


ceph_osd.cc
main()
{
...
//创建心跳messenger
Messenger *ms_hb_back_client = Messenger::create(g_ceph_context, cluster_msgr_type,
entity_name_t::OSD(whoami), "hb_back_client",
getpid(), Messenger::HEARTBEAT); //发送心跳信息
Messenger *ms_hb_front_client = Messenger::create(g_ceph_context, public_msgr_type,
entity_name_t::OSD(whoami), "hb_front_client",
getpid(), Messenger::HEARTBEAT);//发送心跳信息
Messenger *ms_hb_back_server = Messenger::create(g_ceph_context, cluster_msgr_type,
entity_name_t::OSD(whoami), "hb_back_server",
getpid(), Messenger::HEARTBEAT); //接收心跳信息
Messenger *ms_hb_front_server = Messenger::create(g_ceph_context, public_msgr_type,
entity_name_t::OSD(whoami), "hb_front_server",
getpid(), Messenger::HEARTBEAT); //接收心跳信息
...
//绑定地址
r = ms_hb_back_server->bind(hb_back_addr);
if (r < 0)
exit(1);
r = ms_hb_back_client->client_bind(hb_back_addr);
if (r < 0)
exit(1);
r = ms_hb_front_server->bind(hb_front_addr);
if (r < 0)
exit(1);
r = ms_hb_front_client->client_bind(hb_front_addr);
if (r < 0)
exit(1);
...
}2 启动心跳线程
OSD.cc
int OSD::init()
{
...
tick_timer.init();
tick_timer_without_osd_lock.init();
...
//messenger添加dispatcher
hb_front_client_messenger->add_dispatcher_head(&heartbeat_dispatcher);
hb_back_client_messenger->add_dispatcher_head(&heartbeat_dispatcher);
hb_front_server_messenger->add_dispatcher_head(&heartbeat_dispatcher);
hb_back_server_messenger->add_dispatcher_head(&heartbeat_dispatcher);
...
// start the heartbeat
heartbeat_thread.create("osd_srv_heartbt");//创建心跳进程
// tick
tick_timer.add_event_after(get_tick_interval(),
new C_Tick(this));
{
Mutex::Locker l(tick_timer_lock);
tick_timer_without_osd_lock.add_event_after(get_tick_interval(),
new C_Tick_WithoutOSDLock(this));
}
...
}
void add_dispatcher_head(Dispatcher *d) {
bool first = dispatchers.empty();
dispatchers.push_front(d);
if (d->ms_can_fast_dispatch_any())
fast_dispatchers.push_front(d);
