


本文主要对深度学习时代的文本检测技术做一些概要性介绍,回顾文本检测技术的一些关键技术发展。
1. 背景介绍
首先我们来看看文本检测是什么、有什么用、以及有什么难点。
1.1 文本检测任务介绍
任务简介
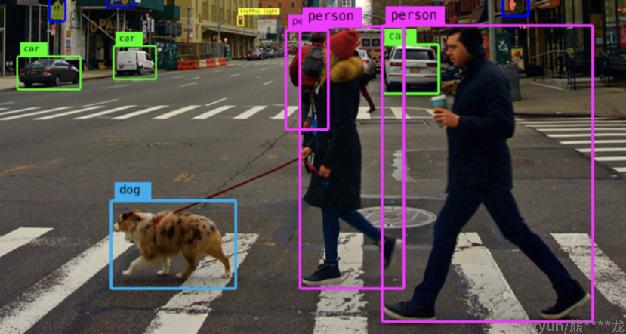
文本检测任务是指通过ocr算法定位出图像中的文字位置。不同于目标检测任务需要同时解决目标的定位和分类任务,文本检测仅需处理定位问题。如下图所示分别为文本检测和目标检测的示例。

应用场景
文字作为一种常用的信息载体,存在于各种场景中,在这些场景中均有用到文本检测技术。它在使用时一般与文本识别技术相结合进行应用。以下列举了一些常见的应用场景。
卡证文字识别: 身份证、银行卡、营业执照、房产证等
票据文字识别:增值税发票、火车票、行程单、保险单据等
行业文档识别: 表格、印章、试卷、文档版面分析、古籍文档等
实体标识识别: 街景指示牌、广告牌、地图POI(Point of Interest)等
网络图片文字识别: 电商商品广告、社区贴吧图片、短视频直播等文字内容审核等
通用文字识别:截图识别、拍照文字识别、视频内容分析、文字内容审核等
难点
文本检测技术存在的技术难点大致包含以下几点:
- 背景多样性,自然场景下文本行的背景复杂,同时会受到光照、阴影、遮挡等因素影响;
- 形状尺度多样性,具有水平、垂直、倾斜、弯曲等多种方向与形状,字体大小差异大,长宽比很大;
- 文字粒度多样性:可能以字符,单词,文本行等多种方式出现,都可以视为独立文本,存在歧义;
- 文本密集与重叠: 文本密集和重叠文本会影响文字检测;
2 技术方案
2.1 算法时间轴
在介绍文本检测方法前。我们先跳出文本检测这个子领域,去看看在深度学习技术应用到文本检测 这个子方向之前一些相关方向有什么技术进展。把时间跳回到2015年,2015年这一年相关几个方向都涌现了对后续技术发展有着深远影响的突破性技术,在目标检测上出现了单阶段YOLO和双阶段fast rcnn方法,其中yolo系列在现今工业界已得到非常广泛的应用。在语义分割方向出现了语义分割领域的开山之作FCN全卷积网络。
2.2 文本检测方法
从2016年首个应用了深度学习技术到文本检测任务的CTPN模型出现开始,后续就陆续出现了各种应用深度学习技术方法的文本检测模型。这里分时间段和一些关键词对这些技术进行一些简要的介绍。
前面我们有提到文本检测任务与目标检测任务比较类似,很自然的会去思考如何在文本检测场景下使用目标检测的方法,最初的一些深度学习文本检测技术便是如此去应用的。
2016-2018 关键词: 水平文本、倾斜文本、通用目标检测
问题:如何适配目标检测算法到文字检测上
思路:目标转换,修改锚框尺寸和卷积核来适应文本目标
2016: CTPN (2016 Faster rcnn)
ctpn是第一个将目标检测思想应用到文本检测领域的文本检测方法,它受启发于2016年出现的faster rcnn目标检测方法,将其改造适配于文本检测领域。考虑到单行文本行长度变化差异太大,直接作为目标进行检测可能会效果不好,ctpn将目标转换为先检测文本小片段再做合并得到文本行,预测时固定了文本片段的宽度,只需要预测文本的高度和高度偏移。
2017年:TextBox (2016 ssd)
Textbox也是受启发于目标检测网络SSD,对其进行了改造来适配文本检测。不同于CTPN预测切割的文本小片段,Textbox是直接回归整个文本框,优化了锚框的尺寸和卷积核尺寸来适应文本目标,加上SSD网络本身有多尺度 应用,可以较好的应对文本尺寸变化较大这一困难。根据特定目标场景来优化网络的策略值得学习,比如如果是检测电线杆、吸烟这种特殊尺寸的目标,可以调整锚框比例和卷积核尺寸。
2018年:TextBox ++
上述两个方案,只能处理水平文本,并不能应用于倾斜文本检测,TextBox ++在之前的基础上,增加输出维度去回归角度使得网络能够胜任倾斜文字场景。
2018-2019 关键词: 弯曲文本、实例分割、可学习后处理
问题:边框回归的目标检测,将水平、倾斜文本定位做到了较高水平,但四边形回归很难处理弯曲文本。
思路: 使用实例分割逐像素的分类文本像素,再找轮廓得到文本框
新问题: 二值化阈值固定,对性能影响较大;后处理十分复杂且耗时
思路: 可学习的二值化阈值
先前的一些方案已经将水平文本和倾斜文本场景做到了一个较高的水平,但采用边框回归的方法很难处理弯曲文本,在2018年左右开始出现了基于分割的方法来处理弯曲文本检测。大致的思路是使用实例分割逐像素的分类文本像素,再找轮廓得到文本框,这样能够更精确的得到弯曲的轮廓。典型的方案代表有pixellink、PseNet、Dbnet。然而这一方法在应用时又出现了新的问题。像素分类后需要确定二值化阈值来区分前景和背景,它对精度的性能影响比较大。此外,这一思路的早期方法pixellink、PseNet使用了比较复杂的后处理来得到文本轮廓,使得该方法在应用时虽然精度有所提升,但也比较耗时。如何避免复杂的后处理带来的耗时成了一个新的问题,2019年华科白翔团队的dbnet网络创新型的提出了一个可学习的二值化阈值方法较好的缓解了二值化阈值和复杂后处理的问题。值得一提的是,dbnet也是目前工业界应用最为广泛的一种主流文本检测方案。
2021 其他方案: 弯曲文本、傅里叶变换
2021: FceNet
思路:傅里叶变换可以拟合任何封闭轮廓,文本框重采样转换为傅里叶特征向量类唯一表示文本轮廓
在回归和分割方法出现后,大部分的文字检测任务能够得到比较好的解决,但在一些复杂场景下仍然存在瓶颈,特别是弯曲文本的精度还不是很理想。如何提高复杂弯曲文本的检测精度至今仍然是一个比较富有挑战的问题。2021年金连文团队提出了一个FCENet网络,方法比较新颖,使用傅里叶变换来得到文本的包围框,该方法在弯曲文本数据集(ctw1500、total-text)上可以达到sota的效果。
3 小结
总的来说,文本检测大致分为基于分割和基于回归的两种方法,最初的方法在目标检测方法上进行改造适配,随着任务难度逐渐加大引入分割方法可以更加精确的定位文本位置,后续也有诸如基于傅里叶变换的其他方法在弯曲文本上取得了更好的效果。在使用上,文本检测一般不是独立的,通常会与文本识别相结合进行应用。
