


前言
在阅读本文之前,建议先看看调度框架官方文档和调度框架设提案,也有必要先看看调度插件,便于理解本文内容。
本文提取以官方文档中笔者认为比较重要的信息,并做了批注:
- kubernetes-scheduler已添加了许多功能,这使得代码越来越大,逻辑也越来越复杂。一个复杂的调度程序很难维护,其错误也很难找到和修复,并且那些自己修改调度程序的用户很难赶上并集成新的版本更新。当前kube-scheduler提供了webhooks来扩展器功能(Extender),但是能力有限。调度器功能越来越复杂,很难维护,虽然有http接口的Extender扩展,但是使用非常受限并且效率不高(详情笔者会在解析Extender的文章中介绍),所以就有了插件化的调度框架
- 调度框架是kube-scheduler的一种插件化设计架构,他将一组新的‘插件’APIs添加到现有的调度器中,插件是在调度器中编译好的(没有动态库方式灵活)。这些APIs允许大多数调度功能以插件的形式实现,同时使调度‘核心’保持简单且易于维护。这句话怎么理解呢?就是大部分的调度功能(比如亲和性、资源均匀调度)都是有插件实现的,而且调度器只需要按照调度框架设计的流程执行即可。
- 每次调度一个Pod都分为两个周期,即调度周期和绑定周期。调度周期为Pod选择一个Node,绑定周期将该决策应用于集群。调度周期是串行运行的,而绑定周期可能是同时运行的。如果确定Pod不可调度或者存在内部错误,则可以终止调度周期或绑定周期。Pod将返回调度队列并重试。调度周期是单协程的,按阶段先后、插件配置顺序串行调用,绑定周期因为有存储写入操作,所以需要异步执行,否则调度效率就太低了。所谓决策应用于集群就是向apiserver写一个API对象,集群内需要watch这类对象的服务就能感知到
- 调度框架定义了一些扩展点,插件注册后在一个或多个扩展点被调用,这些插件中的一些改变调度决策,而另一些仅用于提供信息。所谓扩展点就是插件接口,因为可以按需实现各种各样的插件,所以称之为‘扩展’;而‘点’就是从调度队列的排序一直到Pod绑定的后处理一共有11个节点(也称之为阶段phase)。至于有的改变决策,有的提供信息很好理解,比如,PreXxxPlugins都是提供信息的,而Xxx都是改变决策的。
下图是调度框架的设计图,源于官方文档,结合图和调度插件,就会基本了解kubernetes的调度框架。
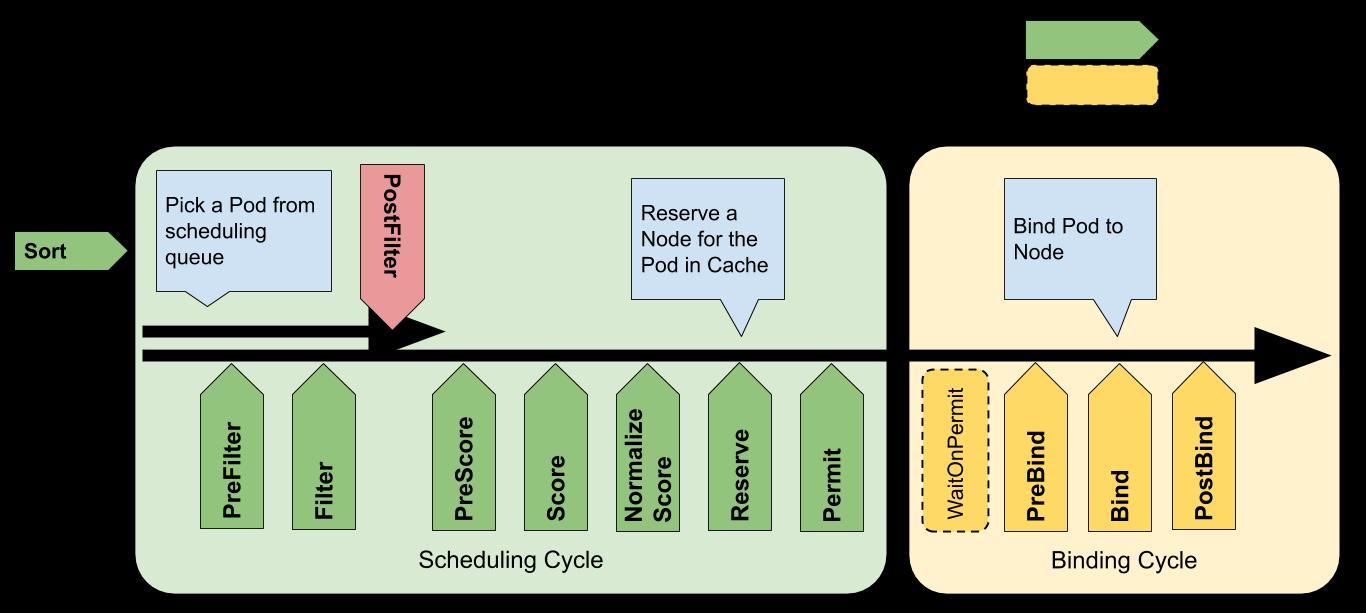
本文结合官方文档与源码解析调度框架的实现,引用源码为kubernetes的release-1.20分支。
调度框架
Handle
句柄的概念在C/C++语言中比较常用,一般都是某个对象的指针,出于安全考虑句柄也可以是一个键,然后把对象放在容器里(比如map)。调度框架的句柄Handle就是调度框架的指针(详情见后文),句柄是提供给调度插件(在插件注册表章节有介绍)使用的。因为调度插件的接口参数只包含PodInfo、NodeInfo、以及CycleState,如果调度插件需要访问其他对象只能通过调度框架句柄。比如绑定插件需要的Clientset、抢占调度插件需要的SharedIndexInformer、批准插件需要的等待Pod访问接口等等。
现在来看看调度框架的句柄是怎么定义的,源码链接:https://github.com/kubernetes/kubernetes/blob/release-1.20/pkg/scheduler/framework/interface.go#L515
type Handle interface {
// SharedLister是基于快照的Lister,这个快照就是在调度Cache文章中介绍的NodeInfo的快照。
// 此处不扩展对SharedLister进行说明,只要有调度Cache的基础就可以了,无非是NodeInfo快照基础上抽象新的接口。
// 在调度周期开始时获取快照,保持不变,直到Pod完成'Permit'扩展点为止,在绑定阶段是不保证快照不变的。
// 因此绑定周期中插件不应使用它,否则会发生并发度/写错误的可能性,它们应该改用调度Cache。
SnapshotSharedLister() SharedLister
// 此处需要说明一下WaitingPod,就是在'Permit'扩展点返回等待的Pod,需要Handle的实现提供访问这些Pod的接口。
// 遍历等待中的Pod。
IterateOverWaitingPods(callback func(WaitingPod))
// 通过UID获取等待中的Pod
GetWaitingPod(uid types.UID) WaitingPod
// 拒绝等待中的Pod
RejectWaitingPod(uid types.UID)
// 获取Clientset,用于创建、更新API对象,典型的应用就是绑定Pod。
ClientSet() clientset.Interface
