


一、背景
1.什么是元数据
元数据(metadata),又称中介数据、中继数据,为描述数据的数据(data about data),主要是描述数据属性(property)的信息,用来支持如指示存储位置、历史数据、资源查找、文件记录等功能。元数据是关于数据的组织、数据域及其关系的信息,所以又被称为“关于数据的数据”。
在数据库系统中,元数据起着至关重要的作用。元数据描述了数据库对象(如:库、表、列、索引)的基本信息和数据的含义。在企业的数据库管理系统种(如:天翼云的DMS产品),很重要的功能就是采集数据库的元数据信息,将其资产化,形成企业的资产全景,并驱动各种数据应用和治理优化。本文就将围绕着元数据这个话题,介绍如何采集和存储企业数据库里的元数据。
2. 数据库中的元数据
在数据库系统中,元数据描述了数据的结构和意义。数据库设计时,数据表的名称、字段名称、字段属性、主键、索引、外键这些就是数据实体的元数据,通过这些元数据定义、描述出一个完整的数据实体。
换言之,数据库元数据就是用于描述数据库中不同对象的属性的数据定义。以大家熟悉的数据表为例,表的元数据就包含了表名、存储引擎、版本、表的行数、表的长度、自增值、排序规则等。这些元数据是描述了某张表的属性和状态,同样的,数据库、数据表列、视图、索引等也具有自身的元数据定义。下面用一张图来表示数据库常用对象的元数据模型概览。
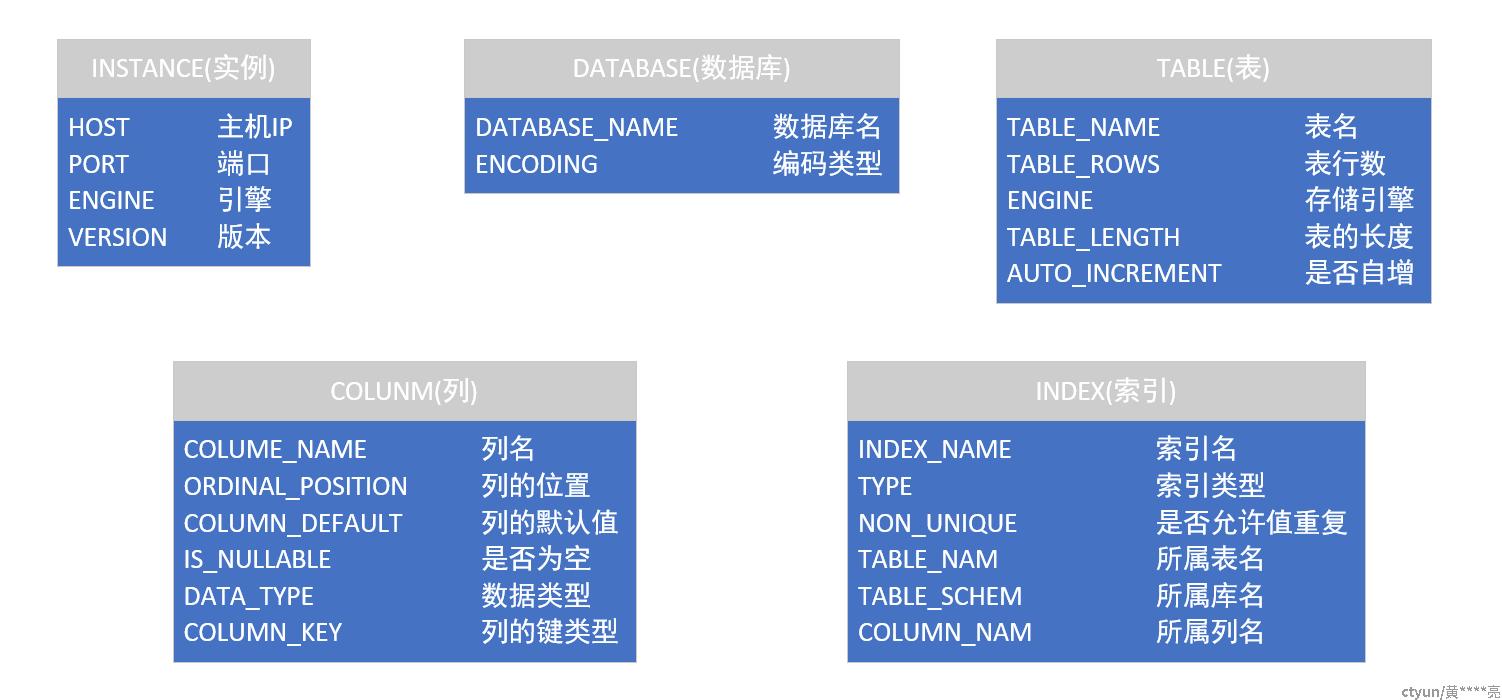
我们再来看一个例子,以常用的数据表为例,区分一下数据库中的元数据和数据的区别。
CREATE TABLE `user_info` (
`ID` int(10) unsigned NOT NULL AUTO_INCREMENT,
`NAME` varchar(32) NOT NULL,
`CREATE_TIME` datetime DEFAULT NULL,
`UPDATE_TIME` datetime DEFAULT NULL,
PRIMARY KEY (`ID`) USING BTREE,
KEY `INDEX_NAME` (`NAME`) USING HASH
) ENGINE=InnoDB AUTO_INCREMENT=13 DEFAULT CHARSET=latin1 COMMENT='用户表'
从建表语句中可以看出,该表共4列,其记录的数据内容如下所示:
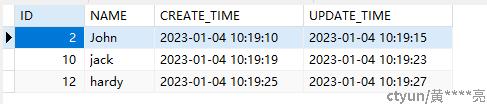
在上图中,ID、NAME我们称之为user_info表所记录的数据,那user_info表的元数据是哪些内容呢?user_info表的元数据则记录了该表的存储 擎、表的大小、表的字符集、表的主键、等信息。我们对比建表语句DDL来看一下user_info表的元数据内容。


通过上面的举例,大家对数据库的元数据应该有了基本的印象了,但由于市面和开源社区的数据源种类繁多,如果想通过数据库管理系统(DMS)工具统一管理多种不同的数据库,也就是对异构数据库的统一管理,则需要分析不同数据源在元数据模型上的差异。
3.异构数据库的元数据差异
从数据源的角度来看,市面上以及开源社区有多种数据库管理系统,如关系型数据库MySQL、PostgreSQL、Oracle、SQL Server等,NoSQL常见的有MongoDB、Redis等。不同数据库的元数据定义存在一定的差异性,因此要对异构数据库进行统一的管理,就有必要对多种不同数据库的元数据结构进行差异化分析,提炼出共性部分和差异部分,进而构建出满足异构数据库场景的存储模型,达到统一管理异构数据库的目的。
下面以MySQL,PostgreSQL和MongoDB为例,对比分析不同数据库常用逻辑对象在元数据设计方面的差异。
|
MySQL |
PostgreSQL |
MongoDB |
|
database(数据库) |
||
|
数据库名 |
数据库名 |
数据库名 |
|
字符集 |
数据库注释 |
集合数 |
|
排序规则 |
数据库所有者 |
视图数 |
|
|
排序规则 |
对象数 |
|
|
字符分类 |
|
|
schema(模式) |
||
|
/ |
模式名称 |
/ |
|
/ |
模式注释 |
/ |
|
/ |
模式所有者 |
/ |
|
/ |
所属库 |
/ |
|
table(表) |
||
|
表名 |
表名 |
表名 |
|
所属库 |
表类型 |
所有记录的内存大小 |
