


题目:Latency-based Vector Scheduling of Many-task Applications for a Hybrid Cloud
作者:Shifat P. Mithila
会议:2022 IEEE 15th International Conference on Cloud Computing (CLOUD)
摘要
这篇文章研究了在异构云资源上对多任务应用程序进行任务放置的问题。针对集中式调度器可能成为瓶颈的问题,论文提出了一种基于性能测量和延迟测量的分散式矢量调度方法。具体而言,每个节点在叠加图上收集其邻居的性能测量和延迟测量,然后做出关于任务移动的本地决策。还提出了一种集中式算法,用于配置叠加图,并扩展了矢量调度方法以考虑延迟信息。在CloudLab上进行的实验表明,这种方法比没有延迟信息时能够产生更好的性能和资源利用率。论文的研究可以帮助优化多任务应用程序在异构云资源上的任务分配和调度,提高应用程序的性能和资源利用率。
相关工作
传统的网格调度方法通过确定最优计算调度来高效利用资源,但对于大量机器的可用性变化、不可靠的网络和高昂的成本等问题来说,不具有可扩展性。大规模桌面网格系统通过主/工作模型实现了技术成熟,但主节点的性能对于数据密集型应用程序来说是一个瓶颈。云计算中的MapReduce和图并行算法在独立任务应用程序中表现出色,但是在需要频繁通信的细粒度并行应用程序中表现不佳。一些学者提出了基于中心化或分散化的调度算法,例如Gutierrez-Estevez等人提出的细粒度中心化资源调度器,以及Mohammadzadeh等人最近提出的多任务云应用程序的中心化调度算法。Organic Grid和IBM的Air Traffic Controller专利文件则分别探讨了分散化调度和智能自组织网络的调度方法。然而,这些方法在实际云环境中并不容易实现,因为云系统中任务来源分散,而Organic Grid和Air Traffic Controller方法的任务来源都是集中的。Peterson等人提出了一种基于向量调度的任务调度器,但他们的实验结果表明,任务传输等待时间导致节点在实验开始和任务执行之间的时间内处于空闲状态,从而导致计算时间的浪费和资源的不当使用。本文的工作通过使用通信延迟来创建覆盖网络并进行任务调度,解决了这个问题,并将空闲时间减少到最小,从而优化了整体计算性能。
简介
随着科学领域的发展,计算需求不断增加。云计算作为一种商业替代方案已经成为主流,研究人员可以从服务提供商那里租用计算需要。这使得研究人员能够更好地利用可用资源并利用分布式机器的联合资源,提高计算效率和降低成本。
当前面临的问题:虚拟化使得云计算行为类似于一个异构集群,节点的计算性能和网络连接的延迟和吞吐量存在差异。这对于粗粒度并行性的应用程序不是问题,但对于依赖于细粒度并行性或频繁节点间通信的高性能计算应用程序来说是一个挑战。例如:NAS MPI基准测试、大气监测程序或大型密集矩阵乘法等应用。
