


1 当前VXLAN隧道建立机制
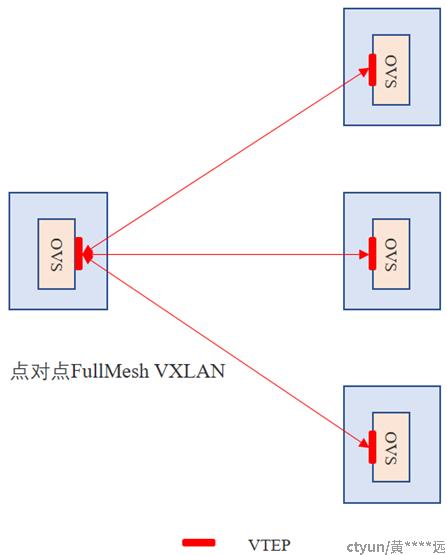
上图为当前Openstack Neutron静态点对点VXLAN隧道模型:
1) 每个节点需要和其他节点建立静态的点对点VXLAN隧道,节点上VXLAN子接口的数量=集群节点数-1。
2) BUM报文泛洪会往本节点上的所有VXLAN子接口复制一份独立的报文发出去。
存在的问题:
1) 随着集群规模越来越大,节点数越来越多,单节点上需要创建的VXLAN子接口数则越来越多,最终会突破系统的上限值 。
2) BUM报文往所有VXLAN子接口泛洪报文,此种情况下,流量总大小=报文大小*VXLAN子接口数,因此,随着集群规模越来越大,单节点上VXLAN子接口数越来越多,BUM总流量很容易突破物理网卡的总带宽,进而严重影响正常业务流量的转发。
3) 非对称流量路径的情况下,总是以广播泛洪的方式发包。
4) 针对一些单向流量,无法根据回应报文自学习目标VXLAN隧道,因此同样会一直以广播泛洪的方式发包。
2 解决方案---动态VXLAN

上图为改进后的动态VXLAN隧道模型:
1) 计算/网络节点上仅创建1个VXLAN子接口,和集群节点数无关。由OpenFlow流表封装隧道外层IP地址。
2) 集中式二层网关集群是由多台节点组成的多活集群,拥有整个集群下所有VPC的二层转发信息。
3) 在计算/网络节点上,对于目标非本地的ARP请求,直接在本地做FakeMAC的ARP代答,避免ARP广播泛滥。
4) 计算/网络节点发出的首包,默认转发到集中式二层网关,在集中式二层网关,匹配精确单播流表,直接转发到目标计算/网络节点,同时,构造回应报文发回源端节点,触发源端节点主动学习目标单播流表。
5) 目标收到请求流量后,能够主动学习源端的单播流表。若需发响应报文,则匹配单播流表直接发回源端节点。
6) 源端节点收到目标端节点发回的响应报文,同样能够主动学习目标的单播流表。
7) 后续报文直接匹配学习到的单播流表,直接转发到目标节点。
改进后:
1) 能够按需动态建立VXLAN隧道,将广播域拦截在本节点内,避免BUM报文往所有节点广播泛洪。该方法可以有效解决上述的几个问题。