|
表类型 |
表所有者 |
对象或文档的数量 |
|
存储引擎 |
表行数 |
对象平均大小 |
|
表行数 |
所属模式 |
索引数量 |
|
表的长度 |
表注释 |
索引总大小 |
|
表注释 |
外部服务 |
|
|
|
外部模式 |
|
|
|
外部表 |
|
|
|
继承表 |
|
|
column(列) |
||
|
列名 |
列名 |
/ |
|
所属库 |
所属表 |
/ |
|
所属表 |
数据类型 |
/ |
|
数据类型 |
字段长度 |
/ |
|
列的精度 |
小数点位数 |
/ |
|
是否可为NULL |
默认值 |
/ |
|
列的位置 |
排序规则 |
/ |
|
列的默认值 |
维度 |
/ |
|
是否自动递增 |
是否可为NULL |
/ |
|
注释 |
注释 |
/ |
|
index(索引) |
||
|
索引名称 |
索引名 |
索引名称 |
|
所属表 |
所属表 |
是否唯一键 |
|
所属库 |
对应字段 |
是否稀疏 |
|
索引类型 |
索引方法 |
版本号 |
|
列名 |
是否唯一键 |
过期时间 |
|
索引顺序 |
注释 |
|
|
索引值是否可重复 |
约束 |
|
|
|
排序规则模式 |
|
|
|
排序规则 |
|
|
|
运算符类别模式 |
|
|
|
运算符类别 |
|
|
|
排序顺序(数字类型) |
|
分析对比异构数据库的元数据差异,其目的是为了选择合适的存储模型和对元数据进行统一管理。
二、统一元数据管理
1. 为什么需要统一元数据管理?
在大型的企业中,各类数据散落在不同的系统、存储中,他们结构各异,管理混乱。导致很多时候业务无法第一时间找到合适的数据。各平台之间的数据无法良好的管理和联动。
统一元数据管理将散落在不同来源的数据集中采集,统一管理。使用户能够全面的了解整个组织的数据资产全貌及其血缘关系,帮助企业进行数据治理。
要实现企业全域数据库的统一管理(如:DMS产品),元数据则是数据管理的基础,需要通过建立统一的数据模型,对数据库相关元数据进行定义和存储。利用存储的元数据可以构建可视化界面,从而对数据库信息进行检索,选择,定位。更进一步地,通过存储的元数据,可以拓展出数据资产地图、血缘分析,影响分析,冷热分析,关联分析等数据治理能力。
2.核心能力
一套完整的元数据管理解决方案应包含以下能力:
发现和提取:从本地或云系统自动收集元数据
元数据存储:用于存储所有业务和技术元数据的单个元数据存储
分类和世系:机器学习驱动的元数据资产分类为数据元素和视觉世系。
治理和安全:业务术语表、数据治理策略和法规遵从性都在一个平台中。
搜索和协作:跨整个数据目录进行搜索。使用评论、评分和标签进行协作。
数据质量 KPI:跟踪所有元数据上的关键数据质量指标。
集成和预配:将元数据公开为服务,通过目录预配数据访问。
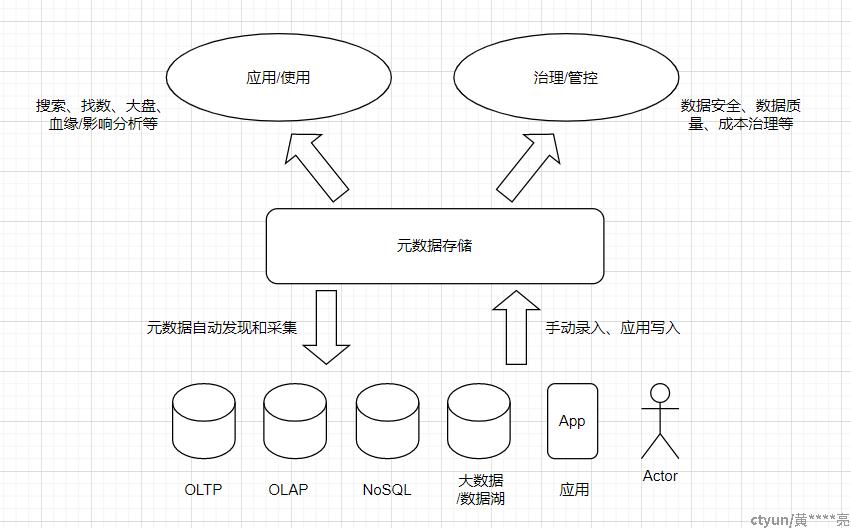
而在元数据管理中,元数据的采集和存储是所有能力的基石,正确的采集和存储元数据对接下来的分析和治理意义重大。下面部分将介绍常见的元数据采集方法。
三、元数据的采集和存储
1. 元数据的采集方法
元数据的采集方法主要分为两种,一种是通过已封装好API对元数据进行访问,如JDBC、redission、MongoClient等都有可采集元数据的API。另一种方式则是直接通过SQL语句去访问当前数据库系统的元数据库,例如访问MySQL数据库的Information_schema库。
下面以MySQL和MongoDB为例说明两种元数据的采集方式。
1.1 通过JDBC进行元数据的采集
JDBC封装了通用的API对不同的数据库进行访问,同时也提供了获取当前数据库连接的元数据的一系列API,下面对JDBC获取元数据的常用API进行详细说明。
建立连接,从数据库连接中获取元数据对象metaData,metaData包含了一些列获取数据库下级对象元数据的API。
DruidDataSource ds = new DruidDataSource();
ds.setUrl(url);
ds.setUsername(userName);
ds.setPassword(password);
ds.setDriverClassName("com.mysql.cj.jdbc.Driver");
Connection connection = ds.getConnection();