// 用于记录调度过程中的各种事件
EventRecorder() events.EventRecorder
// 当调度Cache和队列中的信息无法满足插件需求时,可以利用SharedIndexInformer获取指定的API对象。
// 比如抢占调度插件需要获取所有运行中的Pod。
SharedInformerFactory() informers.SharedInformerFactory
// 获取抢占句柄,只开放给实现抢占调度插件的句柄,用来协助实现抢占调度,详情见后面章节注释。
PreemptHandle() PreemptHandle
}
句柄存在的意义就是为插件提供服务接口,协助插件实现其功能,且无需提供调度框架的实现。虽然句柄就是调度框架指针,但是interface的魅力就在于使用者只需要关注接口的定义,并不关心接口的实现,这也是一种解耦方法。
PreemptHandle
抢占句柄是专为抢占调度插件(PostFilterPlugin)设计的的接口,试想一下我们自己实现抢占调度需要抢占句柄提供什么能力:1)PodNominator记录了所有提名(抢占成功但还在等待被强占Pod退出)的Pod,所以抢占句柄至少应该包含PodNominator接口供插件使用(比如获取已经提名的但是比当前Pod优先级低的Pod);2)抢占调度插件需要能够运行Filter、Score等插件才能评估抢占是否成功。 接下来就看看抢占句柄的定义,源码链接:https://github.com/kubernetes/kubernetes/blob/release-1.20/pkg/scheduler/framework/interface.go#L552
type PreemptHandle interface {
// PodNominator是必须的,他可以获取提名到Node的所有Pod
PodNominator
// PluginsRunner下面有注释,用来运行插件评估抢占是否成功并选择最优Node
PluginsRunner
// Extenders笔者会专门写一篇文章介绍它,此处只需要知道它的实现是一个HTTP的服务,用来扩展kubernetes无法管理的资源的调度能力。
Extenders() []Extender
}
// PluginsRunner运行某些插件,用于抢占调度插件评估Pod是否可以通过抢占其他Pod的资源运行在Node上。
type PluginsRunner interface {
// RunXxxPlugins按照配置的插件循序运行Xxx扩展点的插件。
// 从接口定义来看只有过滤(包括前处理)和评分(包括前处理)的插件,非常合理。
// 因为抢占实现逻辑和普通的调度一样,都是过滤后再评分,不同的地方无非是多了被强占Pod的处理。
RunPreScorePlugins(context.Context, *CycleState, *v1.Pod, []*v1.Node) *Status
RunScorePlugins(context.Context, *CycleState, *v1.Pod, []*v1.Node) (PluginToNodeScores, *Status)
RunFilterPlugins(context.Context, *CycleState, *v1.Pod, *NodeInfo) PluginToStatus
RunPreFilterExtensionAddPod(ctx context.Context, state *CycleState, podToSchedule *v1.Pod, podToAdd *v1.Pod, nodeInfo *NodeInfo) *Status
RunPreFilterExtensionRemovePod(ctx context.Context, state *CycleState, podToSchedule *v1.Pod, podToRemove *v1.Pod, nodeInfo *NodeInfo) *Status
}
Framework定义
前言已经详细说明了调度框架产生的原因以及相关的设计思想,此处直接上代码,源码链接:https://github.com/kubernetes/kubernetes/blob/release-1.20/pkg/scheduler/framework/interface.go#L412
type Framework interface {
// 调度框架句柄,构建调度插件时使用
Handle
// 获取调度队列排序需要的函数,其实就是QueueSortPlugin.Less()
QueueSortFunc() LessFunc
// 有没有发现和PluginsRunner很像?应该说PluginsRunner是Framework的子集,也可以理解为Framework的实现也是PluginsRunner的实现。
