


Introduction
RisingWave
RisingWave是数据库初创企业Singularity Data Inc.(中文简称奇点无限)开发的云原生流式数据库,主要服务于需要超低延迟实时数据分析应用。RisingWave 于 2021 年初使用C++语言执行构建,并在为期七个月的时候使用Rust语言进行全面重构,这意味着27 万行 C++代码库被彻底弃用。对于初创公司,这无疑是一个疯狂的决定。
2022 年 4 月,“奇点无限”开源了 Rust 编写的 RisingWave
RisingWave是一个使用SQL作为接口的云原生流数据库。它旨在降低构建实时应用程序的复杂性和成本。RisingWave使用流数据,在新数据进入时执行增量计算,并动态更新结果。作为一个数据库系统,RisingWave将结果保存在自己的存储中,以便用户可以有效地访问数据。您可以将数据从 RisingWave 接收器到外部流以进行存储或额外处理。
RisingWave接受来自Apache Kafka,Apache Pulsar,Amazon Kinesis,Redpanda和物化CDC来源的数据。它支持将数据输出到Kafka流。
Apache Flink
Apache Flink是一个开源流处理框架,用于在无界和有界数据流上进行有状态计算,其核心是用Java和Scala编写的分布式流数据流引擎。Flink以数据并行和流水线方式执行任意流数据程序,并同时支持批处理。
2019年,阿里巴巴以 9000 万欧元的价格接管了总部位于柏林的创业公司 Data Artisans,看重的就是其背后Flink这项核心技术。针对阿里的电商业务,其高级技术专家王绍翾在一次采访中说道:“我们当时尝试过很多实时计算工具,什么Spark Stream、Kafka Stream、Storm....都用了,但是都不太符合阿里的需求。Spark streaming 不是特别适合于做秒级甚至亚秒级的计算;Kafka streaming 很难满足我们对大体量的复杂计算的需求;Storm 又没有批处理能力....最后,我们发现了Flink,并且惊喜地发现它几乎完美满足了我们所有的需求!”