//获取元数据对象,DatabaseMetaData就是包含了元数据的集合对象
DatabaseMetaData metaData = connection.getMetaData();
获取数据库相关的元数据
//数据库url
metaData.getURL();
//数据库产品名称
metaData.getDatabaseProductName();
//数据库产品版本
metaData.getDatabaseProductVersion();
//数据库是否只读
metaData.isReadOnly();
//数据库用户名
metaData.getUserName();
获取数据库表的元数据:metaData.getTables
方法签名:
ResultSet getTables(String catalog, String schemaPattern,String tableNamePattern, String types[]) 参数说明
catalog:目录名称,一般都为空
schema:数据库名
tablename:表名称
type :表的类型(TABLE | VIEW)
代码示例
ResultSet metaDataTables = metaData.getTables(null, "test", "%", new String[]{"TABLE"});
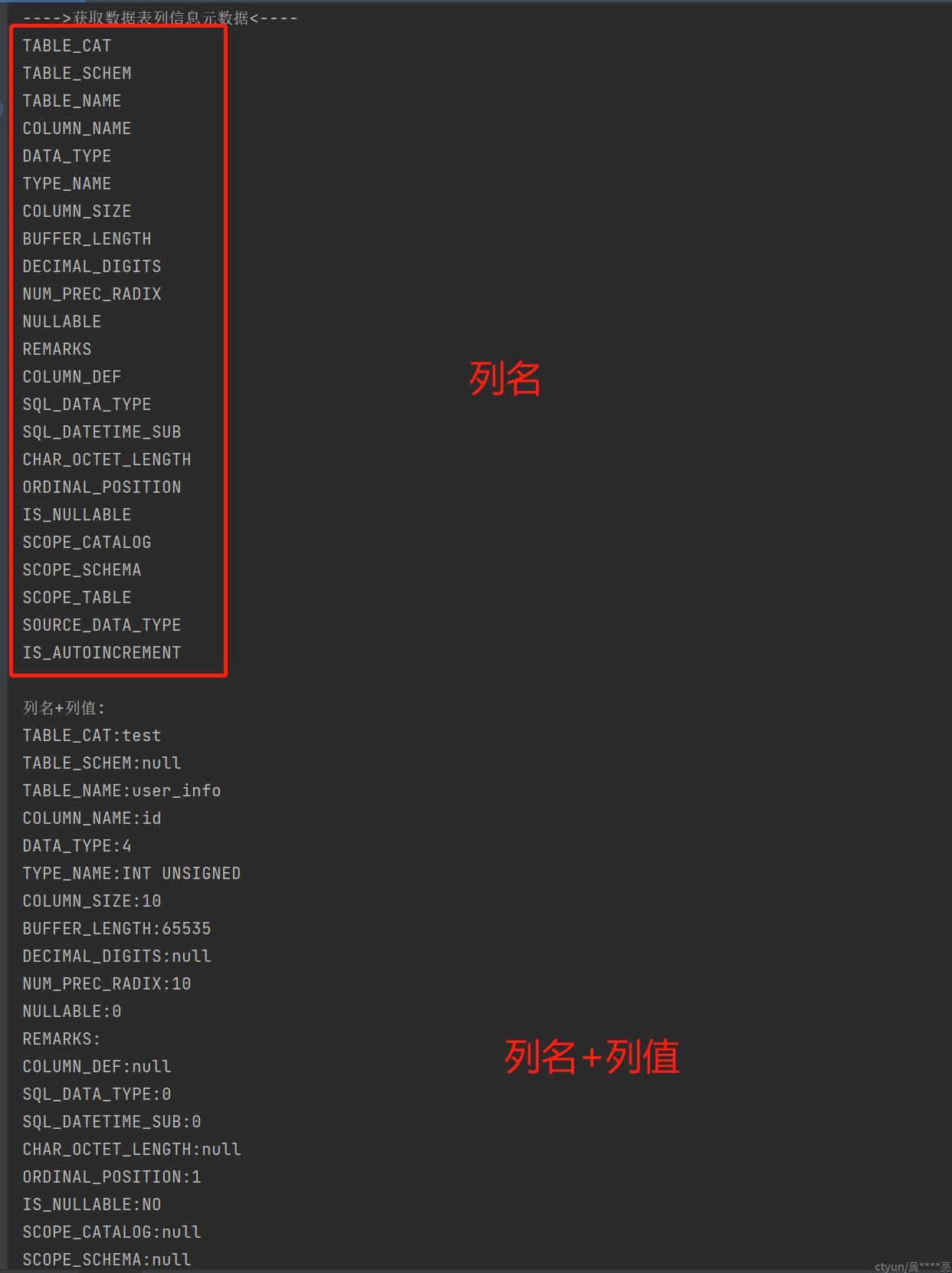
System.out.println("---->获取数据表信息元数据<----");
ResultSetMetaData tablesMetaData = metaDataTables.getMetaData();
//获取表元数据的所有列名
for(int i = 1; i < tablesMetaData.getColumnCount(); i++){
String columnName = tablesMetaData.getColumnName(i);
System.out.println(columnName);
}
//根据列名获取对应列的值
System.out.println("列名+列值:");
while (metaDataTables.next()){
for(int i = 1; i < tablesMetaData.getColumnCount(); i++){
String columnName = tablesMetaData.getColumnName(i);
System.out.println(columnName + ":" + metaDataTables.getObject(i));
}
System.out.println();
}
运行结果

表元数据列及其含义
TABLE_CAT:表目录,看结果这里存的是所在库名
TABLE_SCHEM:表模式,可能为Null
TABLE_NAME:表名称
TABLE_TYPE:表类型,如TABLE|VIEW
REMARKS:表的注释
TYPE_CAT:目录类型
TYPE_SCHEM:模式类型
TYPE_NAME:名称类型
SELF_REFERENCING_COL_NAME:类型表指定的列名称
获取表列的元数据:metaData.getColumns
方法签名
ResultSet getColumns(String catalog, String schemaPattern, String tableNamePattern, String columnNamePattern)
参数说明
catalog : 类别名称
schema : 数据库名称
tableName : 数据库表名称
columnName : 列名称
代码示例
ResultSet columnMetaData = metaData.getColumns(null, "test", "user_info", "%");
System.out.println("列名+列值:");
while (columnMetaData.next()){
for(int i = 1; i < metaDataColumn.getColumnCount(); i++){
String columnName = metaDataColumn.getColumnName(i);
System.out.println(columnName + ":" + columnMetaData.getObject(i));