if (first)
ready();
}
struct HeartbeatDispatcher : public Dispatcher {
...
bool ms_can_fast_dispatch_any() const override { return true; } //支持fast dispatch,不经过队列
...
}-
发送心跳PING包
-
C_Tick_WithoutOSDLock线程 心跳超时检查和上报monitor等
-
C_Tick线程
3 获取心跳peer
tick()/handle_pg_create()/_committed_osd_maps()都会调用maybe_update_heartbeat_peers()来更新heartbeat_peers。
4 发送心跳信息
通过osd_srv_heartbt线程周期性的(osd_heartbeat_interval=6,在该基础上进行随机波动,间隔时间为0.5~5.9秒)进行心跳PING包发送。
OSD.cc
struct T_Heartbeat : public Thread {
OSD *osd;
explicit T_Heartbeat(OSD *o) : osd(o) {}
void *entry() override {
osd->heartbeat_entry();
return 0;
}
} heartbeat_thread;
void OSD::heartbeat_entry()
{
Mutex::Locker l(heartbeat_lock);
if (is_stopping())
return;
while (!heartbeat_stop) {
heartbeat();//执行心跳
double wait = .5 + ((float)(rand() % 10)/10.0) * (float)cct->_conf->osd_heartbeat_interval; //计算等待随机值
utime_t w;
w.set_from_double(wait);
dout(30) << "heartbeat_entry sleeping for " << wait << dendl;//等待一段时间继续心跳[0.5,5.9]
heartbeat_cond.WaitInterval(heartbeat_lock, w);
if (is_stopping())
return;
dout(30) << "heartbeat_entry woke up" << dendl;
}
}5 心跳接收
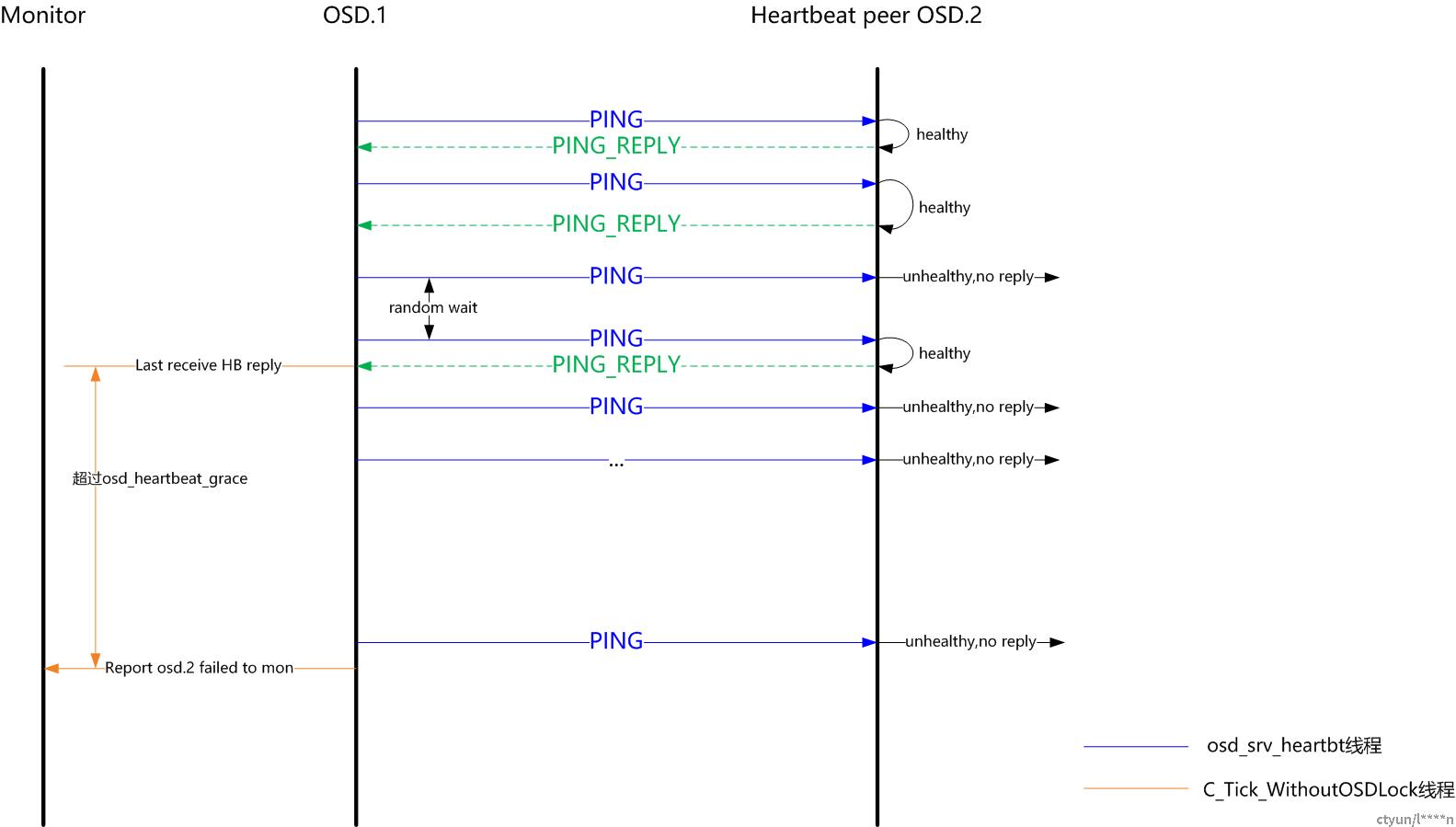
1)收到PING消息
a)首先,会判断自身健康状态(线程是否超时),若健康,则回复PING_REPLY消息;若不健康,则不会回复;
b)若已回复PING_REPLY消息,根据当前osdmap判断发送端osd的状态,若对端osd已不存在或down_at epoch号大于消息中的epoch,则给对端发送YOU_DIED的消息;
收到PING包时,会判断自身线程是否存在超时,若存在超时,则不会回复PING_REPLY
2)收到PING_REPLY回包消息
收到回包时,首先会更新HeartbeatInfo中的接收时间戳;
然后检查心跳是否超时,如没有超时,检查failure_queue中是否有该target osd的记录,若有则移除;
然后检查failure_pending中是否有该target osd的记录(如果有则说明已经上报过monitor),则给mon发送该target osd仍然存活的消息,mon会从target osd的reporter中移除汇报osd;
3)收到YOU_DIED消息
订阅更新osdmap
6 心跳超时检查和上报monitor
C_Tick_WithoutOSDLock线程会周期性的(间隔约1s)执行心跳检测(heartbeat_check)和上报检测,若满足上报条件,则send_failures。
6-1 heartbeat_check
void OSD::heartbeat_check()
{
assert(heartbeat_lock.is_locked());
utime_t now = ceph_clock_now();
// check for heartbeat replies (move me elsewhere?)
