


背景
随着数据越来越重要,在一些场景下,比如金融等场景,对大数据的容灾需求越来越重要,而大数据的容灾本身就是一个复杂需求,是一个模糊需求,很多时候,包括客户以及我们自己,都把很多地方混在一起,导致会有点混乱;一般来说,容灾包括了:数据同步备份方案、灾难切换方案、灾后恢复方案以及容灾演练等方案;
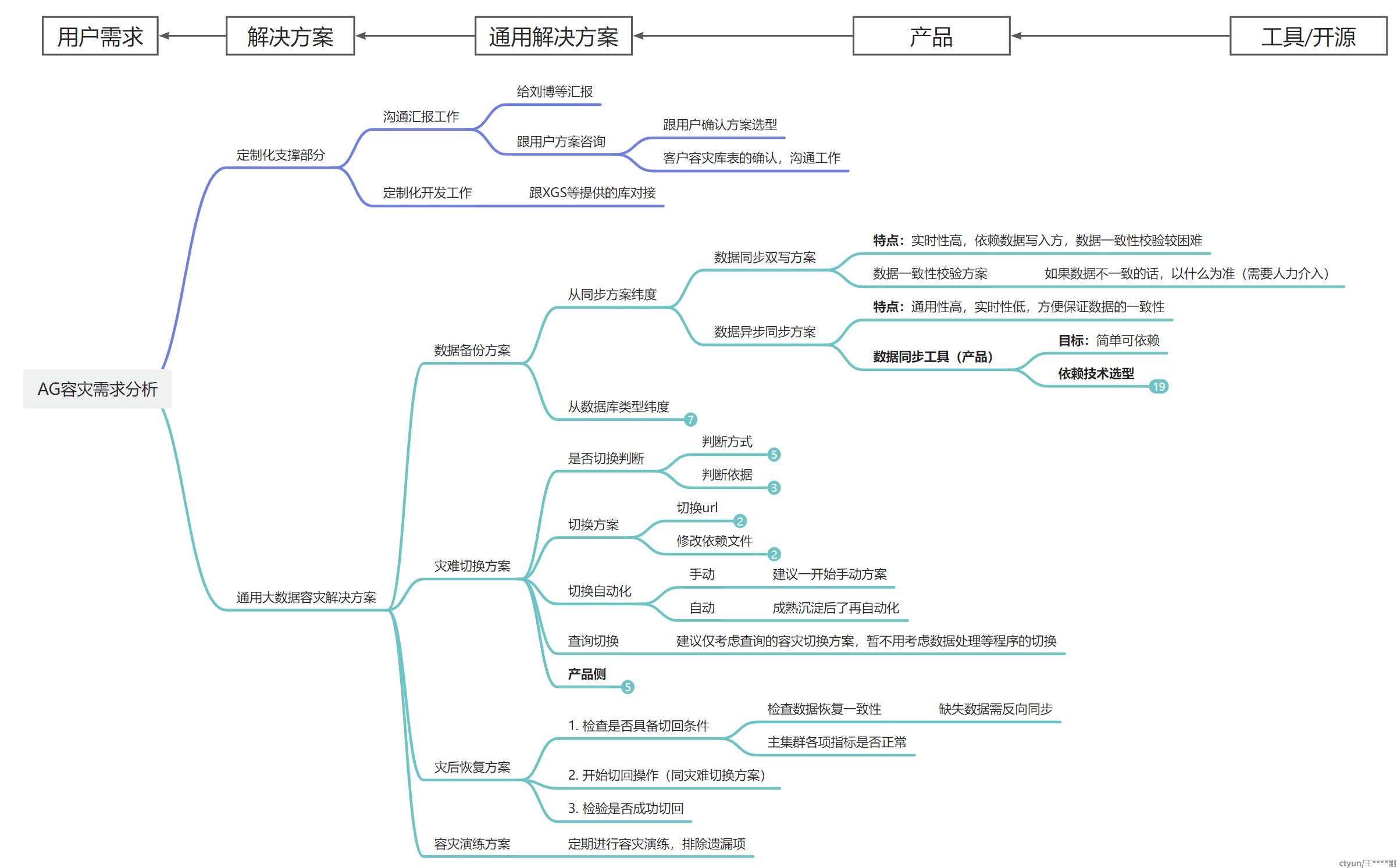
根据上图“用户需求--解决方案--通用解决方案--产品--工具/开源”的思路去梳理的话,就会得到一个相对比较清晰的思路,从需求侧到技术侧实现全面的打通,便于后续的研发落地;
本文旨在提出大数据场景下数据同步架构设计思路;
整体架构设计
整体设计原则:
- 简单可依赖,最小化使用现有的或者比较成熟工具,便于部署;
- 各模块职责明确,若无必要,勿增实体,相对抽象,可被替换(比如DS、Linkis、meta、distcp等,都可以被替换,最终打磨沉淀的核心是replication-server中的逻辑);
- 可以通过API调用,便于上层其它系统调用(比如数据开发治理等能力调用等);
- 未来便于融入整体架构,便于重构;暂时建议松耦合嵌入在墨子里,复用单点登录、权限、监控告警等能力;
- 透明可视可配原则:所有策略,都可以用户定义,对用户来说是可视可配的(因为用户也是程序员,程序员需要掌控感,我们的产品是给程序员用的);
架构图如下所示,简述各模块职责,做到MECE(监控、日志等未写):
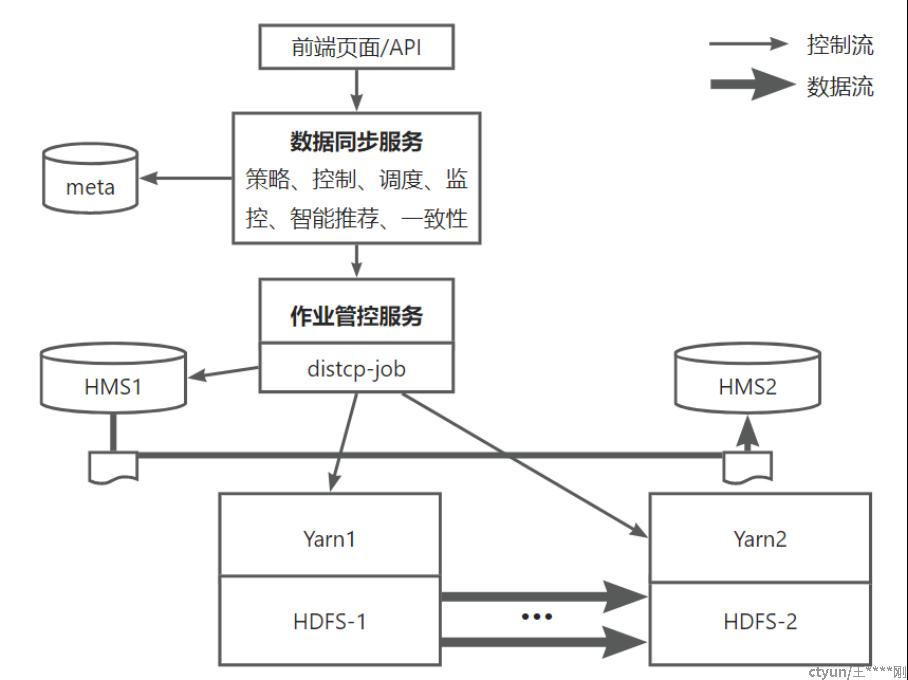
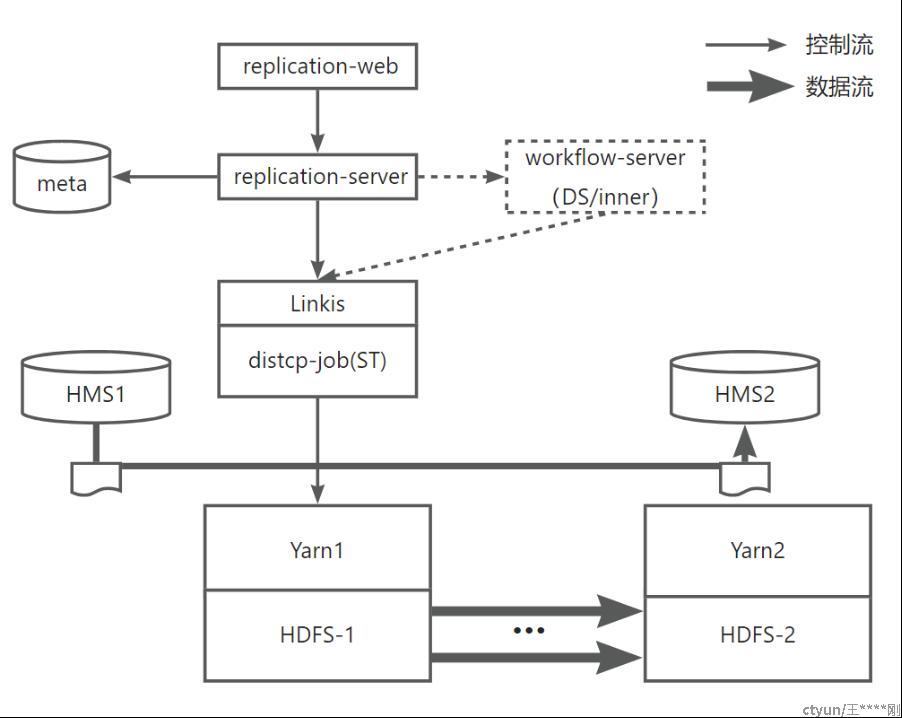
如上图:
- replication-web:数据同步前端页面,遵循墨子风格,嵌入墨子;
- replication-server:数据同步后端服务,对外提供RestFul接口,也可供前端页面调用;提供数据同步相关处理逻辑,专注于迁移策略,底层繁琐对接交给linkis,DAG交给dolphin或自己实现;
- meta数据库:用于保存数据同步所需要的数据,mysql够用了,可以独立(也可以放到墨子一个表里,也可考虑未来融入统一元数据服务中,比如linkis-metadata);
- workflow-server(DS):用于提供定时备份,定时迁移等所需要的定时调度功能,以及相关DAG依赖,目前选型Dolphin Scheduler,调用触发Linkis;
思考-调度的实现选型:这一块的定时调度,可能得自己来实现了,自己实现的好处一个是内聚,便于部署,另一块就是跟server打交道更方便,便于优化;
|
|
方案 |
优势 |
劣势 |
|
自己实现 |
基于Java/Spring自带,或者Quartz。建议基于数据库做就行了; 这个量级放mysql够用了; |
部署简单,不依赖外部系统; 便于与后面distcp等作业参数优化等结合; |
需要自己写,工作量大; 不太好与调度里的其它作业集成;(这个场景需要讨论清楚) 需要考虑好调度性能与量级; |
|
外接DS等 |
撰写相应DS的接口,发送给DS |
成熟的DAG工具; 便于与大数据里其它作业结合 |
架构复杂度增加,依赖DS部署; 触发的distcp作业的参数只能提前设置好,难以利用一些优化经验动态优化 |
结论:内置实现DAG调度功能,未来预留外部对接接口。