}
System.out.println();
}
打印结果
表列元数据列及其含义
TABLE_CAT:目录名称
TABLE_SCHEM:表架构名称
TABLE_NAME:表名
COLUMN_NAME:列名
DATA_TYPE:数据类型
TYPE_NAME:数据类型的名称
COLUMN_SIZE:列的精度
BUFFER_LENGTH:数据的传输大小
DECIMAL_DIGITS:列的小数位数
NUM_PREC_RADIX:列的基数
NULLABLE:是否可为NULL
REMARKS:列的注释
COLUMN_DEF:列的默认值
SQL_DATA_TYPE: SQL 数据类型在描述符的 TYPE 字段中显示的值
SQL_DATETIME_SUB:datatime数据类型的子类型代码
CHAR_OCTET_LENGTH:列中的最大字节数
ORDINAL_POSITION:列在表中的位置
IS_NULLABLE:指示列是否允许NULL值
SCOPE_CATALOG:目录的范围
SCOPE_SCHEMA:模式的范围
SCOPE_TABLE:表的范围
SOURCE_DATA_TYPE:源数据类型
IS_AUTOINCREMENT:是否自动递增
获取索引的元数据:metaData.getIndexInfo
方法签名
ResultSet getIndexInfo(String catalog, String schema, String table,boolean unique, boolean approximate)
参数说明
catalog : 类别名称
schema: 数据库名称
table: 函数名称
unique: 是否只返回唯一值索引
approximate: 是否返回近似值
代码示例
//获取索引元数据
ResultSet indexInfoMetaData = metaData.getIndexInfo(null, "test", "user_info", false, false);
System.out.println("---->获取索引信息元数据<----");
ResultSetMetaData indexInfoMetaDataMetaData = indexInfoMetaData.getMetaData();
while (indexInfoMetaData.next()){
for(int i = 1; i < indexInfoMetaDataMetaData.getColumnCount(); i++){ System.out.println(indexInfoMetaDataMetaData.getColumnName(i) + ":" + indexInfoMetaData.getObject(i));
}
System.out.println();
}
打印结果
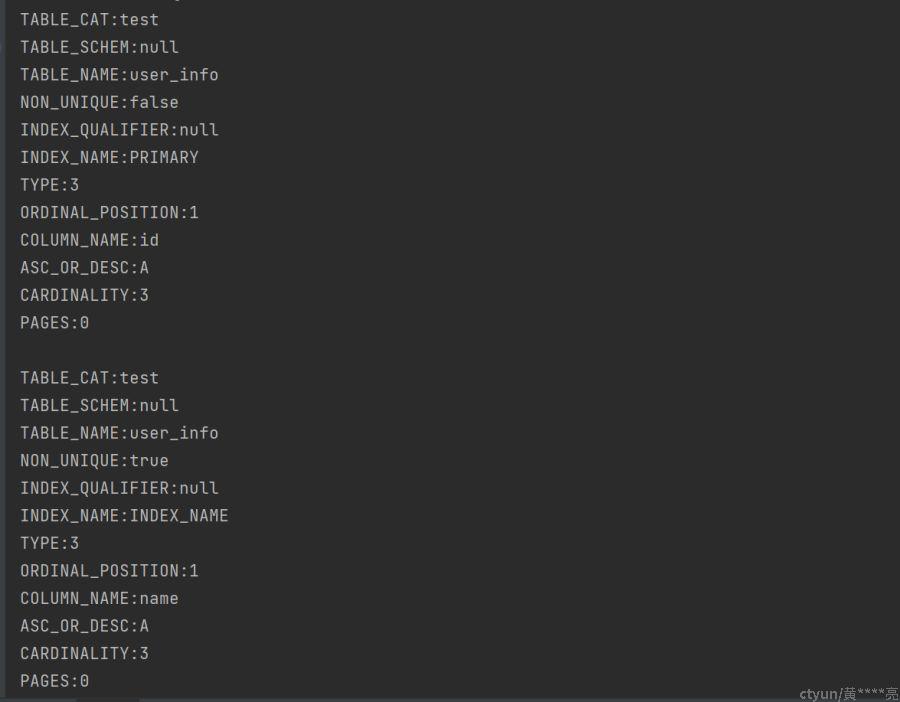
索引元数据列及其含义
TABLE_CAT:表所在的库名
TABLE_SCHEM:表的架构
TABLE_NAME:表的名称
NON_UNIQUE:指示索引值是否可以不唯一
INDEX_QUALIFIER:索引所有者的名称
INDEX_NAME:索引名称
TYPE:索引类型
ORDINAL_POSITION:列在索引的序号位置
COLUMN_NAME:列名
ASC_OR_DESC:索引排序规则中所用的顺序
CARDINALITY:表中的行数或索引中唯一值个数
PAGES:用于存储索引或表的页数
1.2 通过访问数据库系统的元数据库采集元数据
数据库管理系统都有一个元数据库来保存数据库各级对象的元数据,以MySQL为例,每个数据库的information_schema库则保存了该实例下各级对象的元数据,直接通过SQL查询的方式即可完成元数据的采集,下面举例说明。
获取数据库的元数据
数据库元数据存于information_schema.schemata表中,一行则表示一个数据库的元数据信息,查询SQL:
SELECT * FROM `INFORMATION_SCHEMA`.`SCHEMATA`
WHERE SCHEMA_NAME = "XXX";
字段列表
|
字段 |
类型 |
中文含义 |
备注 |
|
CATALOG_NAME |
varchar |
类型名称 |
如def |
|
SCHEMA_NAME |
