



vacuum的作用
- 回收空间
即将dead tuple清理掉。但是已经分配的空间,一般不会释放掉。除非做vacuum full,但是需要exclusive lock。
- 冻结tuple的xid
opengauss会在每条记录(tuple)的header中,存放xmin,xmax信息(增删改事务ID)。transactionID的最大值为2的32次,即无符整形来表示。当transactionID超过此最大值后,会循环使用。
- 更新统计信息
vacuum analyze时,会更新统计信息,让opengauss的planner能够算出更准确的执行计划。
- 更新visibility map
在opengauss中,有一个visibility map用来标记那些page中是没有dead tuple的。这有两个好处,一是当vacuum进行scan时,直接可以跳过这些page。二是进行index-only scan时,可以先检查下visibility map。
- Truncate clog
Autovacuum完成之后,会对clog进行截断,但是不处理csnlog; csnlog是在checkpoint之后截断;
Vacumm分类
Vacuum安装触发时机和清理方式的不同可以分为三类:
- 清理级:只对heap page进行清理,不操作index page;读到该page时触发;空间不会回收;
- 中量级:对index page和heap page会清理,由后台线程触发;空间不会回收;
- 重量级:copy 数据,重建索引;由vacuum full命令触发。空间会回收;

轻量级清理
当查询扫描到堆表的page时,会尝试清理该页面上已经被删除的、足够老的元组。由于只是顺带清理该页面内容,因此只能删除元组内容本身,元组指针还需要保留,以免在索引侧造成空引用或空指针。HOT场景是指对于该表上所有的索引更新前后的索引键值均没有发生变化,因此对于更新后的元组只需要插入堆表元组而不需要新插入索引元组。对于同一个页面内一条HOT链上的多个元组,如果它们都足够老了,那么在清理时可以额外删除所有中间的元组指针,只保留第一个版本的元组指针,并将其重定向到第一个不用被清理的元组版本的元组指针。
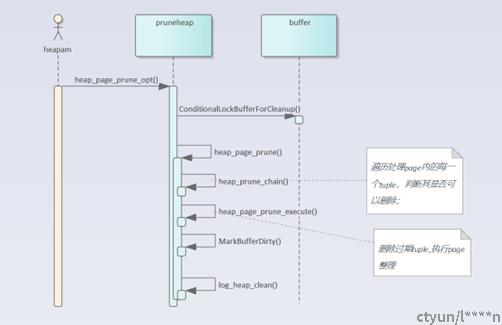
轻量级堆页面清理的接口heap_page_prune_opt函数:
-> 1. heapgetpage()
-> 2. heap_page_prune_opt()
-> 3. heap_page_prune()
-> 3.1 heap_prune_chain()
-> 3.2 heap_page_prune_execute()
-> 3.3 MarkBufferDirty()
-> 3.4 log_heap_clean()
Page能清理的条件:
- Page:: pd_prune_xid < RecentGlobalXmin
- Page写满,或者pages剩余容量小于max(FillFactor,block size/8);
- 加锁成功(try lock);
主要数据结构:
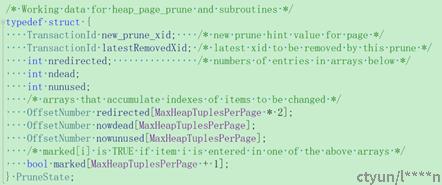
new_prune_xid:用于记录page上此次没有被清理的、但是已经被删除的元组的最小xmax,用于决定下次何时再次清理该页面;最终会赋值给pageheader::pd_prune_xid; 比如:删除事务还未提交或者删除事务的xid大于了oldestxid
latestRemovedXid:用于记录该页面上被清理的元组的最大的xmax,用于判断热备上回放页面整理时是否需要等待只读查询;
备注:
- xlog中记录的是:dead,unused,redirected tuple的itemid;
- 对page进行页面整理时,会按照offset排序;
中量级Vacuum(AutoVacuum)
vacuum相关参数

- autovacuum:默认为on,表示是否开起autovacuum。默认开起。
- autovacuum_mode:控制autoanalyze或autovacuum的打开情况:
analyze表示只做autoanalyze。
vacuum表示只做autovacuum。
mix表示autoanalyze和autovacuum都做。
none表示二者都不做。
