


- vdbench 简介
vdbench是由oracle公司用java语言开发的一个磁盘I/O负载生成器,用来评估和测试存储系统性能的开源工具。它可以模拟各种负载类型,包括顺序读/写,随机读/写,随机混合读/写等,并提供丰富的配置选项和参数来满足不同的测试需求。此工具可以运行在windows和linux上
- vdbench版本包获取
1.vdbench版本包:https://www.oracle.com/downloads/server-storage/vdbench-downloads.html
vdbench工具的使用依赖于java,所以需要部署jdk环境
2. jdk版本包下载链接
windows:https://download.oracle.com/otn/java/jdk/8u251-b08/3d5a2bb8f8d4428bbe94aed7ec7ae784/jdk-8u251-windows-x64.exe
linux:https://download.oracle.com/otn/java/jdk/8u251-b08/3d5a2bb8f8d4428bbe94aed7ec7ae784/jdk-8u251-linux-x64.tar.gz
- vdbench配置与使用
- 安装部署
- linux客户端
a. 解压缩jdk安装包至某个目录,如/root 目录:tar -zxvf jdk-8u251-linux-x64.tar.gz -C /root/
b. 配置jdk环境变量:
echo 'JAVA_HOME=/root/jdk1.8.0_251' >> /root/.bashrc
echo 'PATH=$JAVA_HOME/bin:$PATH' >> /root/.bashrc
echo 'CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar' >> /root/.bashrc
c. 使配置文件生效:source /root/.bashrc
d. 配置完后执行java -version验证是否配置成功

- windows客户端
直接安装jdk软件即可(环境变量在安装完成后会自动添加)
2. 使用
a.上传vdbench50407zip到执行目录并解压:unzip vdbench50407 -d vdbench50407
b. 进入到vdbench50407目录:cd vdbenchV50407
c. 执行 ./vdbench -t ,验证可用性:
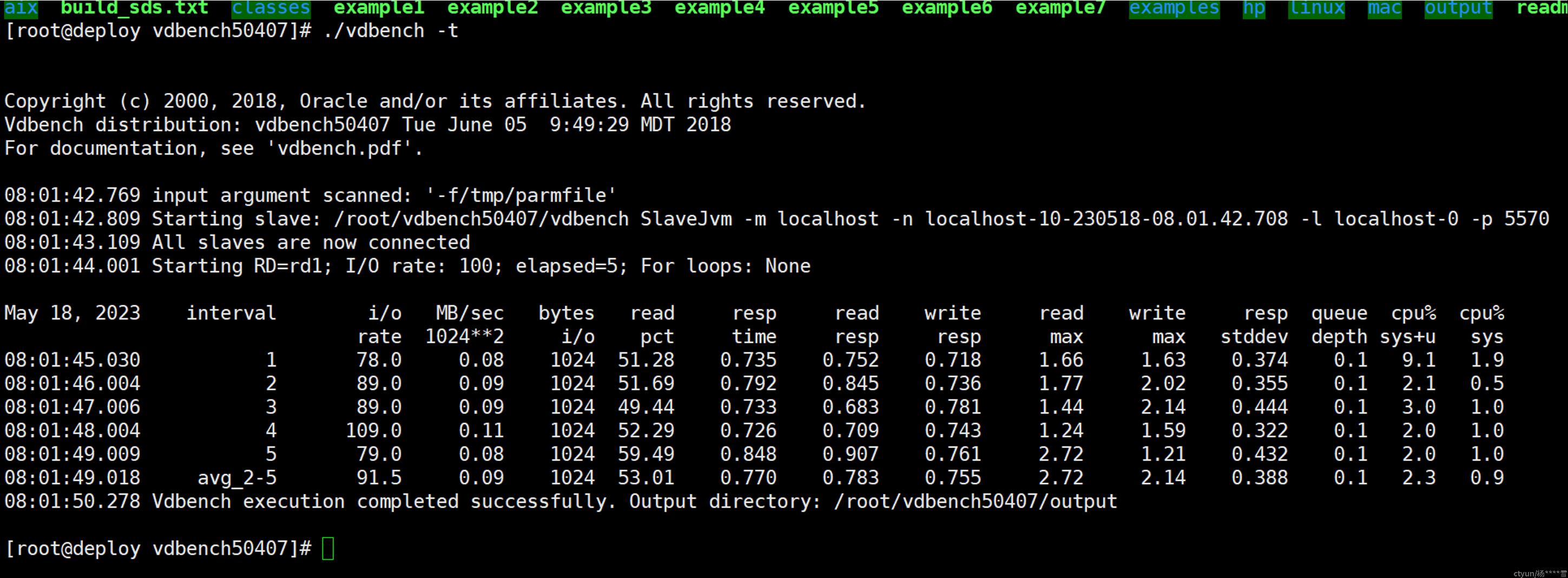
d. 在工作目录中创建一个新的文本文件,作为vdbench的配置文件,通常称为"workload"文件。使用任何文本编辑器都可打开该文件。运行方式:
./vdbench -f {filename} -o {exportpath}
#注:-f后接测试参数文件/名脚本名,-o后接导出测试结果路径
- vdbench测试文件系统性能的配置文件参数说明
- 与文件系统相关的参数定义
|
参数 |
描述 |
|
hd(hostname) |
主机定义 |
|
fsd(file system define) |
文件系统定义 |
|
fwd(file system workload define) |
文件系统工作负载定义 |
|
rd(run define) |
运行定义 |
- 概览
messagescan=no
hd=default,vdbench=/root/vdbench50407,user=root,shell=vdbench
hd=hd1,system=192.168.177.101