varchar |
库名 |
|
|
DEFAULT_CHARACTER_SET_NAME |
varchar |
默认字符集名称 |
|
|
DEFAULT_COLLATION_NAME |
varchar |
默认排序规则名称 |
|
|
SQL_PATH |
varchar |
SQL路径 |
|
获取数据表的元数据
数据表元数据存于information_schema.tables表中,一行则表示一张数据表的元数据信息,查询SQL:
SELECT * FROM `INFORMATION_SCHEMA`.`TABLES`
WHERE TABLE_SCHEMA = “XXX” AND TABLE_NAME = “XXX”;
字段列表:
|
字段 |
类型 |
中文含义 |
备注 |
|
TABLE_CATALOG |
varchar |
表类型 |
如def |
|
TABLE_SCHEMA |
varchar |
所属数据库 |
|
|
TABLE_NAME |
varchar |
表名 |
|
|
TABLE_TYPE |
varchar |
表类型 |
|
|
ENGINE |
varchar |
存储引擎 |
|
|
VERSION |
bigint |
版本 |
|
|
ROW_FORMAT |
varchar |
行格式 |
如Dynamic |
|
TABLE_ROWS |
bigint |
表的行数 |
|
|
AVG_ROW_LENGTH |
bigint |
平均一行的长度 |
|
|
DATA_LENGTH |
bigint |
数据长度 |
|
|
MAX_DATA_LENGTH |
bigint |
最大行的数据长度 |
|
|
INDEX_LENGTH |
bigint |
索引长度 |
|
|
DATA_FREE |
bigint |
空闲空间 |
|
|
AUTO_INCREMENT |
bigint |
自增值 |
|
|
CREATE_TIME |
datetime |
创建时间 |
|
|
UPDATE_TIME |
datetime |
更新时间 |
|
|
CHECK_TIME |
datetime |
检查时间 |
|
|
TABLE_COLLATION |
varchar |
表的排序规则 |
|
|
CHECKSUM |
bigint |
检查次数 |
|
|
CREATE_OPTIONS |
varchar |
创建选项 |
|
|
TABLE_COMMENT |
varchar |
表备注 |
|
获取表列的元数据
数据表列元数据存于information_schema.columns表中,一行则表示一列的元数据信息,查询SQL:
SELECT * FROM `INFORMATION_SCHEMA`.`TABLES`
WHERE TABLE_SCHEMA = “XXX” AND TABLE_NAME = “XXX” AND COLUMN_NAME = “XXX”;
字段列表:
|
字段 |
类型 |
中文含义 |
备注 |
|
TABLE_CATALOG |
varchar |
表类型 |
如def |
|
TABLE_SCHEMA |
varchar |
库名 |
|
|
TABLE_NAME |
varchar |
表名 |
|
|
COLUMN_NAME |
varchar |
列名 |
|
|
ORDINAL_POSITION |
bigint |
该列的位置 |
|
|
COLUMN_DEFAULT |
longtext |
列的默认值 |
|
|
IS_NULLABLE |
varchar |
是否为NULL |
|
|
DATA_TYPE |
varchar |
数据类型 |
|
|
CHARACTER_MAXIMUM_LENGTH |
bigint |
字符类型数据的长度 |
(单位是字符) |
|
CHARACTER_OCTET_LENGTH |
bigint |
字符数据的存储长度 |
(单位是字节) |
|
NUMERIC_PRECISION |
bigint |
数字类型的长度 |
|
|
NUMERIC_SCALE |
bigint |
小数点位数 |
|
|
DATETIME_PRECISION |
bigint |
日期精度 |
|
|
CHARACTER_SET_NAME |
varchar |
字符编码名称 |
如latin1 |
|
