


人群密度估计的任务是估计出图像中的人头个数,主要分为三种方法:
- detection-based: 基于检测的,检测人头或者身体,例如YOLO。在稀疏场景检测精度高,但在极其密集的人群中遇到遮挡和背景杂乱的情况时效果不好。
- regression-based:提取local patch-level features,学习回归函数,直接估计输入图像patch的总数。解决了密集的人群遮挡和背景杂乱的问题,但忽略了空间信息。
- density map based:考虑了空间信息,有一些仅使用传统的手工特征提取底层信息的方法,这种无法指导高质量的密度图估计更准确的计数。目前主流做法是CNN-based的,提高模型对人群变化的鲁棒性。
人群密度估计的任务难点:
- dynamic backgrounds/background clutter/severe occlusion:regression可以解决
- size of the instances/variations of people、head sizes/scale variation:人头有大有小,也是目前多数方法解决的问题
- cross scene:在多个场景训练,在没有训练过的场景测试。
- multi-domain
- perspective distortion
- insuffificient resolution等
人头大小之分在深度学习中采用multi-scale多尺寸方法解决,scale的角度也有多种,可以分为
- 不同的卷积核大小
- 不同的图像尺寸
- 不同的空洞卷积
- 不同的方法结合
- 不同的attention
- 不同的desity-level class
- 不同深浅的网络
不同的卷积核大小
-
MCMMSingle-image crowd counting via multi-column convolutional neural network,” in CVPR, 2016
作者证明了在拥挤计数中,头的大小与k个相邻的人的中心之间的距离有关。因此,最近k个邻居之间的平均距离可以合理地估计当前头的大小(他们称这种方法为几何自适应核)。这样就解决了对透视图的依赖,但是这种方法只适用于头部较大的密集场景。对于稀疏场景或图像中较小的头部尺寸,内核大小将变得太大或太小。
