


可视化 Rust 各数据类型的内存布局
// file: main.rs
fn main() {
println!("Hello World!");
}当我们使用 Rust 中编写程序时,由于 Rust 的 生命周期和所有权模型,你最好为程序可能用到的数据结构做一些前期设计,不然 Rust 编译器可能让你十分痛苦。了解每个数据类型的内存布局有助于锻炼你的直觉,可以提前规避一些编译错误和性能问题。
在这个文章里,我们会讨论
- 在计算机运行二进制文件时发生了什么?
- 常见数据类型的内存布局 (包括:整形,元组,切片,向量,字符串,结构体,枚举,智能指针,特征对象,还有各种
Fn特征)
二进制数据段
当你编写一个 Rust 程序时,要么直接调用 rustc,要不就是通过 cargo 去生成一个可执行文件。
$ rustc main.rs
$ cargo build这个二进制文件以一种特定的格式存储数据。对于 linux 系统,最常见的格式是 elf64 。不同的操作系统比如 linux, mac, windows 使用不同的格式。虽然二进制文件的格式不尽相同,但是它在各种的操作系统中的运行方式几乎相同。
常见的二进制文件一般由 文件头 + 分区 组成。 对于 elf 格式的二进制文件,它的结构大致如下图所示:
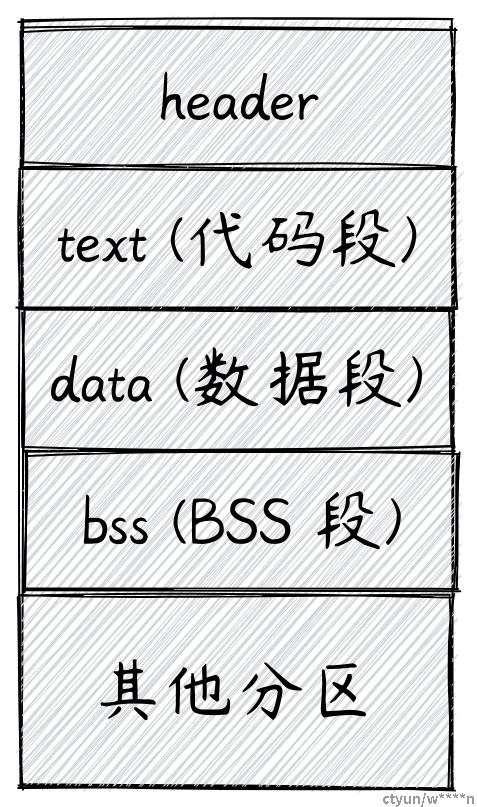
> 段的数量根据编译器而不同。这里只展示了一些重要的一些段。
当你运行二进制文件时
以 elf64 格式的二进制文件为例,在程序运行时,内核会为程序分配一段连续的内存地址,并将这些分区映射到内存中去。

注意:这里的内存地址并不是内存条里实际的内存地址。但是当程序开始使用内存时,内核和硬件会把它们映射到真正的物理内存地址。这被称为 虚拟地址空间。一个正在运行的程序被称为一个进程。从进程的角度来看,它只能看到一段连续的内存,从 0 到地址高位的最大值。
下面我们会介绍进程地址空间中各个区域的作用:
-
代码段 (text)
代码段包含了可执行指令的集合。
编译器能把我们用高级语言写的程序转换为 CPU 可以执行的机器指令,代码段就包含了这些指令。这些指令根据 CPU 架构而有所不同。编译给 x86-64 架构 CPU 运行的二进制文件不能在 ARM 架构的 CPU 上运行。
代码段是 只读 的,运行的程序不能更改它。
-
数据段 (data)
数据段包含 已经初始化 过的数据。比如全局变量,全局静态变量,局部静态变量。
-
BSS 段 (bss)
bss 代表
Block started by symbol, 这里保存着 未被初始化 过的全局变量。由于 bss 段的变量未被初始化,这一段并不会直接占据二进制文件的体积,它只负责记录数据所需空间的大小 -
地址高位
内核会把一些额外的数据,比如环境变量,传递给程序的参数和参数的数量映射到地址高位。
堆 & 栈
堆栈简介
当程序运行时(运行态),还需要需要另外两个域:堆和栈
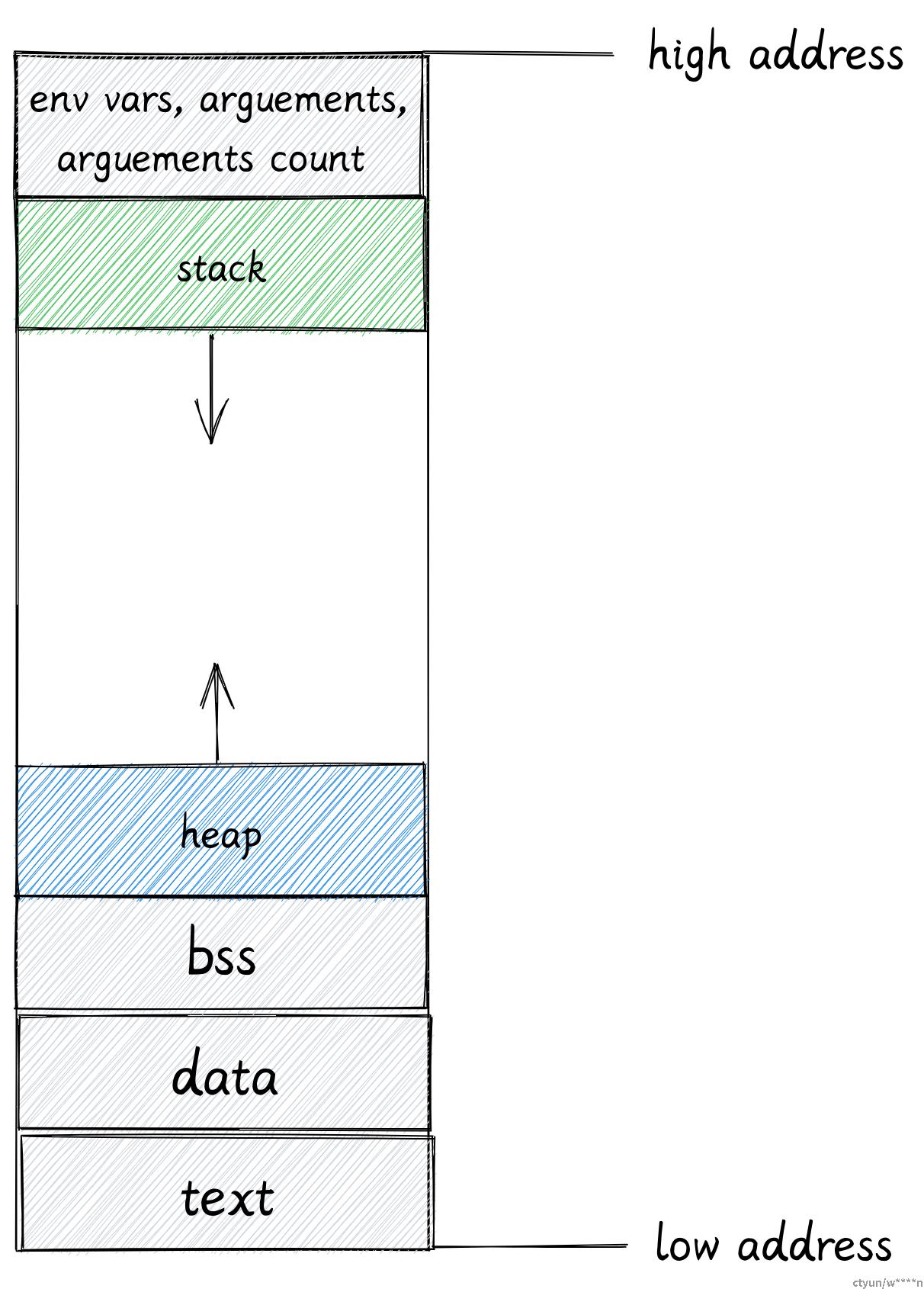
栈:
-
操作系统使用栈存储一个进程的抽象细节,包括 (进程名字,进程 ID 等)。
-
一个进程至少有一个执行线程,每一个线程都有自己的栈内存。
-
在 64 位的 linux 系统上,Rust 程序为主线程分配 8MB 的栈内存。对于用户创建的其他线程,rust 标准库支持自定义大小,默认的大小是 2MB。
-
栈内存的空间会从地址高位向低位增长,但是不会超过线程可以拥有的最大值。对于主线程来说就是 8MB。如果它使用的栈内存超过了 8MB,程序就会被内核终止,并返回一个
stackoverflow错误。 -
栈内存被用于执行函数 (见下方对栈的具体讲解)。
> 虽然主线程的栈内存大小有 8MB,但是这 8MB 也不会被立即分配,只有当程序开始使用时,内核才会开始为它分配内存。
堆:
- 所有线程共享一块堆内存
- 堆内存从地址低位向高位增长。
操作系统通常会提供一些接口让我们检查程序运行时的内存映射状态,对于 linux 系统,你可以在 /proc/PID/maps 文件中查看
下面展示了一个进程的映射状态(部分):
$ cat /proc/844154/maps
55e6c3f44000-55e6c412c000 r-xp 00000000 103:03 22331679 /usr/bin/fish
55e6c412c000-55e6c4133000 r--p 001e7000 103:03 22331679 /usr/bin/fish
55e6c4133000-55e6c4134000 rw-p 001ee000 103:03 22331679 /usr/bin/fish