COLLATION_NAME |
varchar |
排序规则 |
如latin1_swedish_ci |
|
COLUMN_TYPE |
longtext |
列类型 |
如varchar(32) |
|
COLUMN_KEY |
varchar |
列的建类型 |
PRI 主键 MUL非主键 |
|
EXTRA |
varchar |
其余信息 |
如自增 |
|
PRIVILEGES |
varchar |
操作权限 |
select,insert,update,references |
|
COLUMN_COMMENT |
varchar |
列的备注 |
|
|
GENERATION_EXPRESSION |
longtext |
生成表达式 |
|
获取索引的元数据
索引元数据存于information_schema.statistics表中,一行则表示一个索引的元数据信息,查询SQL:
SELECT * FROM `INFORMATION_SCHEMA`.`STATISTICS`
WHERE TABLE_SCHEMA = “XXX” AND TABLE_NAME = “XXX” AND INDEX_NAME=“XXX”;
字段列表:
|
字段 |
类型 |
中文含义 |
备注 |
|
TABLE_CATALOG |
varchar |
所属表目录 |
def |
|
TABLE_SCHEMA |
varchar |
所属表的数据库名称 |
|
|
TABLE_NAME |
varchar |
所属表名称 |
|
|
NON_UNIQUE |
bigint |
索引是否可重复 |
0 不可重复 1 可重复 |
|
INDEX_SCHEMA |
varchar |
所属数据库名称 |
|
|
INDEX_NAME |
varchar |
索引名称 |
|
|
SEQ_IN_INDEX |
bigint |
索引的序号 |
|
|
COLUMN_NAME |
varchar |
列名称 |
|
|
COLLATION |
varchar |
列在所以中的排序方式 |
A 升序 D 降序 NULL 未排序 |
|
CARDINALITY |
bigint |
索引中唯一值的数量 |
该值不一定准确 |
|
SUB_PART |
bigint |
索引前缀字符数 |
如果是前缀索引,则是索引字符的数量;如果是整列索引,则为NULL |
|
PACKED |
varchar |
打包方式 |
|
|
NULLABLE |
varchar |
该列值是否可为NULL |
YES表示可为NULL,否则不可为NULL |
|
INDEX_TYPE |
varchar |
索引类型 |
BTREE,FULLTEXT,HASH,RTREE |
|
COMMENT |
varchar |
注释 |
未在其自己的列中描述的索引信息,例如disabled是否禁用了索引 |
|
INDEX_COMMENT |
varchar |
索引注释 |
NULL |
1.3 通过Mongo Client进行元数据的采集
mongo-java-driver中封装了一些稳定的API可供元数据采集,下面对几个API进行示例。
引入mongo-java-driver依赖包,在程序中建立client连接。
ServerAddress serverAddress = new ServerAddress({IP}, {port});
MongoCredential mongoCredential = MongoCredential.createCredential({userName}, {database}, {secretKey}.toCharArray());
MongoClient client = new MongoClient(serverAddress,mongoCredential,MongoClientOptions.builder().build());
获取数据库相关元数据
MongoIterable<String> it = client.listDatabaseNames();
获取集合相关元数据
MongoDatabase database = client.getDatabase(dbName);
// 返回的集合包括了 system.views 及 视图,需要排除掉
ListCollectionsIterable<Document> it= database.listCollections();