三个分支太相似,而且很浅,整个结果看来只是几个弱回归变量的组合,效果不是很好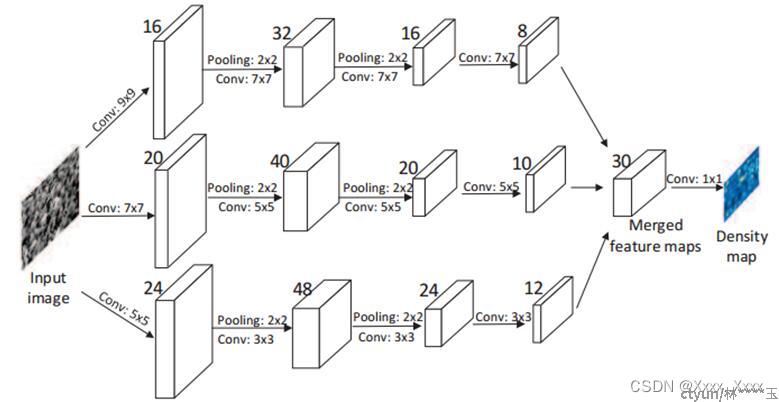
-
McML(Multi-column Mutual Learning (McML) strategy)Improving the learning of multi-column convolutional neural network for crowd counting,” ACMMM, 2019. 5为解决Multi-column由于列中存在大量冗余参数,在不同列中呈现出几乎相同的尺度特征,严重影响计数精度,导致过拟合问题,通过引入statistical network 最小化分支之间的互信息,引导每一列学习不同图像尺度的特征
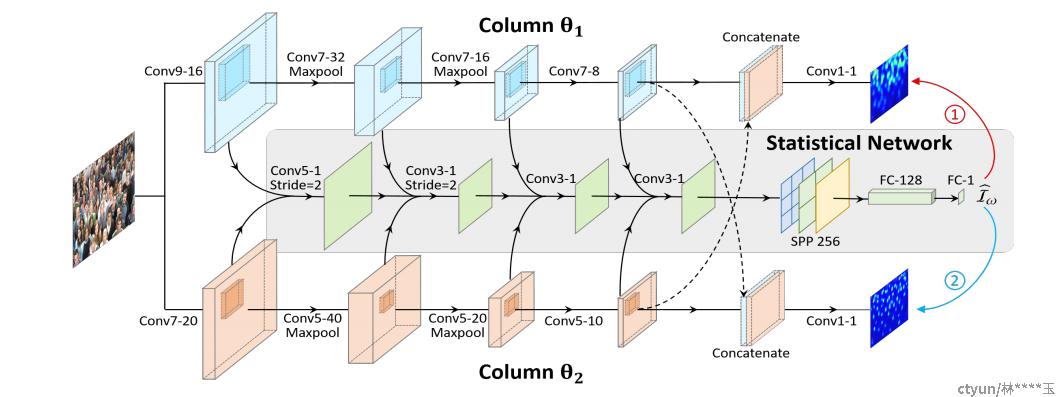
不同的图像尺寸
- Hydra-CNN