55e6c4134000-55e6c4135000 rw-p 00000000 00:00 0
55e6c4faa000-55e6c5103000 rw-p 00000000 00:00 0 [heap]
7fd62326d000-7fd62326f000 r--p 00034000 103:03 22285665 /usr/lib/ld-linux-x86-64.so.2
7fd62326f000-7fd623271000 rw-p 00036000 103:03 22285665 /usr/lib/ld-linux-x86-64.so.2
7ffecf8c5000-7ffecf8f5000 rw-p 00000000 00:00 0 [stack]你可能会想问:堆内存和栈内存是否会相互覆盖?因为他们两个向对方的方向增长。
通过用 stack 的低位减去 heap 的高位
>>> (0x7ffecf8c5000 - 0x55e6c5103000) / (10 ** 12)
46.282743488512差距为 47TB,所以栈堆冲突的情况几乎不可能出现
如果确实发生了,内核会提供守卫去终止程序。注意,这里的内存是指虚拟内存,并非电脑的真实内存大小。
CPU 字长
虚拟内存地址的范围由 CPU 字长 (word size) 决定,字长是指 CPU 一次可以并行处理的二进制位数,对于 64 位的 CPU 来说,它的字长为 64 位 (8 字节)。CPU 中大多数或者全部寄存器一般都是一样大。

因此可以得出:64 位 CPU 的寻址空间为 0 ~ 2^64-1。而对于 32 位的 CPU 来说,它的寻址空间只有从 0 到 2^32,大概 4GB。
目前,在 64 位 CPU 上,我们一般只使用前 48 位用于寻址,大小大概是 282TB 的内存
>>> 2**48 / (10**12)
281.474976710656这其中,只有前 47 位是分配给用户空间使用,这意味着大概有 141TB 的虚拟内存空间是为我们的程序分配的,剩下的位于地址高位的 141TB 是为保留给内核使用的。如果你去查看程序的虚拟内存映射,你能使用的最大内存地址应该是 0x7fffffffffff
>>> hex(2**47-1)
'0x7fffffffffff'栈内存
接下来让我们深入了解栈内存的用途
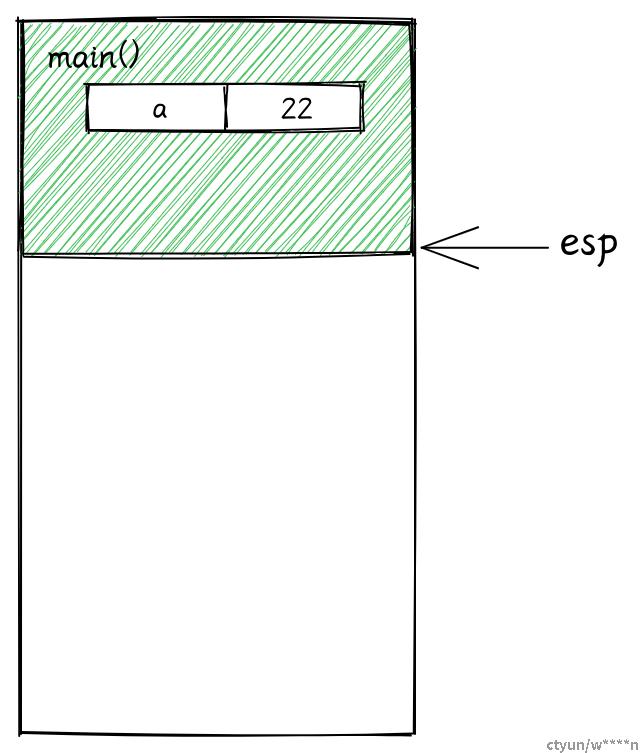
在这个例子中,整个程序只有一个主线程在运行,我们在 main 里调用了 add1 函数。
fn main() {
let a = 22;
let b = add_one(a);
}
fn add_one(i: i32) -> i32 {
i + 1
}栈主要用来保存正在调用的函数的数据 (包括函数参数,函数的局部变量,和它的返回地址)。为一个运行中的函数分配的总内存被称为一个 栈帧。
-
main函数是程序的入口,首先main函数的栈帧被创建。main函数内部有一个两个i32类型的局部变量a和b,大小都是 4 个字节,其中a的值为 22。main函数的栈帧会确保有足够的空间去保存这些局部变量。ESP 和 EBP 寄存器内分别保存着栈顶指针和栈底指针,用来追踪当前的栈的顶部和底部。
-
当
main函数调用add1时,一个新的栈帧被创建用来保存add1函数的数据。栈顶指针被修改为新栈的顶部。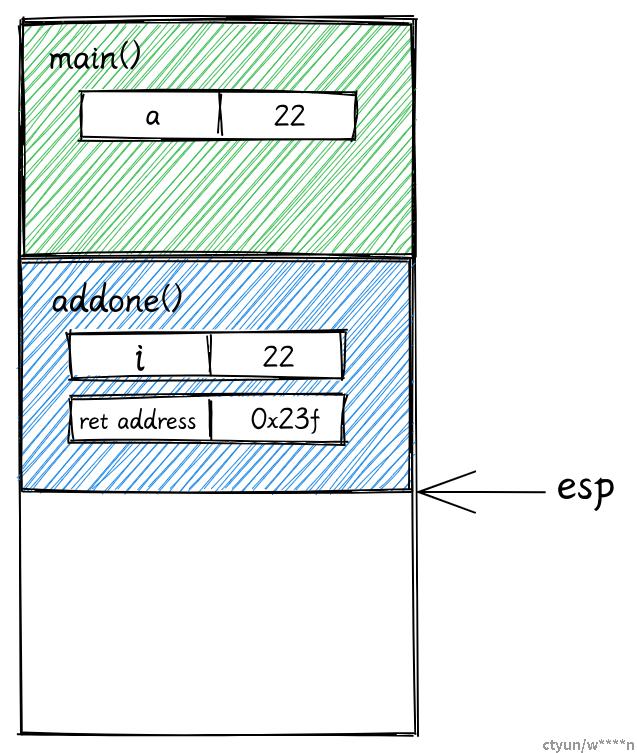
add1函数要接受一个i32类型的参数,因此 4 字节的空间会被保留在add1函数的栈帧上。add1函数并没有局部变量- 栈帧还会保存一个返回地址,当函数运行结束后,会根据该返回地址回到之前的指令。
-
函数调用结束
当函数调用结束后,就会把返回值 23 赋值给局部变量
b。同时栈顶指针也被修改。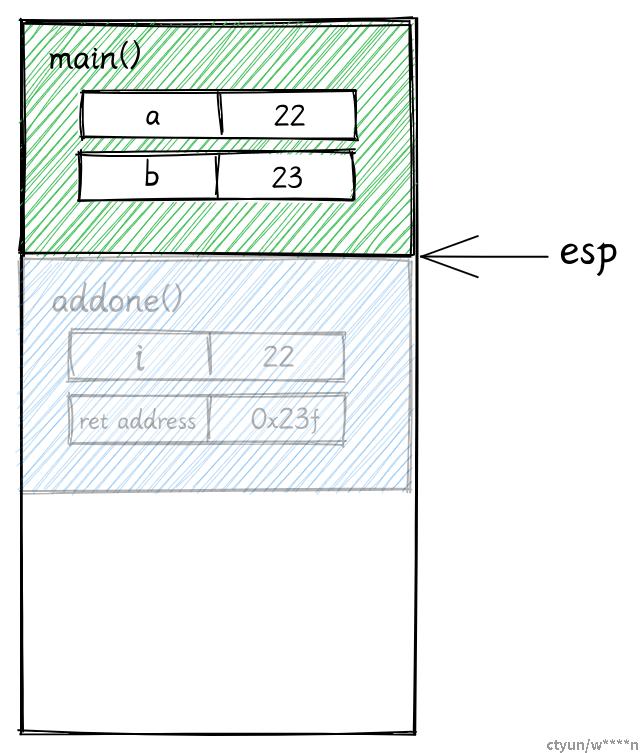
> 注意:函数运行结束后,add1 的栈帧并没有被释放。当你的程序开始调用下一个函数时,新的栈帧会直接将其覆盖。对于栈来说,开辟和释放内存只需要修改栈指针即可。
由此可见,因为在栈上开辟和释放内存只需要移动指针,不需要进行任何系统调用,它的效率是很高的。
当然栈也有一些限制:
- 只有在编译时已知大小的变量才能被存储在栈上。
- 函数不能返回一个位于函数内部的局部变量的引用
如果你把 add_one 改成下面的样子,就会编译失败:
fn add_one(i: i32) -> &'static i32 {
let result = i + 1;
&result
}error[E0515]: cannot return reference to local variable `result`
--> src/main.rs:8:5
|