阿里巴巴基于 Flink 搭建的平台于 2016 年正式上线,并从阿里巴巴的搜索和推荐这两大场景开始实现,目前服务于阿里集团内部搜索、推荐、广告和蚂蚁等大量核心实时业务。大企业的加入促进了Flink的生态建设,也逐渐成为目前主流的实时计算引擎。
Architecture
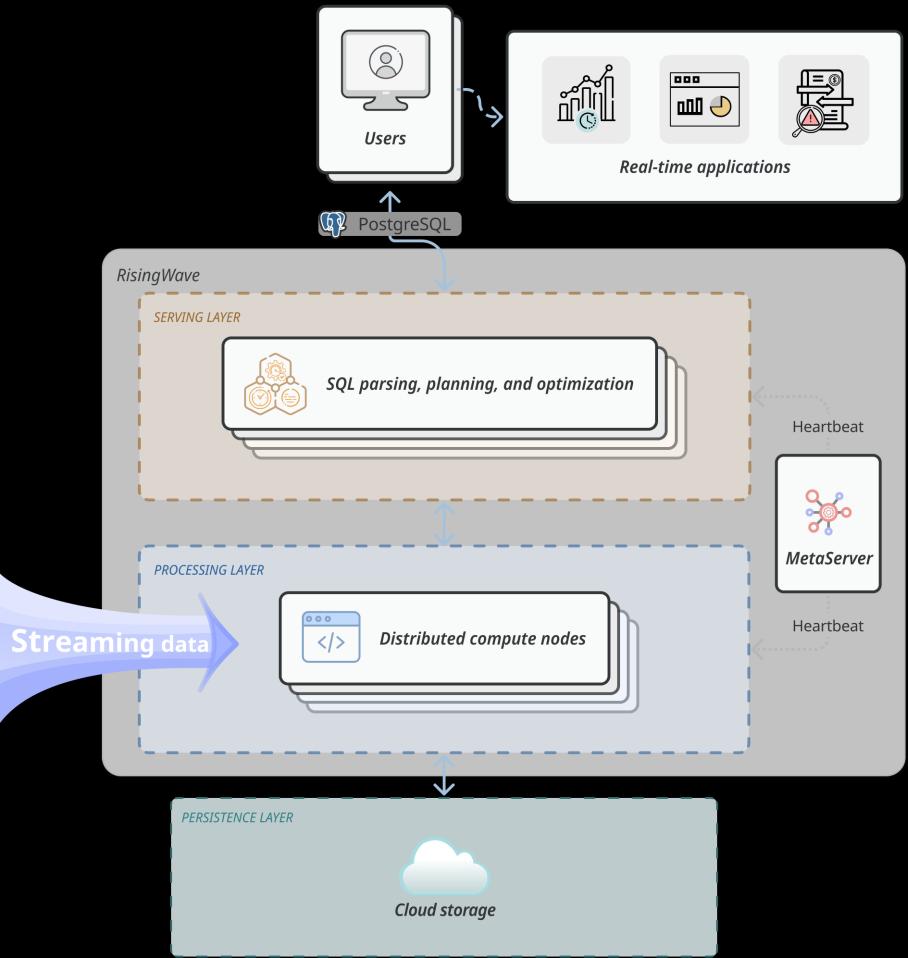
RisingWave包括以下关键组件:
- 分析 SQL 查询并执行查询作业规划和优化的服务层。
- 执行所有数据计算和状态更新的处理层。
- 协调服务层和处理层之间操作的元服务器。
- 一个持久性层,用于将数据存储到对象存储并从中检索数据,如 S3。
Flink 是一个分布式系统,需要有效地分配和管理计算资源才能执行流应用程序。它与所有常见的集群资源管理器(如Hadoop YARN和Kubernetes)集成,但也可以设置为作为独立集群运行,甚至作为库运行。
Flink 运行时由两种类型的进程组成:一个 JobManager 和一个或多个 TaskManager。
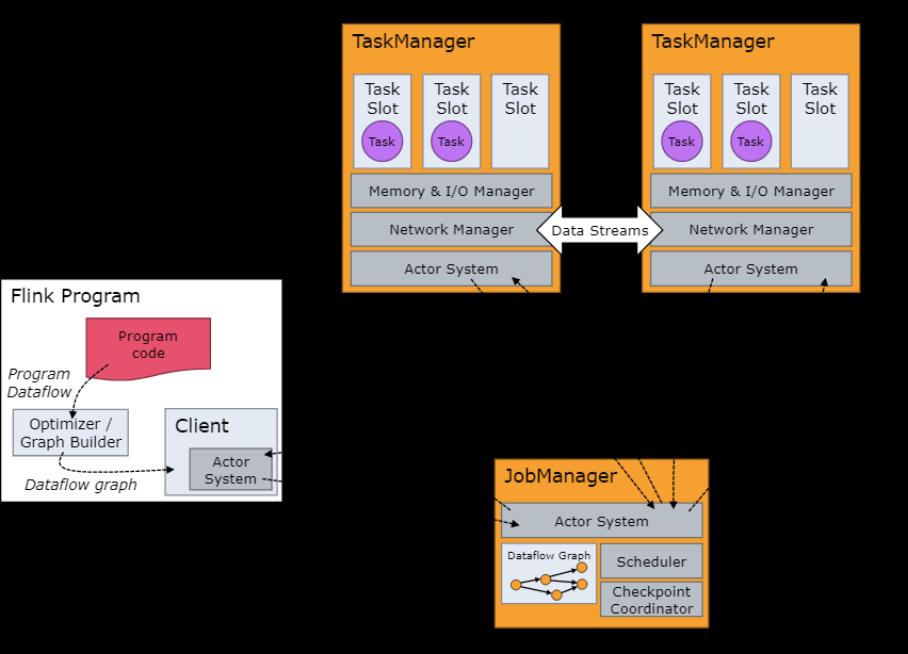
客户端不是运行时和程序执行的一部分,而是用于准备数据流并将其发送到 JobManager。之后,客户端可以断开连接(分离模式)或保持连接以接收进度报告(附加模式)。客户端作为触发执行的 Java/Scala 程序的一部分运行,或在命令行进程中运行。
./bin/flink run ...
JobManager和TaskManagers可以通过多种方式启动:直接在机器上作为独立集群启动,在容器中,或者由YARN等资源框架管理。任务管理员连接到 JobManagers,宣布自己可用,并分配工作。
RisingWave or Next Apache Flink ?