//Framework这些接口主要是为了每个扩展点抽象一个接口,因为每个扩展点有多个插件,该接口的实现负责按照配置顺序调用插件。
// 大部分扩展点如果有一个插件返回不成功,则后续的插件就不会被调用了,所以同一个扩展点的插件间大多是“逻辑与”的关系。
RunPreFilterPlugins(ctx context.Context, state *CycleState, pod *v1.Pod) *Status
RunFilterPlugins(ctx context.Context, state *CycleState, pod *v1.Pod, nodeInfo *NodeInfo) PluginToStatus
RunPostFilterPlugins(ctx context.Context, state *CycleState, pod *v1.Pod, filteredNodeStatusMap NodeToStatusMap) (*PostFilterResult, *Status)
RunPreFilterExtensionAddPod(ctx context.Context, state *CycleState, podToSchedule *v1.Pod, podToAdd *v1.Pod, nodeInfo *NodeInfo) *Status
RunPreFilterExtensionRemovePod(ctx context.Context, state *CycleState, podToSchedule *v1.Pod, podToAdd *v1.Pod, nodeInfo *NodeInfo) *Status
RunPreScorePlugins(ctx context.Context, state *CycleState, pod *v1.Pod, nodes []*v1.Node) *Status
RunScorePlugins(ctx context.Context, state *CycleState, pod *v1.Pod, nodes []*v1.Node) (PluginToNodeScores, *Status)
RunPreBindPlugins(ctx context.Context, state *CycleState, pod *v1.Pod, nodeName string) *Status
RunPostBindPlugins(ctx context.Context, state *CycleState, pod *v1.Pod, nodeName string)
RunReservePluginsReserve(ctx context.Context, state *CycleState, pod *v1.Pod, nodeName string) *Status
RunReservePluginsUnreserve(ctx context.Context, state *CycleState, pod *v1.Pod, nodeName string)
RunPermitPlugins(ctx context.Context, state *CycleState, pod *v1.Pod, nodeName string) *Status
RunBindPlugins(ctx context.Context, state *CycleState, pod *v1.Pod, nodeName string) *Status
// 如果Pod正在等待(PermitPlugin返回等待状态),则会被阻塞直到Pod被拒绝或者批准。
WaitOnPermit(ctx context.Context, pod *v1.Pod) *Status
// 用来检测Framework是否有FilterPlugin、PostFilterPlugin、ScorePlugin,没难度,不解释
HasFilterPlugins() bool
HasPostFilterPlugins() bool
HasScorePlugins() bool
// 列举插件,其中:
// 1. key是扩展点的名字,比如PreFilterPlugin对应扩展点的名字就是PreFilter,规则就是将插件类型名字去掉Plugin;
// 2. value是扩展点所有插件配置,类型是slice
ListPlugins() map[string][]config.Plugin
// 此处需要引入SchedulingProfile概念,SchedulingProfile允许配置调度框架的扩展点。
// SchedulingProfile包括使能/禁止每个扩展点的插件,每个插件的权重(仅在Score扩展点有效)以及插件参数;
// 这个接口是用来获取SchedulingProfile的名字,因为v1.Pod.Spec.SchedulerName就是指定SchedulingProfile名字来选择Framework。