8 | &result
| ^^^^^^^ returns a reference to data owned by the current function根据我们之前介绍过栈的工作原理,假设你现在返回了一个函数内局部变量的引用,但是当函数返回时,本质上函数的内存就被释放了。当下一个函数被调用时,它的栈帧就会重写这块内存空间。
在一个带有 GC 的语言里,编译器能够检测到这种覆盖,并在会为这个变量在堆上分配一块空间,并返回它的引用。但是在堆上分配会带来部分额外开销。因为 Rust 没有 GC,而且不会强制你去显式的分配堆内存,所以这里会编译失败。
堆内存
在这个例子里,我们在 main 函数中调用了 heap 函数。
fn main() {
let result = heap();
}
fn heap() -> Box<i32> {
let b = Box::new(23);
b
}首先会为两个函数再栈上创建栈帧。接着使用 box 将 23 分配在堆上。然后把 23 在堆上的地址赋值给了变量 b。box 只是一个指针,所以栈上有足够的空间去保存 box。
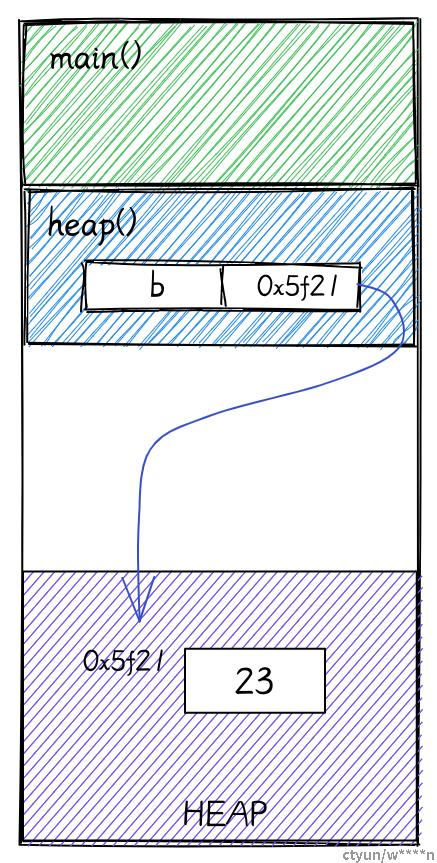
> 在 64 位系统上,指针的大小是 8 字节,所以在栈上的变量 b 的大小是 8 字节。而 b 指向的变量 23 是
i32类型,它在堆上只需要占用 4 字节。
当函数调用结束后,heap 函数返回的 box 指针就会被保存在 main 函数的局部变量里。
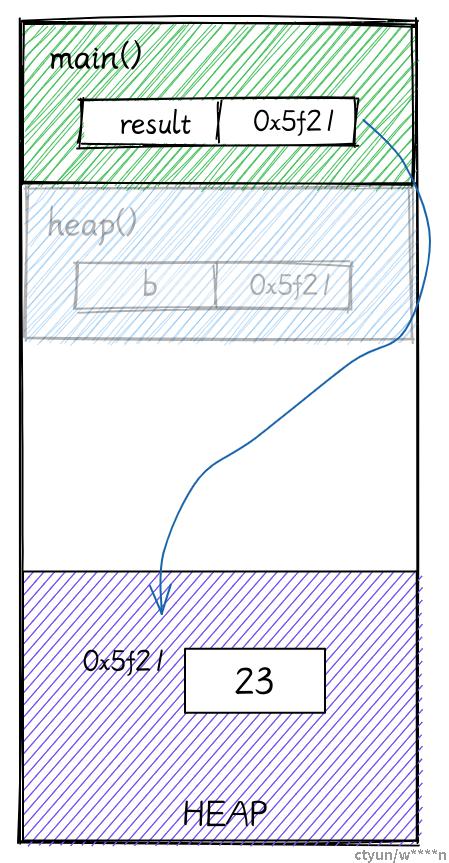
当你对栈上的数据进行赋值操作时,它的栈内存就会被直接 copy 过去。在这个例子里,用来保存 box 的 8 个字节就是从 heap 函数的栈帧直接复制到 main 的局部变量 result。现在即使 heap 函数的栈帧被释放,result 变量依然保存着数据的地址。堆允许你共享变量。
内存分配器
我们之前提到过每个线程都有各自的栈内存,他们共享一块堆内存。
假设你的程序不断在堆上分配新的数据,现在堆内存几乎耗尽了,需要对堆内存进行扩容。

程序的内存分配器一般会使用系统调用请求操作系统分配更多内存。对于 linux 系统来说,一般是 brk 或者 sbrk 系统调用。
在 Rust 里,堆内存分配器需要实现 GlobalAlloc 特征。你几乎不会直接用到它,编译器会在需要时插入合适的系统调用。
// /rust/library/std/src/sys/unix/alloc.rs
#[stable(feature = "alloc_system_type", since = "1.28.0")]
unsafe impl GlobalAlloc for System {
#[inline]
unsafe fn alloc(&self, layout: Layout) -> *mut u8 {
if layout.align() <= MIN_ALIGN && layout.align() <= layout.size() {
libc::malloc(layout.size()) as *mut u8
}
...
}
...
}你可能很熟悉 C 语言里的 malloc 函数,但是它并不是系统调用,malloc 依然会调用 brk 或者 sbrk 去请求内核。Rust 的内存分配器依靠 C 标准库里提供的 malloc 函数,如果你使用像 ldd 这样的工具去检查二进制文件依赖的动态链接库,你应该会看到 libc
$ ldd target/debug/demo
linux-vdso.so.1 (0x00007fff60bd8000)
libc.so.6 => /usr/lib/libc.so.6 (0x00007f08d0c21000)
/lib64/ld-linux-x86-64.so.2 => /usr/lib64/ld-linux-x86-64.so.2 (0x00007f08d0ebf000)> Linux 下 Rust 默认使用 GNU 作为链接器,因此 Rust 二进制文件依赖于操作系统上的 C 标准库或者
libc库。libc更像是操作系统的一部分,使用像libc这样的动态链接库有助于减少二进制文件体积。
同时,内存分配器也不总是依赖于系统调用在堆上分配内存:
-
每次程序使用 box 等把数据分配在堆上时,程序的内存分配器都会成块的请求内存去减少系统调用的次数。
-
堆和栈不一样,内存不一定总是在堆的末尾被释放。当一些地方的内存被释放后,它并没有立即返还给操作系统,内存分配器会追踪内存分页,知道那些页正在使用,那些页被释放了。所以当需要更多堆内存时,它可以直接使用这些已经释放但还未归还的内存分页。