utime_t cutoff = now;
cutoff -= cct->_conf->osd_heartbeat_grace; //cutoff为当前时间-20s
for (map<int,HeartbeatInfo>::iterator p = heartbeat_peers.begin();
p != heartbeat_peers.end();
++p) {
if (p->second.first_tx == utime_t()) {
dout(25) << "heartbeat_check we haven't sent ping to osd." << p->first
<< "yet, skipping" << dendl;
continue;
}
dout(25) << "heartbeat_check osd." << p->first
<< " first_tx " << p->second.first_tx
<< " last_tx " << p->second.last_tx
<< " last_rx_back " << p->second.last_rx_back
<< " last_rx_front " << p->second.last_rx_front
<< dendl;
if (p->second.is_unhealthy(cutoff)) { //检查是否超时
if (p->second.last_rx_back == utime_t() ||
p->second.last_rx_front == utime_t()) {
derr << "heartbeat_check: no reply from " << p->second.con_front->get_peer_addr().get_sockaddr()
<< " osd." << p->first << " ever on either front or back, first ping sent "
<< p->second.first_tx << " (cutoff " << cutoff << ")" << dendl;
// fail
failure_queue[p->first] = p->second.last_tx; //加入failure_queue
} else {
derr << "heartbeat_check: no reply from " << p->second.con_front->get_peer_addr().get_sockaddr()
<< " osd." << p->first << " since back " << p->second.last_rx_back
<< " front " << p->second.last_rx_front
<< " (cutoff " << cutoff << ")" << dendl;
// fail
failure_queue[p->first] = MIN(p->second.last_rx_back, p->second.last_rx_front); //加入failure_queue
}
}
}
}6-2 send_failures
上报monitor,通过monc发送MOSDFailure消息给monitor
针对failure_queue中的元素
1)若failure_pending中没有,上报monitor,发送MOSDFailure消息,并加入failure_pending中,从failure_queue中移除;
2)若failure_pending中已存在,直接从failure_queue中移除;
failure_queue : 记录待上报的peer osd
failure_pending : 记录已上报monitor的peer osd
void OSD::send_failures()
{
assert(map_lock.is_locked());
assert(mon_report_lock.is_locked());
Mutex::Locker l(heartbeat_lock);
utime_t now = ceph_clock_now();
while (!failure_queue.empty()) {
int osd = failure_queue.begin()->first;
if (!failure_pending.count(osd)) {
entity_inst_t i = osdmap->get_inst(osd);
int failed_for = (int)(double)(now - failure_queue.begin()->second);
monc->send_mon_message(new MOSDFailure(monc->get_fsid(), i, failed_for,
osdmap->get_epoch()));
failure_pending[osd] = make_pair(failure_queue.begin()->second, i);
}
failure_queue.erase(osd);
}
}其中,MOSDFailure消息类型为MSG_OSD_FAILURE,消息中的flags设置为FLAG_FAILED。
7 monitor收到MOSDFailure消息
monitor收到消息后,根据其类型MSG_OSD_FAILURE,最终会由OSDMonitor进行处理。
7-1 preprocess_failure预处理
预处理阶段主要是对汇报osd以及bad osd做相关检查,以及bad osd是否允许标down:
1)首先根据osdmap检查reporting osd的信息,若osd id不存在、地址发生变化、osd状态为down,则忽略,并发送osdmap更新;
2)根据osdmap检查bad osd的信息,如果 bad osd的状态已经为down,或者消息中bad osd的信息(类型、id/num、地址信息)与osdmap中的不一致,视为异常,判断接收消息中的osdmap版本号,若小于当前osdmap的版本号,则给reporting osd发送增量osdmap;
3)如果bad osd的状态已经为down,或者其up_from大于消息中的epoch,视为重复汇报,判断接收消息中的osdmap版本号,若小于当前osdmap的版本号,则给reporting osd发送增量osdmap;
4)判断bad osd是否可以标down,如果该osd设置了NODOWN标志,或者已经被标记为NODOWN,或者当前的osd up比例小于最小比例(mon_osd_min_up_ratio),则当前osd不允许标down。
7-2 prepare_failure
预处理检查之后,prepare_failure阶段根据消息中的标志,检查确认是否将目标osd标记为down,或者在reporters中移除汇报osd(取消汇报的场景)。
bool OSDMonitor::prepare_failure(MonOpRequestRef op)
{
op->mark_osdmon_event(__func__);
MOSDFailure *m = static_cast<MOSDFailure*>(op->get_req());