定位
Flink是一个流计算引擎,使用户能够处理流数据。因此它不负责保留用户数据或自发地进行查询优化,你可以使用Java/scala语言对处理逻辑进行编程定义。
RisingWave的核心是一个数据库系统。因此它负责消费数据并为最终用户的查询提供服务。区别于传统的SQL数据库,其官网介绍它还擅长以低延迟处理流数据。
目的
Flink 旨在在给定固定资源量的情况下最大限度地提高性能。其计算存储耦合架构使其能够以高昂的成本实现无限扩展。
RisingWave同样关心性能。更进一步的,RisingWave是为优化成本效益而量身定制的。在扩展时,您需要按实际使用量付费。由于计算与 RisingWave 中的存储分离,因此可以单独扩展。它采用分层架构,充分利用云资源,为用户提供对成本和性能的精细控制。
接口
Flink 原生提供了一个低级 Java API。虽然低级API为专家提供了完全控制底层数据流的能力,但它在开发和调试方面或许对于业余爱好者来说尚存在一定门槛。Flink还提供Stream SQL接口。[传统 SQL 都是基于有限数据集的,而为了解决流处理的独特要求,我们需要扩展一下 SQL 的语义,为其添加窗口结构(比如 sliding window)和流处理特定的算子等支持,这便是 Stream SQL]
RisingWave提供了一个与PostgreSQL兼容的标准SQL接口。用户可以像使用PostgreSQL一样处理数据流。当然了,流处理系统得是确定性并且可重复的,因此它不会支持 PostgreSQL 里的 Rand 或者 Now 等非确定性函数 。
高可用
Flink采用基于 checkpoint 的容错算法来保证精确一次。
RisingWave的状态管理与容错机制与之类似,它是一个基于固定 epoch 的 partial synchronized system。即每隔一个固定的时间,中心的 meta 节点会产生一个 epoch,并会向整个 DAG 的所有 source 节点发起 InjectBarrier请求。source 节点收到 barrier 后,将其注入到当前数据流的一个切片。
分布式与自动扩容
分布式流系统需要支持多线程,同时具备自动扩缩容以及负载均衡。这往往意味着系统希望避免对每条记录都去加锁放锁,否则频繁的加锁放锁操作势必会大幅影响性能。
对于 Flink 等基于 Dataflow 模型的系统,其每个状态都只有一个线程会去读写,所以状态访问时不需要加锁;
RisingWave 目前是通过 KV 存储里面的 keyspace 概念来避免加锁放锁操作,也相当于给不同线程做了一个存储隔离。不过相关部分正在演进中。
生态
Flink是一个与大数据生态系统深度融合的大数据系统,它已有集群基础设施和服务之上专注于它的核心功能--分布式流数据处理。尽管它支持standalone模式,但生产环境中用户通常需要将 Flink 与其他开源大数据系统(如 Zookeeper、HDFS 和 Yarn)一起部署。
然而,RisingWave是一个与云生态系统完全集成的云原生系统。RisingWave是现代数据堆栈不可或缺的一部分:用户可以将RisingWave与云中他们喜欢的任何系统连接起来,例如Apache Kafka,Apache Pulsar,Redpanda,Amazon Kinesis等。RisingWave与PostgreSQL的兼容性进一步允许用户访问繁荣的PostgreSQL生态系统。