Towards perspective-free object counting with deep learning,” in ECCV. Springer, 2016,给定一张测试图片,我们先从图片中密集地提取出image patches来将这些image patches scale到固定的尺寸,即72 x 72,然后输入到CCNN中去,CCNN会为每一个image patch生成对应的密度图,再把这些图像块密度图组合为完整图像的密度估计图
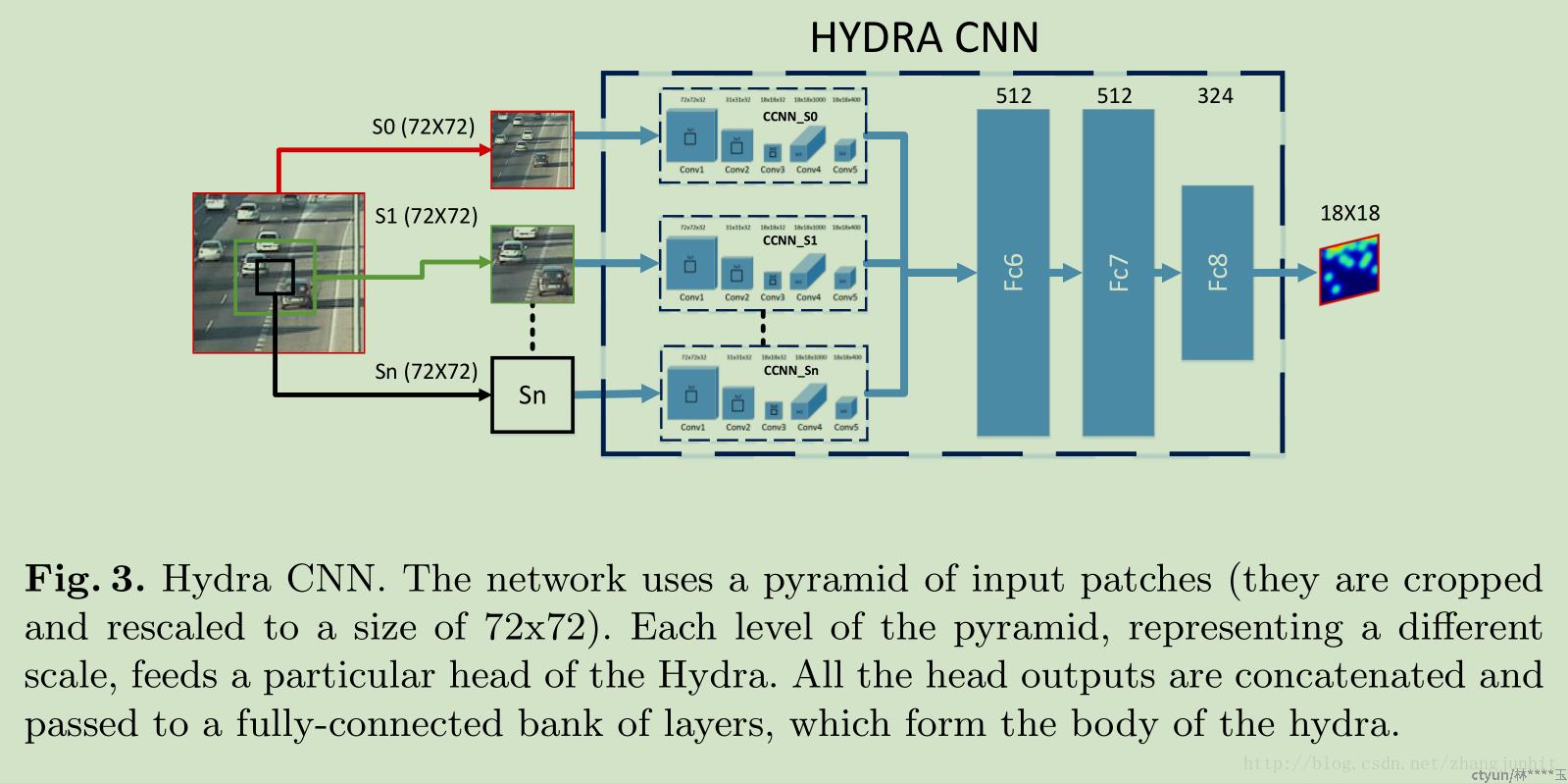
不同网络的深浅
- Crowdnet
deep netweork,该部分卷积核小,捕获高级语义信息,
shallow network,卷积核大,检测距离相机视角远的人
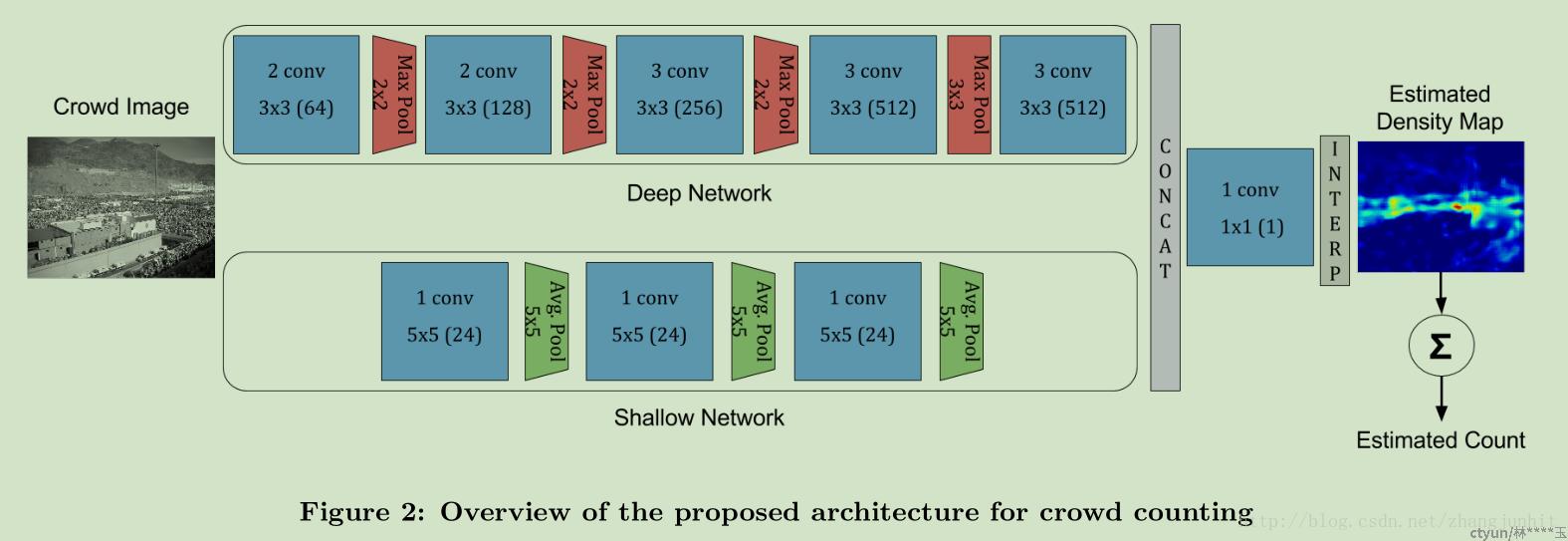
不同desity-level class
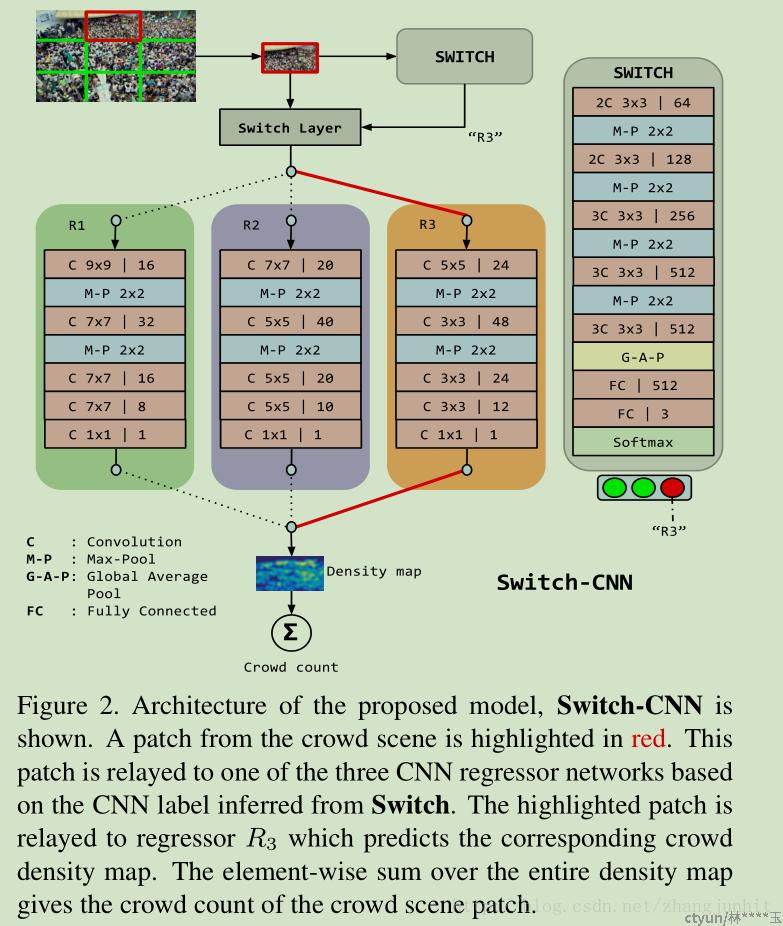
- Switch-CNN
Switching convolutional neural network for crowd counting,” in CVPR. IEEE, 2017
