


概述:
重复数据删除是灾备系统中非常重要的一项技术,这种技术可以在一个重删域当中发现相同的数据,对相同的数据使用索引替代真实的数据存储来达到数据缩减的目的,以此满足日益增长的数据存储需求。重删技术在灾备应用系统当中应用十分广泛,也是灾备系统中较为有竞争力的一项重要技术,这项技术不仅仅能提供缩减数据存储能力,其他的主要优势还有:
- 降低数据存储量,节省存储空间,降低成本。
- 降低网络传输量,节省带宽资源。
- 提升存储效率,减少备份窗口,减小数据压缩加密等数据消耗
重删的基本原理:
重删的基本原理是通过计算数据特征指纹来识别相同的数据,指纹一般来说是通过某种算法计算数据的Hash值,以此hash值作为此部分数据的唯一标识,所以也称作指纹。当某两部分数据的hash值相同时,就认为这两部分数据时一致的。但是不同的算法计算出来的hash值,有不同的碰撞概率,所以需要尽量选择碰撞概率小的hash算法来进行指纹计算。为了避免此种情况,可能会采用2种hash算法来确保数据的唯一性。
通常来说选择强hash计算能够减小碰撞概率,但是计算资源消耗较大。弱hash计算碰撞概率大,计算快。所以为了提升效率通常2中hash算法会选择强弱hash的搭配,只有强弱hash都一致的时候才认为数据时一致的。
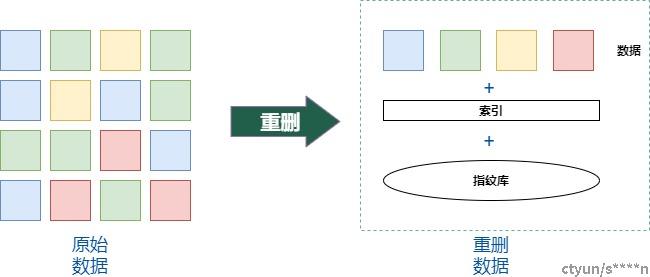
图1 重删的基本原理
源端重删 & 目的端重删 :
这两种技术的区别在于重删动作发生的位置是在数据发送方,还是在数据接收方。一般源端重删指在备份代理位置就已经识别重复数据并将重删后的数据发送到服务端,目的端重删则将所有数据都发送到服务端再进行重复数据识别。从重删发生的位置能够看出源端重删能够较好的减少源端数据传输带来的网络压力,有效的减少数据传输量,通常适用于网络带宽窄或者大数据量的场景。
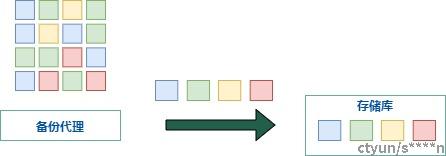
图2 源端重删
目的端重删于源端重删在数据存储上都是存储重删后的数据,其差别在于目的端重删能够有效的释放生产环境的计算压力,但这些计算量并没有减少而是集中在存储服务器上,通常适用于数据量较小,源端备份代理资源较为紧张的场景。

图3 目的端重删
在线重删 & 离线重删:
从重删发生的时间来进行区分,可以分为在线和离线重删,在线重删指在数据存储的过程当中进行重删,离线重删指数据先进行非重删存储,然后在空闲时间再进行数据的读取,重删后再次存储在存储当中。
在线重删对于存储压力更小,而且数据只需要存储一遍,对于海量数据此存储方式效率更高。但问题在于一旦出现计算瓶颈,会导致性能瓶颈,性能下滑。
离线重删则存储效率较差,需要准备较多的存储空间来对应存储非重删数据和重删数据,并且数据需要进行重复的读写操作,对于海量数据此存储方式降低整体存储效率。
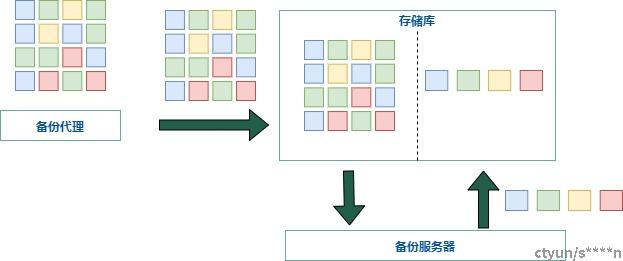
图4 离线重删
变长重删 & 定长重删:
变长重删与定长重删均为将数据流进行切片的方法,定长重删顾名思义就是将数据流按照等长的大小进行切分,每一块大小均相等,这样的切片方法简单高效,并且在数据大小上面有高度的一致性,但在应对数据插入修改的场景下就显得力不从心,特别是在文件备份的场景这样的情况由为多见。因此就引出了变长重删算法,变长重删算法根据数据的特征值来进行分割,当数据符合某种特征的情况下才将数据进行切片,这样每个数据长度并不是固定的,能有效的识别插入数据导致的数据切片全部变化的情况。下面我们详细解释一下两种算法的不同:
定长重删:
定长重删实现逻辑比较简单,将要备份的数据以固定长度进行分块并计算每个分块的hash值作为指纹。
如下图所示,t1时刻总共有16块数据,每4块数据进行切片,总共可以切为4片。计算每个切片的hash值,我们假设为hash1, hash2,hash3,hash4. 其中1 和 3的值一致,那么第3块数据就只需要存储索引,数据不再进行存储,来达到减小存储空间的目的
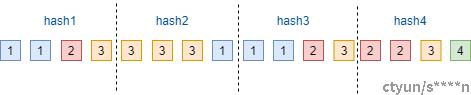
图5 定长切片
下图所示,我们来到了t2时刻其中有一块数据发生了变化,使得hash2的值发生了改变,因此我们需要将hash2’的数据再次进行存储,此时重删效果依然不错