- Linkis:对外提供集群访问统一RestFul接口;用于封装繁琐的distcp(Jindo Distcp/ST)调用逻辑,提交作业给yarn,获取当前作业状态等,Linkis支持distcp还需继续开发 DistcpEngineConn(60%?);
需要借助linkis的能力具备以下接口:作业提交,作业状态,作业杀死等;并且封装一切复杂底层的问题,比如Kerberos跨域支持,keytab鉴权等等;
- Yarn1:占用一定资源,用于跑distcp-job;yarn2一般不用;
- HDFS1:HDFS1的数据,通过distcp-job,拷贝到HDFS2;
- HMS1:Hive metastore,hive同步的话,hive元数据也需同步;
元数据同步方案,这个需要跟hive大佬们讨论:
方案一:通过jdbc的方式,SQL同步;
方案二:dump下来(DML DDL文件等),hdfs distcp传输,然后在载入;
高可用:web和server,单服务,完全Serverless,状态存储在数据库meta(沿用墨子数据库的HA方案),双活或主备HA,后面迁K8S也方便;Linkis、DS、Hadoop等均高可用;
监控告警:复用墨子的监控告警,这一块的话:
方案一:可以监控linkis上作业的状态,通过Linkis发送告警出去;
方案二:可以把监控告警规则,直接发给监控告警模块;
抽象模型
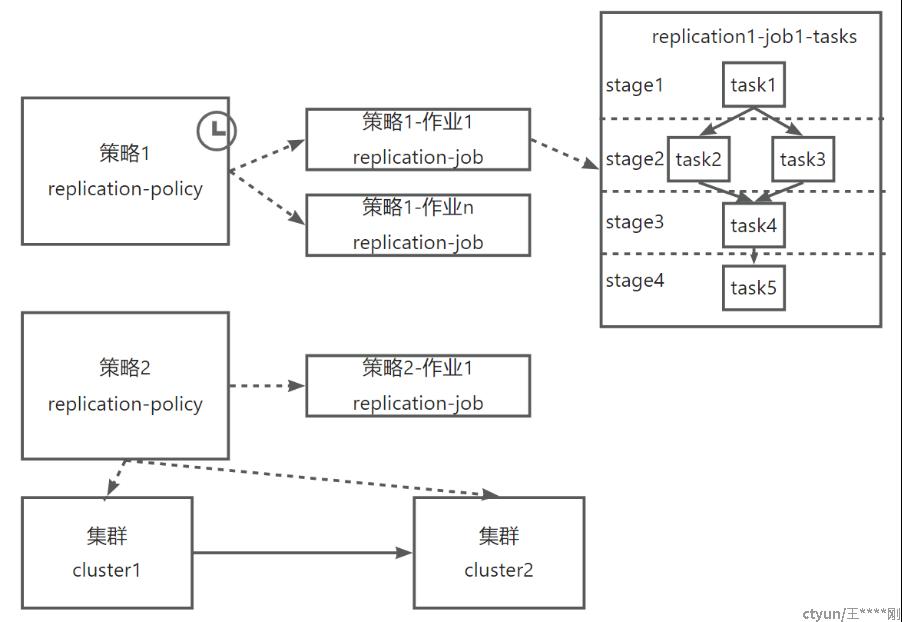
如上图
- 集群cluster:也就是代表集群,比如HDFS集群,或者Hive集群等,用于同步任务执行的时候,所需的访问连接信息;