- autovacuum_naptime:两次启动vacuum的时间间隔,默认10min。 这个naptime会被vacuum launcher分配到每个DB上。autovacuum_naptime/num of db。
- log_autovacuum_min_duration:记录autovacuum动作到日志文件,当vacuum动作超时。 “-1”表示不记录。“0”表示每次都记录。
- autovacuum_max_workers:最大同时运行的worker数量,不包含launcher本身。
- autovacuum_vacuum_threshold: 默认50。与autovacuum_vacuum_scale_factor配合使用, autovacuum_vacuum_scale_factor默认值为20%。当update,delete的tuples数量超过autovacuum_vacuum_scale_factor*table_size+autovacuum_vacuum_threshold时,进行vacuum。如果要使vacuum频繁点,则将此值改小。
- autovacuum_analyze_threshold: 默认50。与autovacuum_analyze_scale_factor配合使用, autovacuum_analyze_scale_factor默认10%。当update,insert,delete的tuples数量超过autovacuum_analyze_scale_factor*table_size+autovacuum_analyze_threshold时,进行analyze。
- autovacuum_freeze_max_age和autovacuum_multixact_freeze_max_age:前面一个200 million,后面一个400 million。强制执行vacuum的的xid上限,防止事务回卷。某表的relfrozenxid的最大值
- autovacuum_vacuum_cost_delay:如果为-1,取vacuum_cost_delay值。
- autovacuum_vacuum_cost_limit:如果为-1,取vacuum_cost_limit的值,这个值是所有worker的累加值。
- vacuum_cost_delay :开销操过vacuum_cost_limit时,线程睡眠的时间。 默认vacuum_cost_delay为20毫秒。
- vacuum_cost_limit:当超过此值时,vacuum会sleep。默认值为200。
- vacuum_cost_page_hit :vacuum时,page在buffer中命中时,所花的代价。默认值为1。
- vacuum_cost_page_miss:vacuum时,page不在buffer中,需要从磁盘中读入时的代价默认为10。
- vacuum_cost_page_dirty:当vacuum时,修改了clean的page。这说明需要额外的IO去刷脏块到磁盘。默认值为20。
- autoanalyze_timeout:设置autoanalyze的超时时间。在对某张表做autoanalyze时,如果该表的analyze时长超过了autoanalyze_timeout,则自动取消该表此次analyze,默认值:5min(即300s)。
- autovacuum_io_limits:控制autovacuum进程每秒触发IO的上限。
- vacuum_defer_cleanup_age:指定VACUUM使用的事务数,VACUUM会延迟清除无效的行存表记录,延迟的事务个数通过vacuum_defer_cleanup_age进行设置。即VACUUM和VACUUM FULL操作不会立即清理刚刚被删除元组,默认为0。
- vacuum_freeze_min_age:指定VACUUM在扫描一个表时用于判断是否用FrozenXID替换记录的xmin字段(在同一个事务中)。默认值:2000000000
- vacuum_freeze_table_age:指定VACUUM对全表的扫描冻结元组的时间。如果当前事务号与表relfrozenxid64字段的差值已经大于参数指定的时间时,VACUUM对全表进行扫描;默认值:4000000000