ProfileName() string
}
从Framework的接口定义基本可以推测它的画像:
- Framework是根据SchedulingProfile创建的,是一对一的关系,Framework中插件的使能/禁止、权重以及参数都来自SchedulingProfile;
- Framework按照调度框架设计图中的扩展点依次提供了运行所有插件的RunXxxPlugins()接口,扩展点插件的调用顺序也是通过SchedulingProfile配置的;
- 一个Framework就是一个调度器,配置好的调度插件就是调度算法(可以从kubernetes/pkg/scheduler/algorithmprovider的包名看出当时设计者的想法),kube-scheduler按照固定的流程调用Framework接口即可,这样kube-scheduler就相对简单且易于维护;
此处用一个不太恰当的比喻:Framework类似于动态库的接口定义,每个SchedulingProfile对应一个实现了Framework接口的动态库,而SchedulingProfile名字就是动态库的名字。kube-scheduler按需加载动态库,然后按照Pod选择的Framework执行调度。这是C/C++视角的理解,虽然kube-scheduler的插件都是静态编译,然后通过配置动态生成,但是原理上是相同的,只要有助于理解就可以。
Framework实现
frameworkImpl
为什么称之为框架?因为他是固定的,差异在于配置导致插件的组合不同。也就是说,即便有多个SchedulingProfile,但是只有一个Framework实现,无非Framework成员变量引用的插件不同而已。来看看Framework实现代码,源码链接:https://github.com/kubernetes/kubernetes/blob/release-1.20/pkg/scheduler/framework/runtime/framework.go#L66
type frameworkImpl struct {
// 调度插件注册表(详情参看调度插件文档),这个非常有用,frameworkImpl的构造函数需要用它来创建配置的插件。
registry Registry
// 这个是为实现Handle.SnapshotSharedLister()接口准备的,是创建frameworkImpl时传入的,不是frameworkImpl自己创建的。
// 至于framework.SharedLister类型会在调度器的文章中介绍,此处暂时不用关心,因为不影响阅读。
snapshotSharedLister framework.SharedLister
// 这是为实现Handle.GetWaitingPod/RejectWaitingPod/IterateOverWaitingPods()接口准备的。
// 关于waitingPodsMap请参看https://github.com/jindezgm/k8s-src-analysis/blob/master/kube-scheduler/WaitingPods.md
waitingPods *waitingPodsMap
// 插件名字与权重的映射,用来根据插件名字获取权重,为什么要有这个变量呢?因为插件的权重是配置的,对于每个Framework都不同。
// 所以pluginNameToWeightMap是在构造函数中根据SchedulingProfile生成的。
pluginNameToWeightMap map[string]int
// 所有扩展点的插件,为实现Framework.RunXxxPlugins()准备的,不难理解,就是每个扩展点遍历插件执行就可以了。
// 下面所有插件都是在构造函数中根据SchedulingProfile生成的。
queueSortPlugins []framework.QueueSortPlugin
preFilterPlugins []framework.PreFilterPlugin
filterPlugins []framework.FilterPlugin
postFilterPlugins []framework.PostFilterPlugin
preScorePlugins []framework.PreScorePlugin
scorePlugins []framework.ScorePlugin
reservePlugins []framework.ReservePlugin
preBindPlugins []framework.PreBindPlugin
bindPlugins []framework.BindPlugin
postBindPlugins []framework.PostBindPlugin