目前的版本,集群需提前配好相关的连接信息,包括Hadoop客户端,Hive客户端,Linkis侧,以及跨域等问题,然后手动录入一次即可,
后续的版本,集群信息可以考虑直接通过mozi的一个url去拿到,或其它更易于配置的方案(不过这个低频操作,不急);
- 同步策略replication-policy:代表一个同步策略,由用户通过前端页面录入,或者RestFul API导入,表示一个目录从一个集群同步到另外一个集群;
- 同步作业 replication-job:代表一次同步作业,表示一个策略的一次执行,可以是手动触发,也可以是定时触发;policy和job的关系是 1:N (可以是0)的关系;每次job的执行,都会动态生成一组stage和task;
- 同步阶段 replication-stage:一次同步作业,由不同的阶段组成,每个阶段依次执行;一个同步阶段中,可以有1或者多个task组成,这些task可以组成一个DAG;stage和task,共同组成简化版的DAG;
- 同步任务 replication-task:(这是跟CDP不同之处)代表一个同步任务,对应对底层作业的一次调用(发送给Linkis等的一次API);
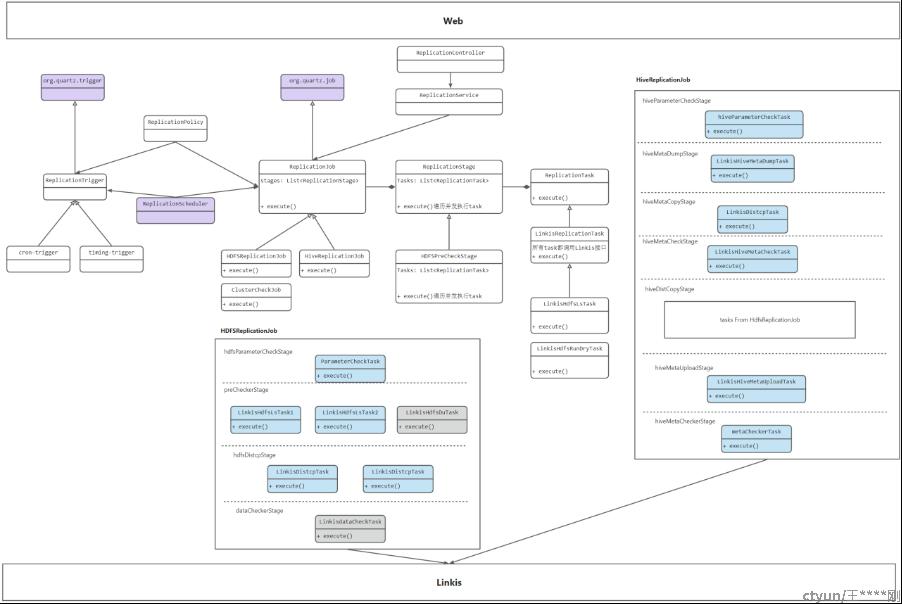
数据结构
- 所有的ReplicationJob,都会维护一个ReplicationStages列表 List<ReplicationStage>,它们都有固定的显示格式();
- Stage之间有前后依赖关系,每个Stage里,又维护着一组Tasks:Map(List)<ReplicationTask>,Tasks可以并行执行;Stage和Task,共同组成了一套简化版DAG(类似墨子里的运维流水线);
