


Ceph基本读写流程
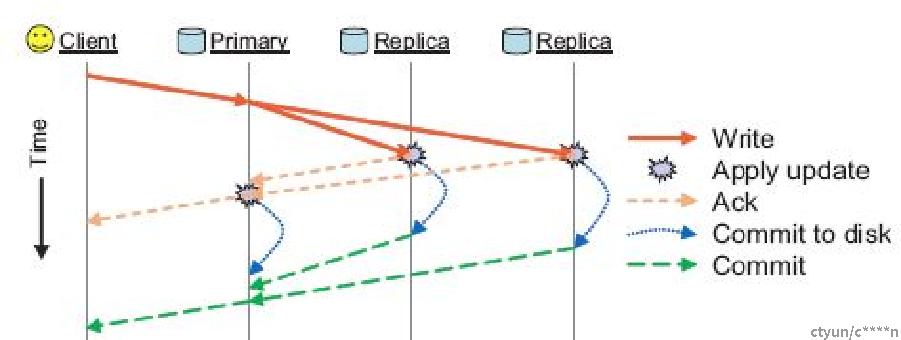
Ceph 的读写操作采用 Primary-Replica 模型,Client 只向 PG所对应 OSD set 的 Primary 发起读写请求,典型的IO流程如下: 客户端将object写请求提交至主PG中 主 PG负责同时向一个或者多个副本PG提交数据与pg_log_entry,并更新自身的pg_log。 当副本PG都写入完成后,主 PG向客户端返回写入成功。 通过主PG转发的强一致写方式,保证了pg_log的线性一致性
Peering
Peering基本概念
Ceph使用基于复制日志(replicated log)的数据一致性模型实现各副本间数据的一致。当集群出现故障(坏盘、宕机、网络中断)时,Ceph通过Peering操作来实现合并各PG副本的pg_log,并以此为基础重建PG权威历史(pg_log+missing set)。Peering操作的流程也是保证ceph数据一致性的核心流程。
定义:使存储放置组(PG)的所有OSD就该PG中所有对象(及其元数据)的状态达成一致的过程。请注意,同意状态并不意味着它们都具有最新的内容。