permitPlugins []framework.PermitPlugin
// 这些是为实现Handle.Clientset/EventHandler/SharedInformerFactory()准备的,因为Framework继承了Handle。
// 这些成员变量是同构构造函数的参数出入的,不是frameworkImpl自己创建的。
clientSet clientset.Interface
eventRecorder events.EventRecorder
informerFactory informers.SharedInformerFactory
metricsRecorder *metricsRecorder
// 为实现Handle.ProfileName()准备的。
profileName string
// 为实现Framework.PreemptHandle()准备的
preemptHandle framework.PreemptHandle
// 如果为true,RunFilterPlugins第一次失败后不返回,应该积累有失败的状态。
runAllFilters bool
}
Framework构造函数
从frameworkImpl的成员变量来看,基本可以想象得到如何实现Framework的接口,所以本文只挑选一些代表性的接口实现,其他的读者自己阅读即可,没什么难度。首先,frameworkImpl的构造函数是一个比较关键的函数,因为一些关键的成员变量是在构造函数中创建的。源码链接:https://github.com/kubernetes/kubernetes/blob/release-1.20/pkg/scheduler/framework/runtime/framework.go#L235
// NewFramework()是frameworkImpl的构造函数,前三个参数在调度插件的文档中有介绍,此处简单描述一下:
// 1. r: 插件注册表,可以根据插件的名字创建插件;
// 2. plugins: 插件开关配置,就是使能/禁止哪些插件;
// 3. args: 插件自定义参数,用来创建插件;
// 4. opts: 构造frameworkImpl的选项参数,frameworkImpl有不少成员变量是通过opts传入进来的;
func NewFramework(r Registry, plugins *config.Plugins, args []config.PluginConfig, opts ...Option) (framework.Framework, error) {
// 应用所有选项,Option这种玩法不稀奇了,golang有太多项目采用类似的方法
options := defaultFrameworkOptions
for _, opt := range opts {
opt(&options)
}
// 可以看出来frameworkImpl很多成员变量来自opts
f := &frameworkImpl{
registry: r,
snapshotSharedLister: options.snapshotSharedLister,
pluginNameToWeightMap: make(map[string]int),
waitingPods: newWaitingPodsMap(),
clientSet: options.clientSet,
eventRecorder: options.eventRecorder,
informerFactory: options.informerFactory,
metricsRecorder: options.metricsRecorder,
profileName: options.profileName,
runAllFilters: options.runAllFilters,
}
// preemptHandle实现了PreemptHandle接口,其中Extenders和PodNominator都是通过opts传入的。
// 因为frameworkImpl实现了Framework接口,所以也就是实现了PluginsRunner接口。
f.preemptHandle = &preemptHandle{
extenders: options.extenders,
PodNominator: options.podNominator,
PluginsRunner: f,
}
if plugins == nil {
return f, nil
}
// pluginsNeeded()函数名是获取需要的插件,就是把plugins中所有使能(Enable)的插件转换成map[string]config.Plugin。
// pg中是所有使能的插件,key是插件名字,value是config.Plugin(插件权重),试问为什么要转换成map?