现在你应该知道为什么分配堆内存比栈内存更消耗性能了。分配堆内存可能使用到系统调用,而且内存分配器每一次分配内前,都必须从堆上找到一个空闲内存块。
Rust 各数据类型的内存布局
整形
| 长度 (byte) | 长度 (bit) | 有符号 | 无符号 |
|---|---|---|---|
| 1 字节 | 8 位 | i8 | u8 |
| 2 字节 | 16 位 | i16 | u16 |
| 4 字节 | 32 位 | i32 | u32 |
| 8 字节 | 64 位 | i64 | u64 |
| 16 字节 | 128 位 | i128 | u128 |
有符号和无符号整形的名字已经展示了它所占的位数,比如 i16 和 u16 在内存都是 16 位 (2 字节)。它们都被完整的分配在函数的栈帧上。
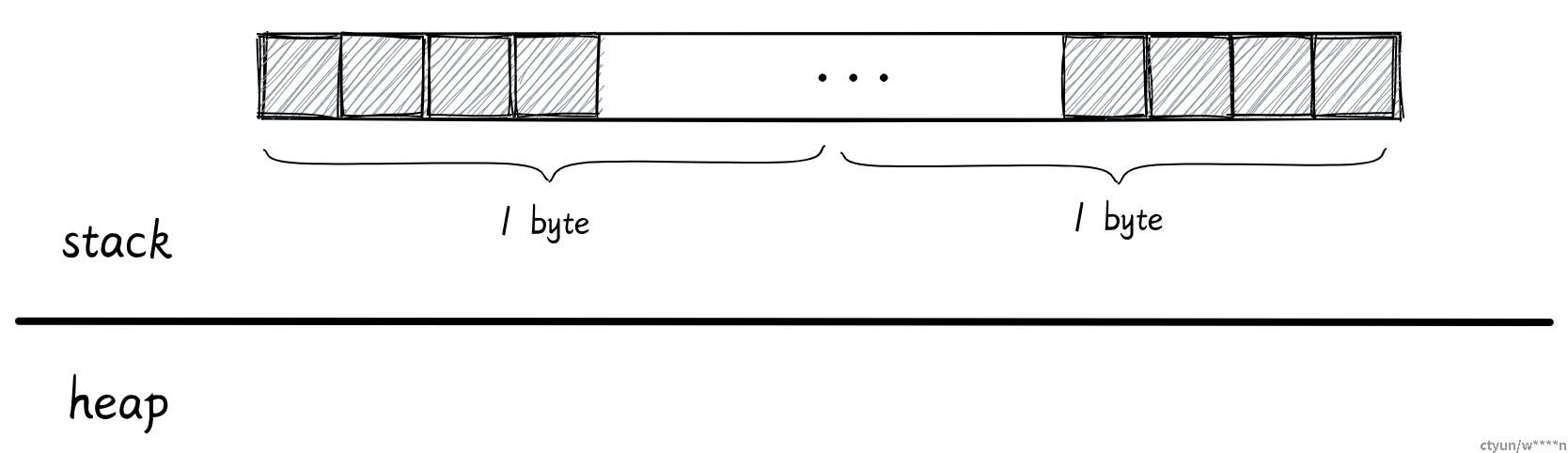
isize 和 usize 的大小则取决于你的系统,32 位系统就占用 4 字节,64 位系统就占用 8 字节。
字符型
char Rust 的字符不仅仅是 ASCII,所有的 Unicode 值都可以作为 Rust 字符。 例如 a、\u{CA0}、*、字、\n、🦀
char 类型长度是 4 字节,直接分配在栈上
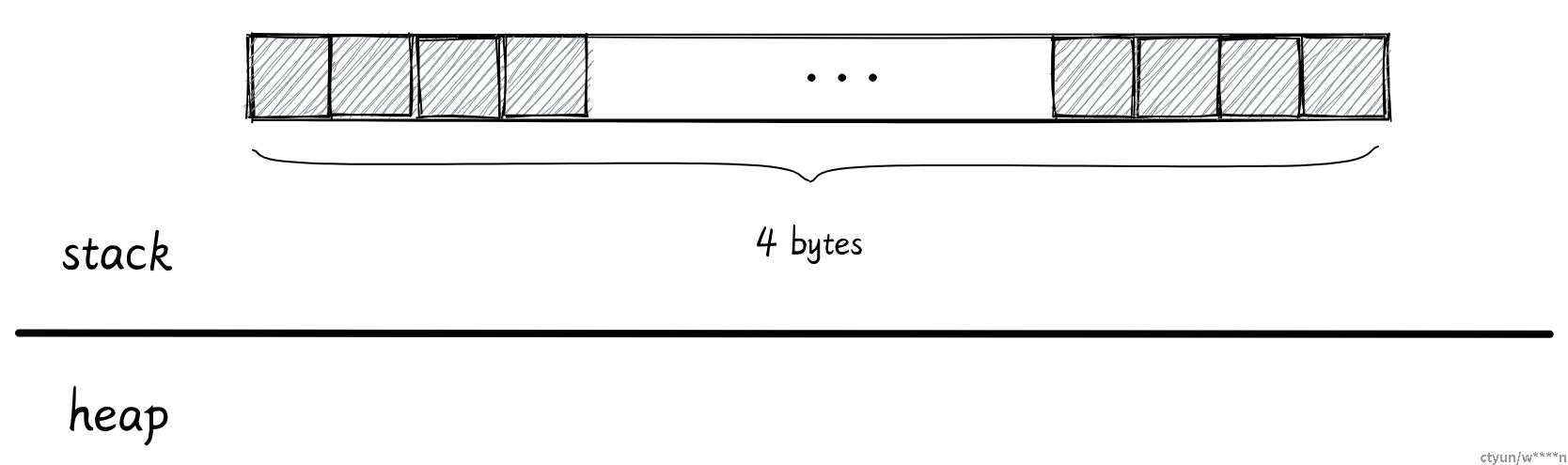
元组
元组是一些类型的集合
let a: (char, u8, i32) = ('a', 7, 354);比如这里,变量 a 包含了 char, u8, i32 三种数据类型,它的内存布局就是将各个成员依次排列。
在这里 char 占用 4 字节,u8 占用 1 字节,i32 占用 4 字节。因为这三种类型都是只在栈上分配的,所以整个元组也全在栈上分配。
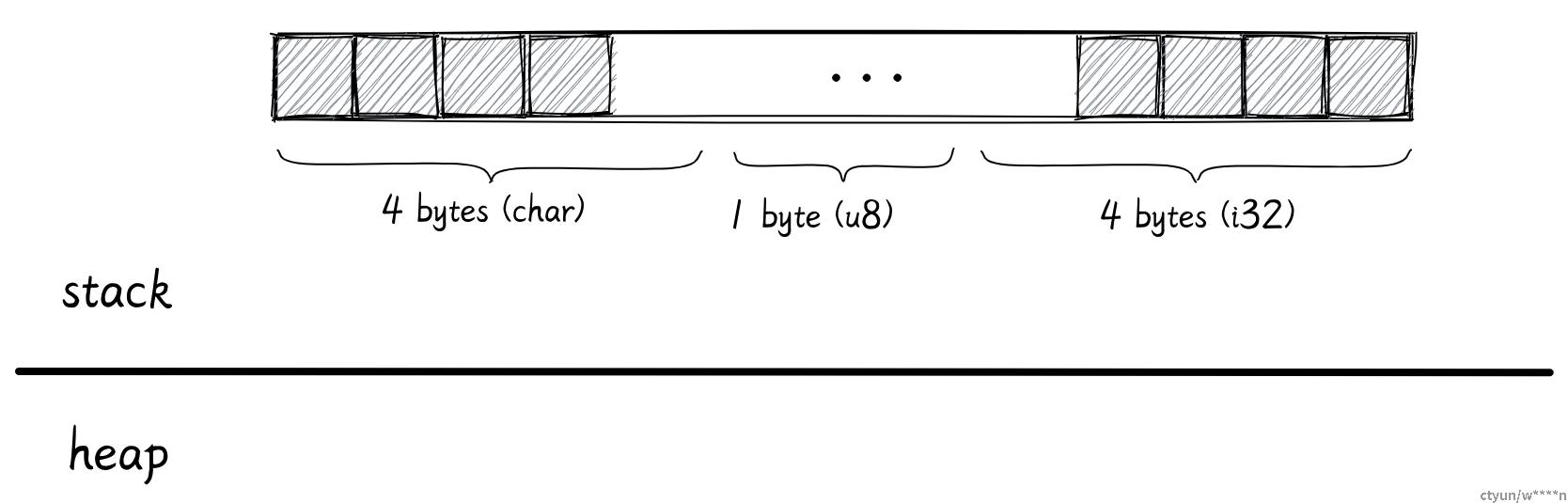
虽然看起来这个元组只会占用 9 字节的空间,但是其实并不是这样,你可以用 size_of 去查看这个元组占用的真正字节数
std::mem::size_of::<T>()size_of 和 align_of
use std::mem::{size_of, align_of};
size_of::<(char, u8, i32)>(); // 12 字节
align_of::<(char, u8, i32)>(); // 4 字节所有的数据类型还有一个对齐属性,你可以通过 align_of 查看。
数据类型的大小必须是对齐属性的整数倍。这一点不仅仅是 Rust,所有的编译器都是这样。数据对齐对 CPU 操作及缓存都有较大的好处,有助于 CPU 更快的读取数据。
对于这个元组,它的对齐属性值是 4,因此它占用的字节数是 12。剩下的 3 字节会被编译器填充空白数据
引用
接下来是引用类型 &T
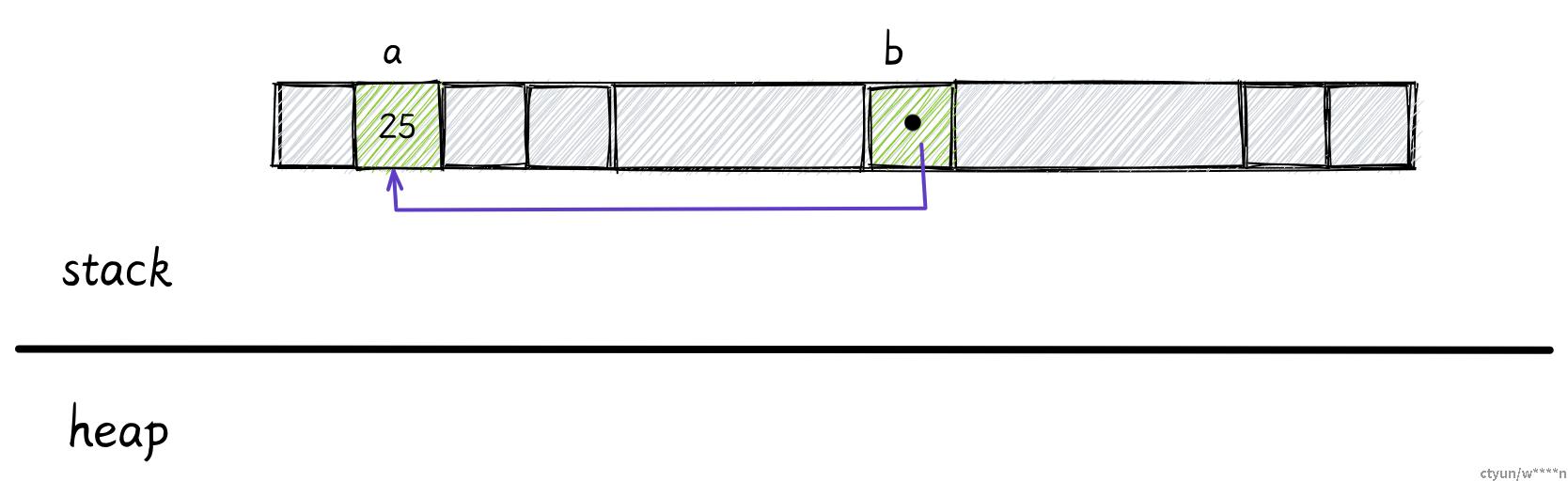
let a: i32 = 25;
let b: &i32 = &a;a 是 i32 类型,b 是对 a 的引用。
> 接下来,我不会在详细展示每个数据的字节大小,我们将重点去关注整体,关注他们是存储在堆上还是栈上。
在这里,a 存储在栈上,它占据 4 个字节。b 也存储在栈上,里面保存了变量 a 的地址。引用类型的大小取决于你的机器位数,所以 64 位系统上它占 8 字节。
如果我们再用 c 保存 b 的引用,c 的类型就是 &&i32
let c: &&i32 = &b;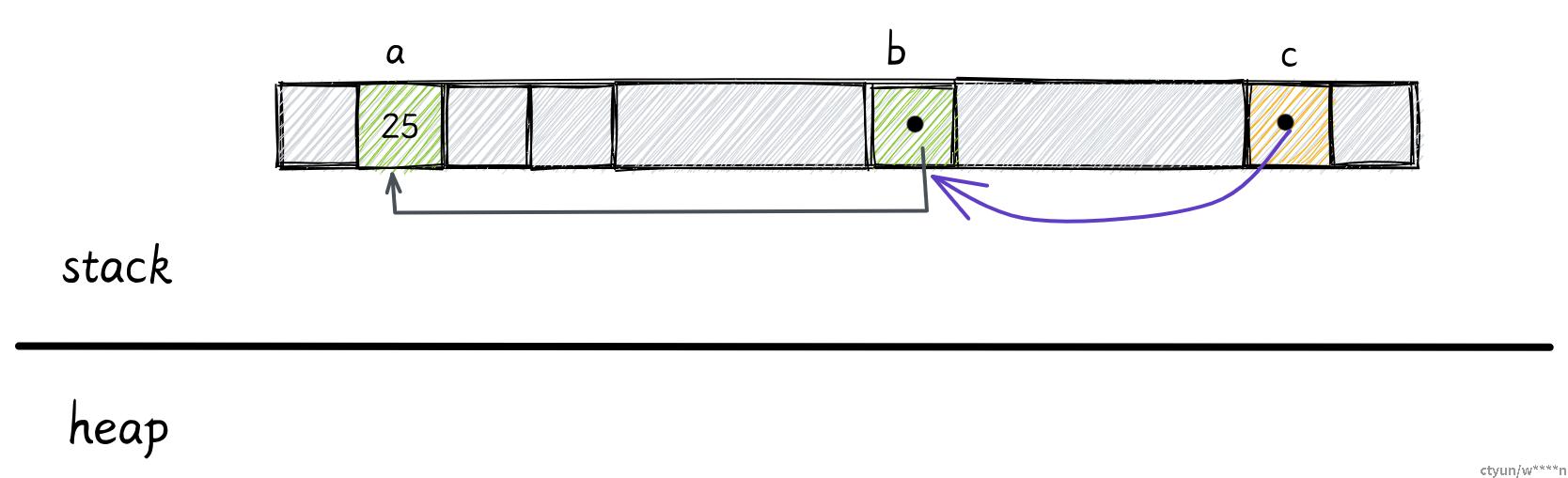
引用也能指向堆上的数据。
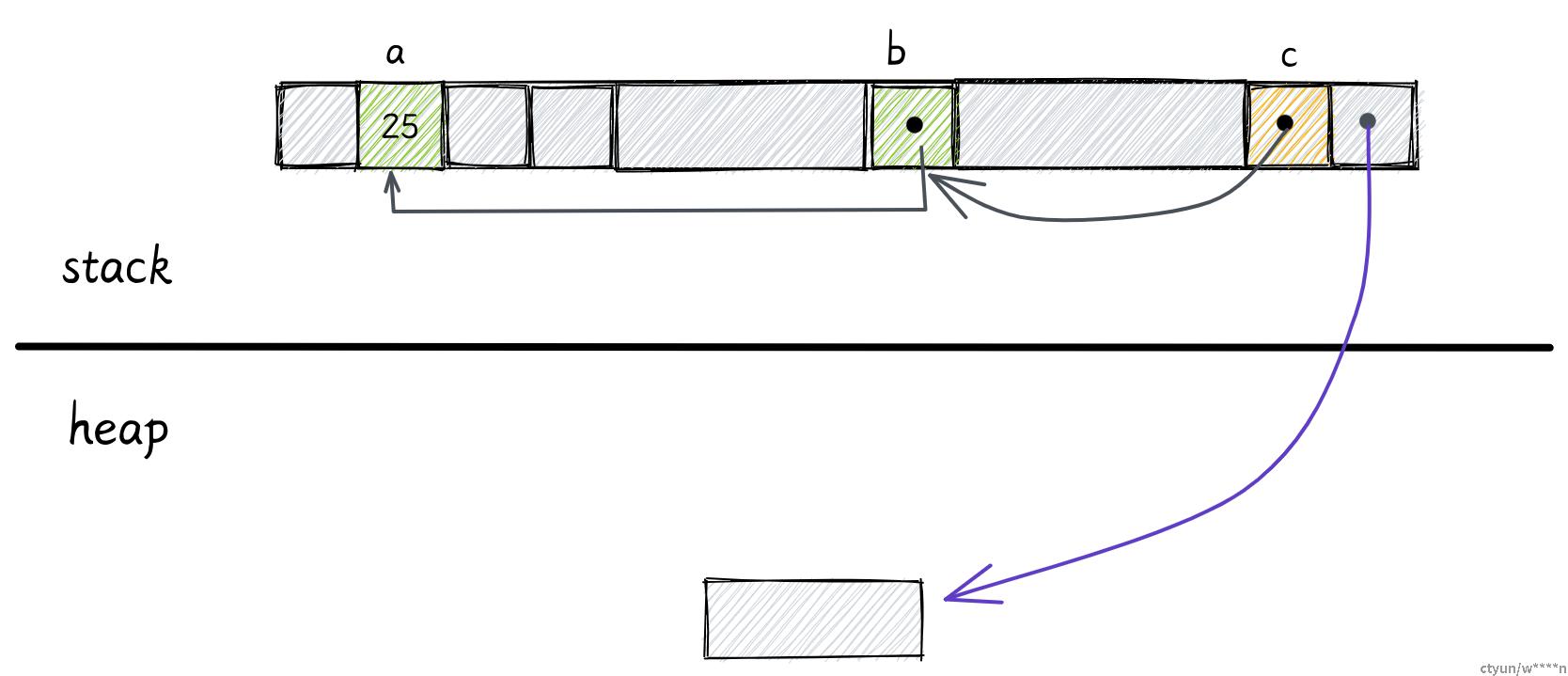
可变引用也有相同的内存布局。
可变引用和不可变引用的区别是他们的使用方式,以及编译器为可变引用添加的额外限制。
数组
let a: [i32; 3] = [55, 66, 77];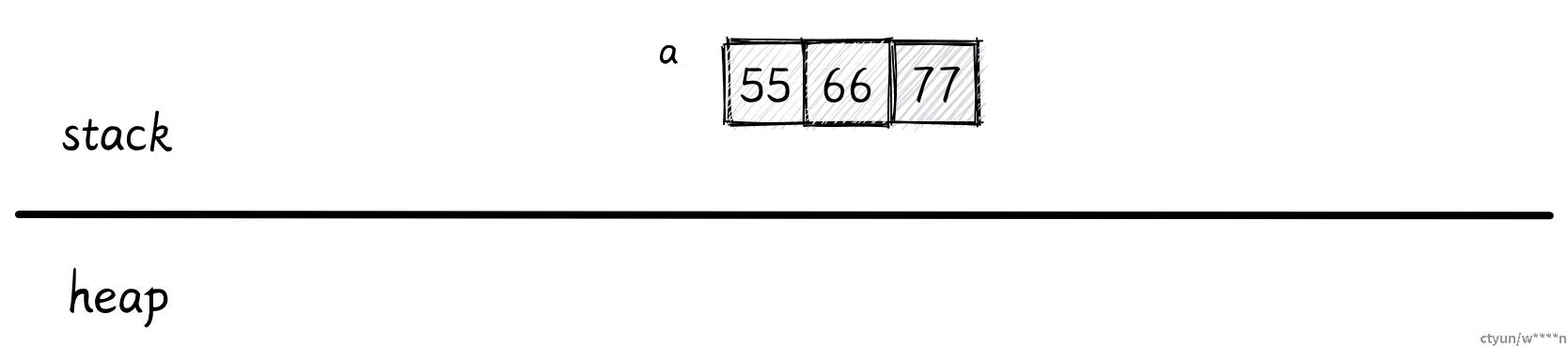
一个数组的大小是固定的,而且它的大小是数据类型的一部分。数组中的每个元素都会在栈上相邻排放。但是当数组创建后,它的大小就不能再改变。
> 注意:只有大小固定而且在编译时已知的数据类型才能存储在栈上。
Vec
Vec 类型是可扩容的,它的大小能够改变,你可以用它代替数组。
let v: Vec<i32> = vec![55, 66, 77];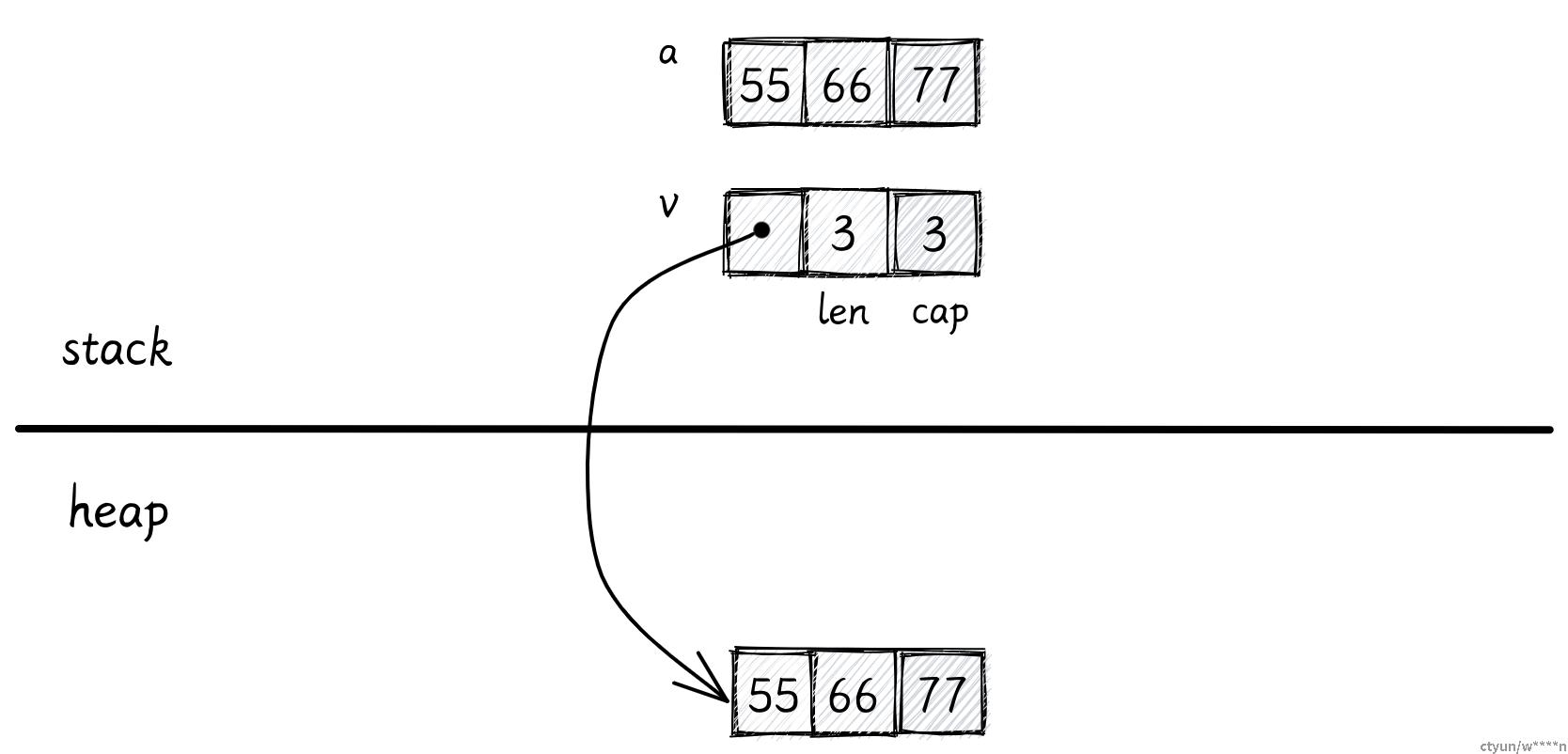
这里我们的变量 v 存储了和数组相同的数据,但是它是在堆上分配的。
变量 v 在栈上占用的大小是固定的,包含 3 个 usize:
- 第一个表示数据在堆上的地址,
- 剩下的两个表示 Vec 的容量和长度。