- 对于Task来说,它就是具体任务的执行,在这里先实现一组实现类,就是LinkisTaskXXX;至少包含:底层命令,Linkis接口,状态信息,日志信息等数据(日志数据最终存储在数据库中);
核心类关系图
几种用户使用场景简要说明
集群信息
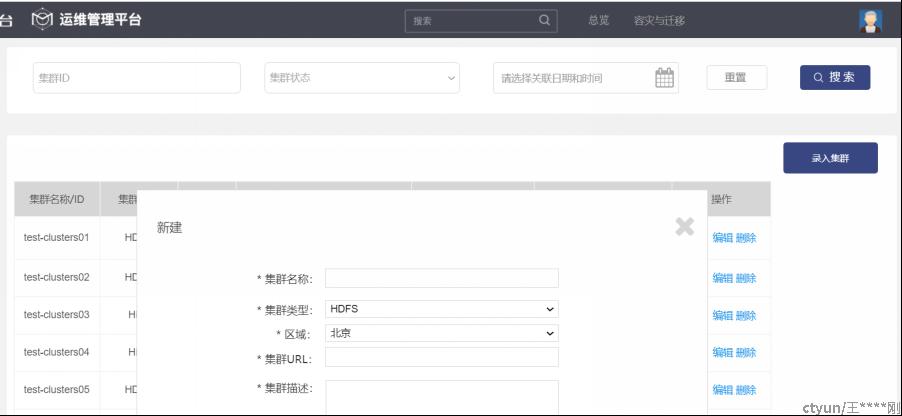
录入集群(删改查)
web前端通过RestFul调用后端接口,controller接到信息后,检查参数,然后通过Service,dao等录入数据库cluster表中;
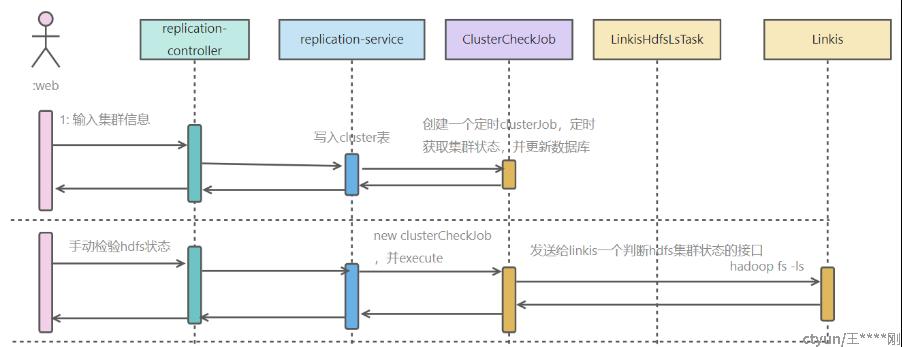
检测HDFS集群状态
前端web调用server的RestFul接口,server从数据库中取出集群信息,然后封装调用 linkis-hdfs-ls 任务,获得相应结果,则为集群正常;
列表里的集群状态,在创建好集群后,创建一个ClusterCheckJob,定时检测,然后检测结果写入数据库;
同步策略
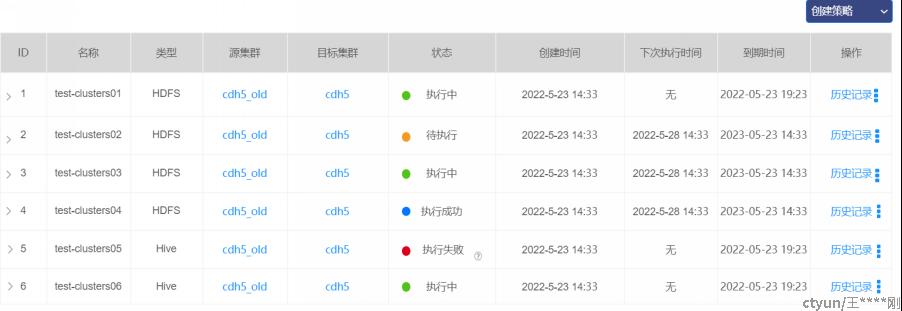
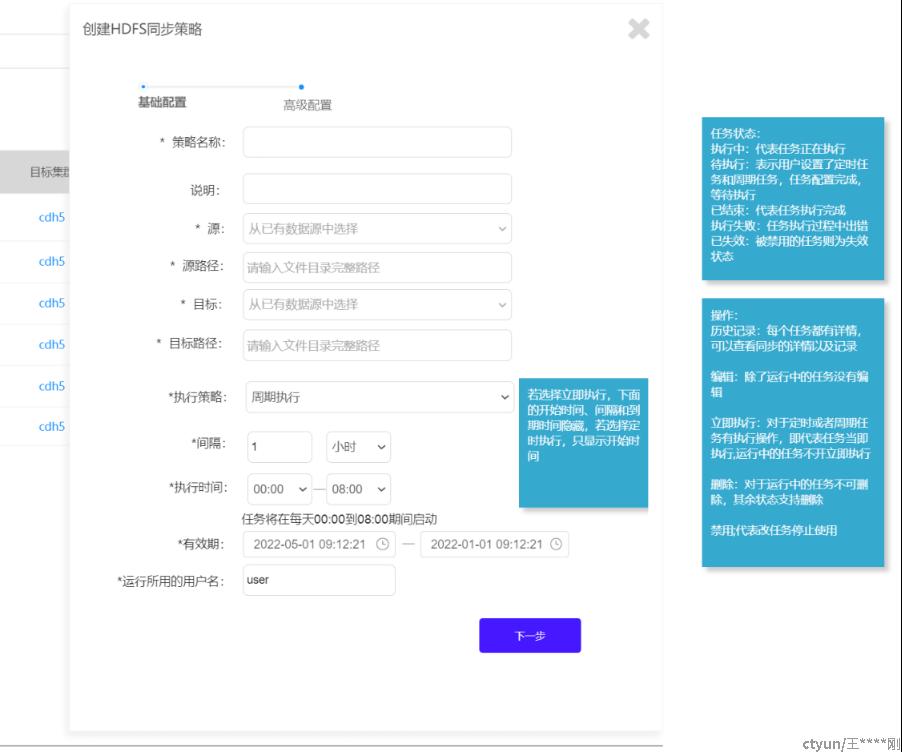
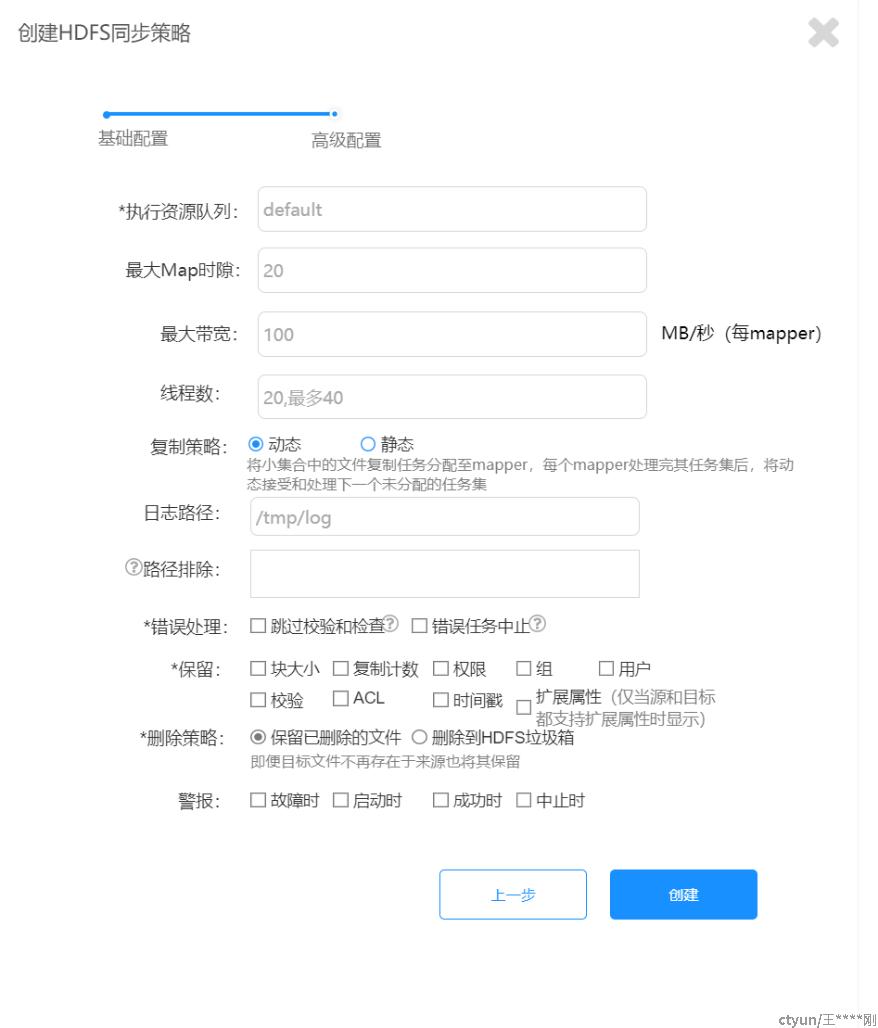
新建策略(删改查)
- web以post方式将策略信息,传给server,server收到后,存入数据库的policy表中;
- 保存后(新建或修改都算),根据策略里的Trigger信息:
- 如果是立即执行一次的话,就直接通过Policy信息,生成相应的ReplicationJob,并开始执行;
