


1. Stream简介
Stream是redis 5版本引入的一种数据结构,用于模拟消息队列功能。它除了提供Pub/Sub功能之外,还可以满足类似于topic场景的更高级应用效果。它的底层基于基数树实现。
参考资料:
Stream介绍:http://www.redis.cn/topics/streams-intro.html
基数树:https://www.jianshu.com/p/8abdfe63e525,https://blog.csdn.net/cowbin2012/article/details/90041486
2. 基本概念
-
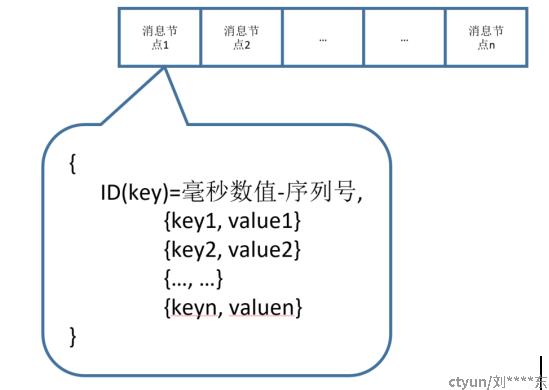
- Stream:一个stream对应一颗基数树,树上节点以消息ID作为key进行排序,如果我们简单把它理解成队列,则它存储消息的格式如下:
- Group: 消费组,消费组内包括stream(被消费队列),消费者和pending队列,他们的关系如下:
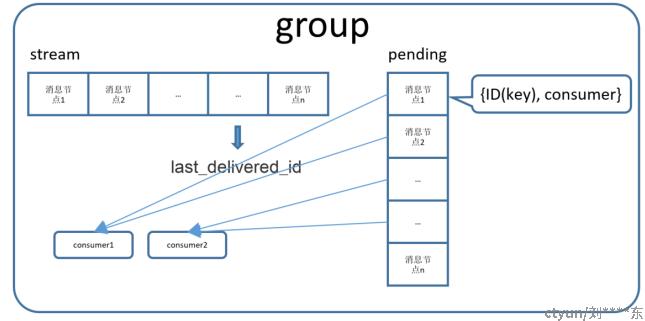
在group中,last_delivered_id指向group消费的位置;pending队列存储当前已经被consumer拿取但consumer还未回复ack的消息;pending节点存储消息ID和对应消息的消费者。
Group保证消息只分发给组内某个消费者,而不会造成组内重复消费;消费消息流程:
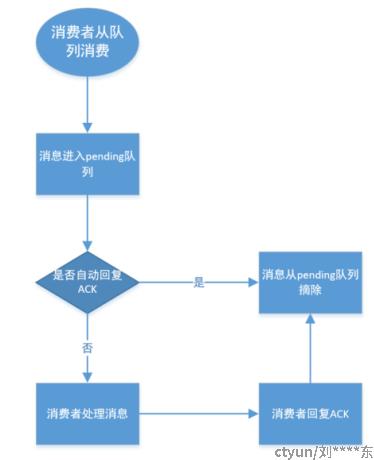
以上可以看出,消息从始至终都没有从stream上删除!即使消费者回复了ACK,也仅仅是从pending队列中删除,从pending队列中删除的消息不可以被队列重复消费。
图示中仅画出了一个stream和两个consumer。但其实一个group可以包含多个stream和多个consumer。每个stream可以属于多个group。但每个consumer只属于某个group。这种对应关系可以构造很复杂的消费系统,但当前我们的需求不需要这么复杂。
Consumer: 消费者,组内consumer可以同时消费同一个stream,也可以消费不同stream,若消费同一个stream,group会保证他们不会消费相同消息。每个consumer都属于某个group,group1的consumer1和group2的consumer1不是同一个consumer,虽然他们可以同一个线程。
3. 命令说明
xadd 队列名 序列号 key1 value1 key2 value2 … … keyn valuen
xadd用于向stream添加消息,当strem不存在时会自动创建stream。其中序列号格式为x-x,通常来说我们不需要主动生成序列号,让系统自动根据时间来帮我们创建即可,此时序列号可以传*,例子如下:

添加成功会返回序列号信息,本次创建生成的序列号为16003217208763-0,它表示生成消息的时间据1970年1月1日过去了16003217208763毫秒,他是这个时间的第一个消息。
另外可以通过加入maxlen来设置strem的长度:

其中maxlen ~ 10表示stream长度设置为比10大,但不是一个精确的数值,比如strem的长度可以时11,15,或者17。如果不带 ~ 符号,即maxlen 10则表明精确设置stream长度为10,若超过长度则会发生消息截断,会从最老的消息开始进行删除,以满足maxlen的最大长度。Redis官网建议使用maxlen ~ 10方式,这样会使Redis对长度检测的效率更好。另外需要注意:设置maxlen并非是一个常属性,也就是说maxlen仅仅会在xadd的当次有效!所以为了确保stream长度,必须每次xadd都要带上maxlen参数。
xdel 队列名 消息ID1 消息ID2 … … 消息IDn
xdel用于从strem中删除消息,前面说过,group消费消息,消息并不会从strem删除,如果要从strem上删除消息,唯一的办法就是用xdel命令,例子如下:

命令返回成功删除的消息数量。
xgroup [create 队列名称 group名 起始消息ID] [setid 队列名称 group名 起始消息ID] [destroy 队列名称 group名] [delconsumer 队列名称 group名 consumer名]
xgroup是对group操作的命令,它支持4种子命令,如上面[]中都是一个子命令。
Create用于创建group,其中“起始消息ID”表示group创建后,它从哪里开始消费,如果ID是0则表示从头开始消费,如果ID是具体的某个消息ID值,则表示从此消息的下一个消息开始消费,如果ID是$则表示从创建group的时间点之后的消息开始消费,例子如下:

返回OK表示创建成功,其他失败场景包括同名group已经存在,stream不存在等。若stream不存在,可以通过参数mkstream指定创建,如:

命令中queue_3本来不存在,因为增加了mkstream所以创建group的同时创建了一个空stream
destroy子命令用于销毁group,销毁的是group,不会销毁stream,即使stream是空,例子如下:

成功返回1。
delconsumer子命令用于删除group中的consumer。例子如下:

返回consumer持有的消息数量。即使将group中消费者删空,group也仍然存在。
xpending 队列名称 组名称 [起始ID 结束ID 数量] [消费者名称]
xpending用于读取消费中的信息,即已经从stream读取但未回复ack的消息。其中[]内的为可选参数。xpending记录的信息包括未回复ack的消息id和对应的消费者,并没有记录消息的具体内容。如果需要读取消息内容,需要根据消息ID调用xrange进行读取。例子如下:
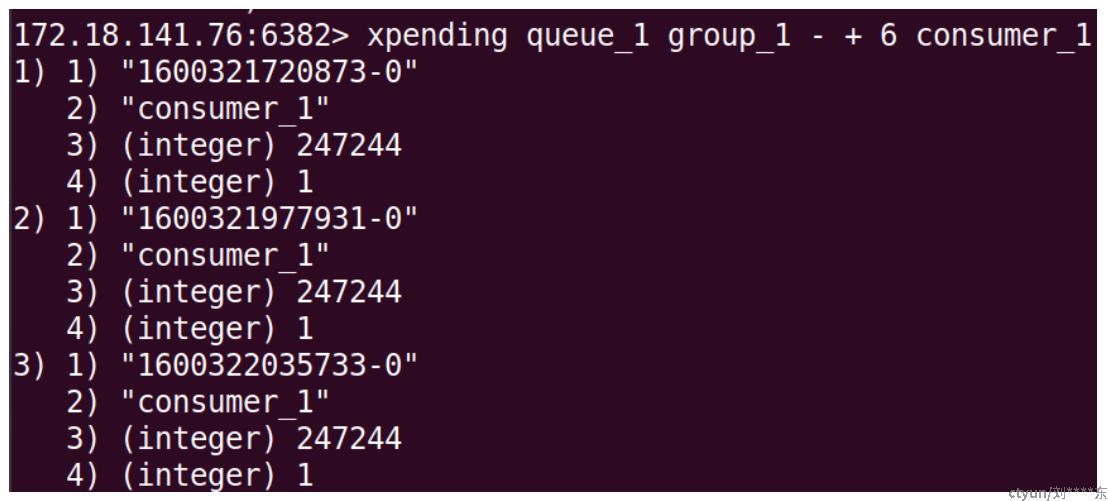
返回消费中的消息ID和对应的消费者等信息。其中,“-”“+”表示用于表示消息范围从最小到最大。
xack 队列名称 组名称 消息ID1 消息ID2 … … 消息IDn
xack命令用于回复消费的消息,表明消费完成,对于消费组来说,回复ACK后,消息将从pending队列摘除。消费消息时可以指定是否自动回复ack,我们当前使用场景中,都是手动回复ack,以保证故障时备份节点能识别哪些消息没有消费完成。例子如下:

返回回复ACK成功的消息数量。
xrange 队列名称 起始ID 结束ID [count 读取的数量]
xrange命令用于读取队列中的消息,它的起始ID和结束ID是闭区间,其中,起始和结束间的消息数量和可选参数count取两者中最小值为读取的真实数量。另外,xrang与消费组无关,是单纯的读取方法,所以也不会产生pending消息,也无需回复ack。在我们当前场景中,主要用于配合xpending读取消息详细内容。例子如下:

命令返回消息ID和消息内容。
xread [count 读取的数量] [block 阻塞时间(毫秒)] [noack] streams 队列1 队列2 … … 队列n 消息ID1 消息ID2 … … 消息IDn
xread用于读取队列消息,与xrange一样,它也是消费组无关的读取方式,与xrange不同的是,它的读取分为阻塞读取和非阻塞读取。
非阻塞读取,例子如下:
注意当id填0的时候,会从第一个消息读起,id是具体消息id的时候,从ID指定的下一个消息读起。因此xread可以用于遍历读取。它的不方便之处在于读取的是ID指定的下一个消息而不是ID消息本身,所以如果我们想要读取某一ID的消息,需要用xrange,将xrange的start和end指定同一个ID即可。
阻塞读取,例子如下:

这里有两点说明,第一通过参数block指定阻塞的时间,如果填0则表示一直阻塞;第二是ID指定为$,表示从stream读取最新数据,如果没有最新数据则阻塞。另外,阻塞读取并非ID一定是$,也可以是某个具体消息ID,比如倒数第二个消息ID,但指定count为2,因为xread从指定的ID下一个开始读取,那么传入倒数第二个ID,读取到的是最后一个消息,但因为count指定为2,所以还有1个消息没有读取到,此时也会引发阻塞。
xreadgroup group 组名 消费者名 [count 读取的数量] [block 阻塞时间(毫秒)] streams 队列1 队列2 … … 队列n 消息ID1 消息ID2 … … 消息IDn
xreadgroup读取消息的参数与xread基本相同,但是多了组名和消费者名,该命令是按消费组消费消息。读取消息时也分为阻塞读取和非阻塞读取两种,两种方式与上面介绍的xread基本相同,不再赘述。需要说明的是,xreadgroup读取时可以指定是否自动回复ack,如果携带noack参数则表示自动回复ack,否则需要手动回复ack。额,这里的语义看起来比较奇怪,noack表示自动回复ack。例子如下:

其中,ID用“>”表示从未消费的第一个开始读起。
其他消息包括xclaim(故障转移)、xlen(获取stream长度)、xinfo(获取strem/group/consumer信息)、xrevange(反向xrange)、xtrim(stream截断)等命令,我们暂时用不到。感兴趣的可以自行研究。