和MCMM相比,Switch-CNN不是将所有分支的特征映射连接起来,而是学习一个分类器,该分类器预测输入图像的离散密度类(高,中,低),然后使用该预测的比例选择一个分支,并使用该分支的特征进行密度估计。
不同attention(global,local)
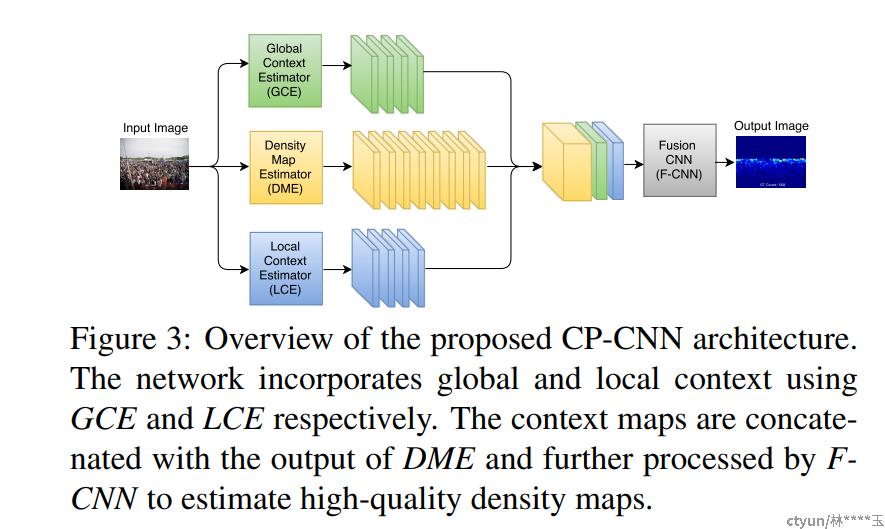
- CP-CNN
Generating high-quality crowd density maps using contextual pyramid cnns, in ICCV, 2017,
提取了global and local contextual information,融合来自不同层次的特征使用对抗性学习。
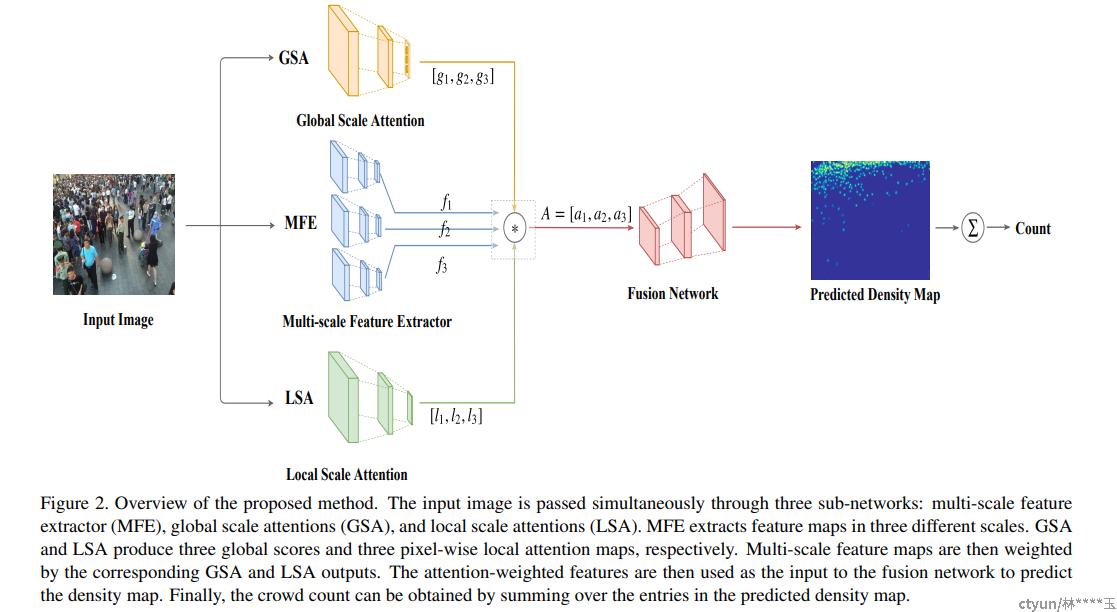
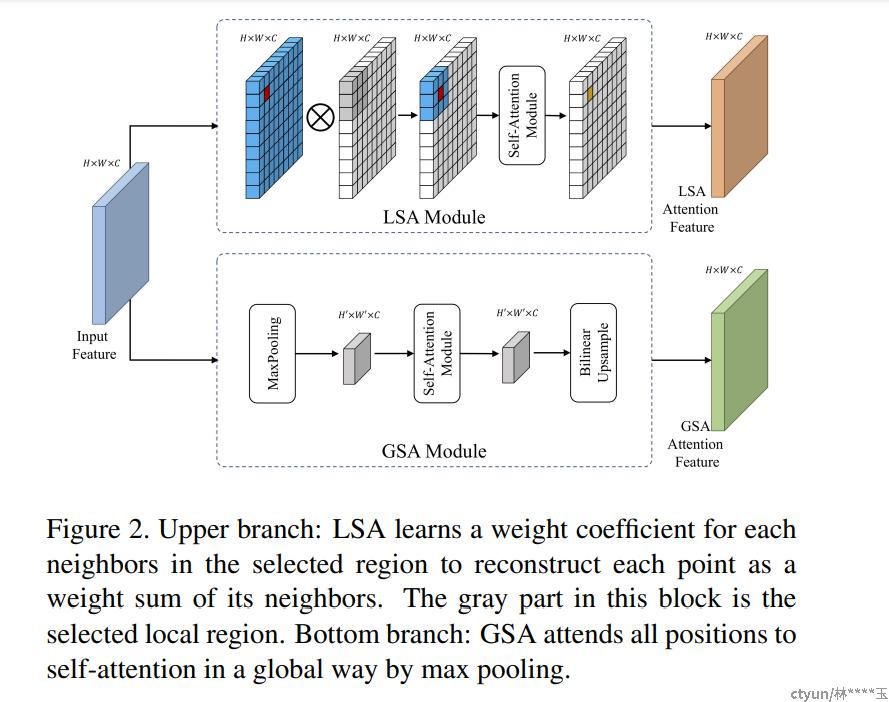
- SAAN
Crowd counting using scale-aware attention networks