List<String> cols = new ArrayList<>();
if (it != null){
for (Document doc : it){
String type = doc.getString("type");
if (StringUtils.equalsIgnoreCase(type, "view")){
continue;
}
String name = doc.getString("name");
if (StringUtils.equalsIgnoreCase(name, "system.views")){
continue;
}
cols.add(name);
}
}
1.4 通过Mongo Command进行元数据的采集
获取数据库详情
db.runCommand({dbStats : 1,scale : 1})
字段列表
|
dbName |
库名 |
|
collectionCount |
集合数 |
|
viewCount |
视图数 |
|
objectCount |
对象数量 |
|
avgObjSize |
平均对象大小 |
|
dataSize |
数据总大小 |
|
storageSize |
文档总大小 |
|
indexCount |
索引数量 |
|
indexSize |
索引总大小 |
|
totalSize |
总大小 |
获取集合详情
db.runCommand({collStats : 'colName',scale : 1024})
字段列表:
|
dbName |
库名 |
|
collectionName |
集合名 |
|
memorySize |
所有记录的内存大小
|
|
objectCount |
对象或文档的数量
|
|
avgObjSize
|
对象平均大小
|
|
storageSize
|
所有文档的总大小 不包括索引 |
|
storageSize
|
索引数量
|
|
indexCount
|
索引数量
|
|
totalIndexSize
|
索引总大小
|
|
capped
|
是否是 capped
|
|
maxSize
|
capped 时最大值
|
|
max
|
capped 时最大文档数量
|
|
autoIndexId
|
是否 自动索引id
|
|
usePowerOf2Sizes
|
使用2的次方大小
|
|
noPadding
|
没有填充
|
|
validationLevel
|
验证级别
|
|
validationAction
|
验证动作 |
2.元数据的统一存储方案
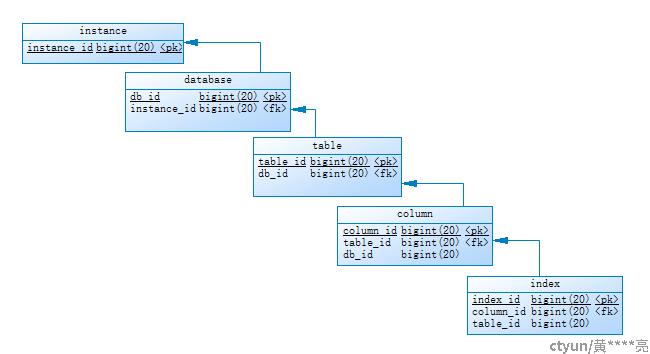
2.1 结构化存储(RDS)
简单直接的方式,则是用关系型数据库对数据库的元数据进行存储,只需要通过分层记录不同数据库下级对象的元数据,保留1-N的关联关系即可。如下图所示:
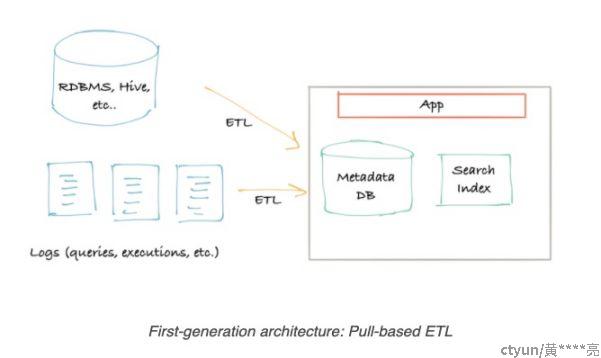
为进一步提高搜索效率,还可以引入搜索引擎等组件。
例如:DataHub的第一代架构Pull-based ETL (基于Pull-ETL模式)。整体架构会简单些,采用单体架构。通常会利用爬取方式定时抓取并结构化数据,存储在一个便于检索的主存储,和搜索引擎(ES)中,提供一前端展示数据并支持简单检索。
2.2 宽表方案(HBase)
Apache Atlas架构:
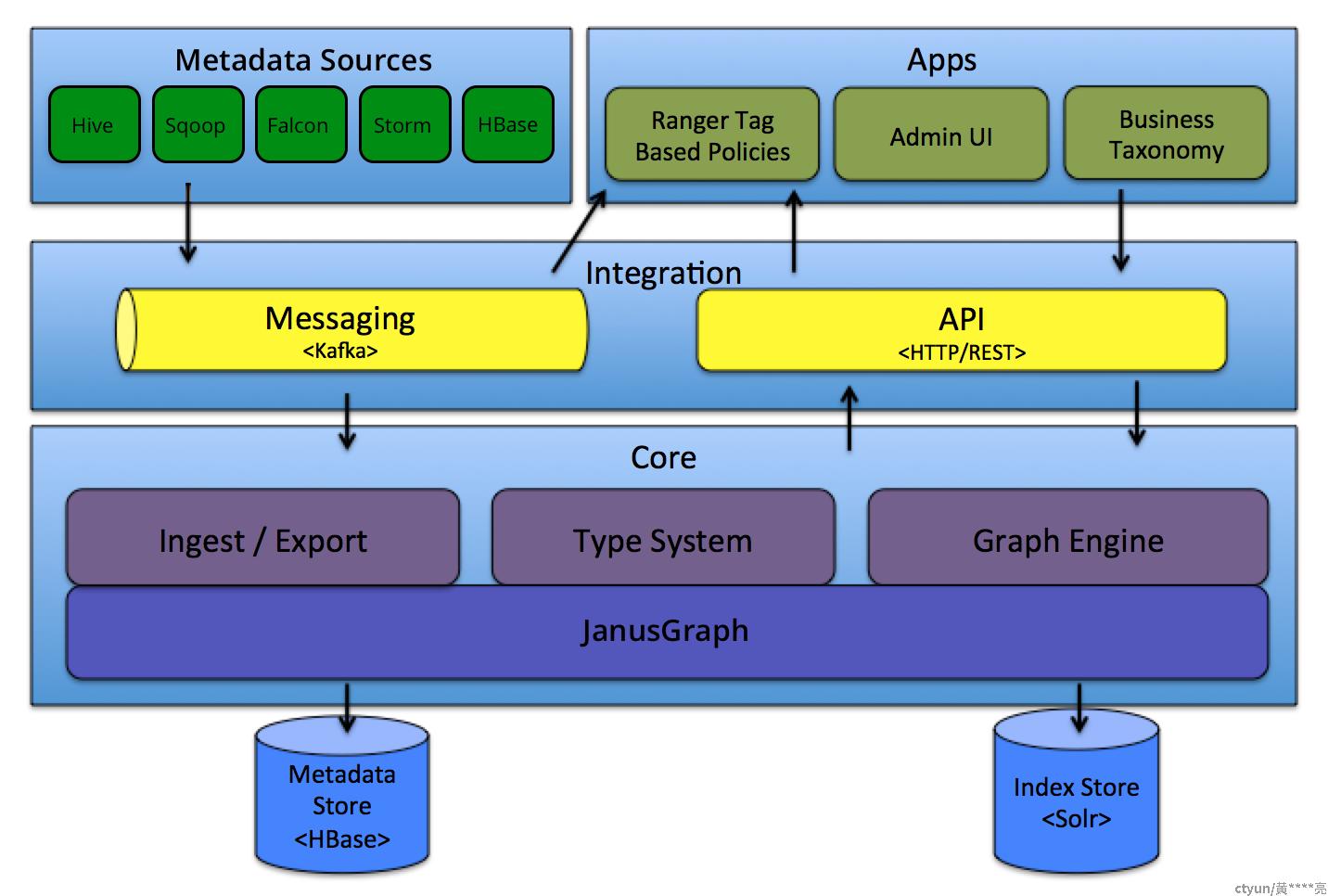
Atlas官网:https://atlas.apache.org/#/Architecture
Atlas来自大数据生态,是数据治理方向流行的开源软件。Atlas抽象出了实体(entity)和关系(relationship)的概念,实体又有类型(entity type),类似于面向对象编程里的类(class)和对象(object)。通过实体类型,可以描述各种元数据的实体,如:库、表、列。下面是一个Atlas里描述Hive table的例子:

类型中包含一系列属性(attribute),并且属性也有类型,可关联到其他的实体(类似于嵌套),如:上图中的db属性属于hive_db类型。
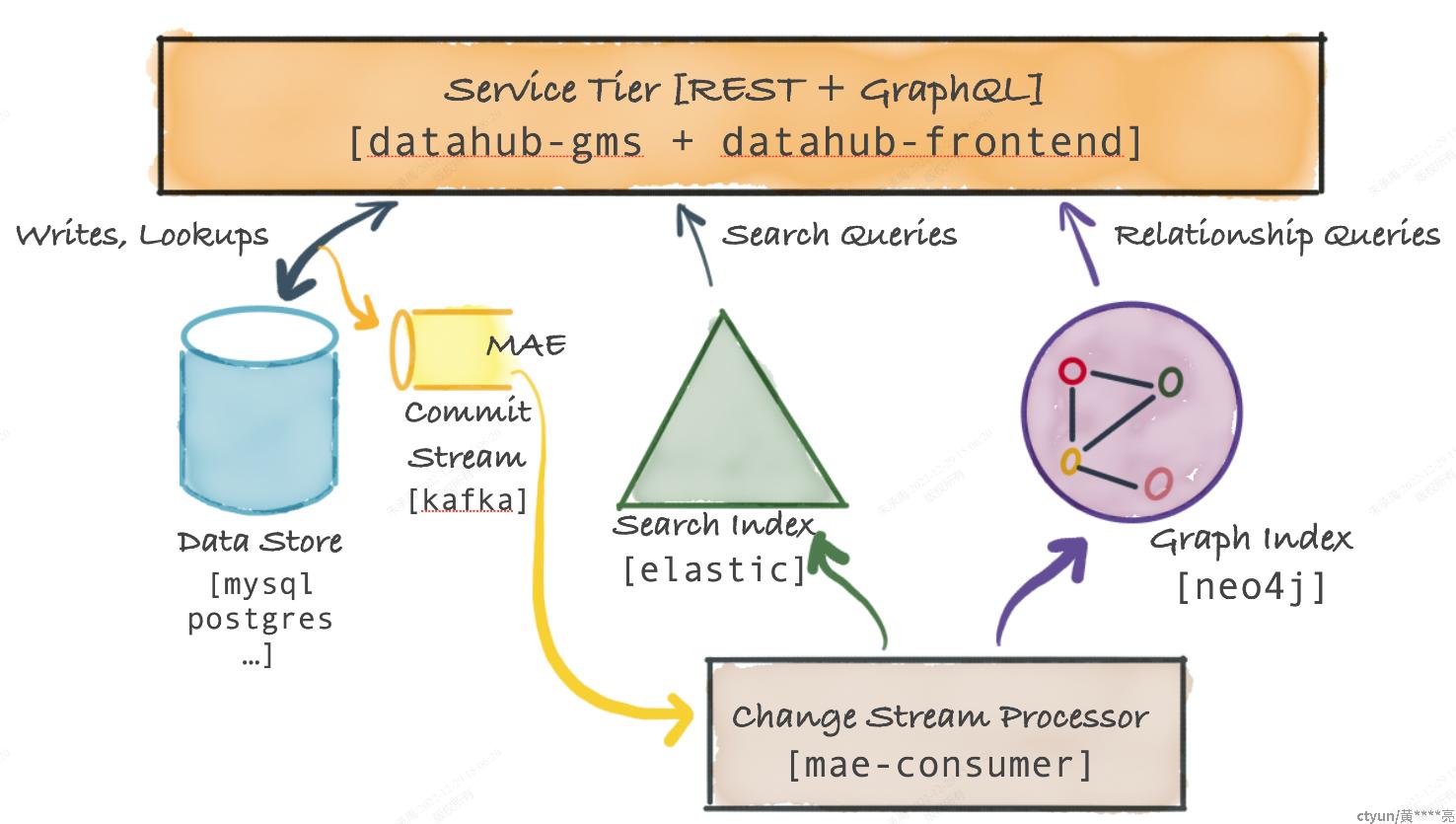
2.3 混合存储方案(Datahub)