容量表示 Vec 的最大空间。当我们向 Vec 中添加更多数据时,如果元素个数还没有达到容量大小,Rust 就不必为堆内存分配更多空间。
如果长度和容量已经相等了,我们还要向 Vec 添加更多数据,Rust 就会在堆中重新分配出一块更大的内存,将原数据复制到新的内存区域,并更新栈中的指针。
切片
let s1: [i32] = a[0..2];
let s2: [i32] = v[0..2];切片 [T] 和数组非常相似,但是不用指定大小。切片就像是底层数组的一个视图,s1 表示数组 a 的前两个元素,s2 表示向量的前两个元素。
由于切片没有指定元素数量,编译时 Rust 编译器不知道它具体占了多少字节。同时,你也不能将切片存在变量中,因为它没有已知大小,所以不能被分配在栈上,这样的类型被称为 DST 动态大小类型 。
> 还有其他的 DST 类型,比如字符串切片和特征对象。
如果你尝试运行上面的代码,应该会编译失败:
error[E0277]: the size for values of type `[i32]` cannot be known at compilation time
--> examples/vec.rs:8:9
|
8 | let s1: [i32] = a[0..2];
| ^^ doesn't have a size known at compile-time
|
help: consider borrowing here
|
8 | let s1: [i32] = &a[0..2];
| +因此,几乎在任何情况下,我们只会使用到切片的引用 &[T]。被引用的数据既能在栈上,也能在堆上:
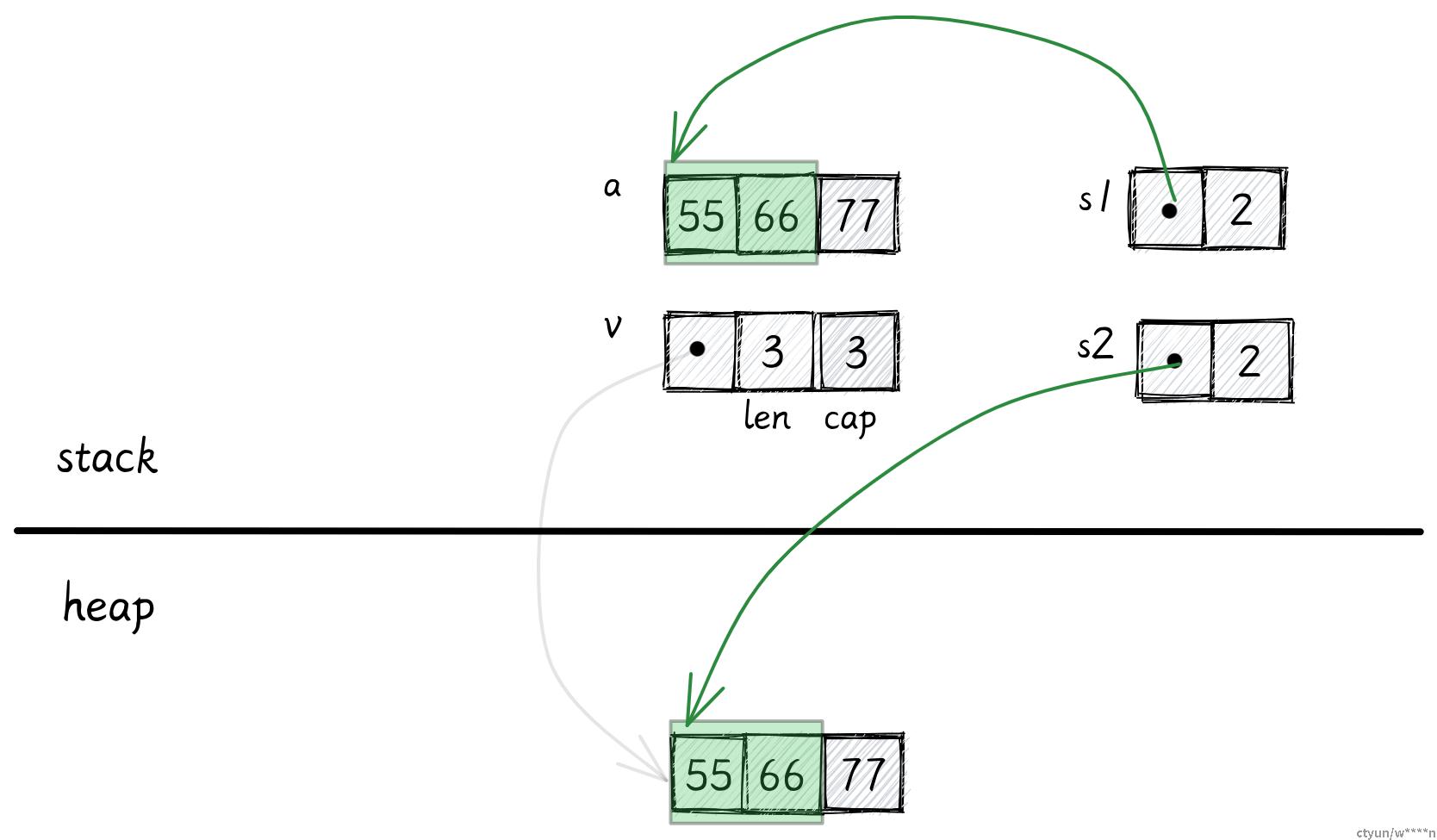
我们之前说过,引用只是一个指针,它占据一个 usize 去存储它所指向的数据的地址。
但是当你用指针去指向一个动态大小类型时 (比如切片),Rust 会使用一个额外的 usize 去存储数据的长度。这种引用也叫做 胖指针 (将一些附加信息和指针一起存储)。
切片引用可以用两个 usize 表示,所以它可以存在栈上。
字符串
与字符串相关的有三种类型:String, str, &str,他们分别对应 Vec, [T], &[T}
字符串类型 String 的内存布局和向量相同,唯一的区别是,字符串类型必须是 UTF-8 编码。
以下面的代码为例:
let s1: String = String::from("hello");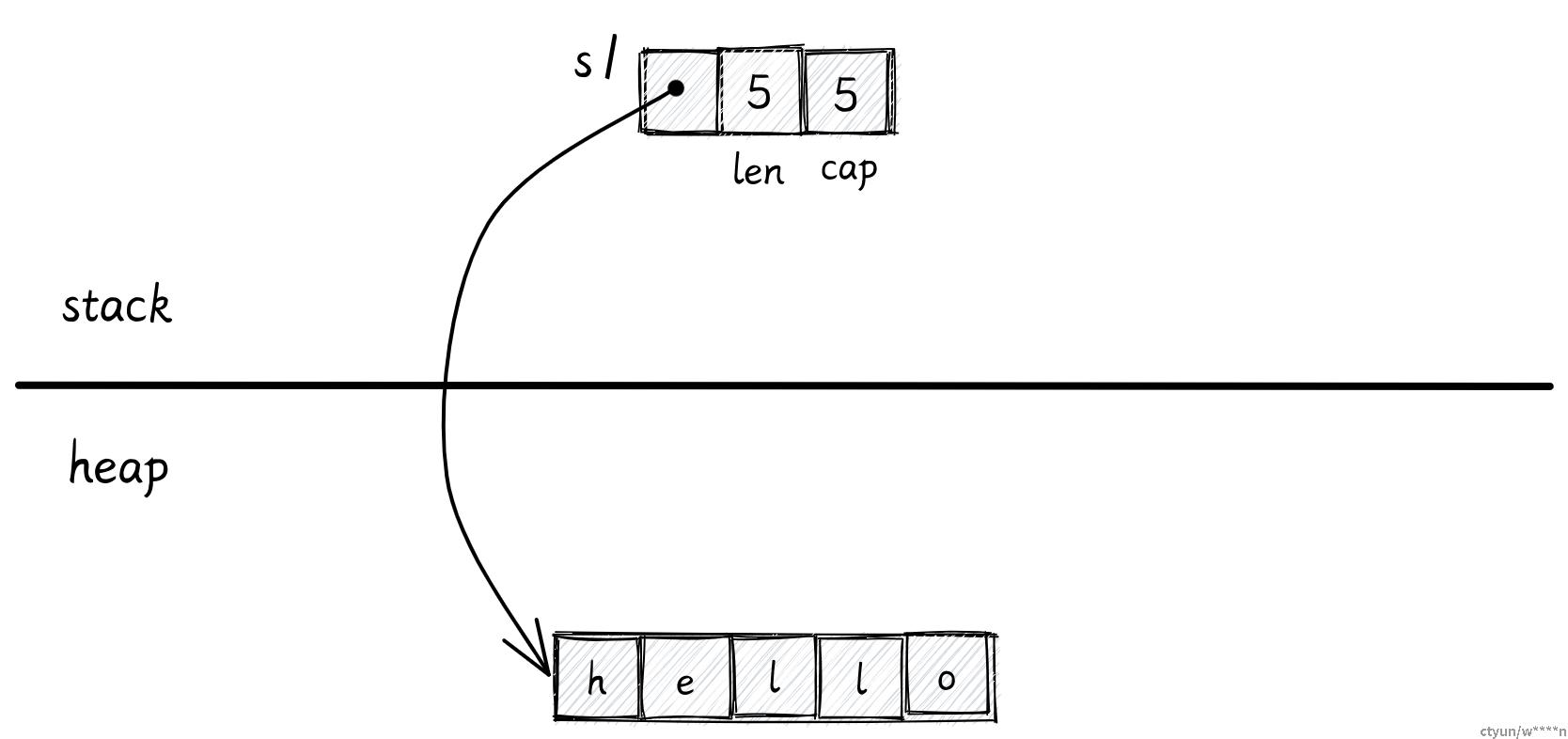
但是,如果你把一个字符串直接保存在变量中:
let s2: &str = "hello";s2 的类型就会变成字符串切片的引用,这个字符串的数据不会在堆上,而是直接存储在编译好的二进制文件中。这种字符串有 'static 的生命周期,它永远不会被释放,在程序运行时都是可用的。
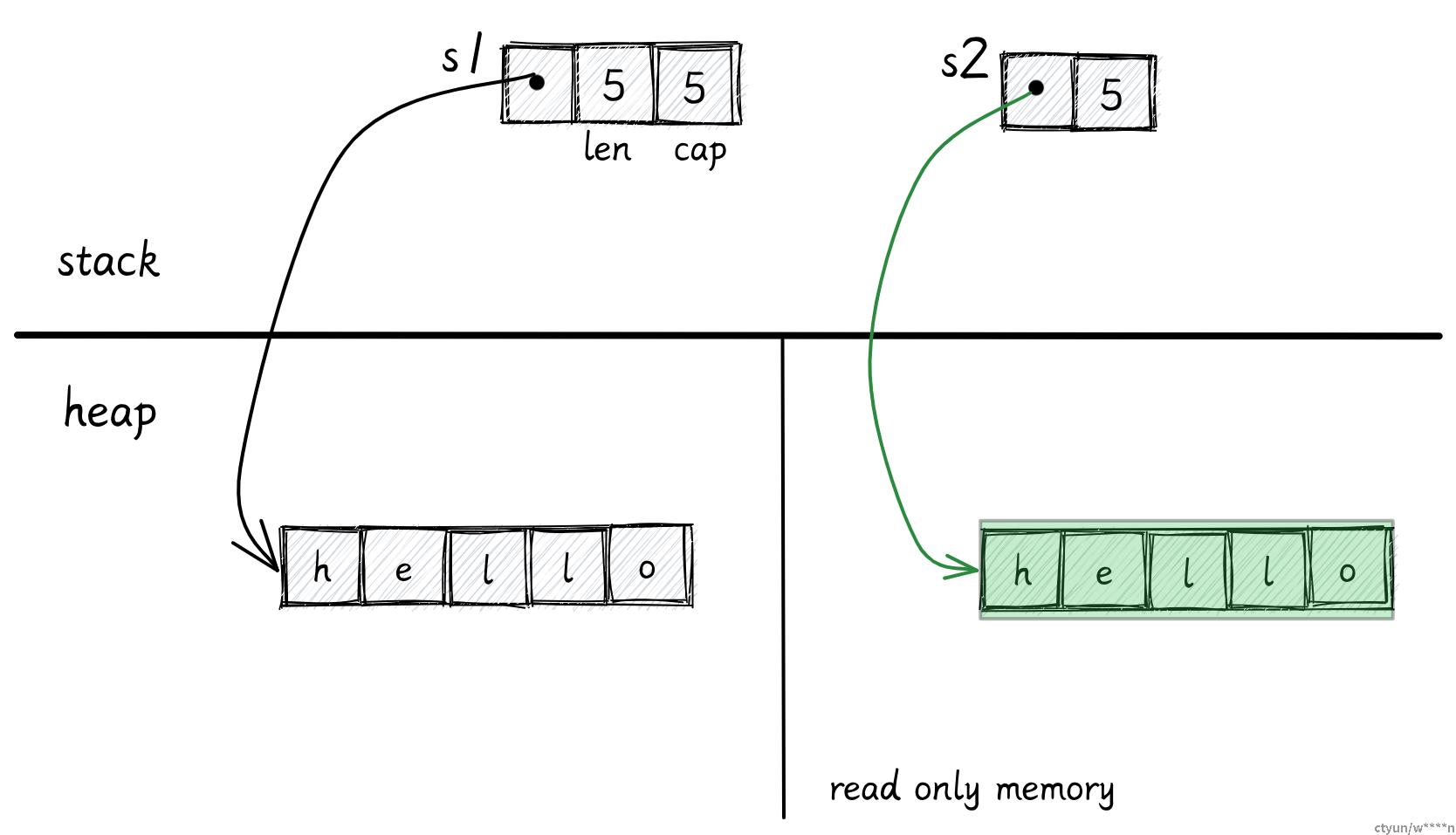
> 据我所知,Rust 不会指定字符串被保存在文件的那个部分,但是很可能就在代码段 (text segment)
和切片引用一样,对字符串的切片的引用也是一个胖指针,包含两个 usize,一个用来存储字符串的内存起始地址,另一个存储字符串长度。
你不能直接使用字符串切片 str:
// error: size can not be known at compile time
let s: str = s1[1..3];对字符串的切片引用是可行的:
let s: &str = &s1[1..3];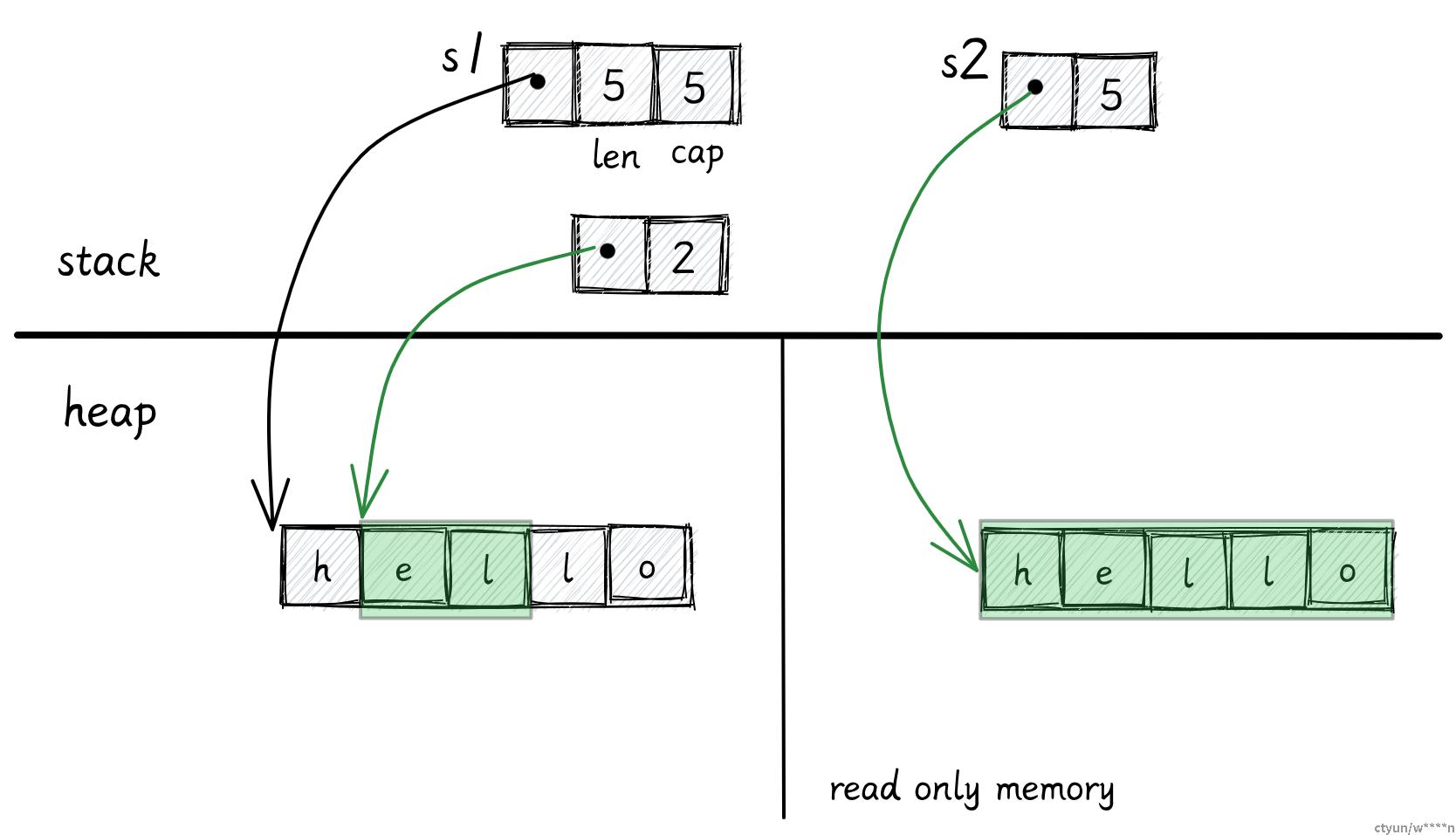
结构体
Rust 有三种结构体类型:结构体,元组结构体 (Tuple Struct) 和单元结构体 (Unit-like Struct)。
普通结构体:
struct Data {
nums: Vec<usize>,
dimension: (usize, usize),
}元组结构体:
struct Data(Vec<usize>);单元结构体:
struct Data;单元结构体不保存任何数据,所以 Rust 编译器甚至不会为他分配内存。
另外两种结构体的内存排布非常类似于之前所说的元组,我们以普通的结构体为例:
struct Data {
nums: Vec<usize>,
dimension: (usize, usize),
}它有两个字段,一个 Vec 和一个元组,结构体的各个成员会在栈上依次相邻排列。
- Vec 需要占用 3 个
usize,nums 的成员会被分配在堆上。 - 元组需要占用 2 个
usize。
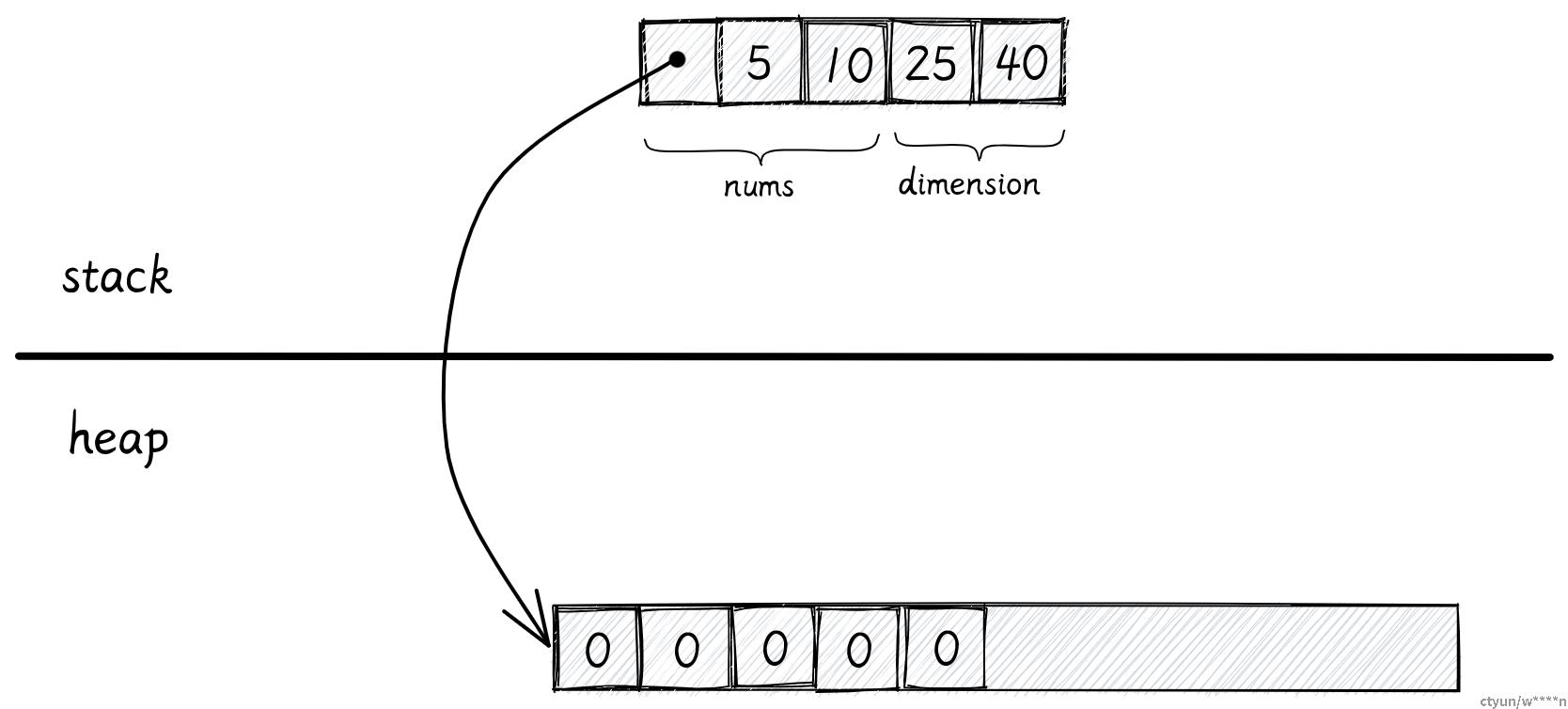