hd=hd2,system=192.168.177.102
fsd=default,openflags=o_direct,depth=2,width=100,files=6600,size=4K
fsd=fsd1,anchor=/mnt/test_host1
fsd=fsd2,anchor=/mnt/test_host2
fwd=format,xfersize=1M,operation=write,fileio=random,fileselect=random,threads=64
fwd=fwd11,fsd=fsd1,host=hd1,operation=write,fileio=random,fileselect=random,xfersize=4K,threads=64
fwd=fwd12,fsd=fsd2,host=hd2,operation=write,fileio=random,fileselect=random,xfersize=4K,threads=64
fwd=fwd21,fsd=fsd1,host=hd1,operation=read,fileio=random,fileselect=random,xfersize=4K,threads=64
fwd=fwd22,fsd=fsd2,host=hd2,operation=read,fileio=random,fileselect=random,xfersize=4K,threads=64
fwd=fwd31,fsd=fsd1,host=hd1,rdpct=70,fileio=random,fileselect=random,xfersize=4K,threads=64
fwd=fwd32,fsd=fsd2,host=hd2,rdpct=70,fileio=random,fileselect=random,xfersize=4K,threads=64
rd=rd1,fwd=fwd1*,fwdrate=max,format=yes,warmup=20,elapsed=400,interval=1
rd=rd2,fwd=fwd2*,fwdrate=max,format=restart,warmup=20,elapsed=400,interval=1
rd=rd3,fwd=fwd3*,fwdrate=max,format=restart,warmup=20,elapsed=400,interval=1
- 详解
messagescan=no
添加messagescan=no 可以过滤掉多余的系统日志。
hd=default,vdbench=/root/vdbench50407,user=root,shell=vdbench
hd=hd1,system=192.168.177.101
hd=hd2,system=192.168.177.102
hd=标识主机的名称,多主机运行时,可以使用hd1,hd2,hd3…区分;
vdbench=vdbench执行文件存放路径,当多主机存放路径不同时,可以在hd定义时单独指定;
user = 通信使用用户;
shell=可选值为rsh, ssh,和vdbench,默认值为rsh。
fsd=default,openflags=o_direct,depth=2,width=100,files=6600,size=4K
fsd=fsd1,anchor=/mnt/test_host1
fsd=fsd2,anchor=/mnt/test_host2
fsd=表示文件系统定义的名称,多文件系统时(fsd1,fsd2,fsd3…),可以指定default(将相同的参数作为所有fsd的默认值)