- 如果是定时或者未来某个时间触发的话,从数据库相关字段,新建一个对应的ReplicationTrigger,提给ReplicationScheduler;
- 然后通过Scheduler和Trigger触发,执行相应ReplicationJob的execute()方法,见“单次调用HDFS同步任务”;
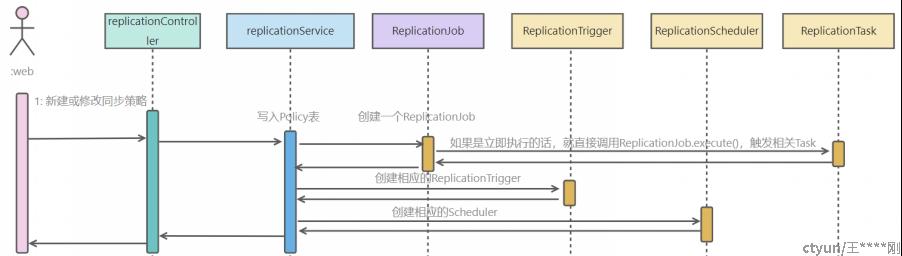
单次调用同步任务
大概原型如下图所示:
无论是立即执行,还是定时执行,指定时间执行,最终都会调用XXXReplicationJob.execute();
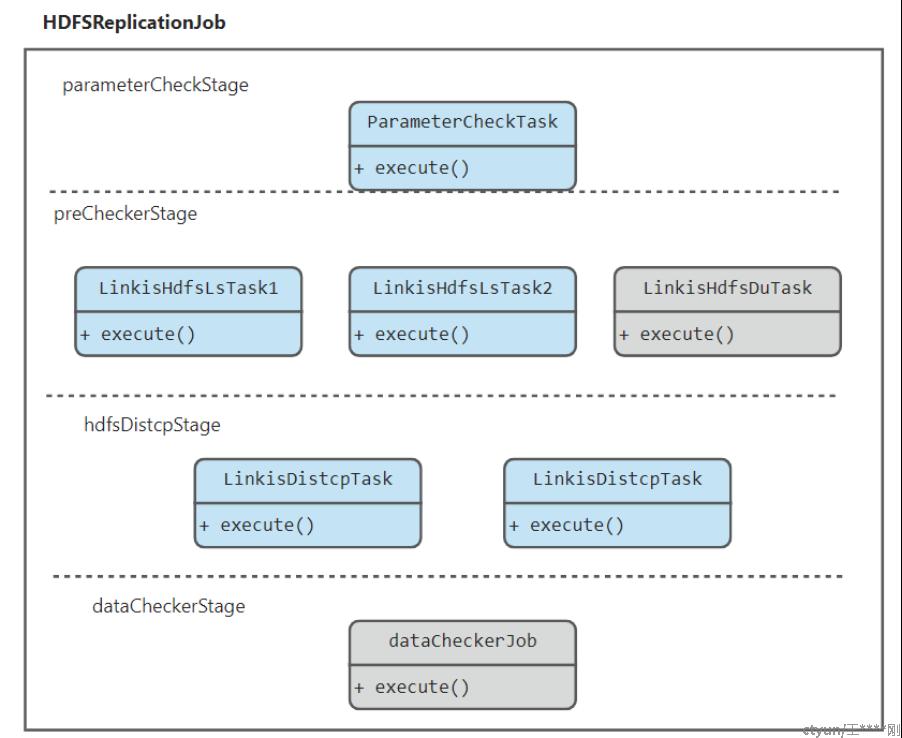
对于HDFSReplicationJob来说:
- 调用execute()后,同步进行如下动作:
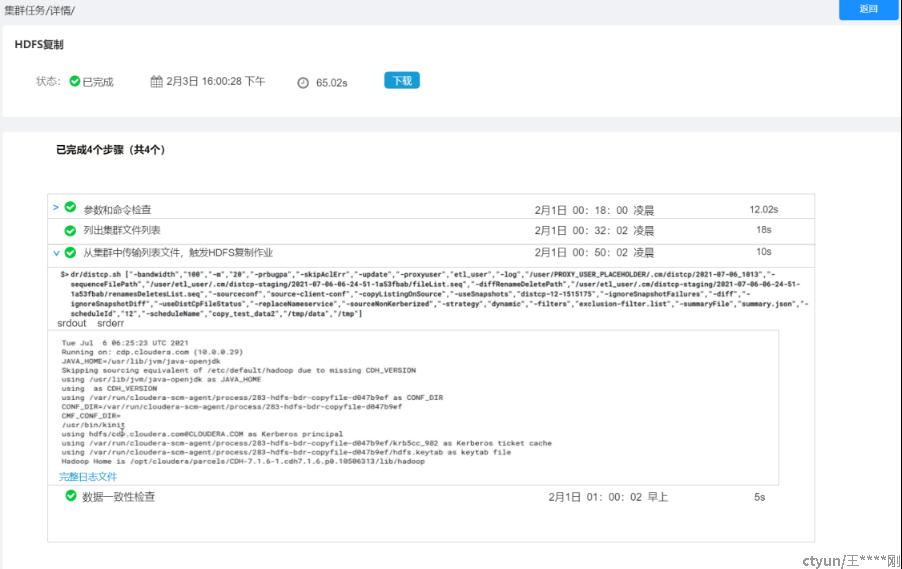
- parameterCheckStage:执行参数校验;以校验各个参数是否合规,主要包括数据源和数据目标的文件检查;
- hdfsPreCheckStage: 接口判断,包括权限,源数据与目标数据目录是否存在等;(产品侧可以考虑加一个连通性测试(或试运行)功能,供单独调用)
- LinkisHdfsLsTask;给Linkis发送2个task,LS检查2个Hadoop集群的源文件目录与目标目录是否存在;(隐含着集群连通性测试,以及集群权限)并且返回目录下的文件列表;并且判断,如果参数里的目录,底层没有的话,就(先)报错;
- LinkisHdfsDuTask(P1):检查源数据文件目录及大小,用于后续distcp任务的参数优化(第二优先级);