> 注意:我们在这里忽视了内存对齐和编译器填充的 padding。
枚举
像结构体一样,Rust 支持用不同的语法表示枚举。
下面展示的是一个 C 风格的枚举,在内存中他们被保存为从零开始的整数,Rust 编译器会自动选择最短的整数类型。
enum HTTPStatus {
Ok,
NotFound,
}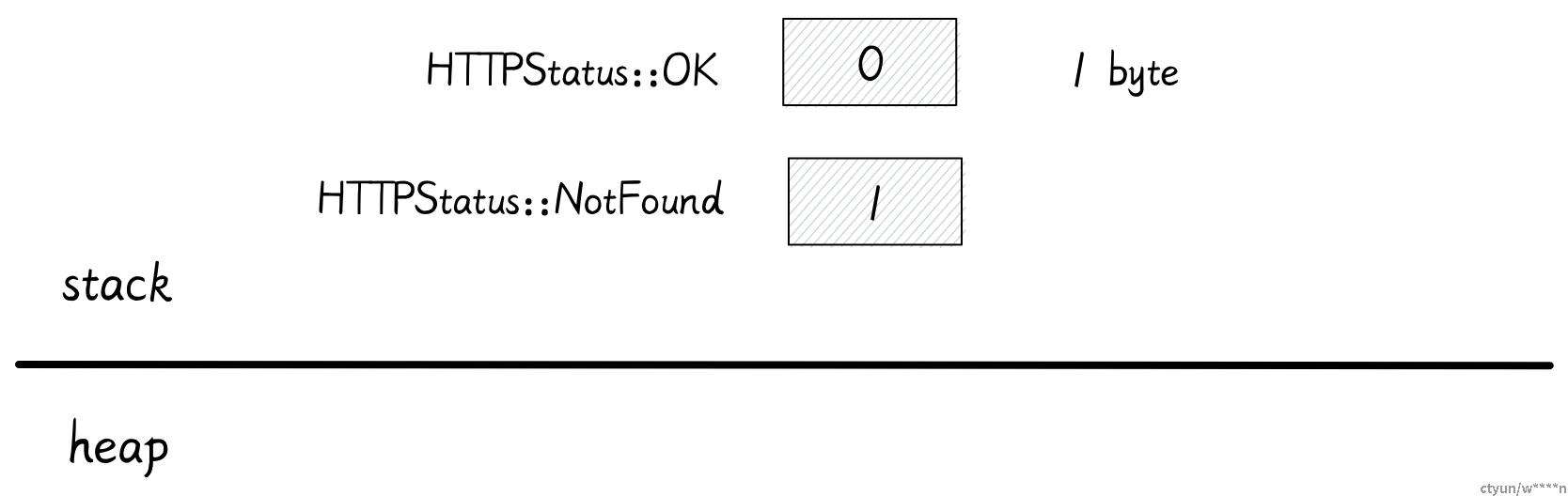
在这里最大值为 1,因此该枚举可以使用 1 字节存储。
你也可以手动为枚举的每个变体指定它的值:
enum HTTPStatus {
Ok = 200,
NotFound = 404,
}这个例子里最大的数是 404,需要至少 2 字节存储。所以这个枚举的每种变体都需要 2 字节。

枚举值也可以选择具体的类型
enum Data {
Empty,
Number(i32),
Array(Vec<i32>)
}在这个例子中
Empty变体不存储任何数据Number内部有一个i32Array里面有个Vec
它们的内存布局如下图所示:
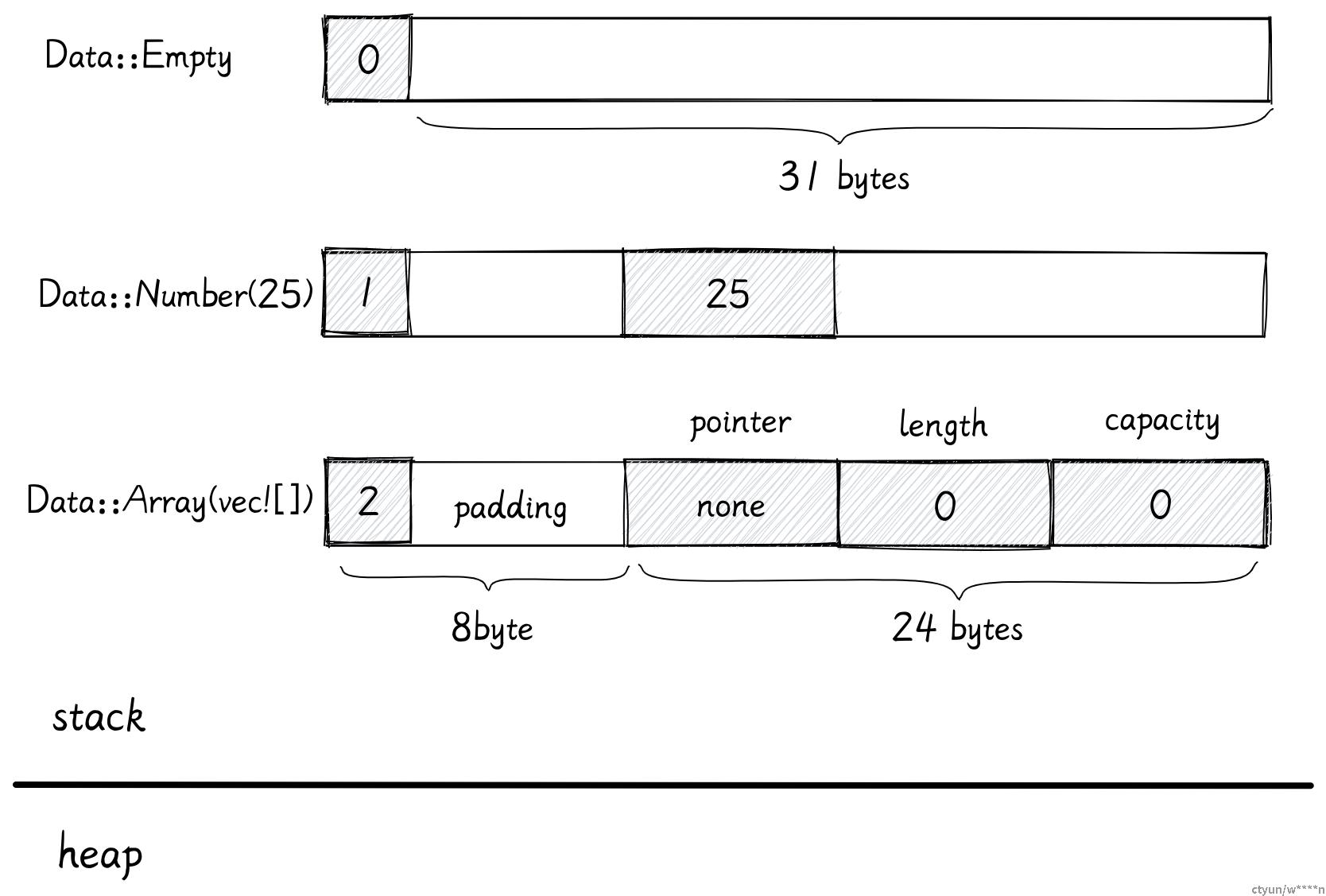
首先我们看 Array 变体:
首先是一个整数标记 2 占用 1 字节,接着就是 Vec 所需的三个 usize ,编译器还会填充一些空白区域让他们内存对齐,所以这个变体需要 32 字节 (1 + 7 + 3 * 8)。
接着是 Number 变体,首先是整数标记 1,接着是 Number 里存储的 i32,占用 4 字节。因为所有变体的大小应该是一致的,所以编译器会为它们两个都添加 Padding 达到 32 字节
对于 Empty,它只需要一个字节去存储整数标记,但是编译器也必须添加 31 字节的 Padding
所以,枚举占用的空间取决于最大变体占用的空间。
减少内存使用的一个技巧就是降低枚举最大变体占用的内存:
enum Data {
Empty,
Number(i32),
Array(Box<Vec<i32>>) // 使用 Box 代替
}在这个例子里,我们存除了 Vec 的指针,此时 Array 变体需要的内存只有 16 字节:
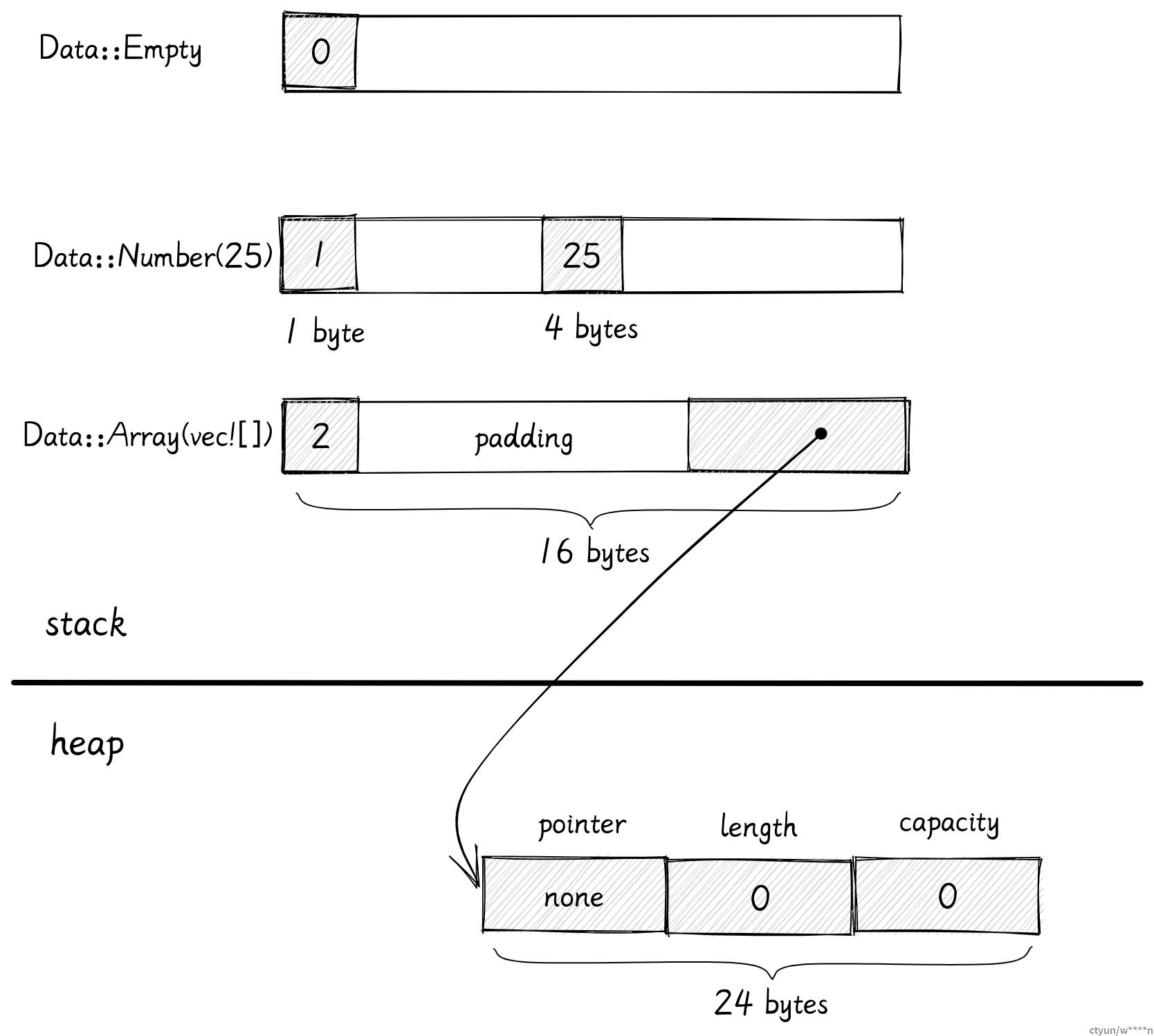
Box
Box 是一个指针指向堆上的数据,所以 Box 在栈上只需要 1 个 usize 去存储地址。
在上个例子中,Box 指向了一个在堆上分配的 Vec。
> 如果向量里面有值,这些值也会被存储在堆上。指向数据的指针将保存在 Vec 的指针字段里
对 Option 的优化
pub enum Option<T> {
None,
Some(T)
}由于 Rust 不允许出现空指针,想要实现同样的效果,你需要使用
Option<Box<i32>>这能够让 Rust 编译器确保不会出现空指针异常。
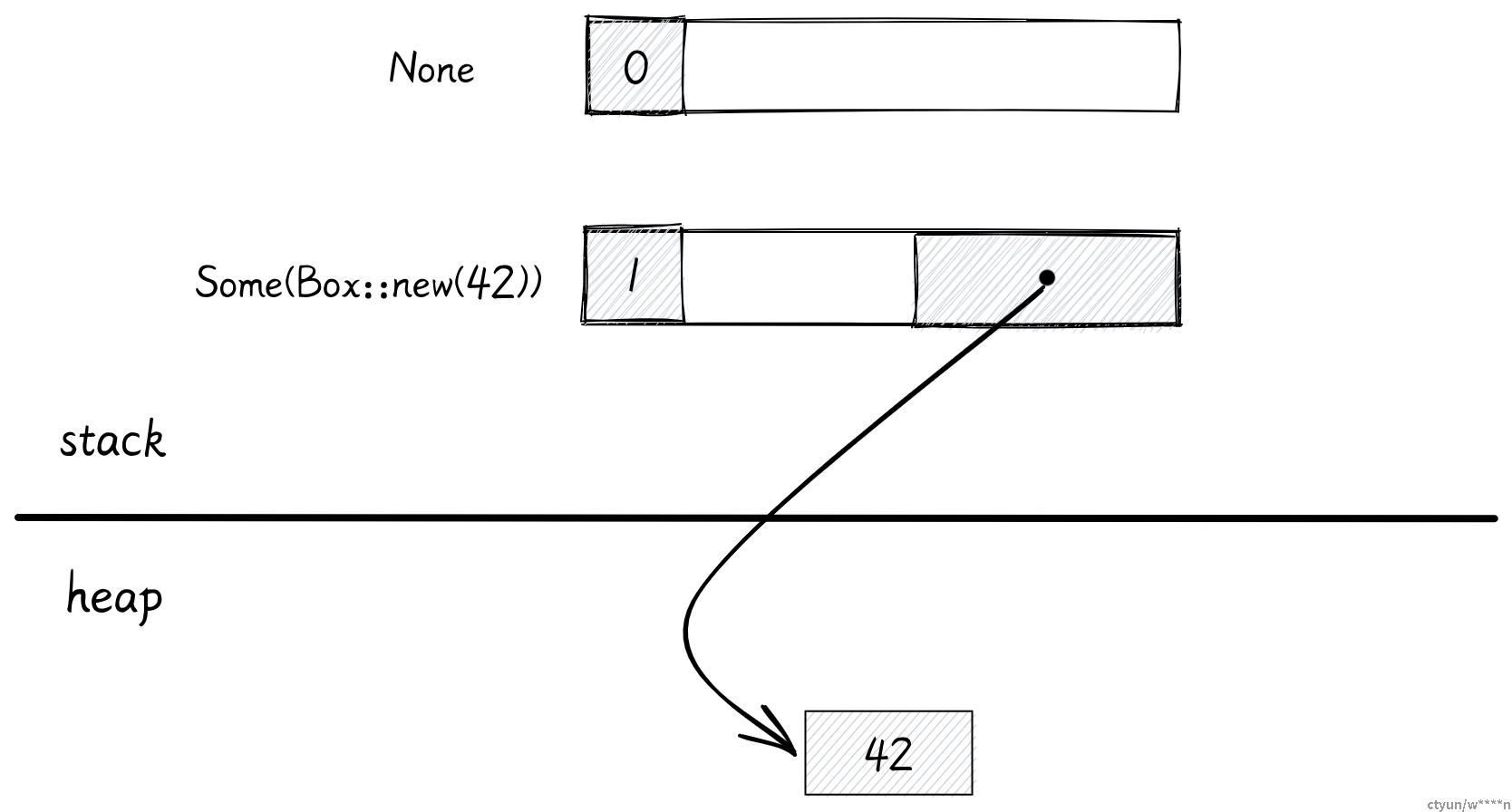
在其他语言里,使用一个指针就能表示这两种状态。但是 Rust 却需要一个额外的整数标记和随之带来的 padding,这会造成内存浪费。
编译器能对此做出一些优化,如果 Option 里是 Box 或者是类似的指针类型,编译器就会省略掉整数标记,并使用值为 0 的指针表示 None。
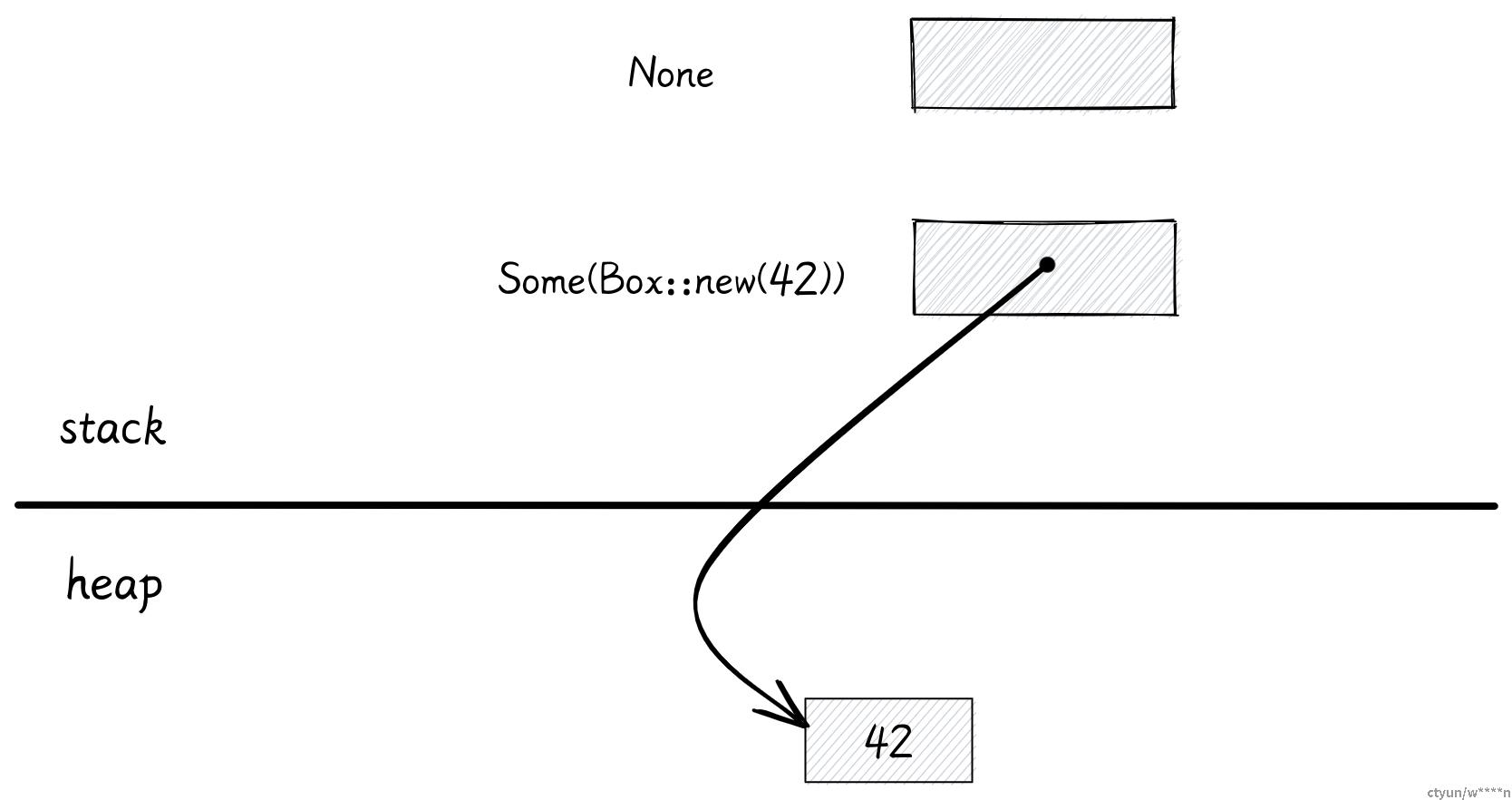
这种特性使得 Rust 中被包装在 Option 内的智能指针像其他语言里的指针一样,不会占用多余的内存。同时还能够提前找到并消除空指针异常
Copy 和 Move
在继续向下讨论之前,让我们先了解一下 Copy 和 Move
let num:i32 = 42;
let num_copy = num;对于原始类型数据,他们的大小是在编译时已知的,会被存储在栈上。如果你将一个变量赋值给另一个变量,它得到的实际上是原始数据的一份拷,Rust 会逐位进行复制。
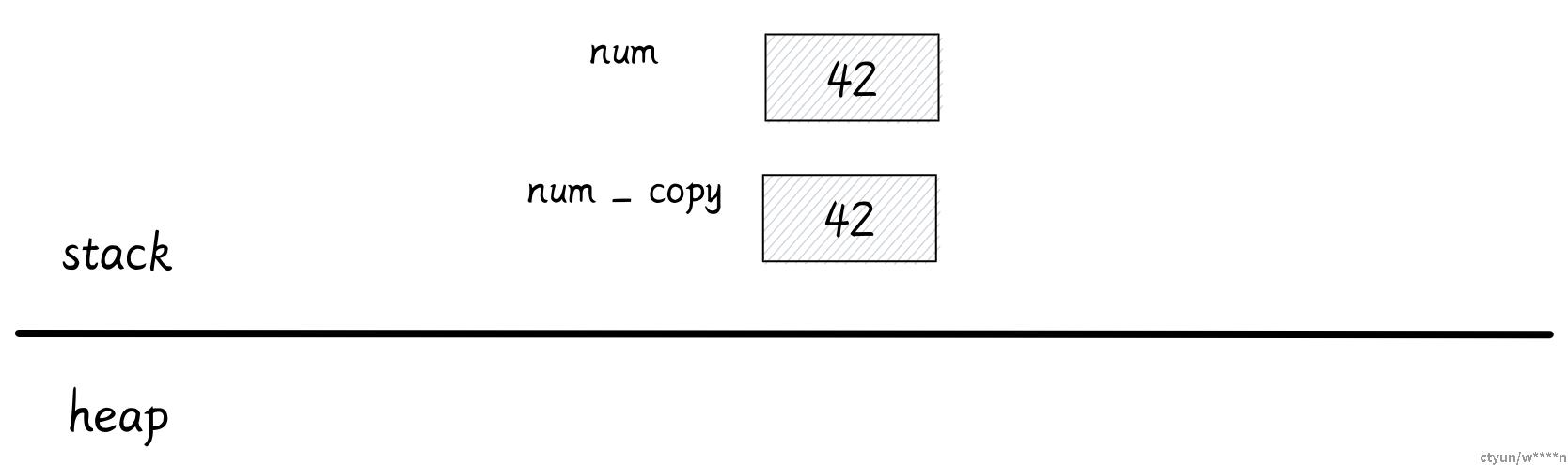
这两个变量之后能同时使用
对于在堆上存储的数据来说:
let v: Vec<String> = vec![
"Odin".to_String(),
"Thor".to_String(),
"Loki".to_String(),
]在这个例子里,我们有一个在堆上分配的字符串向量。
变量 v 被保存在栈上,它需要 3 个 usize 去存储 Vec 的信息,并指向数据在堆中的地址。
每个字符串也需要 3 个 usize 来存储实际字符串的信息。
真正的字符串会被分配到堆上的其他地方。
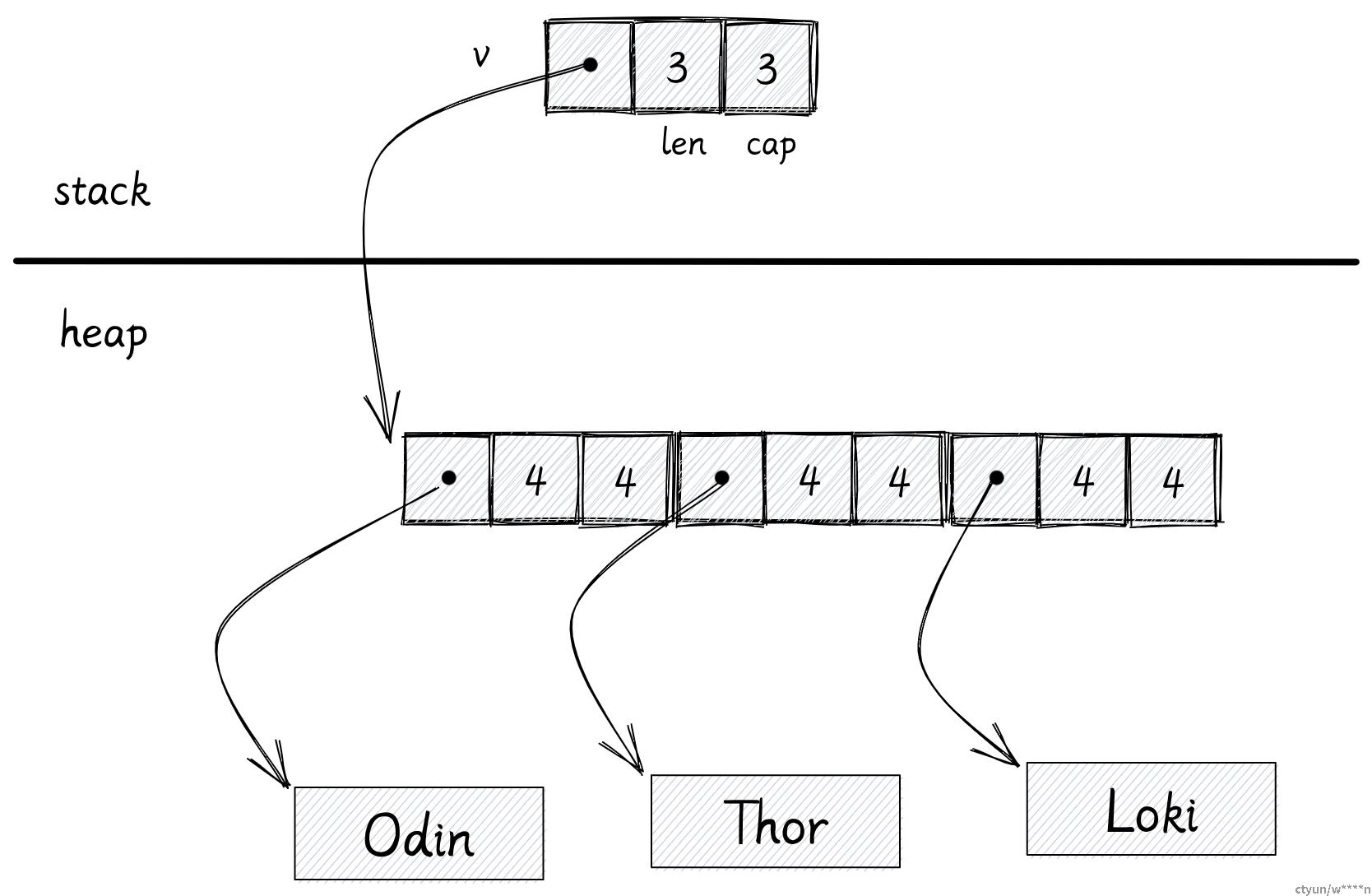