现有解决方法:使用多任务计算方法(many-task computing)是在网格和超级计算机上有效利用资源的一种被证明的方法。这种方法将应用程序分解成一组小任务,并对它们进行调度。例如,Rajbhandari等人成功地将量子化学张量收缩方程计算扩展到超过25万个核心,同时动态地在处理器组上调度任务,并通过工作窃取来平衡负载。在云中运行高性能或多任务应用程序需要确定云节点的性能特征,识别它们之间的网络连接,并将计算任务映射到具有适当性能特征的节点子集上。集中式任务调度程序维护所有这些信息可能会变得过于昂贵。因此,有多种方法被提出来解决这个问题,包括部分集中的方法和完全分散的方法。这些方法包括IBM的Air Traffic Control (ATC)算法、有机网格(OG)以及Peterson等人提出的基于轻量级矢量调度算法的云计算。这些方法各有优缺点,需要根据具体情况选择适合的方法。 贡献有三:(1)提出了基于性能和延迟测量的分散式矢量调度方法,用于在云资源上对多任务应用程序进行任务放置。(2)构建了一个基于延迟测量的中心化初始叠加网络,以替代随机生成的图形。(3)提出了一种新的三维任务调度策略,考虑队列长度(QL)、性能和延迟的因素。
基于延迟的中心化网络和任务调度
网路设计:论文旨在通过利用节点之间的通信信息来生成更好的初始叠加图,以实现更好的工作分配。与Peterson等人使用随机图不同,本文的方法是先建立一个全局图,然后利用延迟信息删除较慢和较远的链接,如下图。

具体来说,算法先构建一个全局图并将其发送给所有工作节点。每个工作节点接收到所有其他节点的信息后,收集它们的延迟测量并将它们发送回控制器。然后,控制器根据整个网络的通信信息使用分层聚类算法将工作节点分组。每个独立的集群或组形成一个团,即它们之间具有完整的图。每个组的延迟测量被分别排序,并为每个节点设置连接。如果集群大小超过6个节点,则每个节点将从其他集群中删除4个链接;如果集群大小在4到6之间,则删除2个链接;如果集群大小小于4,则不删除链接。这个删除大小设置为保持网络中每对集群之间的连接少于50%,以便任务在整个网络中均匀传播并与计算相竞争。每个组内部的连接将有助于加快任务的执行速度。这个初始叠加图将为工作节点提供通过相对较快的链接进行通信的优势。算法流程如下图。

环境搭建:为了在云中实现,从Cloudlab请求了少量物理机器(PMs)。然而,CloudLab集群中的物理节点之间的距离并不符合真实情况。为了模拟真实情况,设计了多个具有低通信成本和高成本的节点集群。通过对某些通信链接施加不同数量的人为延迟来实现这一点。工作节点之间的延迟测量是通过重复发送和接收一个字节来完成的,并测量往返时间。为了在节点-邻居链接中引入人为延迟,在发送和接收字节之前和之后,线程被休眠。每个实验由400个任务组成,其中每个任务是一个100x100的矩阵乘法。实验使用了46个工作节点,在Cloudlab Clemson集群的2个PM上进行调度。下图显示了机器配置的详细信息。