- hdfsDistcpStage: 根据用户输入参数,生成linkis-distcp命令组,提交linkis执行;异步通过linkis定时获取作业状态,写入meta表,供前端调用;
- dataCheckStage(P1,distcp有自带的检查,而且比我们做得好):作业执行完毕后,调用数据校验命令以校验拷贝成果(可选):调用linkis-hdfs-api(不一定有), 校验文件大小、文件数量是否一致;校验备集群的数据表能否正常执行,以及更复杂的采样。
- 数据不一致的情况下的处理策略,比如重试?补数策略?(这些前端也都可配)以checksum为准;(这些暂不考虑,stage有问题,就报错)
- 记录不一致的数据,或失败的数据,然后把它们输出收集到一个list:
- 自动新建一个重跑作业并准备好,由用户手动触发,(或后面增加错误重试策略功能);
- dataRedoStage(P1),用于错误的数据补充重跑;从之前的stage里的错误日志里找出列表;
- 数据不一致的情况下的处理策略,比如重试?补数策略?(这些前端也都可配)以checksum为准;(这些暂不考虑,stage有问题,就报错)
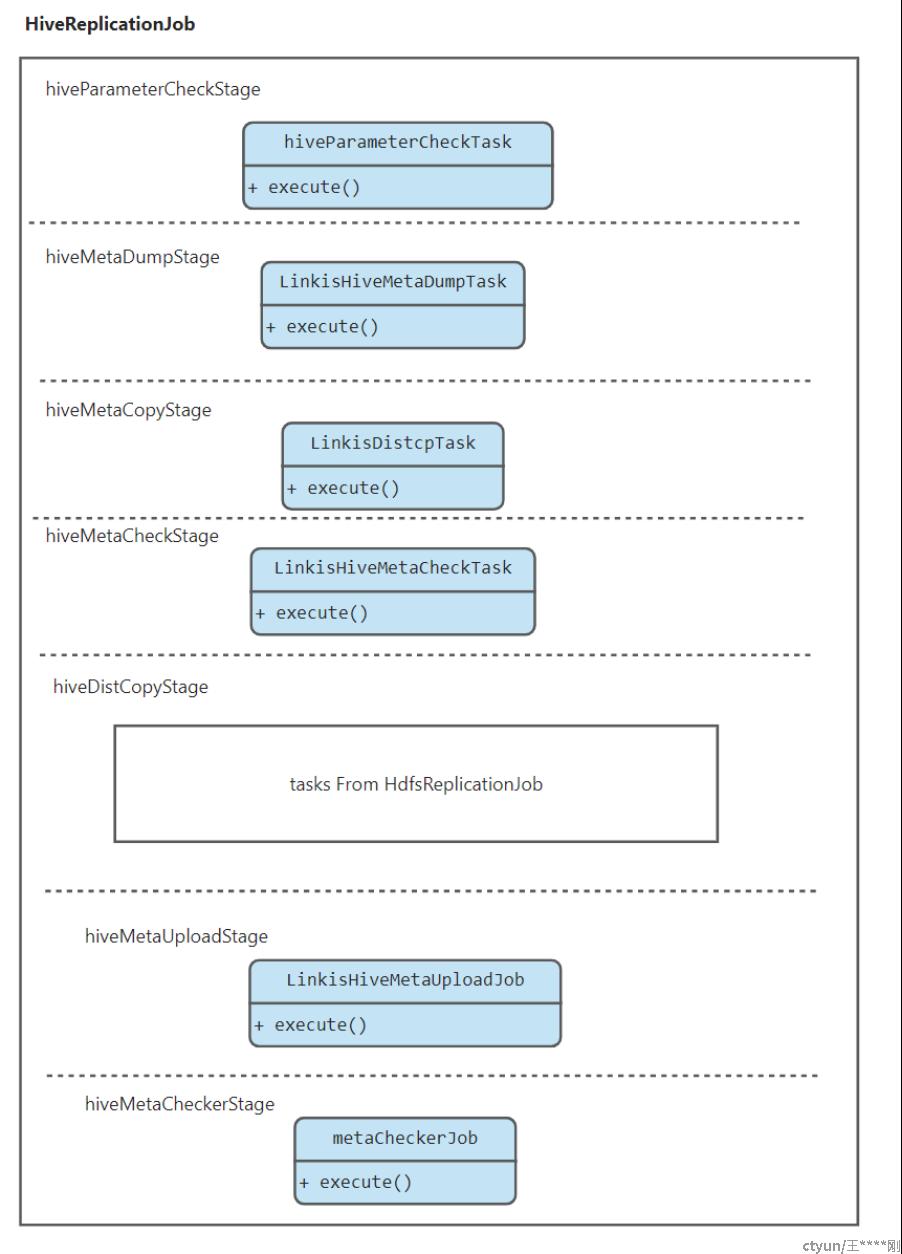
对于HiveReplicationJob来说:
- hiveParameterCheckStage,以校验各个参数是否合规,主要包括数据源和数据目标的文件检查
- hiveMetaDumpStage,导出要迁移源hive库的Hive metastore到hdfs中;
- hiveMetaCopyStage:传输元数据文件;