图6 数据原地修改
但当我们来到了t3时刻在数据流的最前面新增了一个数据块,此时依然以每4块数据进行切片,总共切分为5片数据。计算每个切片的hash值,我们就得到了完全不同的5个hash值,hash1’,hash2’, hash3’, hash4’, hash5’。这些产生的数据块需要重新存储,因此导致的存储的数据大量增加

图7 定长切片插入数据
由于文件常发生插入型修改,在这种场景下定长重删的效果大打折扣。一般来说定长重删更多适应于卷备份、虚拟机备份等场景。
变长重删:
变长重删一般常用的有滑动窗口和CDC算法
滑动窗口算法:
滑动窗口算法先将数据按照固定长度进行切片,计算各个切片的hash值:
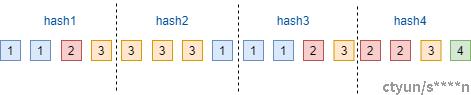
图8 滑动窗口
第二次切片时,使用第一次固定长度作为滑动窗口大小,对数据进行扫描尝试找到相同的hash值,如果当前窗口没有发现相同的hash值则向后进行滑动一个数据块,直到找到匹配为止。

图9 插入数据后的滑动窗口切片
当插入一个数据之后能很好的将插入的数据隔离出来:

图10 滑动窗口切片
但是有个问题,如果数据变化较大窗口一直滑动可能也无法发现相同的hash值,所以我们需要定义一个最大滑动长度:
- 当滑动长度>=最大滑动长度超过边界时,我们就按照窗口大小进行切分
- 如果滑动长度<=最大滑动长度时就发现相同的hash值,则将滑过的部分单独切片,当前窗口再进行切片。
此方案能够带来良好的查重效果,但是有可能引入大量的数据碎片,从而影响整体效率。
CDC算法:
CDC算法的原理其实在于利用hash算法的随机性来分割相同特征的数据,假设有个hash函数h(x)使得任意数据的计算结果能够均匀分布,我们将h(x)得出得结果对固定数值取余,判断取余的结果是否等于某个值,即h(x) mod D = R,将这种特征作为数据切片的边界。由于hash函数是均匀分布的,所以任意一段数据符合这种条件的概率是相同的。
我们再看下CDC算法是如何解决插入数据的问题的,如下图所示:

图11 CDC边界计算
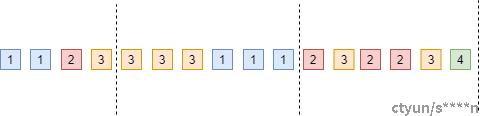
图12 CDC切片结果
当插入新的数据导致分片1已经无法找到满足边界条件的数据片,则滑动到第二个分片的边界能找到相同的边界,所以当插入数据之后第一个分片和相邻分片可能会发生影响,但后续分片并不会发生影响:

图13 CDC算法-插入数据
从上图可以看出,这种边界计算方法也可能在初始窗口就开始切片,使得切片很小造成很多数据碎片影响整体系统效率。所以通常对于CDC算法我们会引入最小边界与最大边界来控制切片的大小既不会特别大也不会特别小。