执行者:一般情况下由主PG执行,若主PG条件不满足,则重新选主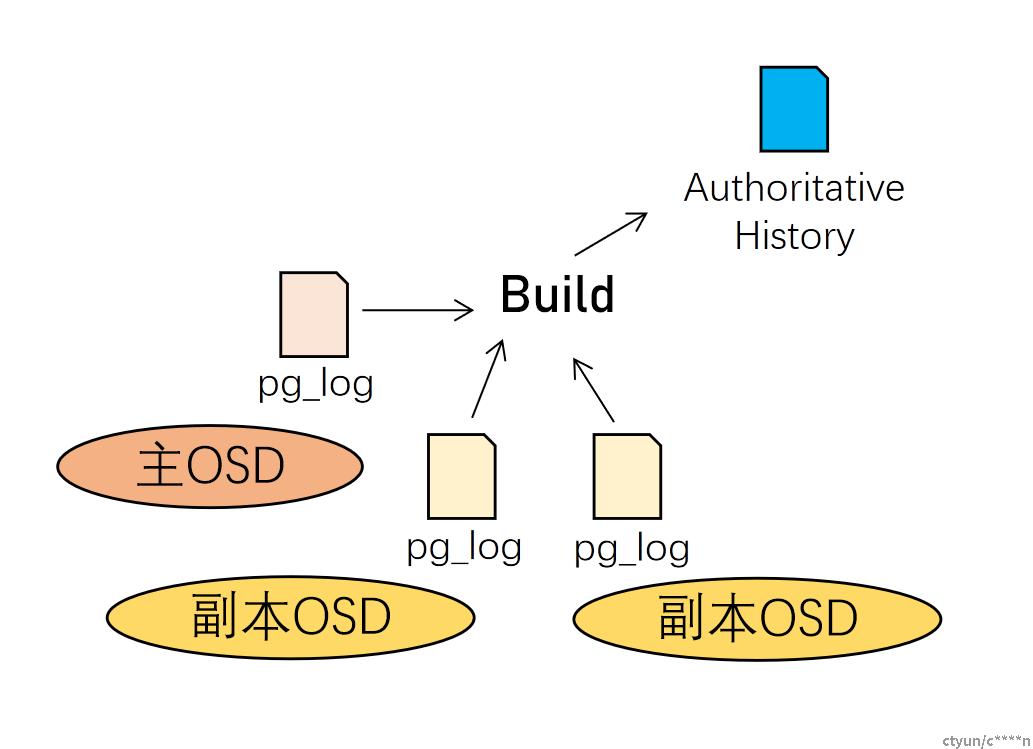
Peering基本流程
选取进行Peering的副本OSD
主PG会通过PG的up_set以及acting_set的变化,将PG的历史分为多个Interval,称为Past Intervals。遍历从last epoch start(上一次Peering完成的epoch)到当前epoch之间的所有Interval。若某个Interval内,PG可能会Peering成功,则该Interval中,PG有可能发生了读写。由于Ceph的强一致写特性,任何一个PG副本的log中,必然拥有写入成功的对象,所以PG成员必须至少有一个要参与当前的Peering过程。
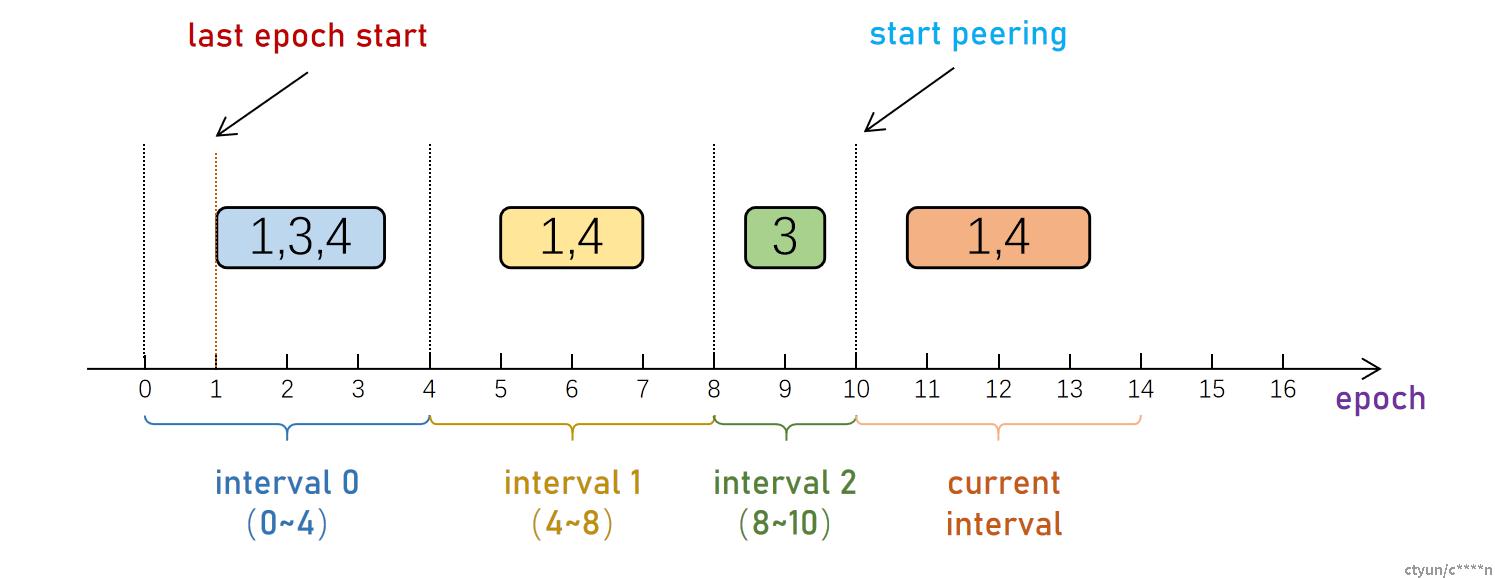
“可能会Peering成功”判定依据:
- Acting Primary存在