操作
Flink的操作相当困难且昂贵,因为它深深植根于大数据堆栈中。操作 Flink 本质上需要用户使用多个系统,包括 Zookeeper、HDFS 和许多其他系统。用户可能必须手动重新配置系统,以便在面对工作负载波动时实现更高的效率。
RisingWave的云原生设计大大降低了系统操作的标准。RisingWave不依赖于任何大数据服务,其解耦的计算和存储架构大大简化了弹性的管理。
目标用户
Flink的目标用户大多是数据工程师和专家。运营成本和学习曲线使业余用户难以充分利用 Flink 的强大功能。
RisingWave不仅针对工程师,还针对数据科学家,分析师,决策者以及任何需要新结果的人。它可以在云中轻松部署和维护,并且可以在几乎没有人为干扰的情况下实现弹性。它的PostgreSQL风格的SQL也使用户可以轻松编程他们的流媒体应用程序。
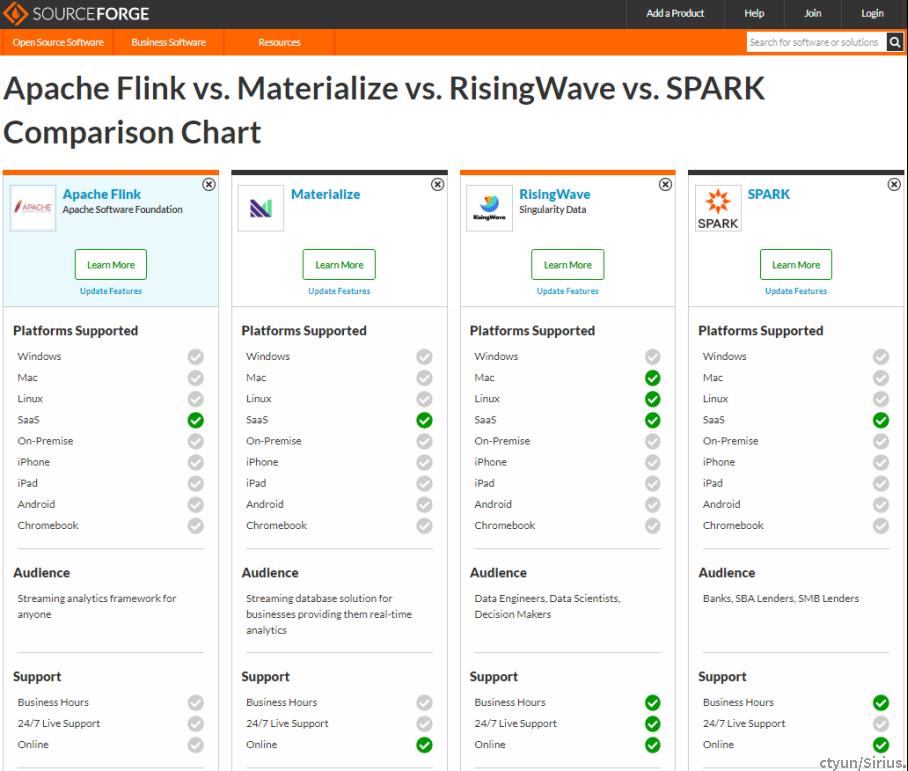
Comparison Chart
借助SOURCEFORCE对于目前流行的实时计算类产品进行了多维度比较:主要集中在平台支持、受众、售价、产品类型、生态、集成性等方面。
总结
多快才算实时?
比如说,实时系统一般默认指实时操作系统,和这一概念相比,实时流处理系统的实时属性其实并不强。
大家平时说的实时流处理系统往往指 Flink 这种亚秒级延迟系统,像 Spark Streaming 这种秒级延迟的系统有时就被称为准实时系统,而实时 OLAP 系统则通常是分钟级或亚分钟级的延迟。
当然,实时操作系统和实时 OLAP 系统不能和流处理系统直接相比,同一个系统上跑不同的查询其延迟也可以天差地别,但这些系统其总体延迟的相对关系大抵如此。
怎么才能实时?
为了系统能够“搞快点”,几种常见做法主要包括:牺牲系统通用性、扩大集群规模、做些工程优化、利用各种新硬件、进行预计算等。
降低系统通用性最典型的例子就是时序数据库。时序数据库是一种特殊的分析型数据库,它通过牺牲系统的通用性换取了相当可观的性能提升,甚至时序数据库之间还会进一步将所面向的应用场景切分成 IoT、金融等不同领域。
扩大集群规模,则大家看法不同。比如 RisingWave 就面向分布式而设计,直接进行云原生。
工程优化方面,比方说放弃 Storm、Flink 等大数据框架中常用的 JVM 语言,转而像 RisingWave 和 Materialize 那样使用 Rust 这种底层语言;放弃流处理引擎中通用的 RocksDB,转而像 RisingWave 和 Materialize 那样自己定制一些轮子。
至于预计算,传统数据库对于 materialized view 支持的不是很好,常常是周期性更新 materialized view 之类的,做法比较粗暴。但 materialized view 其实非常重要,比如 Flink 就基本上是在对原始数据做 materialized view,所以出现了 RisingWave 和 Materialize 这种算是专门针对 materialized view 而构建的流数据库。