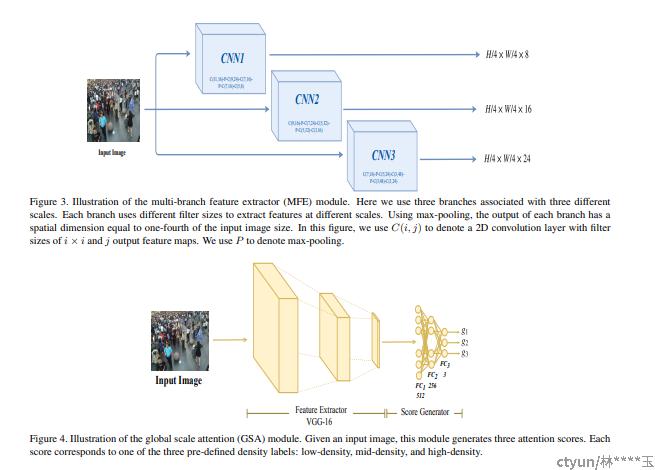
global scale attention (GSA): 将图像密度分为三类: low-density, mid-density, and high-density. 是一个scalar
local scale attention (LSA) : 捕获图像中不同位置的局部尺度信息,生成 pixel-wise attention maps

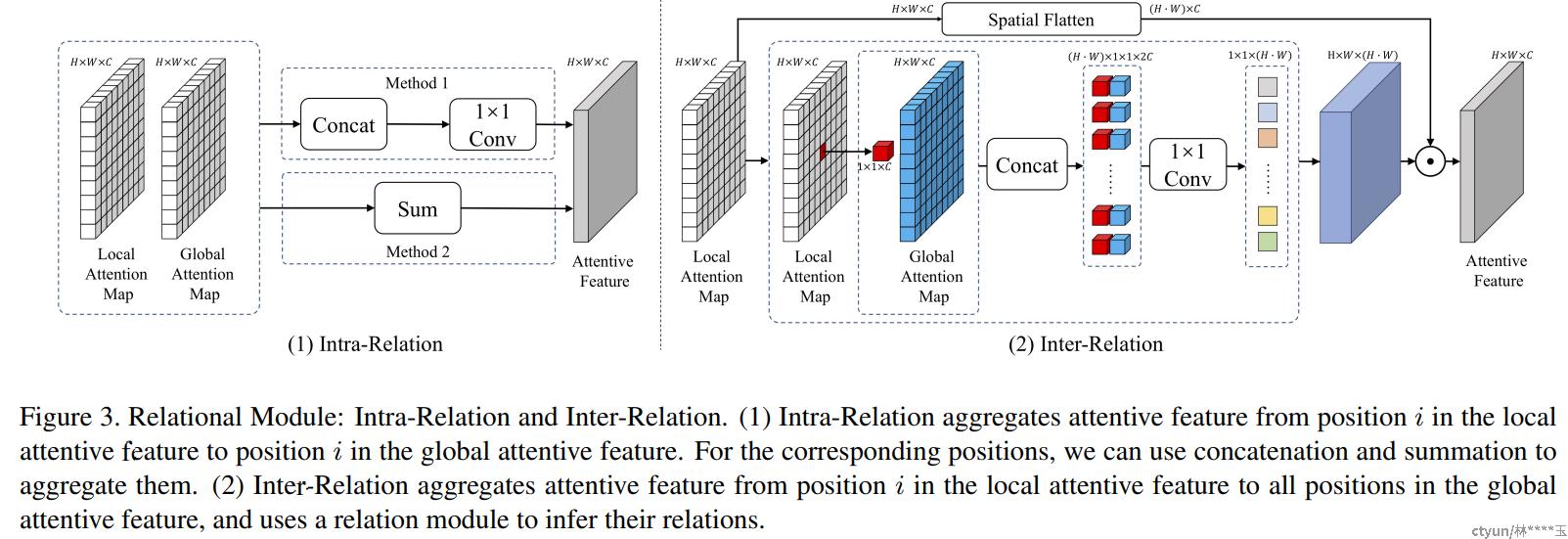
- RANet
“Relational attention network for crowd counting,” in ICCV, 2019
和SAAN类似,也是local self-attention (LSA) and global self-attention (GSA) ,再fusion, fusion之前经过两个 relation module(intra-relation\inter-relation).