为了观察延迟对计算性能的影响,排除了其他可能影响性能的变量。为了实现这一点,设计了实验使得节点具有统一的性能,并将向量调度的性能参数保持为零。节点组部署在Docker容器中,模拟节点之间的延迟。容器内的节点之间没有额外的延迟,同一物理机内的节点组具有一些额外的延迟以模拟它们彼此之间略微远离的情况,而不同物理机的节点组之间的链接具有相对较长的延迟,以模拟它们作为远离彼此的集群。
实验:在模拟环境中进行实验,测试本文所提出的方法,并将结果与随机图形构建进行了比较。同时对比了不同的调度算法和图形结构,来证明方法的优越性。
实验结果显示,使用QL调度算法和20%的随机图形时,节点在实验开始和任务执行之间的空闲时间很多,这是由于任务传输到其他节点的等待时间造成的。为了改进这种情况,论文提出了使用延迟的中心化初始图形和支持延迟的3D向量调度进行实验,并与随机图形进行了比较。结果表明,在图形构建和任务调度中使用延迟可以最大程度地减少任务之间的空闲时间和初始延迟,并且可以提高计算性能。所有400个任务完成所需的时间从380秒降低到282秒,计算时间减少了约25%。下图是两个实验的比较结果。

同时,论文还进行了两个样本t-test,比较了随机图形和中心化图形构建的5个实验运行的整体计算时间。结果表明,中心化图形构建的性能明显优于随机图形构建,中心化图形构建的计算时间平均为297.5秒,标准差为10.52秒,而随机图形构建平均计算时间为317.6秒,标准差为12.28秒。t-test结果表明,两者之间存在显著差异(t(8)= 2.77,p = 0.05)。实验结果证明了基于延迟的网络中进行任务调度的有效性,并表明使用中心化的初始图形和支持延迟的3D向量调度可以显著提高计算性能。
节点性能变化下的实验
在之前的实验中,为了确保节点性能不会主导由延迟引起的变化,实验将其保持在最低限度,并发现在使用中心化图形构建时,整体计算性能优于随机网络。接下来,在节点性能的变化的情况对中心化图形的行为进行进一步的测试。为了模拟这种变化,将不同数量的工作节点放置在不同数量的CPU内核中。例如,分配给10个内核的5个节点不必像分配给2个内核的5个节点一样竞争网络带宽,因此会表现得更好。使用随机网络和QL性能调度以及中心化网络和QL、性能和延迟三维调度策略进行实验。当完成了约70%的工作时,调度策略从“initial”切换到“after swap”。在下图中展示了这些实验结果的比较图。
实验结果表明,在节点性能变化的情况下,使用基于延迟的中心化图形构建和调度可以显著改善整体执行时间,提高资源利用率。