openGauss提供VACUUM语句来让用户主动执行对某个astore表(或某个库中所有的astore表)及其上的索引进行中量级清理。中量级清理过程中,不阻塞相关表的查询和DML操作。由于在astore表中,新、老版本元组是混合存储的,因此,与顺带执行的轻量级清理相比,astore表的中量级清理需要进行全表顺序(或索引)扫描,才能识别出所有待清理的老版本元组。对于扫描出来的确认要清理的元组,会首先清理索引中的元组,然后再清理堆表中的元组,从而可以避免出现索引空指针的问题。
线程模型

- AutoVacuum Launcher:调度线程;收集数据库运行信息,选择一个Database,并调度一个AutoVacuum Worker线程执行清理操作。Vacuum是database间的并行;
- AutoVacuum Worker:真正执行vacuum的线程;线程个数可以配置,默认3个;
AutoVacuum Launcher
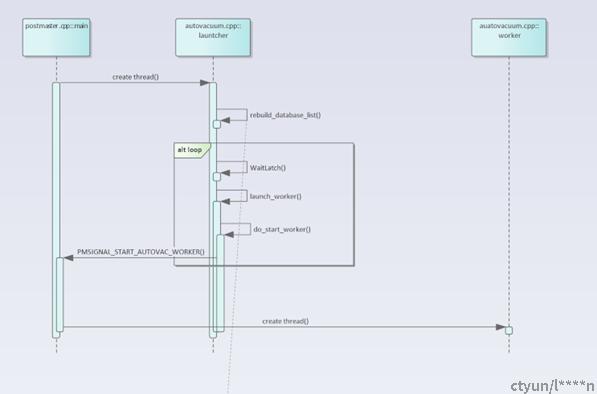
- rebuild_database_list()
创建一个database的链表,链表中的元素是所有需要做vacuum的db(同时pg_databsae和pg_stats中存在),链表中的DB按照其vacuum启动时间排序;各个database vacuum启动时间计算:
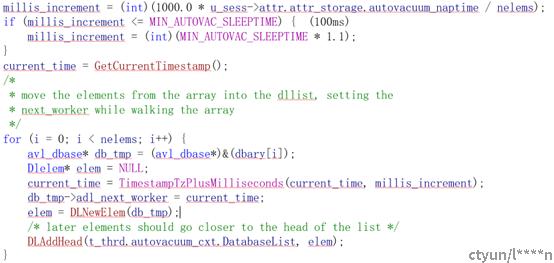
- WaitLatch()
等待时间根据第一步中计算的计算结果;
- 根据统计信息,选择一个DB,并发送信号给postmaster;
需要有空闲的work线程;
同时只能有一个DB 在starting vacuum;
AutoVacuum Launcher选择database规则:
- 存在Database的frozenxid超过配置autovacuum_freeze_max_age时,寻找frozenxid最小的Database对其进行vacuum。
- 如果第一步没有找出满足条件的database,则选择database列表中最早未执行过vacuum操作的database。
AutoVacuum Worker
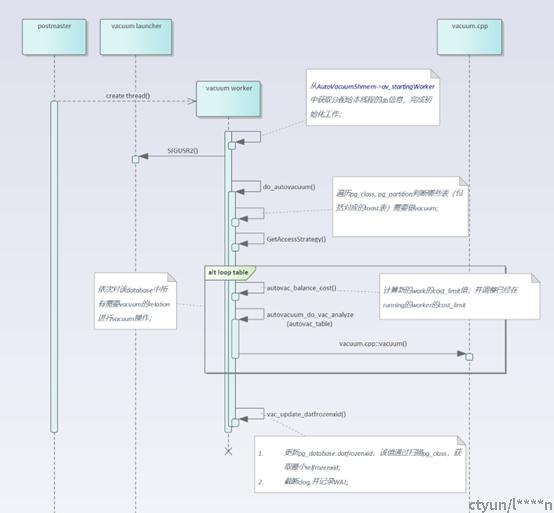
从pg_class中过滤出需要做vacuum的表类型,如:view、index、sequnence,temp table,globle temp table等不需要vacuum;
vac_truncate_clog,Clog的截断位置,通过扫描pg_database,取最小的datfrozenxid;
判断是否需要vacuum
relation_needs_vacanalyze(),判断table是否需要vacuum/analyze,以及是否需要强制vacuum,判断方法如下:
- Table 的relfrozenxid < recentXid - autovacuum_freeze_max_age为了防止XID 的回卷问题,这时必须强制vacuum;
- 该表统计信息中标记为dead的元组数大于autovacuum_vacuum_threshold+ autovacuum_vacuum_scale_factor* reltuples时,需要vacuum;
- 该表统计信息中从上次analyze之后改变(insert,update,delete)的元组数大约autovacuum_analyze_threshold+ autovacuum_analyze_scale_factor* reltuples时,需要analyze
AutoVacuum cost balance
为了尽量避免vacuum对当前DML操作的影响,从而减少因vacuum而对系统IO的压力,PG对vacuum进行了限流,通过在处理每个block之间加入sleep来实现:
- 新的的AutoVacuum worker线程加入,会balance每个worker线程的cost limit和cost delay;通过autovac_balance_cost()函数实现: 计算每个worker的cost limit,并对已经runing的worker的cost limit,进行调整;
- Worker线程在执行过程中会统计其IO代价消耗,并在处理每个page(包括data ,index,VM, FSM几种page)之间sleep:
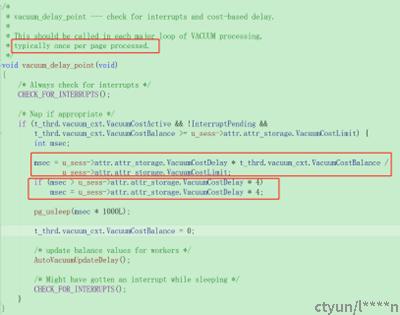
其中:
vacuumCostBalance = vacuum_cost_page_hit * x + vacuum_cost_page_miss*Y + vacuum_cost_page_dirty*Z。其中x,y,z为访问次数;在vacuum执行过程中会统计该值;