openflags=o_direct 以无缓冲缓存的方式进行读写操作(不配置这个的话,要走本地的缓存,跑出来的io不真实)
与文件系统结构相关的参数:
depth= 创建目录层级数(即目录深度)
width= 每层文件夹的子文件夹数,一般会根据文件系统的大小调整这个数
files= 测试文件个数(vdbench测试过程中会生成多层级目录结构,实际只有最后一层目录会生成测试文件),一般不超过100000。
size= 单个文件大小
测试文件个数=(width^depth)*files 例子文件数据大小:100^2*6600*4K≈251GB
注:通过depth,width,files,size这四个参数算出来的数据大小,一般要超过客户端的内存
anchor = 文件写入根目录
fwd=format,xfersize=1M,operation=write,fileio=random,fileselect=random,threads=64
#创建写,fwd用format参数(默认128K的块,线程为8去写)(从无到有去分配数据块)
#业务定义
#覆盖写,随机读、混合读写
fwd=fwd11,fsd=fsd1,host=hd1,operation=write,fileio=random,fileselect=random,xfersize=4K,threads=64
fwd=fwd12,fsd=fsd2,host=hd2,operation=write,fileio=random,fileselect=random,xfersize=4K,threads=64
fwd=fwd21,fsd=fsd1,host=hd1,operation=read,fileio=random,fileselect=random,xfersize=4K,threads=64
fwd=fwd22,fsd=fsd2,host=hd2,operation=read,fileio=random,fileselect=random,xfersize=4K,threads=64
fwd=fwd31,fsd=fsd1,host=hd1,rdpct=70,fileio=random,fileselect=random,xfersize=4K,threads=64
fwd=fwd32,fsd=fsd2,host=hd2,rdpct=70,fileio=random,fileselect=random,xfersize=4K,threads=64
fwd=标识文件系统工作负载定义的名称,多文件系统工作负载定义时,可以使用fwd1、fwd2、fwd3区分;
fsd=标识此工作负载使用文件存储定义的名称;
host=标识此工作负载使用主机,联机测试时需要指定;
operation=read或write,文件操作方式;
rdpct=0~100,读写占比百分比,一般混合读写时需要指定,当值为70时,则混合读写比为7:3;
fileio=可选值为random或sequential,标识文件I/O将执行的方式;一般大块的为sequential,小块的为random。小块一般要看iops以及时延,random要快一些。大块的看带宽,sequential就可以;
fileselect=random或sequential,标识选择文件或目录的方式;
xfersize=数据传输(读取和写入操作)处理的数据大小(即单次IO大小或者块大小)。
threads=此工作负载的并发线程数量。
#运行定义
#第一个rd的format要设置为yes,因为不清楚拿到的文件系统是否是空的)
rd=rd1,fwd=fwd1*,fwdrate=max,format=yes,warmup=20,elapsed=400,interval=1