主体网络用的是 Stacked hourglass networks,文中提出的东西加在decoder of each hourglass module。据说Stacked Hourglass Networks网络结构能够捕获并整合图像所有尺度的信息
intra-relation : position i in LSA and position i in GSA
inter-relation : position i in LSA and position j in GSA
不同的方法
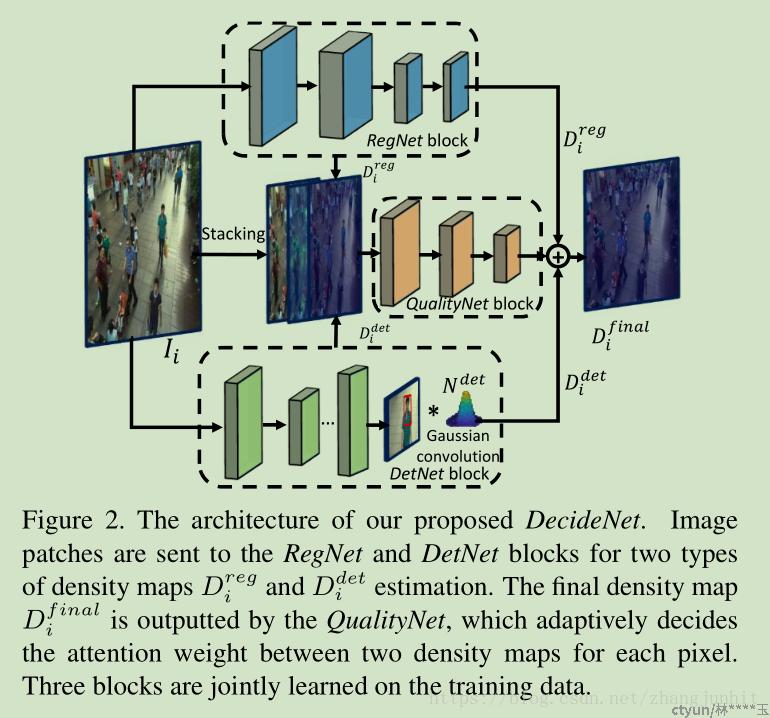
- DecideNet
《DecideNet: Counting Varying Density Crowds Through Attention Guided Detection and Density》
.基于检测的计数方法将在低密度场景中准确估计人群,同时降低其在拥挤区域的可靠性。 另一方面,基于回归的方法捕获拥挤区域中的一般密度信息。在不知道每个人的位置的情况下,它倾向于高估低密度区域中的计数。思路就是将 检测方法和回归方法结合起来,各取所长。
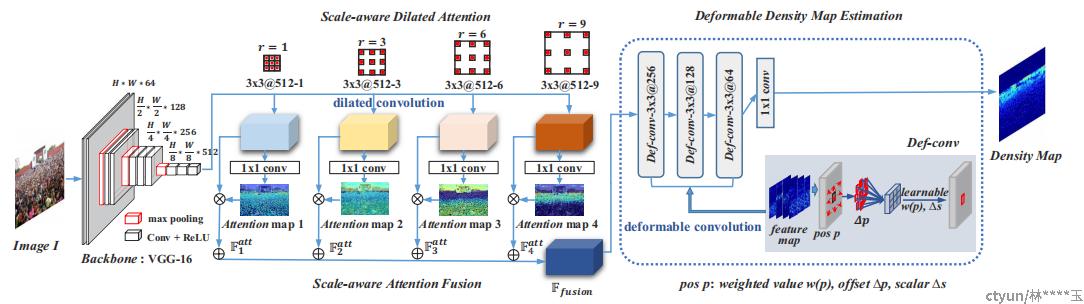
不同空洞卷积
Dadnet: Dilated-attention deformable convnet for crowd counting,” in ACMMM. ACM, 2019,
不同的空洞卷积感受野不同,融合多个感受野,这里还用到了形变卷积 deformable convolution,比普通卷积具有更高的形变能力
multi-columns 缺点:
- 多个分支难免网络结构庞大
- 使用不同的分支,但网络结构几乎相同,不可避免地会导致大量的信息冗余
- 在将图像发送到网络之前使用密度级分类器density level classififiers 。然而,由于现实世界的拥挤场景中人群的数量变化很大,使得密度级别的粒度很难定义。更细粒度的分类器也意味着需要设计更多的列和更复杂的结构, density level classififiers 需要大量参数,密度图的生成参数反而更少