// 笔者在调度插件的文章中提到了,很多插件实现了不同扩展点的插件接口,这会造成plugins中有很多相同名字的插件,只是分布在不同的扩展点。
// 因为map有去重能力,这样可以避免相同的插件创建多个对象。
pg := f.pluginsNeeded(plugins)
// pluginConfig存储的是所有使能插件的参数
pluginConfig := make(map[string]runtime.Object, len(args))
for i := range args {
// 遍历所有插件参数,并找到使能插件的参数,因为pg是所有使能的插件。
name := args[i].Name
if _, ok := pluginConfig[name]; ok {
return nil, fmt.Errorf("repeated config for plugin %s", name)
}
pluginConfig[name] = args[i].Args
}
// outputProfile是需要输出的KubeSchedulerProfile对象。
// 前文提到的SchedulingProfile对应的类型就是KubeSchedulerProfile,包括Profile的名字、插件配置以及插件参数。
// 因为在构造frameworkImpl的时候会过滤掉不用的插件参数,所以调用者如果需要,可以通过opts传入回调函数捕获KubeSchedulerProfile。
outputProfile := config.KubeSchedulerProfile{
SchedulerName: f.profileName,
Plugins: plugins,
PluginConfig: make([]config.PluginConfig, 0, len(pg)),
}
// 此处需要区分framework.Plugin和config.Plugin,前者是插件接口基类,后者是插件权重配置,所以接下来就是创建所有使能的插件了。
pluginsMap := make(map[string]framework.Plugin)
var totalPriority int64
// 遍历插件注册表
for name, factory := range r {
// 如果没有使能,则跳过。这里的遍历有点意思,为什么不遍历pg,然后查找r,这样不是更容易理解么?
// 其实遍历pg会遇到一个问题,如果r中没有找到怎么办?也就是配置了一个没有注册的插件,报错么?
// 而当前的遍历方法传达的思想是,就这多插件,使能了哪个就创建哪个,不会出错,不需要异常处理。
if _, ok := pg[name]; !ok {
continue
}
// getPluginArgsOrDefault()根据插件名字从pluginConfig获取参数,如果没有则返回默认参数,函数名字已经告诉我们一切了。
args, err := getPluginArgsOrDefault(pluginConfig, name)
if err != nil {
return nil, fmt.Errorf("getting args for Plugin %q: %w", name, err)
}
// 输出插件参数,这也是为什么有捕获KubeSchedulerProfile的功能,因为在没有配置参数的情况下要创建默认参数。
// 捕获KubeSchedulerProfile可以避免调用者再实现一次类似的操作,前提是有捕获的需求。
if args != nil {
outputProfile.PluginConfig = append(outputProfile.PluginConfig, config.PluginConfig{
Name: name,
Args: args,
})
}
// 利用插件工厂创建插件,传入插件参数和框架句柄
p, err := factory(args, f)
if err != nil {
return nil, fmt.Errorf("initializing plugin %q: %w", name, err)
}
pluginsMap[name] = p
// 记录配置的插件权重
f.pluginNameToWeightMap[name] = int(pg[name].Weight)
// f.pluginNameToWeightMap[name] == 0有两种可能:1)没有配置权重,2)配置权重为0
// 无论哪一种,权重为0是不允许的,即便它不是ScorePlugin,如果为0则使用默认值1
if f.pluginNameToWeightMap[name] == 0 {
f.pluginNameToWeightMap[name] = 1
}
// 需要了解的是framework.MaxTotalScore的值是64位整数的最大值,framework.MaxNodeScore的值是100;
// 每个插件的标准化分数是[0, 100], 所有插件最大标准化分数乘以权重的累加之和不能超过int64最大值,
// 否则在计算分数的时候可能会溢出,所以此处需要校验配置的权重是否会导致计算分数溢出。
if int64(f.pluginNameToWeightMap[name])*framework.MaxNodeScore > framework.MaxTotalScore-totalPriority {
return nil, fmt.Errorf("total score of Score plugins could overflow")
}
totalPriority += int64(f.pluginNameToWeightMap[name]) * framework.MaxNodeScore
}
// pluginsMap是所有已经创建好的插件,但是是map结构,现在需要把这些插件按照扩展点分到不同的slice中。
// 即map[string]framework.Plugin->[]framework.QueueSortPlugin,[]framework.PreFilterPlugin...的过程。
// 关于getExtensionPoints()和updatePluginList()的实现还是挺有意思的,用了反射,感兴趣的同学可以看一看。
for _, e := range f.getExtensionPoints(plugins) {
if err := updatePluginList(e.slicePtr, e.plugins, pluginsMap); err != nil {
return nil, err
}
}
// 检验ScorePlugin的权重不能为0,当前已经起不了作用了,因为在创建插件的时候没有配置权重的插件的权重都是1.
