


一、算法介绍
1. 核心思想
最近,vision transformer(ViT)在多种图像领域展示了其全局处理的优势,并与CNN相比实压缩现了显著的性能提升。然而,当将计算预算限制在1G FLOPs时,ViT的增益会显著减少。如果进一步压缩计算成本,MobileNet及其扩展仍然占据着的主导地位(例如,用于ImageNet分类的触发器少于300M FLOPs),因为它们通过深度和点卷积的分解在局部处理滤波器方面效率很高。如何设计高效的网络来有效地对局部处理和全局交互进行编码?
|
Transformer |
CNN |
|
|
特征 |
浅层即可获得全局表示 |
局部表示 |
|
空间信息 |
保留更多 |
较少 |
|
严重遮挡、空间排列等干扰时 |
鲁棒性强 |
鲁棒性弱 |
|
偏向 |
形状信息 |
纹理信息 |
一个简单的想法是将卷积和ViT结合起来。在本文中,作者提出了一个并行设计的双向连接MobileNet和Transformer的结构Mobile-Former。这种结构利用了MobileNet在局部信息处理和Transformer的在全局交互方面的优势,这样的连接可以实现局部和全局特征的双向融合。
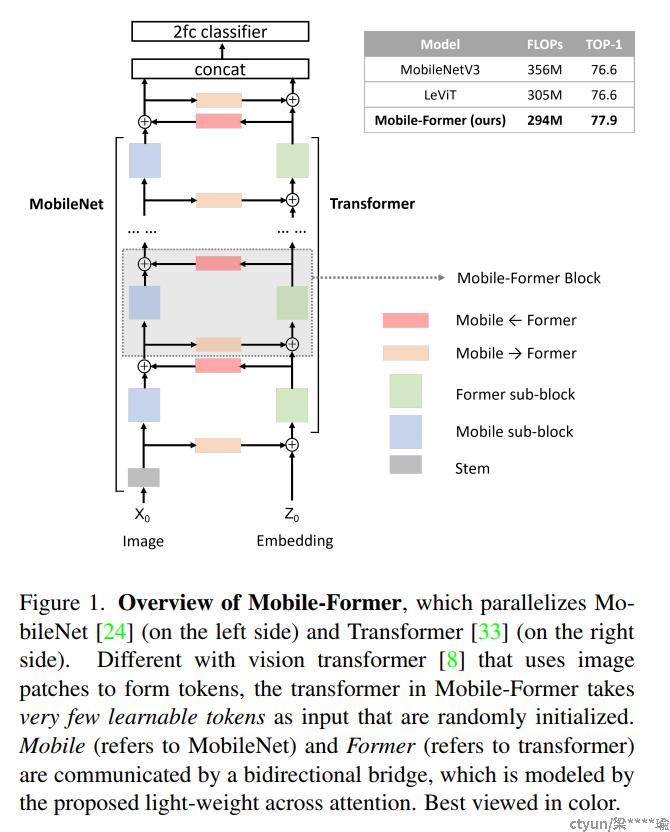
图1
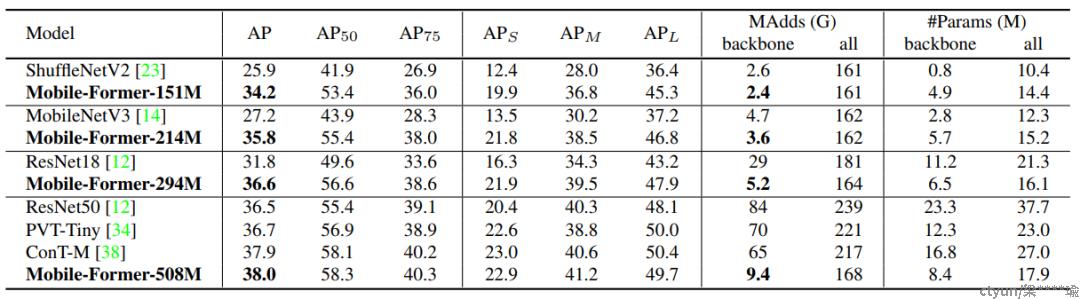
不同于现有的Vision Transformer,Mobile-Former中的Transformer包含很少的、随机初始化的tokens,因此计算量非常小。通过用一个非常lightweight的cross attention将MobileNet和Transformer连接起来,使得MobileFormer不仅计算量非常小,而且也能拥有超强的表征能力。在ImageNet分类任务上,从25M到500M FLOPs的复杂度下,所提出的Mobile-Former方案均取得了优于MobileNetV3的性能。