- hiveMetaCheckStage: 检查hive metastore是否不匹配,主要是看看源集群的hive meta,最终能否导入到新集群hive metastore;;
- hiveDistCopyStage:创建hive库表对应的数据的distcp task,hive表数据复制distcp;(参考或复用hdfs distcp)
- hiveMetaUploadStage:导入hive metastore;
- hive数据一致性检测(P1);
定时同步HDFS目录
分为两种方式:
第一种就是让用户自己去通过参数,设置不同的分区备份,定期期备份到备集群的HDFS目录;
这种情况比较清晰明了,也容易控制,通常适用于按分区备份的场景,比如每小时一个分区,或者每天一个分区,但是需要在同步任务的页面上,可以通过变量参数,通过Linkis内置时间变量(eg: &{yyyyMMdd%-1d}),来设置不同时间的触发的脚本是不一致的;
第二种就是直接设置一个HDFS目录,定期备份到备集群的HDFS目录;
第二种适用于用户对自己的目录规划不清晰的场景,需要底层程序去判断,哪些数据要覆盖,哪些数据不需要拷贝等(distcp命令原生支持,但是会有额外操作,需要明确计算量大不大?)
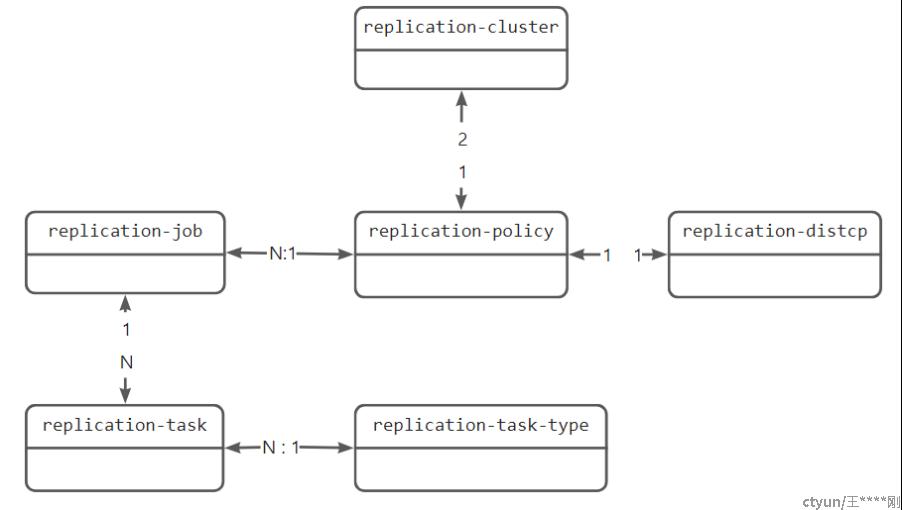
数据库设计
核心数据库关系如下:
设计方案还需细化,基本整体按照这个思路,就可以实现比较合理的基本的数据同步工具;
不过我们还有很多其它场景需要考虑更多细节:比如:
数据量超级超级大,一个大目录里有千万级文件,如何做好准实时同步?
关于这个问题,使用现有的方案会有一些性能问题,我们也有一些解法,这里暂不赘述。