dout(1) << "prepare_failure " << m->get_target()
<< " from " << m->get_orig_source_inst()
<< " is reporting failure:" << m->if_osd_failed() << dendl;
int target_osd = m->get_target().name.num();
int reporter = m->get_orig_source().num();
assert(osdmap.is_up(target_osd));
assert(osdmap.get_addr(target_osd) == m->get_target().addr);
if (m->if_osd_failed()) { //消息中的flags带有FLAG_FAILED标记
// calculate failure time
utime_t now = ceph_clock_now();
utime_t failed_since =
m->get_recv_stamp() - utime_t(m->failed_for, 0);
// add a report
if (m->is_immediate()) {
mon->clog->debug() << m->get_target() << " reported immediately failed by "
<< m->get_orig_source_inst();
force_failure(target_osd, reporter);
mon->no_reply(op);
return true;
}
mon->clog->debug() << m->get_target() << " reported failed by "
<< m->get_orig_source_inst();
failure_info_t& fi = failure_info[target_osd];
MonOpRequestRef old_op = fi.add_report(reporter, failed_since, op); //添加reporter
if (old_op) {
mon->no_reply(old_op);
}
return check_failure(now, target_osd, fi);
} else { //消息为带有仍然存活标志FLAG_ALIVE的消息
// remove the report
mon->clog->debug() << m->get_target() << " failure report canceled by "
<< m->get_orig_source_inst();
if (failure_info.count(target_osd)) {
failure_info_t& fi = failure_info[target_osd];
MonOpRequestRef report_op = fi.cancel_report(reporter);//从目标osd的failure_info中移除该reporter
if (report_op) {
mon->no_reply(report_op);
}
if (fi.reporters.empty()) {
dout(10) << " removing last failure_info for osd." << target_osd
<< dendl;
failure_info.erase(target_osd);//如果reporter空了,就在failure_info中移除目标osd的信息
} else {
dout(10) << " failure_info for osd." << target_osd << " now "
<< fi.reporters.size() << " reporters" << dendl;
}
} else {
dout(10) << " no failure_info for osd." << target_osd << dendl;
}
mon->no_reply(op);
}
return false;
}check_failure
1)首先判断pending_inc中是不是已经标记为down,若已经标记,则返回;
2)遍历failure_info_t中的reporter,统计reporter的个数;
3)检查目标osd是否满足标down条件(1、failed_for时间超过阈值[默认20s];2、reporter个数超过阈值[默认3]),则在pending_inc中将目标osd的状态标记为down;
"osd_heartbeat_grace": "20", ##心跳超时时间, tell修改后立即生效
"osd_heartbeat_interval": "6", ##osd与osd心跳间隔,该值为base,基于该值计算间隔,发送间隔为0.5~5.9随机值
"osd_heartbeat_min_healthy_ratio": "0.330000", ##心跳peers中的最小up比例,小于该值osd判断为unhealthy,OSD::_is_healthy()
"osd_heartbeat_min_peers": "10", ##心跳peer最小个数
"osd_heartbeat_min_size": "2000", ##心跳消息的最小大小
"osd_heartbeat_use_min_delay_socket": "false",
"osd_debug_drop_ping_probability": "0.000000
"heartbeat_inject_failure": "0" ##注入的心跳故障时间,[now,now+该值]时间段内判定为unhealthy,不回心跳HeartbeatMap::is_healthy()
"osd_mon_report_interval_max": "600" ##osd向mon汇报最大间隔
"osd_mon_report_interval_min": "5" ##osd向mon汇报最小间隔
"osd_mon_heartbeat_interval": "30" ##osd与mon心跳间隔
"osd_mon_ack_timeout": "30.000000"
"osd_stats_ack_timeout_factor": "2.000000"
"osd_mon_report_max_in_flight": "2"
"mon_osd_min_up_ratio": "0.300000" ##up osd的最小比例
"mon_osd_reporter_subtree_level": "host"
"mon_osd_laggy_halflife": "3600"
"mon_osd_adjust_heartbeat_grace": "false"
"mon_osd_min_down_reporters": "3" ##osd 标down时最小的汇报个数
"osd_beacon_report_interval": "300" ##给mon发送beacon消息的间隔 5分钟
"mon_osd_report_timeout": "900"
...
结语
心跳异常通常可以用来判断当集群出现异常时,是网络问题还是磁盘性能问题。