从所有权角度来说,变量 v 拥有所有在堆上分配的内存。因为 Rust 没有 GC,当变量 v 自己超出作用域后,它需要自己释放自己拥有的堆内存。
接下来我们将 v 赋值给了 v2:
let v2 = v;对于有 GC 的语言来说,程序会对变量 v 在栈上的数据进行了按位复制,最后 v2 也将拥有指向堆上数据的指针。
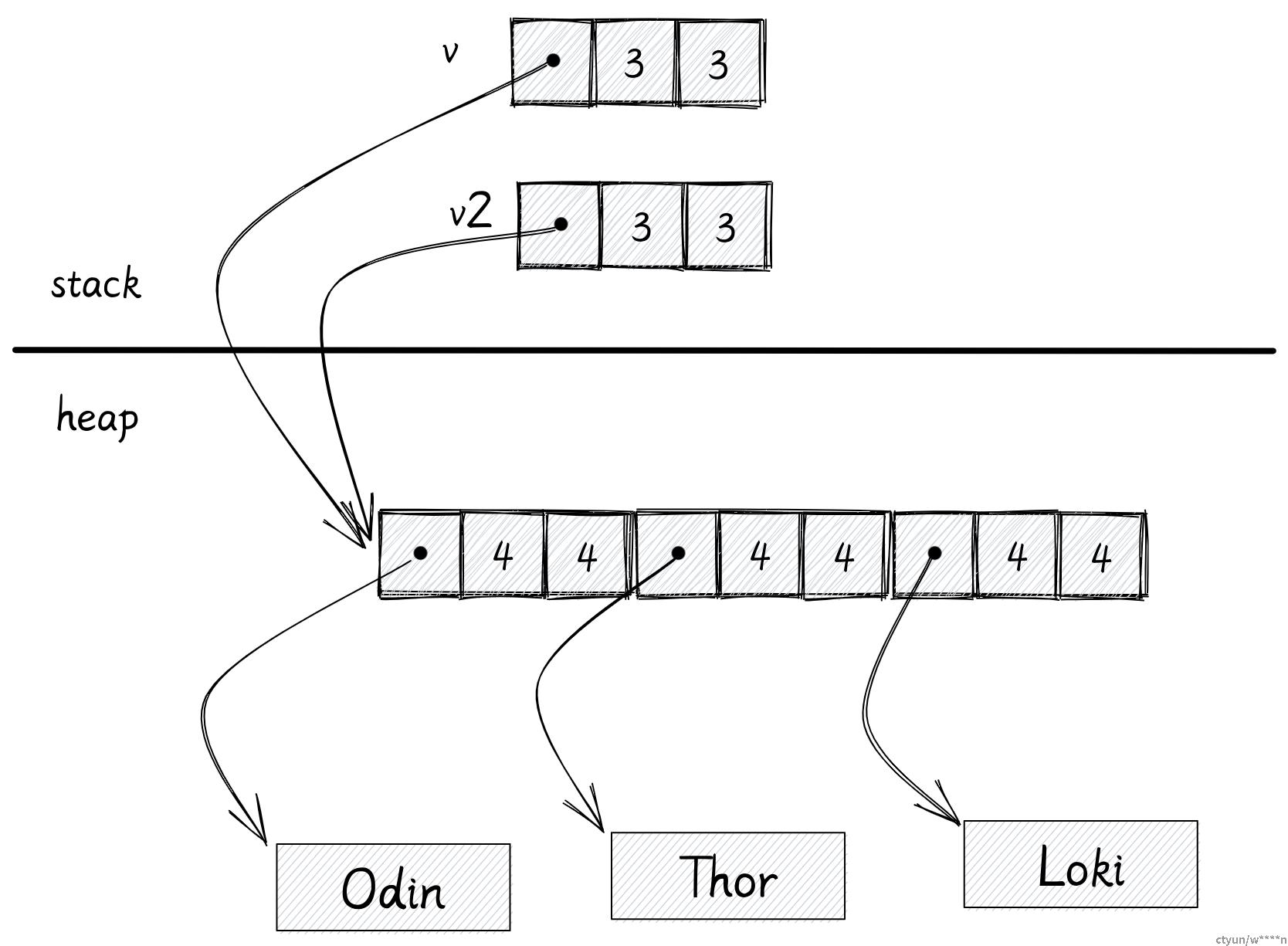
这种方案很节省内存,无论在堆中的数据有多大,我们只需要复制栈上的数据。垃圾回收器会追踪堆内存的引用数量,当引用计数归零,垃圾回收器会帮我们释放堆内存。
但是 Rust 没有 GC,它只有所有权模型。我们不清楚到底哪个变量需要对释放内存负责。
另一种方案是:在赋值时为堆内存也创建一个副本。但是这会导致内存使用量升高,降低性能。
Rust 的选择是让用户必须做出选择:如果你在对变量赋值时想让它拥有一份属于自己的堆内存,你应该使用 clone 方法。如果你不使用 clone 方法,Rust 编译器就不允许你再使用之前的变量。
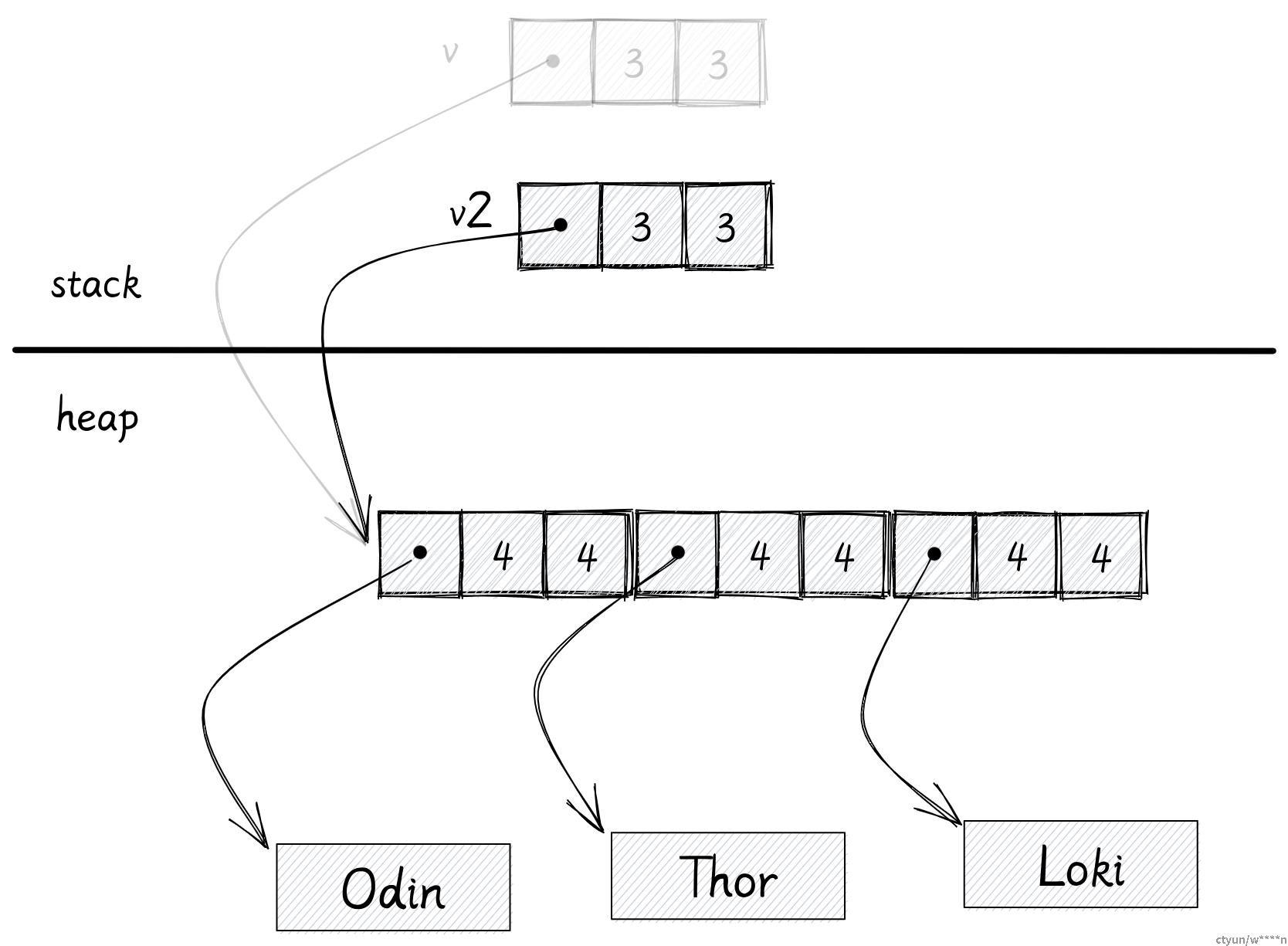
我们把它称为:变量 v 已经被 move 了,现在 v2 是数据的拥有者。当 v2 超出作用域时,它会负责释放堆上的数据。
Rc
有时候我们想让一个值拥有多个拥有者,大多数情况下,你可以用普通的引用去解决。但是这种方法的问题在于,当数据的拥有者超出作用域后,所有的引用也不能再继续使用。
我们想要的是所有变量都是数据的拥有者,只有所有变量都超出作用域后,数据才会被释放。Rc 智能指针通过引用计数能够实现这个功能:
use std::rc::Rc;
let v: Rc<Vec<String>> = Rc::new(vec![
"Odin".to_String(),
"Thor".to_String(),
"Loki".to_String(),
]);
let v2 = v.clone();
println!("{}, {}", v.capacity(), v2.capacity())当你使用 Rc 去包裹一个 Vec 时,Vec 的 3 个 usize 会和引用计数一起分配在堆上。变量 v 在栈只占用一个 usize,里面存储了 Rc 在堆上的地址。
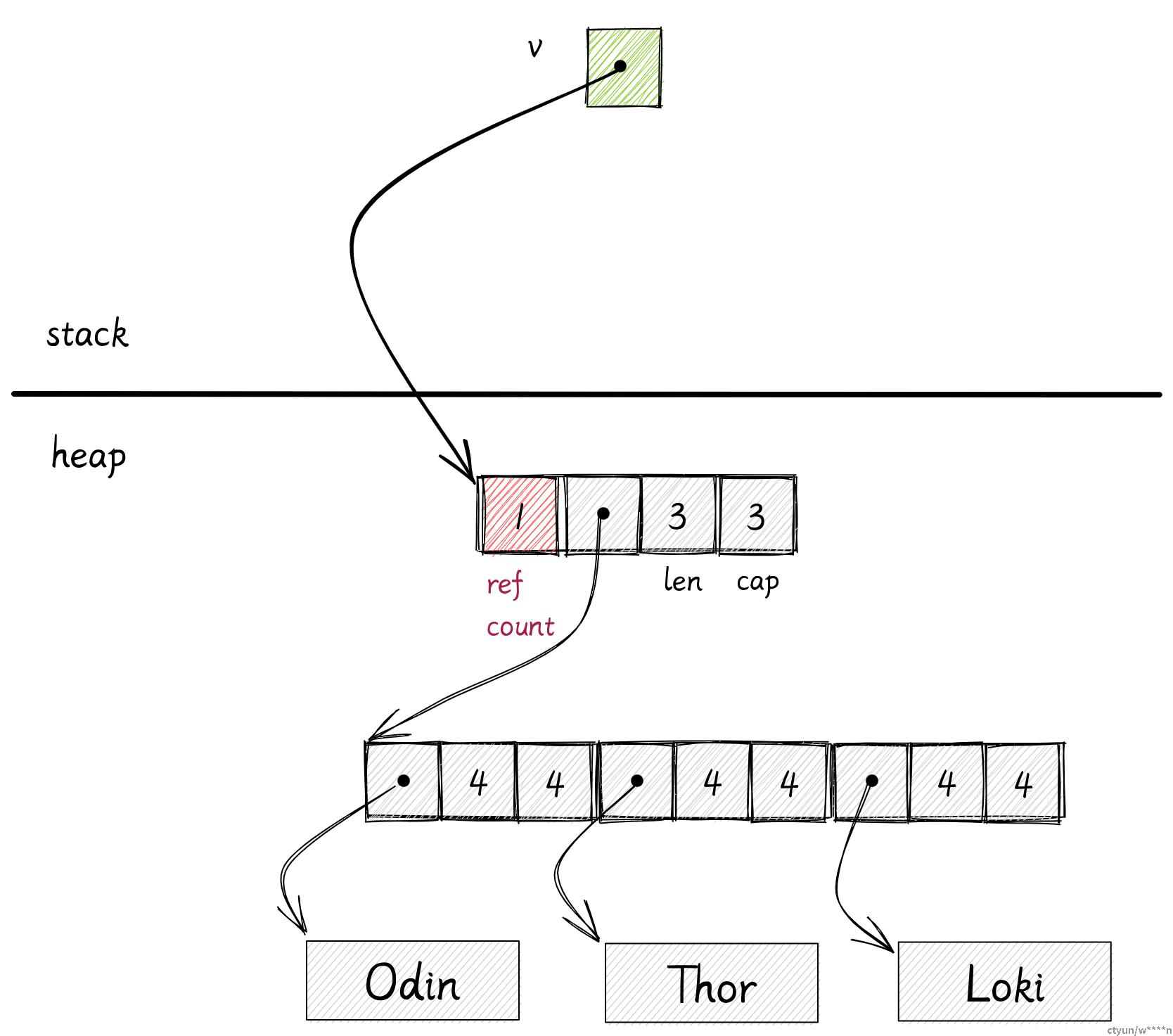
现在你能通过克隆 v 来创建 v2,这个克隆不会克隆任何位于堆上的数据,他只会克隆一份栈上的地址,然后将 Rc 的引用计数加 1,现在 v 和 v2 都持有相同的一份数据,这就是为什么它被称为引用计数指针。
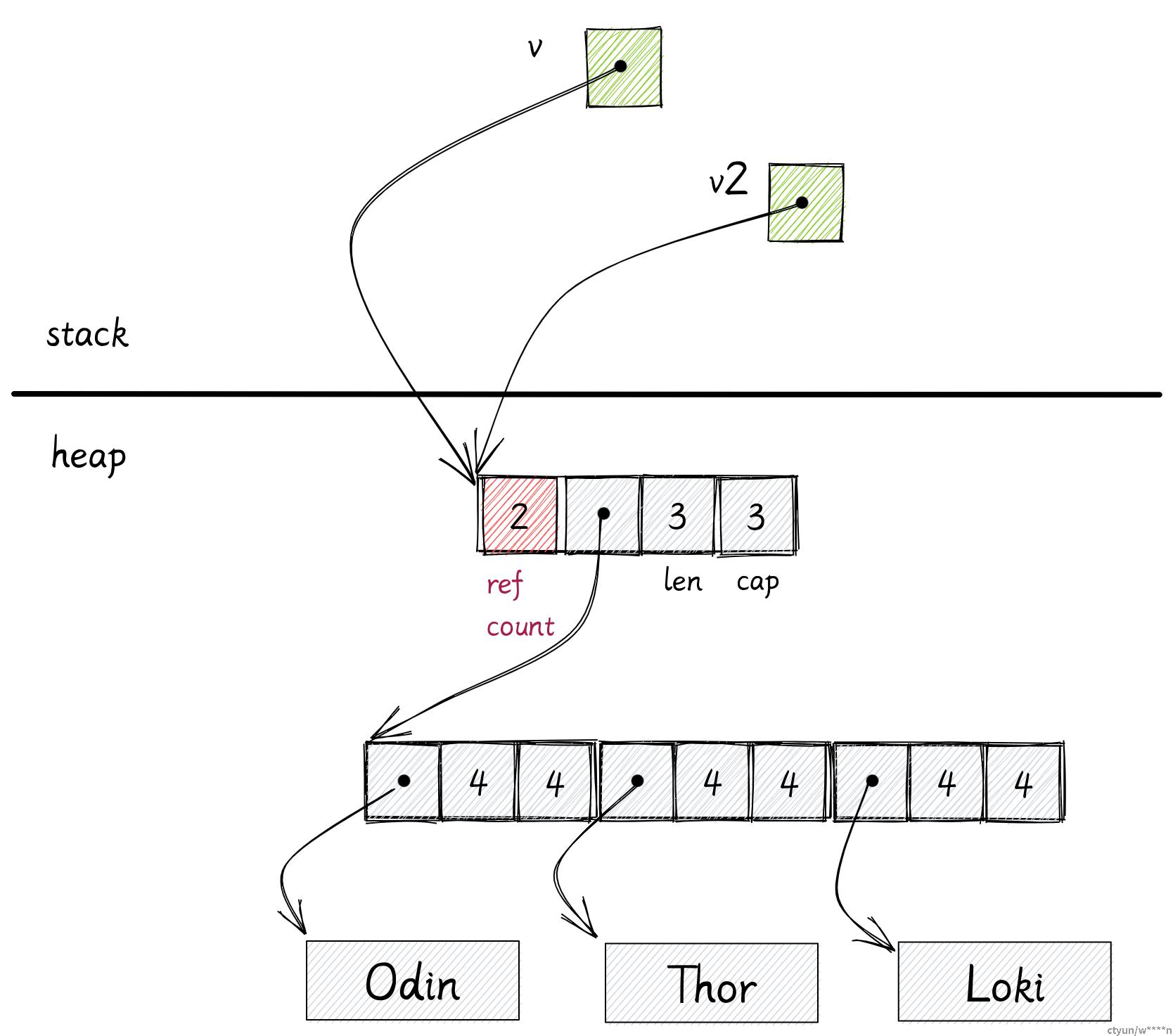
但是 Rc 也有限制,Rc 内部的数据是不可变的,你可以使用内部可变性可以解决这个问题。
每当有一个共享者超出作用域,引用计数就会减 1,让引用计数减到 0 时,整个堆内存就会被释放。
Send 和 Sync
Rust 有一些特殊的标记特征,例如 Send 和 Sync。
如果一个类型实现了 Send,那就意味着数据可以从一个线程移动到另一个线程。
如果一个类型实现了 Sync,多个线程就可以使用引用去共享该数据。
Rc 没有实现 Send 和 Sync。假设两个线程在某个时间点同时拥有对某数据的引用,并且同时对该引用进行克隆。两个线程同时更新引用计数就会引发线程安全问题。
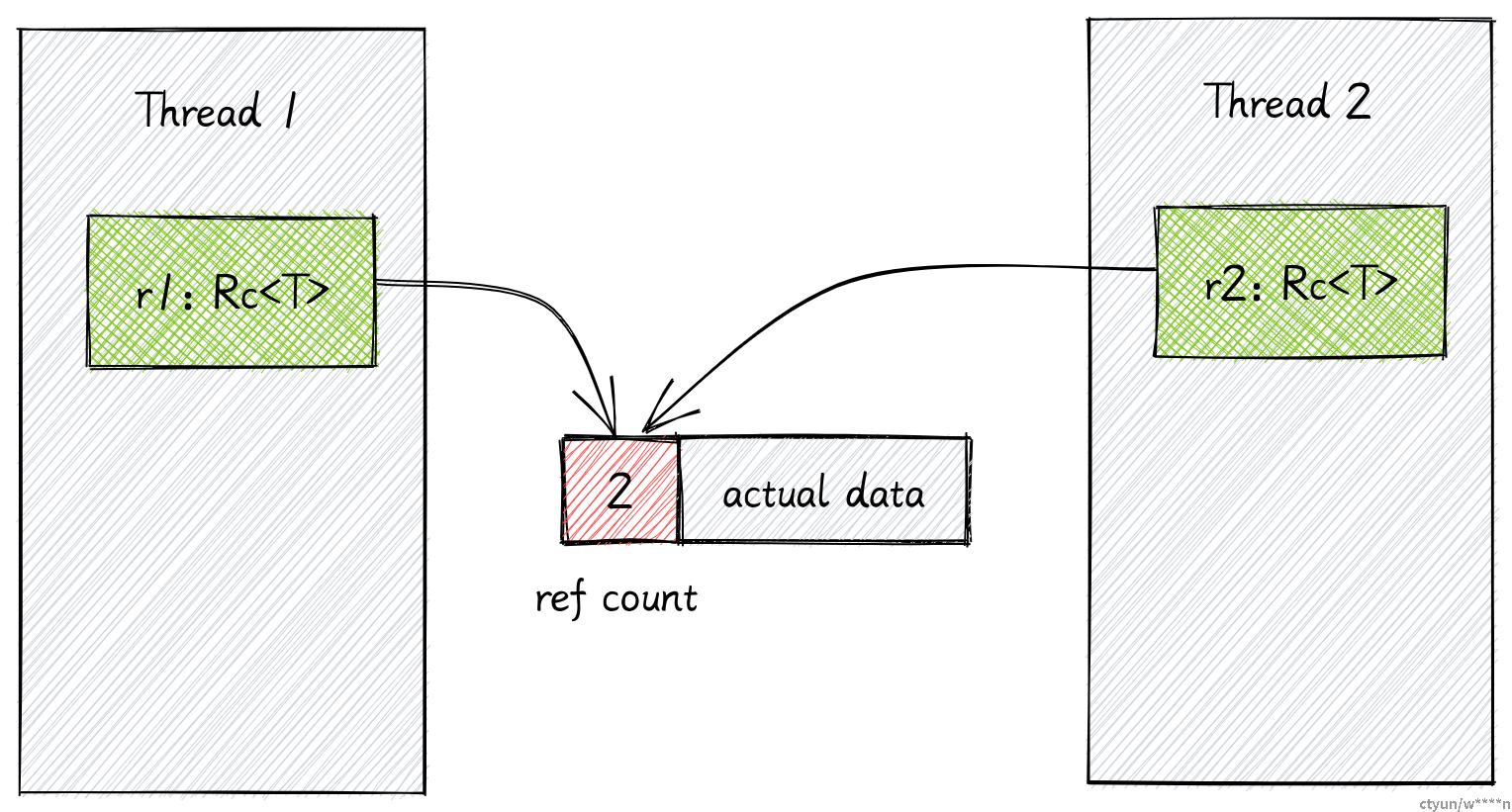
Arc
如果你真的想要在线程间共享数据,你应该使用 原子 引用计数指针 Arc。
Arc 的工作方式几乎和 Rc 相同,只是引用计数的更新是原子性的,它是线程安全的。但是原子操作会带来一些微小的性能损耗。如果你只需要在单线程内共享数据,使用 Rc 就够了。
默认情况下 Arc 也是不变的,如果你想让数据是可变的,你可以使用 Mutex。
// Arc<Mutex<T>>
let data: Arc<Mutex<i32>> = Arc::new(Mutex::new(0));现在即使有两个线程尝试同时修改数据,他们需要首先获取锁,同时只有有一个线程能拿到锁,因此只能由一个线程修改数据。
特征对象
实现了特征的实例被称为特征对象。
下面列举了将一种具体类型转化为特征对象的方法:
use std::io::Write;
let mut buffer: Vec<u8> = vec![];
let w: &mut dyn Write = &mut buffer;第一个例子中,转化发生在为变量 w 赋值时
fn main() {
let mut buffer: Vec<u8> = vec![];
writer(&mut buffer);
}
fn writer(w: &mut dyn Write) {
// ...