rd=rd2,fwd=fwd2*,fwdrate=max,format=restart,warmup=20,elapsed=400,interval=1
rd=rd3,fwd=fwd3*,fwdrate=max,format=restart,warmup=20,elapsed=400,interval=1
rd=标识文件系统运行定义的名称
fwd=标识文件系统工作负载定义的名称
fwdrate=每秒执行的文件系统操作数量。设置为max,表示不做任何限制,按照最大限度自适应.
format=可选值为yes,no或restart,表示预处理目录和文件结构的方式
--yes表示删除目录和文件结构再重新创建
--no表示不删除目录和文件结构
--restart表示只创建未生成的目录或文件,并且增大未达到实际大小的文件
如果测试的时候定义的文件数是1000,后面改为了2000,如果使用了format=restart就会创建1001-2000 如果设置format=yes会删除1000个文件后再重新创建2000个文件,使用format=no就不会重新创建1000个,但会创建1001-2000但不会检查前1000个文件的大小
warmup=预热时间,最终会被忽略
elapsed=默认值为30,测试运行持续时间(单位为秒)
interval=结果输出打印时间间隔(单位为秒)
- 文件目录结构参考
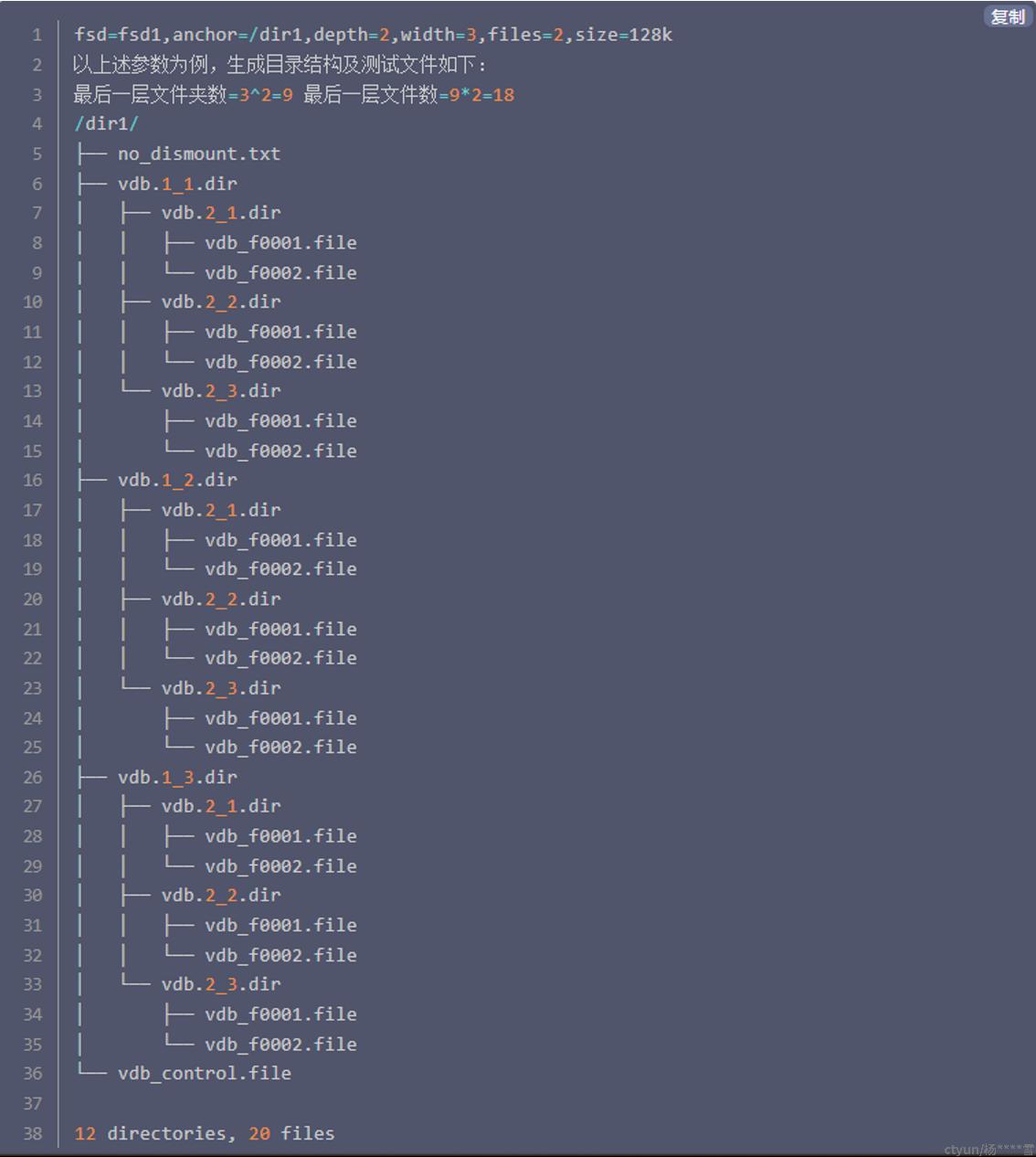
图来源:https://cloud.tencent.com/developer/article/2088802
- 结果分析
当测试完成后,你可以在工作目录中找到生成的结果文件,其中包含详细的性能数据和统计信息。结果目录下的主要文件有
- histogram.html
一种包含报告柱状图的响应时间、文本格式的文件
- logfile.html
包含 Java 代码写入控制台窗口的每行信息的副本。logfile.html 主要用于调试用途
- parmfile.html
包含测试运行配置参数信息
- summary.html
记录全部数据信息,显示每个报告间隔内总体性能情况及工作负载情况,以及除第一个间隔外的所有间隔的加权平均值
- totals.html
记录全部数据计算之后的平均值,一般测试结果从该文件取值,除第一个间隔外所有间隔的加权平均值
- 注意事项
1. 联机测试时,客户端的系统时间需要保持一致,否则会出现时钟同步警告,联机跑时需要在联机的客户端执行./vdbench rsh
2. 联机测试时,客户端的防火墙需要关掉(或者设置执行开放程序指定端口为5570和5560)
参考链接:https://blog.csdn.net/Micha_Lu/article/details/109227774?spm=1001.2101.3001.6650.8&utm_medium=distribute.pc_relevant.none-task-blog-2%7Edefault%7EBlogCommendFromBaidu%7ERate-8-109227774-blog-51553230.pc_relevant_3mothn_strategy_recovery&depth_1-utm_source=distribute.pc_relevant.none-task-blog-2%7Edefault%7EBlogCommendFromBaidu%7ERate-8-109227774-blog-51553230.pc_relevant_3mothn_strategy_recovery&utm_relevant_index=13