DataHub官网:https://datahubproject.io/docs/metadata-modeling/metadata-model
元数据模型与Atlas非常类似,也是主要由实体(entity)和关系(relationship)组成。实体由类型、唯一标识(identifier)和一系列的属性组成,其中属性也被称为aspect。关系是连接实体间的边,关系是有名字的。下图是个实体和关系的例子:
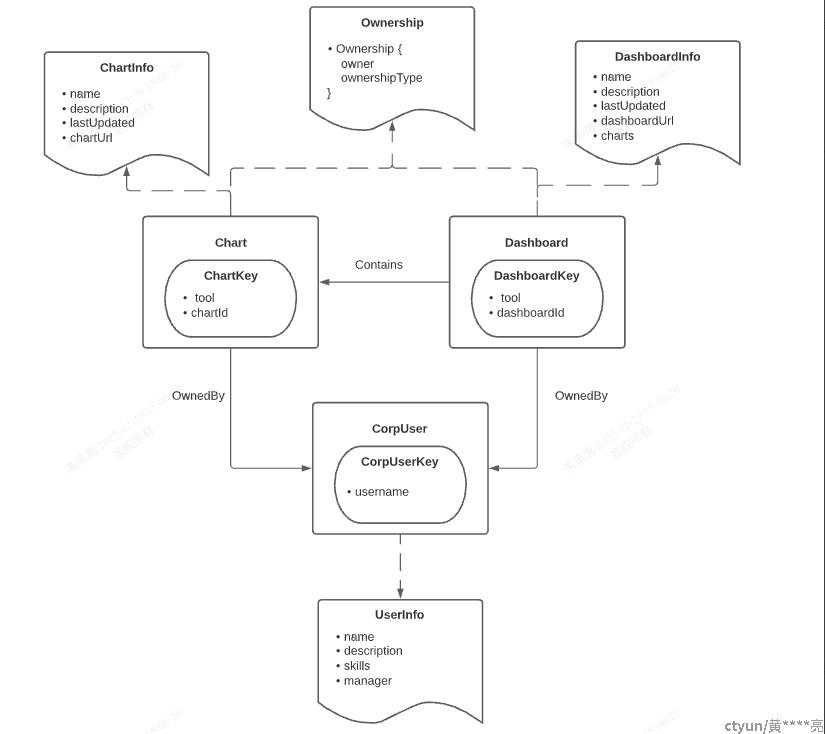
元数据的存储采用混合方案,元数据首先写入数据库中(如:MySQL/PG/Cassandra),元数据的变更(Metadata Change Log)会同步至搜索引擎和图引擎中,分别用于实体搜索和关系搜索。若只是按主键查找元数据,则直接访问数据库获得。
3. 存储方案对比
前面介绍了三种不同的存储方案,分别是结构化存储、宽表方法和混合存储方案,这三种存储方案各有优缺点,接下来我们简单对比分析一下:
结构化存储方案
优点:
1、易于维护,都是使用表结构,格式一致;
2、使用方便,SQL语言通用,可用于复杂查询;
3、快速上手,架构简单,很方便地整合开源框架如SpringBoot、Mybatis等。
不足:
1、写性能较差,不擅长大量数据的写入处理;
2、结构固定,不擅长数据更新的表做索引或表结构变更;
3、在模糊查询和多表关联查询方面的效率较低;
4、因不同数据源的元数据差异,采用统一的表结构存储则不可避免地会存在空值字段,存在存储空间上的浪费。
宽表方案
优点:
1、存储结构灵活,可以适配不同的元数据模型,采用“实体”作为存储模型具有很强的扩展性;
2、利用HBase的多版本能力能够保存元数据的历史版本;
缺点:
1、学习和维护成本较高,目前成熟的实践案例仍比较少;
混合存储方案
优点:
1、功能强大,根据应用场景的需要来选择搜索的方式;
2、简单查询和复杂查询都能高效完成;
3、复杂查询直接走搜索引擎,支持大数据量的查询场景。
缺点:
1、架构复杂,需要同时搭配多个中间件使用;
2、维护成本高,由于架构组件较多,对服务的监控和维护难度也随之增加。
下面用一个表格来总结不同存储方法的优点和不足:
|
存储方案 |
优点 |
不足 |
|
结构化存储 |
架构简单,方便易用 |
在模糊查询和多条件关联表查询等方面性能较差;存在存储空间上的浪费 |
|
宽表方案 |
模型通用,存储结构较灵活,空列不会占用额外的存储空间,扩展性强,适合存储海量数据 |
学习和维护的成本相对较高,不能支持条件查询,因HBase的计算能力不足,需引入计算引擎来支持业务 |
|
混合存储方案 |
引入搜索引擎来解决复杂查询的性能问题,支持海量数据的搜索场景 |
架构较为复杂,维护成本较高 |
四、总结
现如今,数据日益增长,大数据时代到来,如何挖掘、发挥数据的价值成为技术关注的焦点。在此之上衍生出了数据治理的概念:数据治理的最终目标是提升数据的价值,数据治理非常必要,是企业实现数字战略的基础,它是一个管理体系,包括组织、制度、流程、工具。想要合理、正确、有价值地实现数据治理,关键就是元数据管理。
正如企业级数据管理软件提供商Informatica公司认为:数据治理成功的关键在于元数据管理,即赋予数据上下文和含义的参考框架。经过有效治理的元数据可提供数据流视图、影响分析的执行能力、通用业务词汇表以及其术语和定义的可问责性,最终提供用于满足合规性的审计跟踪。元数据管理成为一项重要功能,让IT部门得以监视复杂数据集成环境中的变化,同时交付可信、安全的数据。因此,良好的元数据管理工具在全局数据治理中起到了核心作用。
如果没有良好的元数据管理,数据缺乏透明度、可审计性以及数据的标准化与重复利用能力。容易出现数据孤岛,数据治理将难以为继。
本文从DMS统一数据库管理的角度去深入分析了数据库元数据的采集和存储问题,这也将是如何设计打造一款好用且高效的数据库管理工具的基础。通过采集元数据,合理地设计元数据管理的数据模型,以及选择高效的存储方案,将从性能、应用等方方面面利于数据的管理、统计、应用、发掘价值等,使企业数据治理更为便利、合理,也更加可持续。从企业的角度出发,企业也更加注重降本增效,可持续性将贯穿各企业的发展过程,做好元数据管理,支撑好数据治理,这将为企业更加明确发展道路提供有效的手段和途径。
围绕着统一数据库管理和DMS产品,我们后续将推出一系列的文章对其中的关键技术进行剖析,敬请期待。