- Acting中的副本个数不小于存储池最小副本数(min_size),如上图: 当min_size为2时,interval 2中只有osd3存活,无法完成peering,本次peering时不考虑osd3 当min_size为1时,interval 2中只有osd3但可能完成peering,本次peering失败,必须等待osd3 up
选举master log
在PG获取到相关OSD集合之后,就已经知道了需要合并哪些OSD上的pg_log。此时OSD会选举出最具权威的日志作为日志合并的基础日志,也称“master log”。 主PG会根据上一步得到的相关OSD列表,拉取各个OSD上该PG的元信息。并通过元信息中last_update以及log_tail等信息根据一下规则选取master log: 优先选取具有最新内容的日志(last_update最大) 如果存在多分满足条件1的日志,优先选取日志条目最多的日志 如果存在多份满足条件2的日志,优先选取当前Primary PG(自己) 通过上述规则,能够理论上选择出尽量新,并与其他pg_log重合度最高的pg_log,有助于减少需要backfill的PG数量。
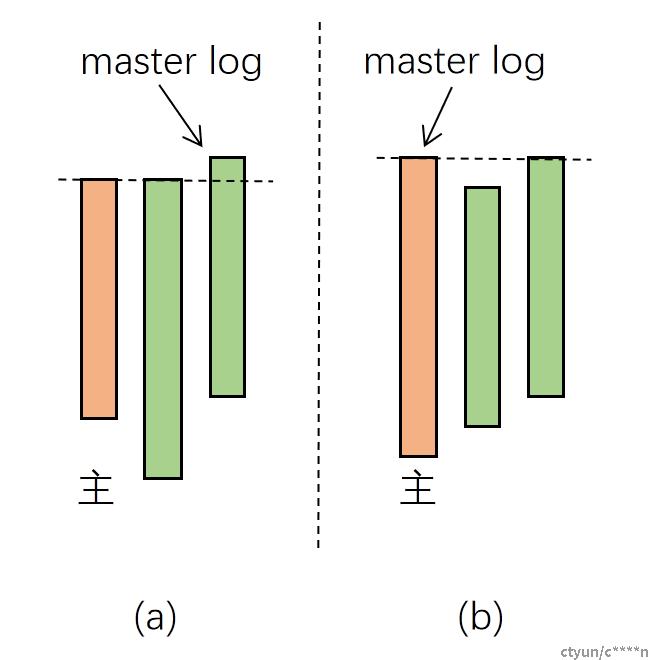