}第二个例子中,转化发生在将具体类型变量传递给接受特征对象的函数时
这两个例子里 Vec<u8> 类型的变量都被转化为实现了 Write 的特征对象。
Rust 用胖指针表示一个特征对象。该胖指针由两个普通指针组成,占用 2 个机器字长。
- 第一个指针指向值,这里就是
Vec<u8> - 另一个指针指向 vtable (虚表)。
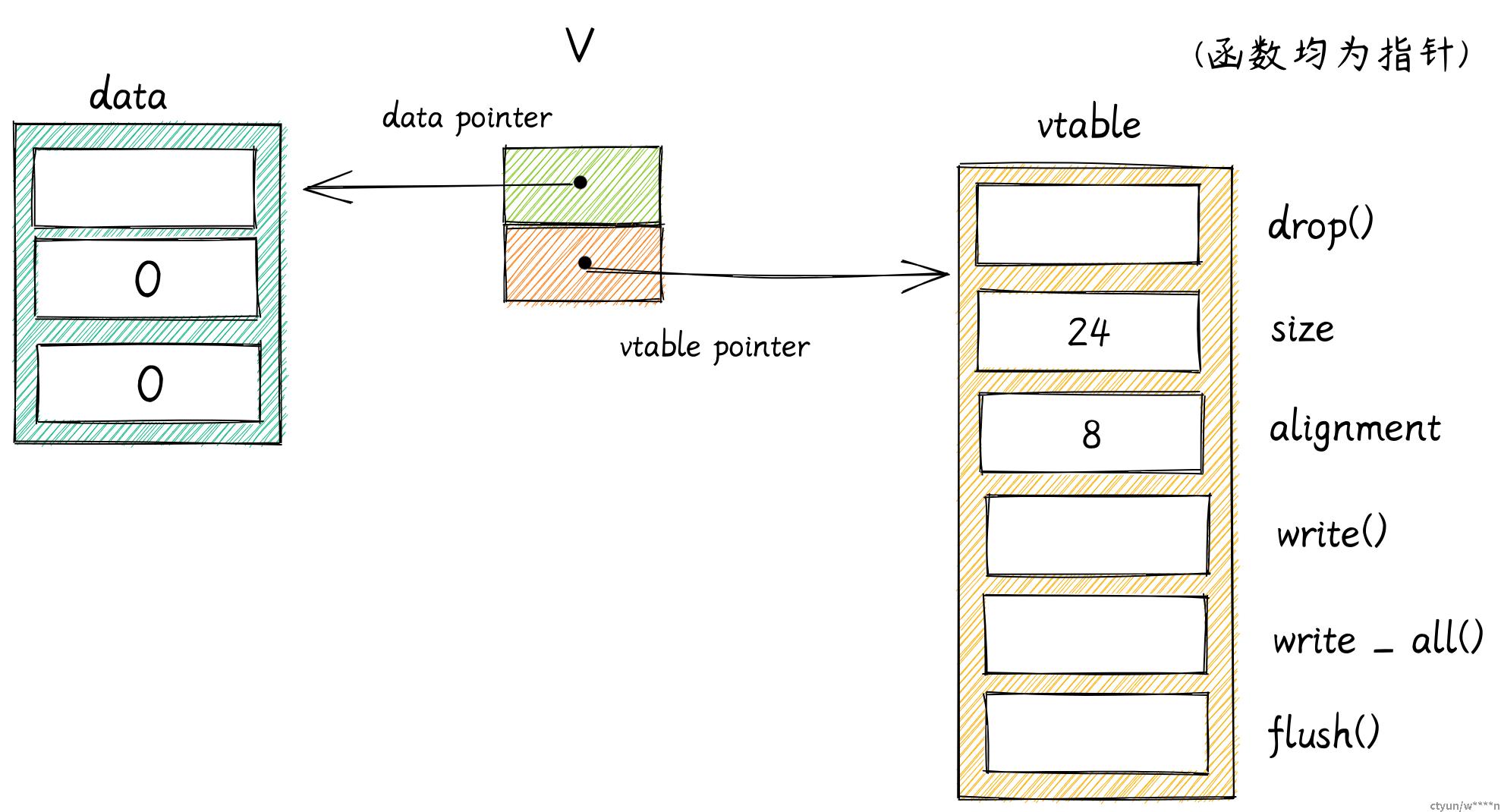
vtable 在编译时生成,被所有相同类型的对象共享。vtable 包含了实现 Writer 必须实现的方法的指针。当你在调用特征对象的方法时,Rust 自动使用 vtable 找到对应的方法。
注意:dyn Write 也是动态大小类型,因此我们总是使用它的引用,即 &dyn Write。
我们能把 Vec<u8> 转换成特征对象是因为标准库已经为它实现了 Write 特征。
impl Write for Vec<u8>Rust 不仅能将普通引用转化为特征对象,rust 也能将智能指针转换为特征对象:
// Box
use std::io::Write;
let mut buffer: Vec<u8> = vec![];
let w: Box<dyn Write> = Box::new(buffer);
// Rc
use std::io::Write;
use std::rc::Rc;
let mut buffer: Vec<u8> = vec![]
let mut w: Rc<dyn Write> = Rc::new(buffer);无论是普通引用还是智能指针,在转换发生的时候,Rust 只是添加了适当的 vtable 指针,把原始指针转换为了一个胖指针。
函数指针
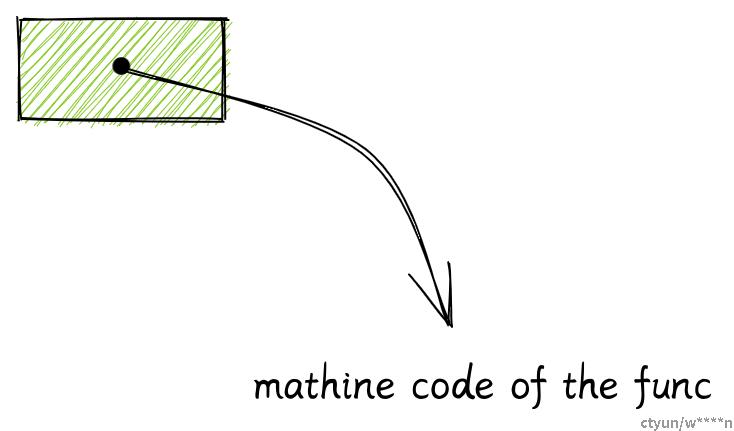
函数指针只需要一个 usize 去存储函数的地址。
test_func 是一个会返回 bool 的函数,我们可以把它存在了一个变量里。
fn main() {
let f: fn() -> bool = test_func;
}
fn test_func() -> bool {
true
}
闭包
Rust 没有具体的闭包类型,它制定了 3 个特征 Fn、FnMut、FnOnce。
FnOnce
首先是 FnOnce,create_closere 函数返回了一个实现 FnOnce 的对象
fn main() {
let c = create_closure();
}
fn create_closure() -> impl FnOnce() {
let name = String::from("john");
|| {
drop(name);
}
}在函数体内部我们创建了一个局部变量 name,它是字符串类型,在栈上占据 3 个 usize ,接着又创建了一个闭包,闭包可以捕获函数内的局部变量。在闭包内部,我们 drop 了 name。
FnOnce 只是一个特征,它只定义了一个对象的行为或方法。Rust 内部会使用结构体表示闭包,它会根据闭包捕获的变量创建对应的结构体,并为该结构体实现最合适的特征
struct MyClosure {
name: String
}
impl FnOnce for MyClosure {
fn call_once(self) {
drop(self.name)
}
}
> FnOnce特征的真实函数签名比较复杂,这里只展示一个简化版本。
结构体内部只有一个 name 字段,是闭包从 create_closure 函数内部捕获而来,call_once 是 FnOnce 特征必须实现的方法。因为闭包对应的结构体只有一个 String 类型字段,所以他的内存布局和 String 一样。
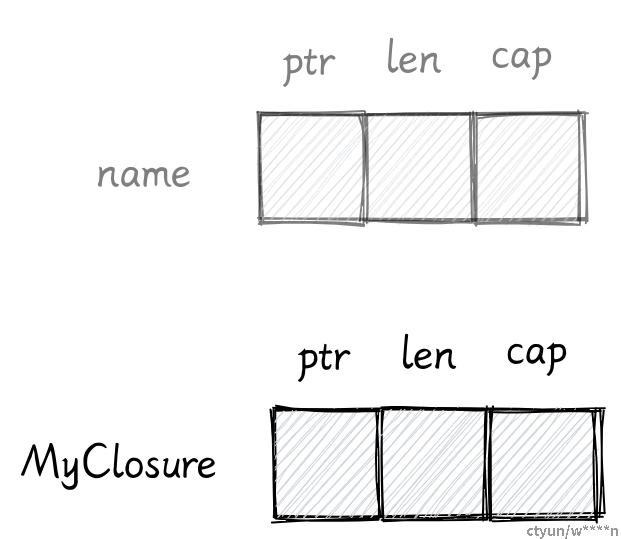
注意 call_once 函数的参数,他需要一个 self ,这意味着 call_once 只能调用一次。原因也很简单,如果我们调用两次这个闭包,拿他就会 drop name 两次。
FnMut
在这个例子里,我们创建了一个可变的闭包:
let mut i: i32 = 0;
let mut f = || {
i += 1;
};
f();
f();
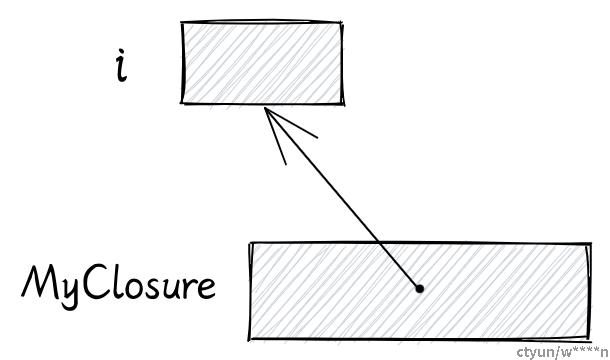
println!("{}", i); // 2这个闭包的类型是 FnMut ,因为我们在闭包里尝试修改变量 i 。因此该闭包生成的结构体中将会有一个对变量 i 的可变引用,call_mut 方法也需要一个对 self 的可变引用:
struct MyClosure {
i: &mut i32
}
impl FnMut for MyClosure {
fn call_mut(&mut self) {
*self.i += 1;
}
}
如果你在闭包 f 改为不可变的:
let f = || {
i += 1;
};就会编译失败:
error[E0596]: cannot borrow `f` as mutable, as it is not declared as mutable
--> src/main.rs:16:5
|
12 | let f = || {
| - help: consider changing this to be mutable: `mut f`
13 | i += 1;
| - calling `f` requires mutable binding due to mutable borrow of `i`
...
16 | f();
| ^ cannot borrow as mutable
For more information about this error, try `rustc --explain E0596`.错误信息提示我们,该闭包需要设为可变的
Fn
最后是 Fn 特征:
fn create_closure() {
let msg = String::from("hello");
let my_print = || {
println!("{}", msg);
};
my_print();
my_print();
}在这个例子里,我们的闭包只是打印了一下它捕获到的 msg 变量,print 宏接受的是变量的引用,所以 Rust 会自动为闭包实现 Fn 特征:
struct MyClosure {
msg: &String,
}
impl Fn for MyClosure {
fn call(&self) {
println!("{}", self.msg);
}
}生成的结构体内部只有一个对 msg 的引用。call 方法只需要一个 self 的引用,因此这个闭包能够被多次调用。
move
这个例子中我们将使用和刚刚相同的闭包,只不过是用一个函数去返回:
fn create_closure() -> impl Fn() {
let msg = String::from("hello");
|| {
println!("{}", msg);
}
}但是这样会编译错误:
error[E0597]: `msg` does not live long enough
--> src/main.rs:30:24
|
29 | || {
| -- value captured here
30 | println!("{}", msg);
| ^^^ borrowed value does not live long enough
31 | }
32 | }
| -- borrow later used here
| |
| `msg` dropped here while still borrowed
For more information about this error, try `rustc --explain E0597`.错误信息提示我们,变量 msg 的生命周期可能比闭包短。
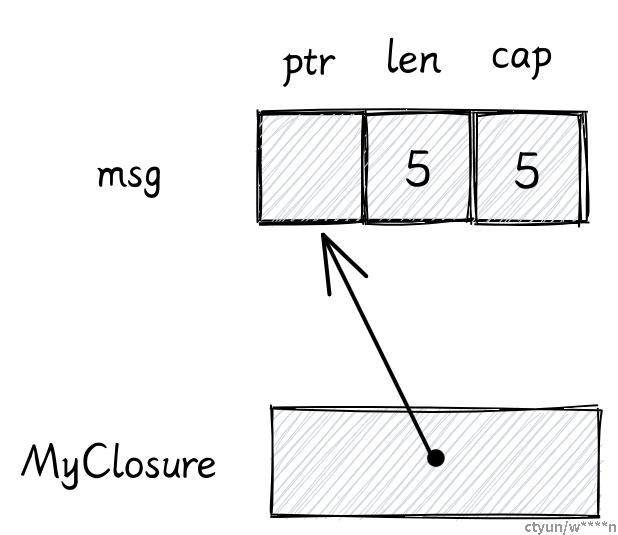
现在回想一下闭包的内存布局,闭包的结构体内部只有一个对 msg 的引用。所以当函数调用结束后,它的栈帧将被释放,闭包就不能再引用到该函数栈帧里的局部变量。
Rust 希望我们使用 move 关键字去明确表示我们想让闭包拿走闭包捕获到的变量的所有权
fn create_closure() -> impl Fn() {
let msg = String::from("hello");
move || {
println!("{}", msg);
}
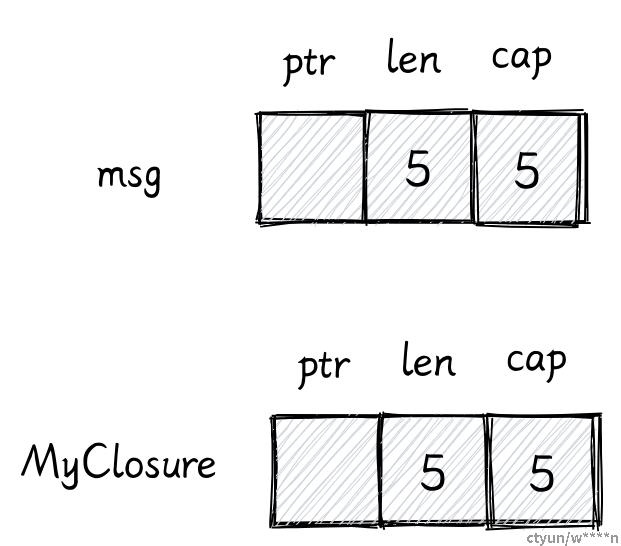
}当我们使用 move 之后,闭包的结构体就不再是引用,而是字符串本身。
struct MyClosure {
msg: String,
}
impl Fn for MyClosure {
fn call(&self) {
println!("{}", self.msg);
}
}
捕获多个变量
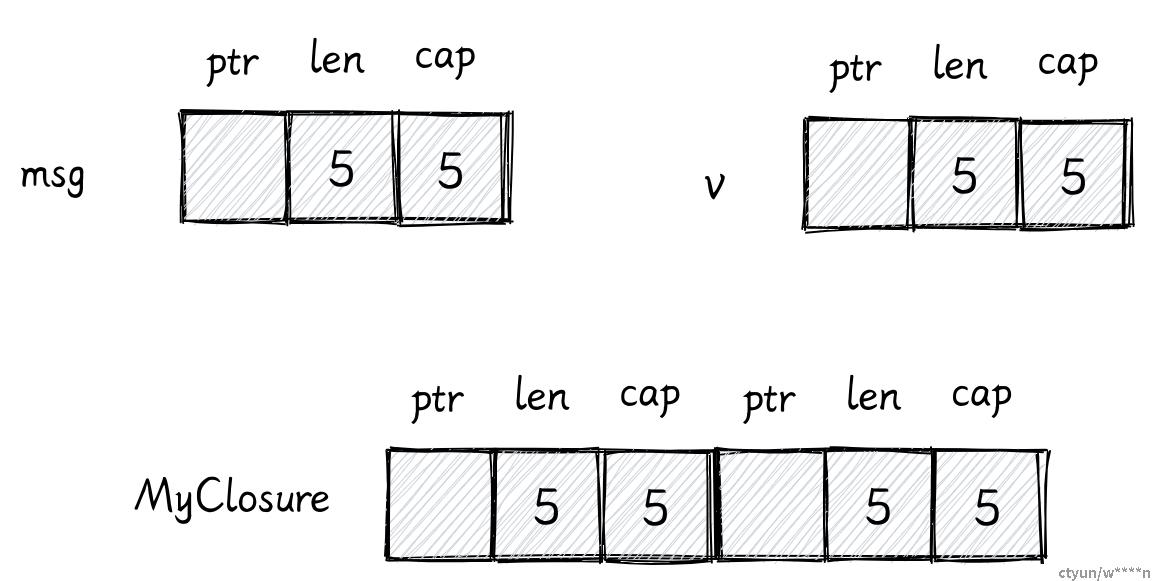
到目前为止,我们的闭包还只是捕获一个变量,在这个例子里闭包捕获了两个对象,一个字符串和一个 Vec:
fn create_closure() -> impl Fn() {
let msg = String::from("hello");
let v: Vec<i32> = vec![1, 2];
move || {
println!("{}", msg);
println!("{:?}", v);
}
}它的结构体大致如下:
struct MyClosure {
msg: String,
v: Vec<i32>,
}
impl Fn for MyClosure {
fn call(&self) {
println!("{}", self.msg);
println!("{:?}", self.v);
}
}它的内存布局和结构体的一样,并没有什么特殊的。
这个模式在其他地方也遵循,比如 异步生态中大量使用的 Future 特征。在内存中编译器会使用枚举表示实际的对象,并为这个枚举实现 Future 特征。这里不会详细讲解 Future 的实现细节,我提供了一个链接,视频里详细的解释了异步函数的实现细节。
资料
因不可插入超链接,请参加原文链接。