VacuumCostLimit
vacuum_cost_limit是所有vaucuum的总计,所有vacuum worker在vacuum_cost_delay时间段内所允许消耗的最大IO。每个vacuum_worker都会进行vacuum worker之间的rebalance,得到此worker的VacuumCostLimit值;
每次delay最小值为vacuum_cost_delay值,最大值为4*vacuum_cost_delay值。判断依据为VacuumCostBalance / VacuumCostLimit的值是否大于”4“。大于”4“之后就是4*vacuum_cost_delay。PG设置delay最大值为4倍,就是不希望延迟太长。
vacuum()->vacuum_rel()
AutoVacuum和vacuum命令最终都会调用到vacuum.cpp::vacuum()函数中;
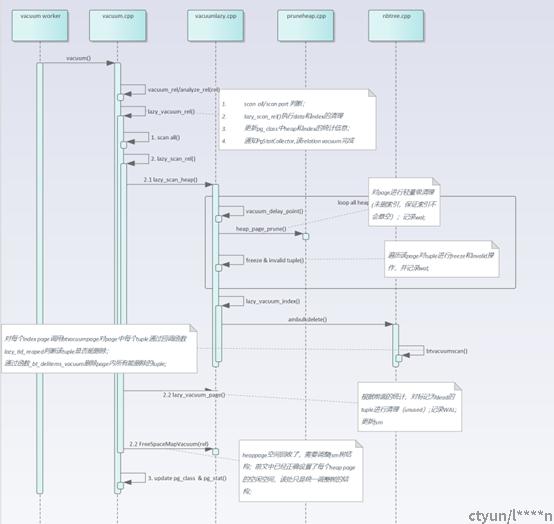
lazy_vacuum_rel 获取oldestXmin,relfrozenxid,scan all判断,open indexes等;
lazy_scan_rel
- lazy_scan_heap 扫描heap relation的每个block查找可以清理的tuples:
- vm block,heap block 加锁
- heap_page_prune, 轻量级清理(不涉及索引);
- 扫描page,逐一判断tuple是否满足vacuum条件,freezing判断;
- lazy_vacuum_index清理dead tuples对应的所有indexes;
- lazy_vacuum_page清理dead tuples;
- FreeSpaceMapVacuum
relfrozenxid < newestxid - vacuum_freeze_table_age ? scan all : part scan(强制freeze);
scan all不会跳过mv标记为全部可见的block;
重量级清理(vacuum full)
无论是轻量级清理,或是中量级清理,都只能局部清理astore页面中的死亡元组,无法真正实现对这些空闲空间的释放(被清理出的空间,仍然只能被该表使用)。因此,openGauss还提供了VACUUM FULL语句来让用户主动执行对某个astore表(或某个库中所有astore表)及其上的索引进行重量级清理。重量级清理将一个表中所有仍未死亡(但是可能已经被删除)的元组重新紧密插入到新的堆表文件中并在此基础上重新创建所有索引,从而实现对空闲空间的彻底回收。在重量级清理的主体流程中只允许用户执行只读查询操作,在重量级清理的提交流程中只读查询操作也会被阻塞。
为了尽可能提高重新创建的索引性能,如果用户堆表上有索引,那么上述全表扫描会采用索引扫描。
代码流程
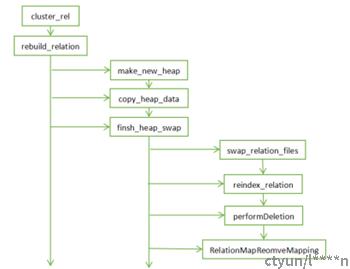
- make_new_heap会调用heap_create_with_catalog()函数进行新的临时表创建,表名为pg_temp_%u。
- copy_heap_data函数的过程是:初始化新旧元组,置use_wal标识(copy过程需要记录wal日志),计算freezexid用以剔除死元组,置新表relfrozenxid值,通过优化器评估使用indexscan还是seqscan算法进行扫描,扫描元组,记录日志,写入新堆表。
- 拷贝完数据后调用finish_heap_swap函数完成切换,第一步swap_relation_files切换表的oid、tablespace等信息。
- 再调用reindex_relation函数进行索引的重建,invalid索引也会被重建,重建后invalid索引可以正常使用。
- 最后就是删除临时表,同时删除临时表的map信息。
备注
- 在数据copy阶段新表老表都是7级锁(只允许select),在swap阶段8级锁(阻塞所有操作);
- 这里使用了两个hashtable 来暂存update操作对应的mvcc版本链,rs_unresolved_tups rs_old_new_tid_map,opengauss的astore使用mvcc版本管理,老版本通过ctid指向新版本,vacuum full之后,新老版本的tid均变化,所以老版本必须修改其ctid;
