


《SegFormer: Simple and Efficient Design for Semantic Segmentation with Transformers》
本文是将Transformer模型应用于语义分割任务的一个新的尝试,主要创新点如下:
● 使用分级的Transformer block设计,可以产生多种尺度的特征。
● 使用重叠的patch融合策略,解决了各patch特征不连续问题。
● 轻量级全MLP解码器设计,无需复杂和计算要求高的模块即可产生强大的表示。
● 在三个公开可用的语义分割数据集的效率、准确性和鲁棒性方面创下了最新水平。
模型结构
SegFormer主要由Encoder和Decoder组成。
Encoder: 一个多层的Transformer编码器。由四层的Transformer block组成。产生从高分辨率到低分辨率的不同特征。
Decoder: 接收多尺度的编码特征,结构为一个结构简单的解码器,仅由上采样和多层感知机组成。
分级Transformer编码器
作者设计了一系列的Mix Transformer编码器(MiT),MiT-B0到MiT-B5,具有相同的结构,但尺寸不同。MiT-B0是用于快速推理的轻量级模型,而MiT-B5是用于最佳性能的最大模型。作者设计的MiT部分灵感来自ViT。
Overlapped Patch Merging. 给定一个图像块(image patch),ViT里用到的patch merging流程是将一个H * W * 3的图像块resize为一个1*1*C的向量。ViT最初是设计固定的下采样倍数,以及每个patch之间没有重叠信息。因此,它无法保持这些块周围的局部连续性。
作者使用重叠的块合并过程。为此,作者定义了K、S和P,其中K是卷积核大小,S是两个相邻块之间的步幅,P是填充大小。在实验中,设置K=7,S=4,P=3,以及K=3,S=2,P=1来进行重叠的块合并,分别可以实现相对上一层特征的4倍和2倍的下采样。
高效的自注意力。 编码器的主要计算瓶颈是自注意力层。在原来的多头自注意过程中,每个头的Q,K,V都有相同的维数N*C、 其中N=H*W是序列的长度,自注意力的计算为:
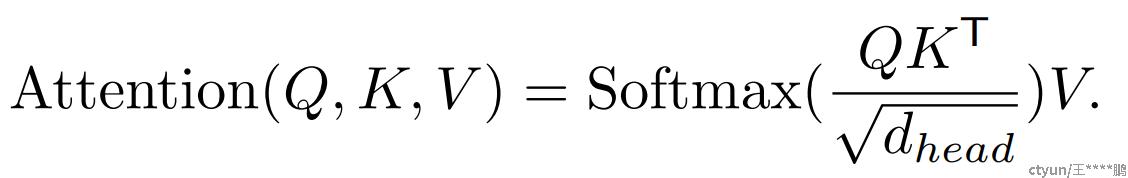
作者使用PVT(Pyramid vision transformer )中介绍的序列缩减过程。此过程使用缩减比R来缩短序列长度,如下所示:
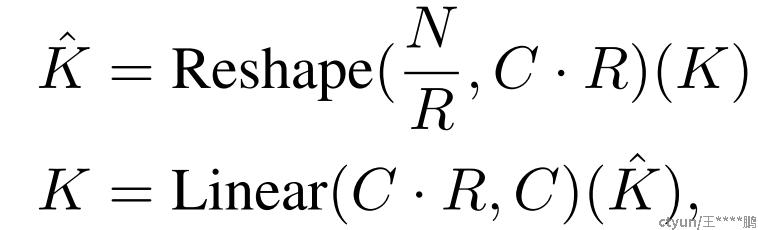
MixFFN ViT使用位置编码(PE)来引入位置信息。然而,PE的分辨率是固定的。因此,当测试分辨率与训练分辨率不同时,需要对位置编码进行插值,这常常导致精度下降。为了缓解这个问题,作者认为,对于语义分割,位置编码实际上是没有必要的。相反,作者引入了Mix-FFN,在前馈网络(FFN)中直接使用3×3卷积。MixFFN可写为:
![]()
其中Xin是自注意力输出的特征。MixFFN将一个3×3卷积和MLP混入到每个FFN中。在作者的实验中,作者将证明3×3卷积足以为Transformers提供位置信息。具体地,作者使用深度卷积以减少参数量和提高计算效率。
轻量级All-MLP解码器
SegFormer集成了一个仅由MLP层组成的轻量级解码器,这避免了其他方法中通常用的手工制作和计算要求很高的组件。实现这种简单解码器的关键是作者的分层Transformer编码器比传统的CNN编码器具有更大的有效感受野(ERF)。
作者提出的全MLP解码器由四个主要步骤组成。
1) 来自MiT编码器的多级特征Fi会通过MLP层来统一通道维度。
2) 特征上采样到原图像的1/4尺寸并拼接在一起。
3) 采用MLP层融合拼接后的特征F。
4) 最后用一个MLP层进行类别预测,输公式为:
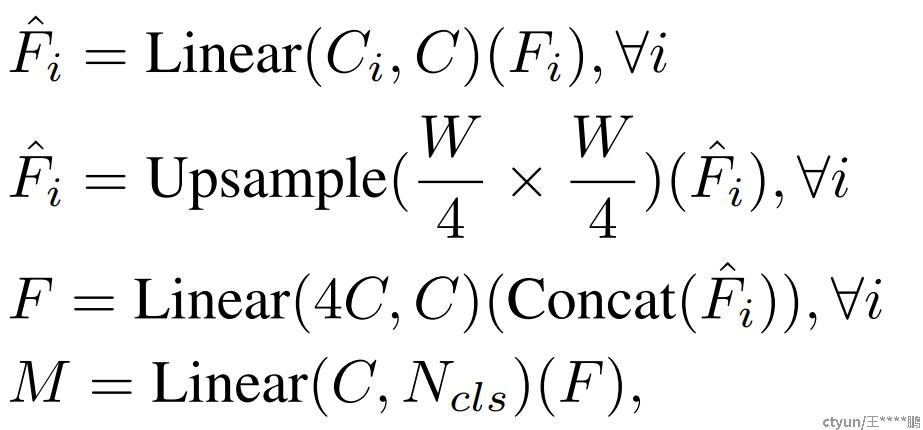
其中M表示预测的掩码。
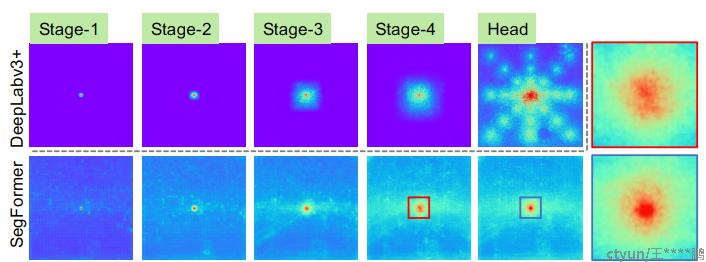
下图是与DeepLabV3+进行的有效感受野对比,SegFormer可以产生更大的有效感受野。
与SETR的关系。
与SETR(基于ViT的架构)相比,SegFormer包含了多种更高效、更强大的设计:
• 只使用ImageNet-1K进行预训练。SETR中的ViT在较大的ImageNet-22K上预训练。
• SegFormer的编码器具有分层结构,比ViT更小,可以捕获高分辨率粗特征和低分辨率精特征。相比之下,SETR的ViT编码器只能生成单一的低分辨率特征图。
• 本文去除了位置编码,而SETR使用固定尺寸的位置编码,当推理的分辨率与训练的分辨率不同时,会降低精度。
• 本文的MLP解码器比SETR中的更紧凑,计算要求更低。这导致了可以忽略不计的计算开销。相反,SETR需要多个3×3卷积的计算量大的解码器。
