



故障描述
redis机器的一个ssd盘出故障,只能读不能写。其他盘写入速度也很慢。导致redis实例的aof刷新一直失败,最终挂掉。
故障原因
ssd盘早期没有格式化好,4k对齐没做好
处理过程
该redis机器是用来存储collector采集到的日志的meta信息,比较关键,而且一台机器上开启了8个redis实例,所以不好处理。
一开始准备把redis的aof文件转移到一个新的盘上,并且把aof的dir动态更改到其他盘,结果发现redis实例挂掉了,就没有动态更换aof目录。这其中,redis的数据可能有所丢失,不过通过collector和redis日志发现,磁盘挂了后redis写入已经失败,估计有丢失数据也不多。collector有实现meta写入redis失败时转为写入本地磁盘,所以在redis实例down掉时,数据也不会丢失。
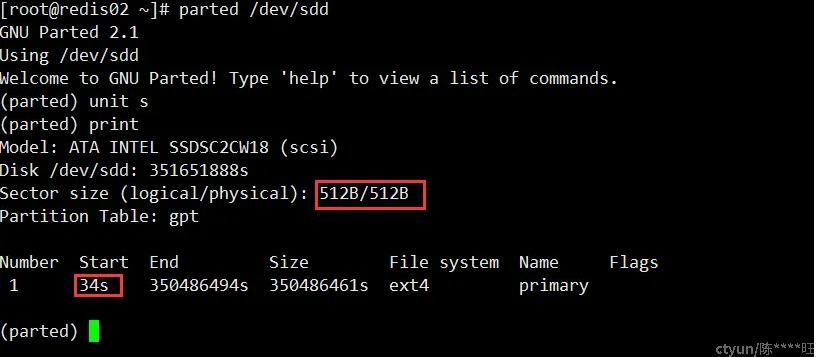
接着,处理4k对齐。先把所有redis实例进行bgwrite. redis-cli -h redis02 -p 6379 bgrewriteaof, 停掉所有redis实例。
处理4k对齐, 重启机器。结果发现机器重启失败,阵列卡或线松了。
重启机器后,赶紧把所有aof文件都备份到其他机器上。结果有发现,有一块盘丢了,尝试mount回来。发现有很多block错误,要修复又怕丢数据。但现在盘有错误,只能先fsck修复,如果修复成功再从里面拷贝出来。要是觉得不保险,就先备份正常盘的数据,空出一块盘,把cache3的盘做个镜像,再做修复。最后aof文件终于弄出来了,启动redis实例,发现aof文件有问题,启动失败。使用redis-check-aof --fix修复了aof文件,再启动,成功。redis数据是被截断一部分丢失了。
数据恢复后,开始重新把redis机器上的ssd盘一个个重新格式化。
经验教训
因为redis的meta信息,是衔接collector采集,以及storm处理和hadoop camus入库。本次redis故障,大动干戈,对集群影响比较大。
还好collector有redis失败转存文件的功能,所以日志采集一直正常。
接下来的深圳新机房,存储meta的redis准备使用cluster,避免单点故障。保障可用性。