上图中,根据规则:
- 图(a)会选择第三个OSD上的日志作为master log;
- 图(b)会选择主PG所在OSD,即第一个OSD作为master log
选择出master log之后,若up set中第一个OSD上的PG副本的pg_log与master log重叠,则优先选择该OSD上的副本PG作为主PG。否则直接选择master log所在的副本PG作为主PG(通过PG_Temp指定)。
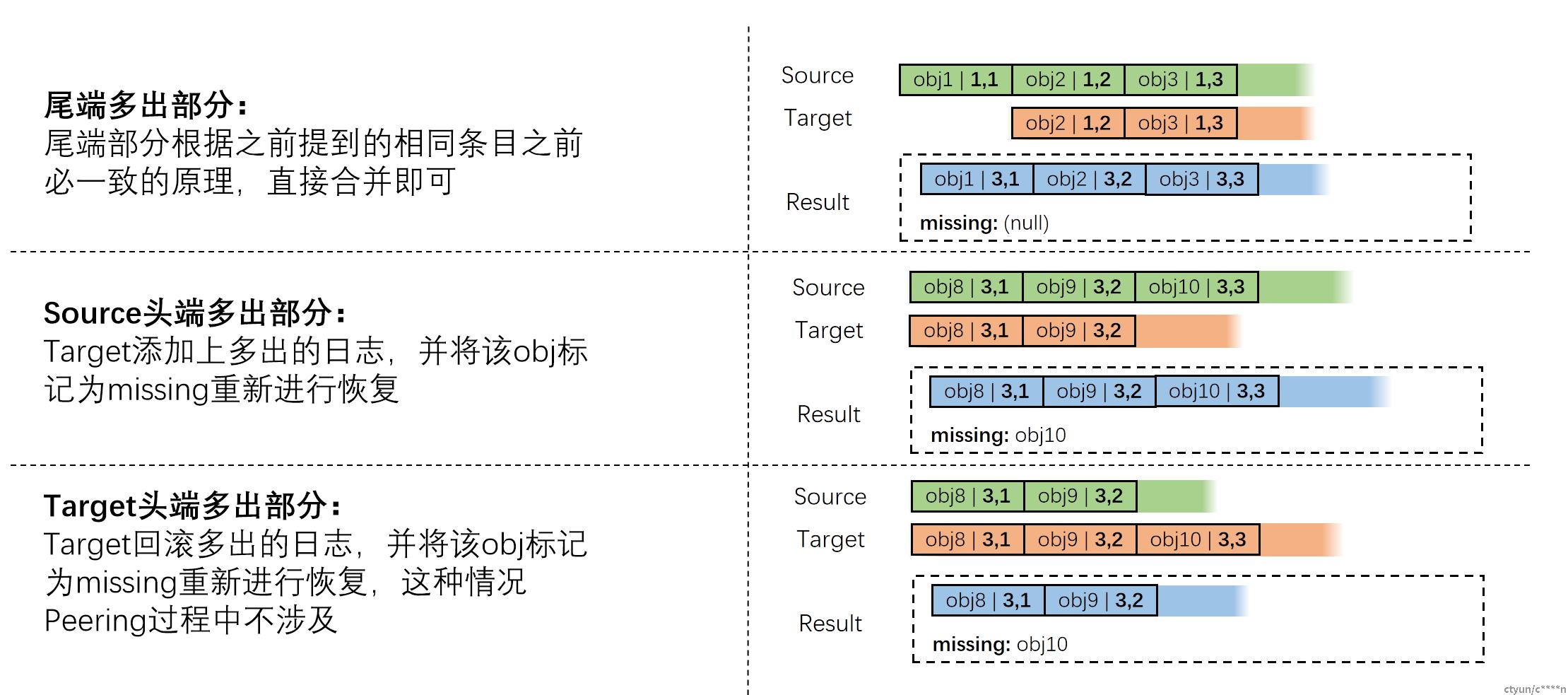
合并log,计算missing set
当选取master log之后,会将master log与其他副本log进行合并。合并一般采用如下规则进行:
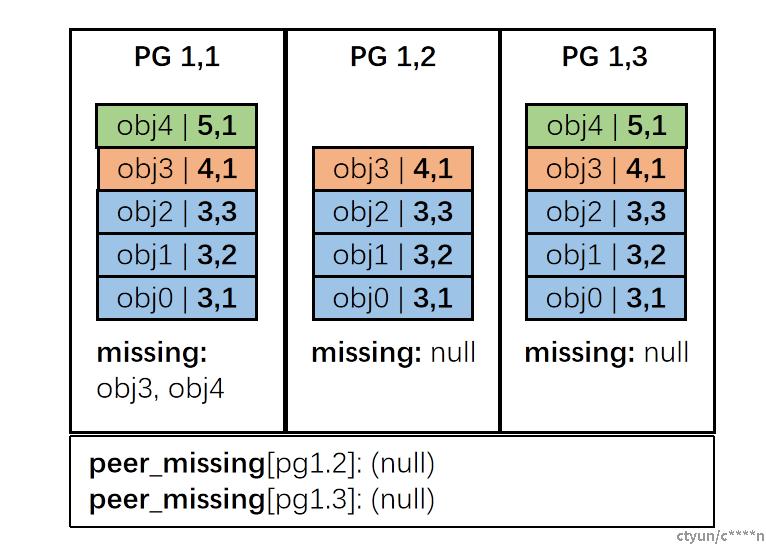
在选举完主PG以及master log之后,就可以构建权威历史。除此之外,主PG还需要知道各个副本PG的缺失对象列表(peer_missing)用于后续的数据恢复。以下通过实例说明具体步骤:

起始状态: pg_log如上图所示,peer_missing为空,根据先前规则选举master log为PG1,3的pg_log 根据选主规则,选择PG1,1为主PG