同时,进行了双样本t-test,比较了两种图形构建之间的7次实验运行的整体计算时间。结果表明,在节点性能变化的情况下,中心化图形构建(M = 439.72,SD = 8.98)和20%随机图形构建(M = 456.4,SD = 4.45)之间存在统计学显著差异;t(12)= 4.402,p = 0.05。
任务量变化和使用虚拟机进行实验
本文讨论了在实验中使用不同大小的任务和通信开销的问题。作者的实验中所有任务的大小都相同,并且没有通信开销,因为矩阵是在每个节点上生成的。Vannikkarasan在他的实验中使用了不同大小的任务,并将任务所需的矩阵从一个节点传输到另一个节点,其中传输的矩阵始终具有相同的大小。这些操作是通过为任务传递不同的命令行参数来执行的,例如ChooseRandom、ChooseFromDisk等。这些任务是两个矩阵A和B的乘积。在ChooseRandom中,A和B都是随机矩阵,其中A的大小是随机的,B的大小在一定范围内。在ChooseFromDisk中,A是一个固定大小的矩阵,从文件中随机选择,B是一个随机大小的矩阵。
对于云中的虚拟机(VMs),节点的物理位置是不可预测的。因此,虚拟节点的性能特征和它们之间的通信行为可能非常不同,也是不可预测的。为了在实际环境中测试多任务应用程序,实验所能达到的最接近的情况是在一组VM中运行应用程序,每个工作节点都在单独的VM中。实验设计了47个VM的实验,其中一个是实验控制器,另外46个专门用于运行46个工作节点。
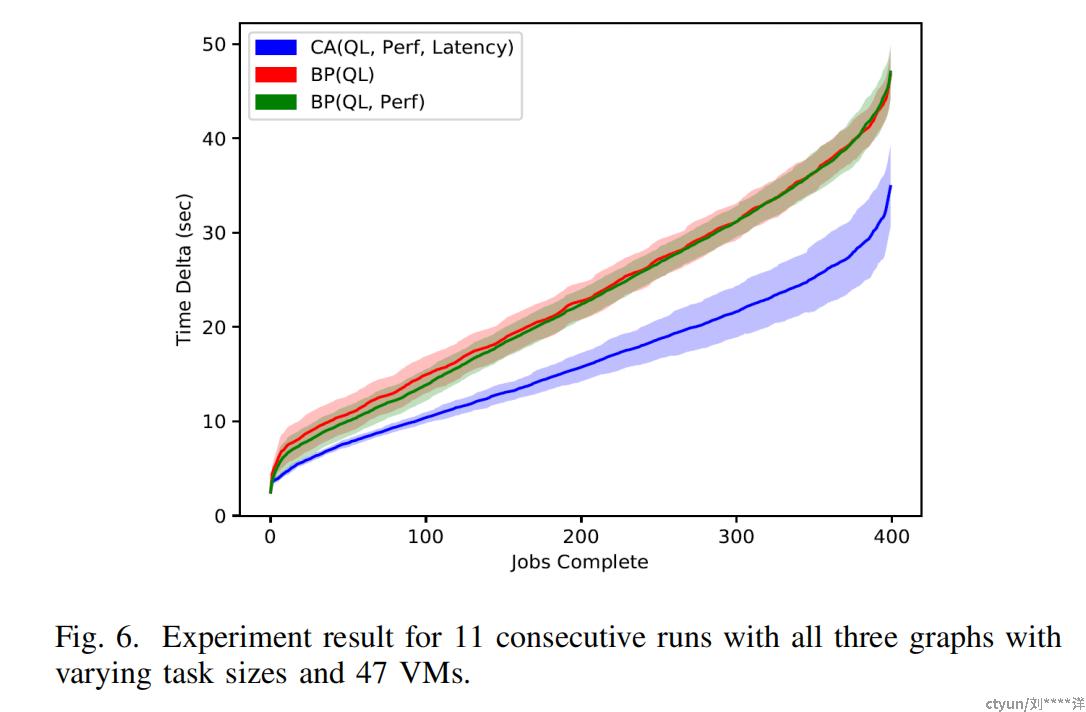
实验结果:实验从CloudLab Wisconsin站点请求了47个虚拟节点,并获得了由不同处理器类型的10个PM组成的47个VM,其中物理节点包含了不同数量的VM,范围从2到7个。对于应用程序,实验使用了类型为ChooseRandom和ChooseFromDisk的不同大小的任务。实验将本文的工作与在相同机器配置下使用1D(仅QL)和2D(QL和性能)调度策略的20%连通性的随机图的实验结果进行了比较。下左图显示了在47个VM中使用ChooseFromDisk方法进行不同大小的任务的2D调度的实验结果。每个节点任务条之间的间隙表示通过传输参数矩阵产生的通信开销。然而,使用基于延迟的中心化图形和3D调度允许更多任务移动到更接近的节点,实验中填充了空闲节点,许多任务在空闲时间内被调度,导致整体计算时间显着改善(见下右图)。

在下图中,使用了11个实验运行来更明显地显示三种不同图形和调度策略中任务传播和完成的性质。其中,中心化图形(CA)(蓝线)在QL仅(红线)和QL与性能(绿线)调度策略下都表现优于随机图形(BP)。这个图形表明,使用延迟来创建初始网络和调度任务显着提高了整个实验的计算性能,导致更低的总计算时间,而仅在任务调度中添加QL和性能并不明显影响性能。
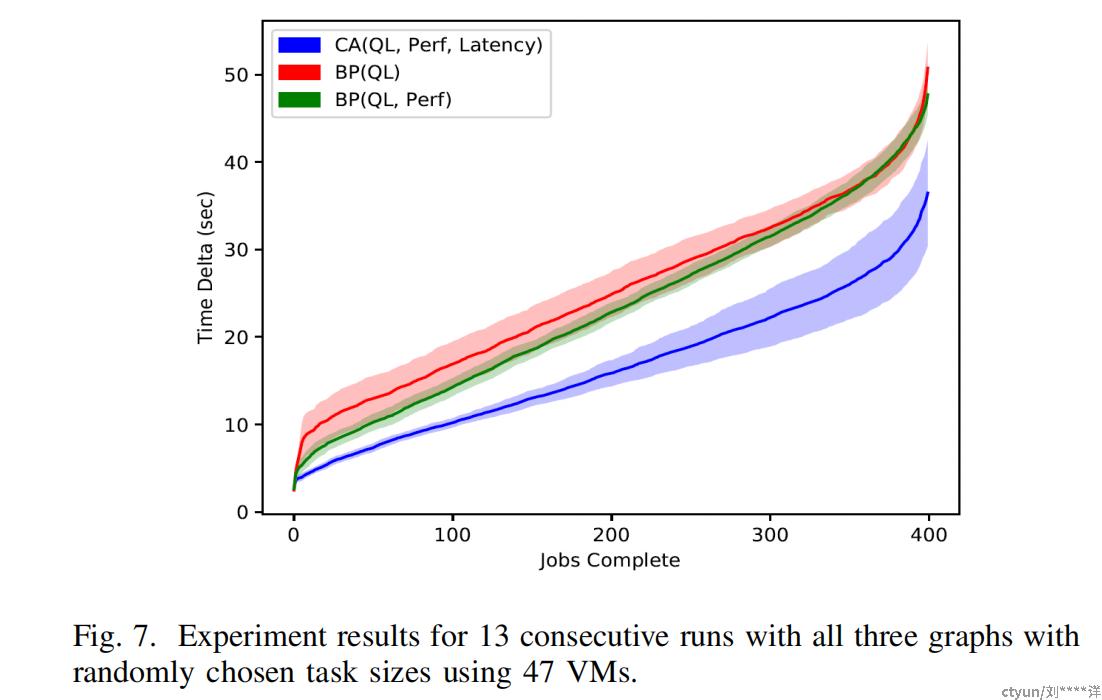
