


1 整体业务流程
业务流程分为前处理和后处理两部分,以前处理为例,说明整体业务处理逻辑如下:
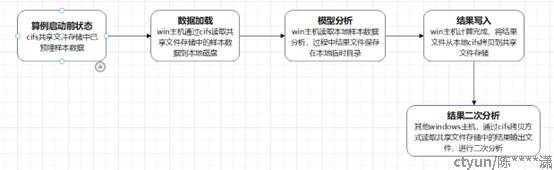
- 算例启动前状态:算例样本数据预先已存入共享文件系统中,此步骤属于预操作,可暂不关注
- 数据加载:多台windows计算节点(客户反馈最大750台规模)并行通过cifs协议访问共享文件系统,将算例样本输入数据,通过拷贝方式复制到计算节点本地磁盘中(对于单台计算主机,是目前单线程拷贝动作)
- 模型分析计算:此步骤为计算节点本地实现,中间会生成结果文件,存入计算节点本地磁盘临时目录,与后端共享文件存储无交互
- 结果写入:多台windows计算节点,将运算完成后本地临时目录中的结果文件,通过cifs拷贝方式(目前为单线程)写入共享文件存储
- 结果文件分析:其他windows主机,通过cifs拷贝方式读取共享文件存储中的结果输出文件,进行二次分析并本地呈现
综上,步骤1是预处理暂不关注,步骤2)、4)、5)是涉及存储IO交互的,用户比较关注批量文件的读入/读出耗时。
后处理流程与前处理近似,算例输入数据、计算模型、结果输出数据上会有差异。
整体业务耗时情况:
数据加载和结果写入耗时都是分钟级,半小时以内;模型分析计算耗时是小时级,整体属于计算密集型。
2 数据文件结构
- 前处理部分:
计算输入样本数据:总量几十MB,单个KB级,此部分数据量很小,拷贝耗时秒级;
计算输出结果数据:总量几个g到几十g,文件分布60%为1MB以下,剩余为MB级
- 后处理部分:
计算输入样本数据:总量几个~几十GB级,文件分布60%为KB级,40%为MB级;
计算输出结果数据:总量上百GB级,文件分布60%为KB级,40%为MB级
- 以一个测试样本数据(数据总量同比缩小),分析如下:
|
文件总量2.75GB,共5个目录,单个目录下文件62个,单目录总计562MB |
||
|
单目录下文件大小范围 |
文件个数 |
个数占比 |
|
80MB |
6 |
9.7% |
|
10MB~20MB |
2 |
3.2% |
|
1MB~10MB |
18 |
29.0% |
|
100KB~1MB |
12 |
19.4% |
|
100KB以下 |
24 |
38.7% |
3 业务场景预期性能
750台windows主机并行cifs访问,在数据加载过程总计性能可达15GB/s,即单台主机要求可达20MB/s以上