例如,它在294M FLOPs上达到了77.9%的Top-1准确率,比MobileNetV3增加了1.3%,但节省了17%的计算量。当转移到目标检测任务上时,Mobile-Former的性能比MobileNetV3高出8.6AP。
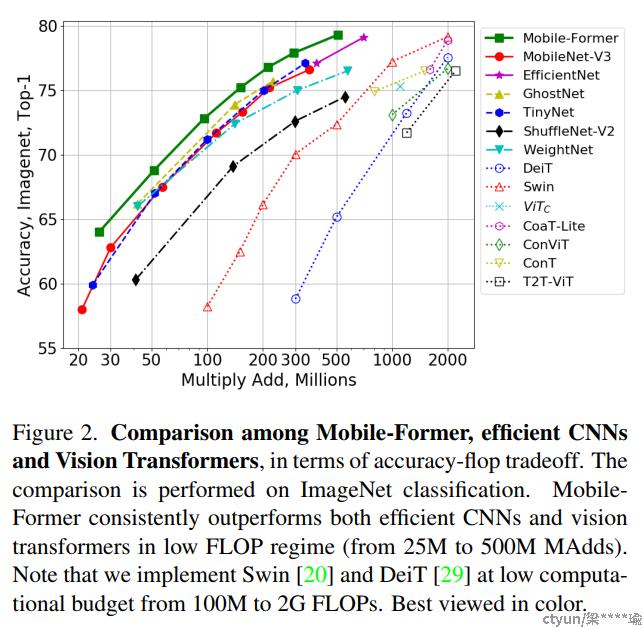
图2
2. 详细过程
Mobile-Former将MobileNet和transformer并行化,并通过双向交叉注意力将两者连接起来(见图1)。Mobile-former中,Mobile(简称MobileNet)以一幅图像作为输入,采用inverted bottleneck block提取局部特征。前者(指transformer)以可学习参数(或token)作为输入,记为,其中d和M分别为token的维数和数量。这些token被随机初始化,每个token表示图像的全局先验。这与Vision Transformer(ViT)不同,在ViT中,token线性地投射局部图像patch。这种差异非常重要,因为它显著减少了token的数量从而产生了高效的Former。
2.1 Low Cost Two-Way Bridge
作者利用cross attention的优势融合局部特性(来自Mobile)和全局token(来自Former)。这里为了降低计算成本介绍了2个标准cross attention计算:
- 在channel数较低的MobileNet Bottlneck处计算cross attention;
- 在Mobile position数量很大的地方移除预测(),但让他们在Former之中。
将局部特征映射表示为x,全局token表示为z。它们被分割为x=[xh]和z=[zh](1≤h≤H)表示有H个头的多头注意力。从局部到全局的轻量级cross attention定义如下:

其中WhQ是第h个head的query投影矩阵,WO用于将多个head组合在一起,Attention(Q,K,V)是query Q、key K和value V上的标准自注意力函数,如下所示:
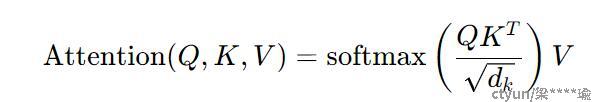
注意,全局特性z是query,而局部feat x是key和value。WhQ和WO应用于全局token z上。这个cross attention如图3(Mobile→Former)所示。
以类似的方式,从全局到局部的cross attention计算如下:

其中WhK和WhV是key和value的投影矩阵。在这里,局部feat x是query,而全局feat z是key和value。这种cross attention的图表如图3(Mobile←Former)所示。
2.2 Mobile-Former Block
Mobile-Former可以解耦为Mobile-Former块的堆栈(见图1)。每个块包括Mobile sub-block、Former sub-block和双向桥接(MobileFormer和MobileFormer)。Mobile-Former块的细节如图3所示。

图3
2.2.1 输入和输出
Mobile-Former块有2个输入:
- 局部特征图Xi∈RL×C,具有C通道和L空间位置(L=hw,其中h和w为特征图的高度和宽度);
- 全局tokenZi∈RM×d ,其中M和d分别是token的数量和维数。
Mobile-Former块输出更新后的局部特征映射为Xi+1和全局tokenZi+1 ,用作下一个(i+1)块的输入。注意,全局token的数量和维度在所有块中都是相同的。
2.2.2 Mobile sub-block
Mobile sub-block以feature map Xi为输入。与MobileNet中的inverted bottleneck block略有不同,在第一次pointwise卷积和3×3深度卷积后用dynamic ReLU代替ReLU作为激活函数。
与原来的dynamic ReLU不同,在平均池化特征上使用两个MLP层生成参数,而在前者输出的第一个全局token上使用2个MLP层(图3中的θ)保存平均池化。注意,对于所有块,深度卷积的核大小是 3x3。将Mobile sub-block的输出表示为Xihidden ,作为Mobile Former的输入(见图3)。
2.2.3 Former sub-block
Former sub-block是带有多头注意(MHA)和前馈网络(FFN)的标准transform block。在这里,作者遵循ViT使用后层标准化。为了节省计算,作者在FFN中使用的扩展比为2而不是4。
Former sub-block之间处理是双向交叉注意力,即(Mobile→Former和Mobile←Former)(见图3)。其复杂性为O(M2d+Md2)。第1项涉及到计算query和key的点积,以及根据注意力值聚合值。第2项涉及到线性投影和FFN。由于Former只有几个token(m6),所以第1项M2d是可以忽略的。
2.2.4 Mobile→Former
采用所提出的轻量cross attention(式1)将局部特征Xi融合到全局tokenZi 。与标准自注意力相比去掉了key WK和value WV(在局部特征上)的投影矩阵,以节省计算量(如图3所示)。其计算复杂度为O(MHWC+MdC),其中第1项涉及计算局部特征和全局特征之间的cross attention以及为每个全局token聚合局部特征,第2项是将全局特征投影到局部特征C的同一维度并在聚合后返回到维度d的复杂性。
2.2.5 Mobile←Former
在这里cross attention(公式3)位于移动方向的相反方向。它融合了全局token Zi和局部特征Xi。局部特征Xi是query,全局token Zi是key和value。因此,保留keyWK 和valueWV的投影矩阵,但在queryWQ 时去掉投影矩阵以节省计算,如图3所示。
3. 评估
在 ImageNet 分类上从 25M 到 500M FLOsP 的低 FLOPs 机制下优于 MobileNetV3。 例如,它在 294M FLOP 下实现了 77.9% 的 top-1 准确率,比 MobileNetV3 提高了 1.3%,但节省了 17% 的计算量。

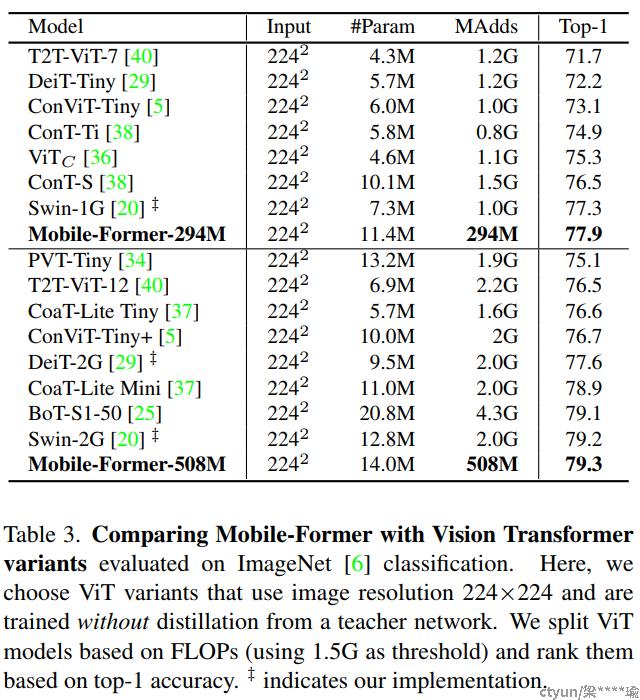
在迁移到目标检测时,Mobile-Former 比 MobileNetV3 高 8.6 AP。
三、附图
为了理解Mobile和Former之间的协作, 作者将cross attention形象化在双向桥上(Mobile→Former和Mobile←Former) (见图4、5、6)。使用ImageNet预训练的MobileFormer294M,其中包括6个全局token和11个Mobile-Former块。作者观察到3种有趣的现象:
lower level token的注意力比higher level token更多样化。如图4所示,每一列对应一个token,每一行对应相应的多头交叉注意中的一个头。注意,在Mobile→Former(左半部分)中,注意力是在像素上标准化的,显示每个token的聚焦区域。相比之下,Mobile←Former中的注意力是在token上标准化的,比较不同token在每个像素上的贡献。显然,第3和第5区块的6个token在MobileFormer和MobileFormer中都有不同的cross attention模式。在第8块中可以清楚地观察到token之间类似的注意力模式。在第12区块,最后5个token的注意力模式非常相似。注意,第1个token是进入分类器头部的class token。最近关于ViT的研究也发现了类似的现象。

图4
全局token的重点区域从低到高级别逐渐变化。图5显示了MobileFormer中第1个token的像素交叉注意力。这个token开始关注局部特性,例如边缘/角(在第2-4块)。然后对像素连通区域进行了更多的关注。有趣的是,聚焦区域在前景(人和马)和背景(草)之间转换。最后,定位识别度最高的区域(马身和马头)进行分类。

图5
MobileFormer的中间层(例如第8块)出现了前景和背景的分离。图6显示了特征图中每个像素在6个token上的cross attention。显然,前景和背景被第一个token和最后一个token分开。这表明,一些全局token学习有意义的原型,聚类相似的像素。

图6