// 但是这些代码还是有必要的,未来保不齐会修改前面的代码,这些校验可能就起到作用了。关键是在构造函数中,只会执行一次,这点校验计算量可以忽略不计。
for _, scorePlugin := range f.scorePlugins {
if f.pluginNameToWeightMap[scorePlugin.Name()] == 0 {
return nil, fmt.Errorf("score plugin %q is not configured with weight", scorePlugin.Name())
}
}
// 不能没有调度队列的排序插件,并且也不能有多个,多了没用。
// 那么如果同时存在两种优先级计算方法怎么办?用不同的Framework,即不同的SchedulingProfile.
if len(f.queueSortPlugins) == 0 {
return nil, fmt.Errorf("no queue sort plugin is enabled")
}
if len(f.queueSortPlugins) > 1 {
return nil, fmt.Errorf("only one queue sort plugin can be enabled")
}
// 不能没有绑定插件,否则调度的结果没法应用到集群
if len(f.bindPlugins) == 0 {
return nil, fmt.Errorf("at least one bind plugin is needed")
}
// 如果调用者需要捕获KubeSchedulerProfile,则将KubeSchedulerProfile回调给调用者
if options.captureProfile != nil {
if len(outputProfile.PluginConfig) != 0 {
// 按照Profile名字排序
sort.Slice(outputProfile.PluginConfig, func(i, j int) bool {
return outputProfile.PluginConfig[i].Name < outputProfile.PluginConfig[j].Name
})
} else {
outputProfile.PluginConfig = nil
}
options.captureProfile(outputProfile)
}
return f, nil
}
不知道读者什么感觉,反正笔者看完frameworkImpl构造函数后感觉打通了任督二脉,Framework一下就全通了。接下来笔者带领大家看一些比较有特色的Framework接口实现。
RunFilterPlugins
为什么RunFilterPlugins?因为相比于其他RunXxxPlugins多了runAllFilters校验,源码链接:https://github.com/kubernetes/kubernetes/blob/release-1.20/pkg/scheduler/framework/runtime/framework.go#L527
func (f *frameworkImpl) RunFilterPlugins(
ctx context.Context,
state *framework.CycleState,
pod *v1.Pod,
nodeInfo *framework.NodeInfo,
) framework.PluginToStatus {
// 之前一直没有介绍PluginToStatus,它是一个map类型,用于记录每个插件的执行状态,此处状态和HTTP返回的status类似,是一种结果。
statuses := make(framework.PluginToStatus)
// 遍历所有的FilterPlugin,因为filterPlugins是slice类型,所以每次都是按照配置的顺序执行
for _, pl := range f.filterPlugins {
// runFilterPlugin()是执行单个FilterPlugin插件的函数,下面有注释
pluginStatus := f.runFilterPlugin(ctx, pl, state, pod, nodeInfo)
// 此处需要简单说明一下插件返回的状态包括:
// 1. Success: 成功,没什么好解释的
// 2. Error: 插件内部错误,比如插件调用Clientset报错
// 3. Unschedulable: 不可调度,比如资源不足,但是可以通过抢占的方式解决
// 4. UnschedulableAndUnresolvable: 不可调度并且无法解决,意思就是抢占调度也解决不了
// 5. Wait: PermitPlugin专属状态,用来延迟Pod的绑定
// 6. Skip: BindPlugin专属状态,如果BindPlugin不能绑定Pod则返回这个状态
// 过滤成功就继续循环用下一个插件过滤,过滤失败则需要特殊处理一下
if !pluginStatus.IsSuccess() {
// 如果插件返回的不是不可调度,那只能是内部错误,那么就直接返回错误,因为内部错误后续是无法解决的,抢占也不行
if !pluginStatus.IsUnschedulable() {
errStatus := framework.NewStatus(framework.Error, fmt.Sprintf("running %q filter plugin for pod %q: %v", pl.Name(), pod.Name, pluginStatus.Message()))
return map[string]*framework.Status{pl.Name(): errStatus}
}
// 当前只有Unschedulable或者UnschedulableAndUnresolvable,二者都是不可调度状态。
statuses[pl.Name()] = pluginStatus
// 如果配置了runAllFilters = true,剩下的FilterPlugin也需要执行一次,这样的设计时为什么?