下图显示了使用47个VM进行ChooseRandom任务大小的13次连续运行的三个图形的实验结果。在这种情况下,随机图形和2D调度显示出比相同网络和基于QL的调度更好的性能,直到实验的三分之三。然而,最终两者的性能相似。文章所提出的中心化图形在任务执行效率方面比随机图形更高,导致总体计算时间更低。这两个图中的阴影表示误差棒。
本文讨论了分布式系统的调度问题和不同调度策略的优缺点。传统的网格调度方法虽然可以高效利用资源,但对于大规模系统的可扩展性、网络可靠性和成本问题存在困难。大规模桌面网格系统虽然技术成熟,但主节点的性能限制了数据密集型应用程序的计算能力。云计算中的MapReduce和图并行算法适用于独立任务应用程序,但对于细粒度并行应用程序的性能不佳。学者们提出了基于中心化或分散化的调度算法,例如Gutierrez-Estevez等人提出的细粒度中心化资源调度器和Mohammadzadeh等人提出的多任务云应用程序的中心化调度算法。Organic Grid和IBM的Air Traffic Controller专利文件则探讨了分散化调度和智能自组织网络的调度方法。作者利用延迟信息构建了初始覆盖图,并使用延迟信息调度任务,减少了节点在任务执行之间的空闲时间,优化了多任务应用程序的计算性能。作者最初考虑使用工作节点自己构建分散化图形,但发现这种方法需要手动检查和试验,难以找到合适的平衡点。作者设计了一种中心化图形构建算法,利用通信延迟信息构建优化的覆盖图。在运行时,节点使用延迟信息调度任务,选择延迟较低的相邻节点进行工作重分配。通过实验和测量,作者发现使用工作节点之间的延迟信息构建初始覆盖图,以调度云中的多任务应用程序,可以比使用随机网络获得更好的整体性能。
"Latency-based Vector Scheduling of Many-task Applications for a Hybrid Cloud" 是一篇研究论文,旨在提出一种用于混合云环境下的许多任务(Many-Task)应用程序的基于延迟的矢量调度算法。该算法旨在改善混合云环境中的任务负载均衡,并最小化任务执行时间和网络延迟。
具体来说,该算法提出了一种延迟向量(Latency Vector)模型,该模型基于任务之间的网络流量和延迟时间,计算出任务之间的相对延迟时间。然后,该算法使用这些延迟向量来构建一个任务调度矢量,以便在混合云环境中动态地分配任务。
该算法还提供了一种任务迁移策略,该策略利用延迟向量模型,将特定任务从一个云到另一个云迁移,以便最小化网络延迟和执行时间。这种迁移策略采用了基于网络交通量的贪心算法,以最小化跨云迁移所需的网络开销。
该算法在实验中得到了验证,结果表明它能够有效地减少任务执行时间和网络延迟,提高任务的整体性能。此外,与其他调度算法相比,该算法在多个基准测试中表现出更好的性能和可伸缩性。
总的来说,该论文提出了一种用于混合云环境下的任务调度算法,它基于延迟向量模型和任务迁移策略,能够有效地解决许多任务应用程序的负载均衡问题,并提高整体性能。
