于CAS机制。
- MVCC多版本并发控制:引入版本控制机制,每个事务的写都分配一个独立revision,读也只允许读到已提交的revision。MVCC并发的多个读和一个写都不需要加锁,并发性能优秀,也不会有脏读、不可重复读、幻读。但MVCC不能解决第二类丢失更新问题,仍然需要配合锁(悲观锁或乐观锁)解决写-写冲突。
1.5 MVCC多版本并发控制
MVCC引入了版本控制机制,通过并行的多个版本,来实现并发事务隔离。MVCC在MySQL中有成熟的工程化应用实例,网上大多以MySQL的MVCC实现机制为例来介绍。而MySQL作为RDBMS数据库,事务实现细节较为繁琐。这里给出一个KV数据库可用的简化描述版本。
MVCC可通过revision标识每次数据库的修改,每当数据库产生一次修改记录,revision加1。
查询数据库时指定revision,可找到这个revision时刻所修改的数据,以及没修改到的上一版本所有数据,revision所对应的是这两套数据的集合。一个revision所代表的是这次修改后整个数据库的所有数据集合,是数据库某次修改的全量快照。
这样说可能不太好理解,考虑git的某次commit实际只修改了几个文件中的几行代码,但checkout指定的commit id,检出的不仅仅是这几行代码,而是这次commit修改后的全量数据。
因此具备MVCC机制的数据库,每次修改不会覆盖之前的数据,而是产生增量的数据拷贝,形成一份只读快照。已提交的revision,其数据不会再被修改。对已提交的revision做只读操作,可以不用加锁(特指针对事务原子性的数据锁)。
基于MVCC的事务,在开始事务时会得到两个revision:一个是用于只读请求的readRev,必定是已提交的revision;另一个writeRev则专为当前事务分配,所有写入都保存于此revision,并在commit时一并提交。
MVCC机制的示意图如下:
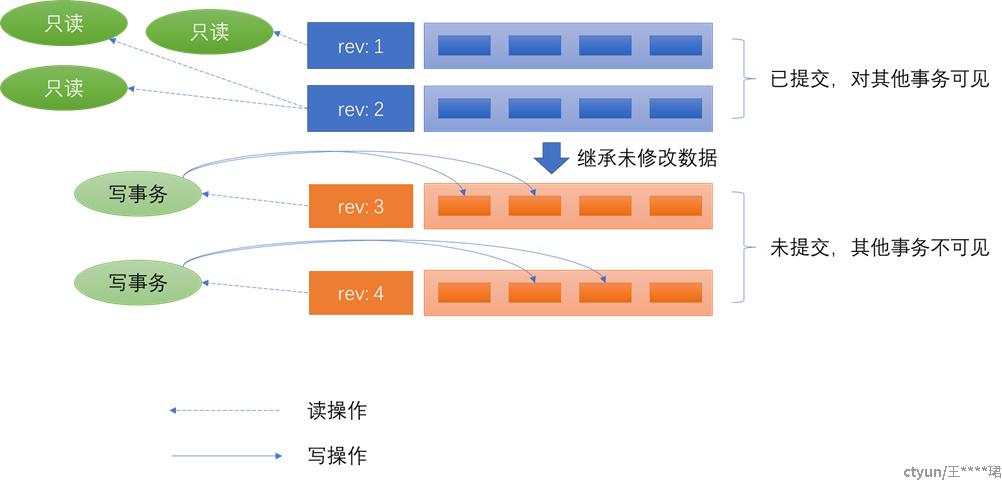
图 7 MVCC多版本并发控制
可以看到在MVCC中,读写是分开的,每个事务的写操作也完全分离,因此不需要借助额外的锁即可达到事务隔离的效果,具备极高的并发性能。但并发的多个写事务,仍然会有第二类丢失更新现象,最简单的做法是使用锁确保同时只有一个写事务。
在MVCC的实现中,事务可以读哪个revision版本的数据,由ReadView控制;事务可以写进哪个revision,由WriteView控制。