STEP1: 主PG首先合并master log用于构建权威历史。根据先前的提到的规则,主合并后的日志如右图,并且更新自己的missing set为obj3, obj4
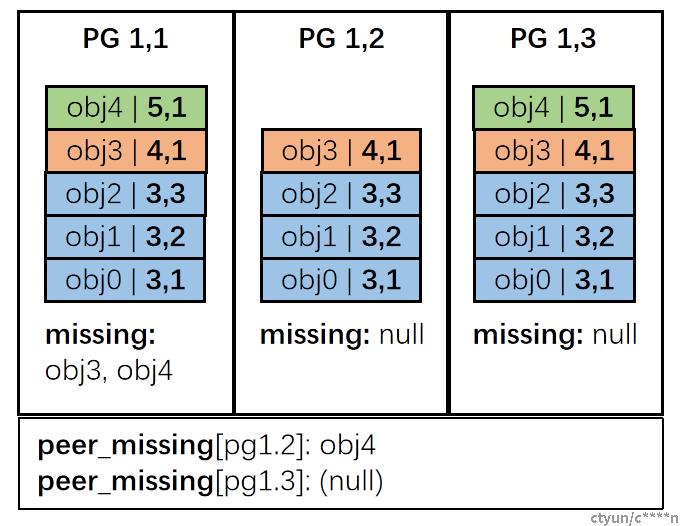
STEP2: 主PG拉取各个PG副本的pg_log(并不进行合并),并通过将这些pg_log与权威历史进行对比,得到各个PG副本缺失的条目并计入peer_missing中。如有图拉取PG1,2的pg_log后记录PG1,2缺失obj4,PG1,3无缺失
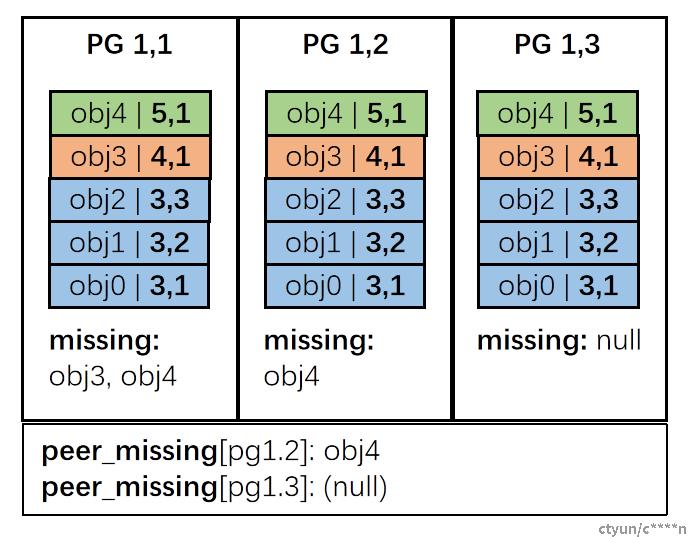
STEP3: 主PG将权威历史推送至各个PG副本,各个PG副本自身合并权威历史,并计算自己的missing set,如有图中PG1,2计算出自己缺少obj4并持久化该条目。
至此,整个Peering过程就已经完成,后续PG会转入activate状态。主PG根据自身missing set对缺失对象进行修复后,即通过peer_missing对PG副本进行数据修复
