


CLIP模型:就是给定一对“文本图像对”,文本内容通过文本编码器得到一个文本特征;图像通过图像编码器得到图像特征,这两个就应该是一个正样本,这个文本跟其他的图像就是负样本,通过这种方式去做对比学习,从而把文本和图像编码器都学的很好,而且这个文本和图像的特征就联系在一起了,是一个合并的多模态的特征空间。一旦这个CLIP模型训练好了之后,文本和图像编码器就锁住了。在dall-e2这篇论文里面,是不会进行任何训练和fine-tune。
梳理了一下大厂这两年在图像生成领域的工作,从OpenAI2021年发表的DALL-E之后陆续有很多论文发表,可以参考着看看。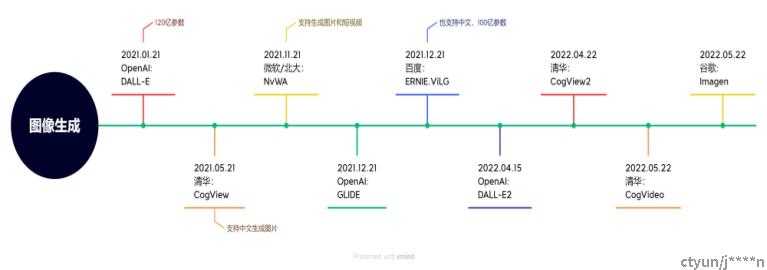
UNCLIP模型结构
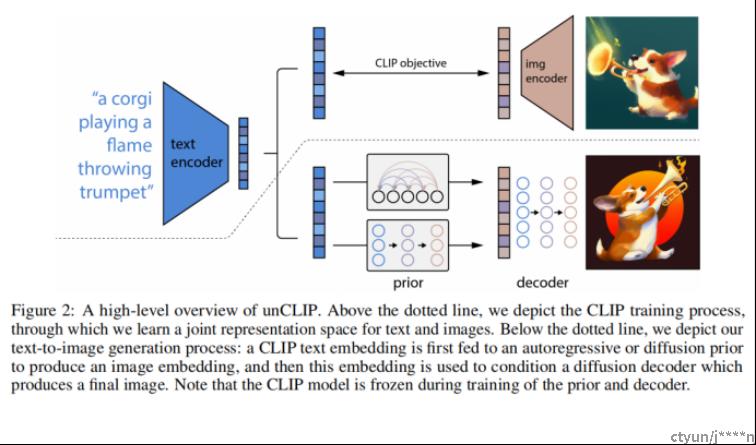
图片的上面部分其实就是CLIP模型,下面才是两阶段模型。
其中Prior阶段:由文本编码器得到的文本特征经过prior模型得到一个显式的图像特征,在训练的时候是有这个图像文本对的,就可以利用CLIP模型将图像得到图像特征,把这个图像特征当这个GT来监督。通过这种方式就把prior模型训练出来了,这样等到推理的时候就可以生成图像特征了。并对先验网络使用自回归模型和扩散模型进行实验,发现后者在计算上更高效,并产生更高质量的样本。
Decoder阶段:拿到图像特征之后使用扩散模型decoder得到图像。使用扩散模型并利用classifier-free guidance和CLIP guidance在给定CLIP图像编码的情况下生成图像。为了生成高分辨率图像,训练了两个扩散上采样模型,分别用于将图像从64*64上采样到256*256、进一步上采样到1024*1024。
模型效果
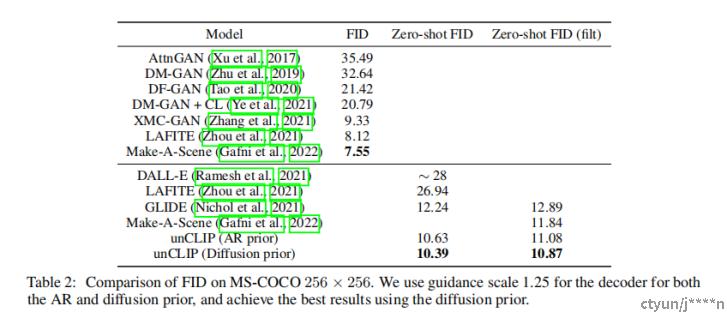
图像对比