// 笔者猜测是为了抢占调度准备,因为后续插件可能还会返回不可调度状态,比如当前因为CPU不可调度,后续可能因为PVC不可调度。
// 如果提供给抢占调度插件的状态中只有CPU不满足,那么抢占了CPU资源也会因为PVC无法满足而过滤失败。
// 更关键的是,如果后续插件返回了UnschedulableAndUnresolvable,那么就没必要调用抢占调度插件了。
// 所以只有运行全部插件才能为Pod后续操作提供最准确的参考。
if !f.runAllFilters {
return statuses
}
}
}
return statuses
}
// runFilterPlugin()运行一个FilterPlugin,非常简单,单独封装一个函数就是为了记录metrics。
func (f *frameworkImpl) runFilterPlugin(ctx context.Context, pl framework.FilterPlugin, state *framework.CycleState, pod *v1.Pod, nodeInfo *framework.NodeInfo) *framework.Status {
if !state.ShouldRecordPluginMetrics() {
return pl.Filter(ctx, state, pod, nodeInfo)
}
startTime := time.Now()
status := pl.Filter(ctx, state, pod, nodeInfo)
f.metricsRecorder.observePluginDurationAsync(Filter, pl.Name(), status, metrics.SinceInSeconds(startTime))
return status
}
RunScorePlugins
为什么是RunScorePlugins?因为可以让我们知道Framework是如何利用ScorePlugin计算Node的分数,源码链接:https://github.com/kubernetes/kubernetes/blob/release-1.20/pkg/scheduler/framework/runtime/framework.go#L635
func (f *frameworkImpl) RunScorePlugins(ctx context.Context, state *framework.CycleState, pod *v1.Pod, nodes []*v1.Node) (ps framework.PluginToNodeScores, status *framework.Status) {
startTime := time.Now()
defer func() {
metrics.FrameworkExtensionPointDuration.WithLabelValues(score, status.Code().String(), f.profileName).Observe(metrics.SinceInSeconds(startTime))
}()
// 此处需要简单说明一下PluginToNodeScores类型,它是一个map[string][]{Name, Score}(伪代码,Name是Node名字,Score是Node分数)类型。
// 说白了就是每个ScorePlugin给每个Node的分数,此处的Node是所有RunFilterPlugins()返回成功的Node集合。
pluginToNodeScores := make(framework.PluginToNodeScores, len(f.scorePlugins))
// 提前把所有ScorePlugin对所有的Node的评分的内存申请出来,这样后面并行计算分数时就不用加锁了
for _, pl := range f.scorePlugins {
pluginToNodeScores[pl.Name()] = make(framework.NodeScoreList, len(nodes))
}
// 为并行计算分数创建context和错误chan,请参看parallelize包了解细节
ctx, cancel := context.WithCancel(ctx)
errCh := parallelize.NewErrorChannel()
// parallelize.Until()是一个比较有用的工具,就是并行的执行函数。需要注意len(nodes)不是并行度,它是处理总量。
// parallelize的并行度是可设置的,默认值是16,如果处理的总量超过并行度, parallelize.Until()会分片处理,即一个协程处理一小部分。
// 所以下面的代码可以假定Node间并行的执行所有ScorePlugin计算分数。
parallelize.Until(ctx, len(nodes), func(index int) {
// 遍历所有的ScorePlugin
for _, pl := range f.scorePlugins {
// 计算第index个Node的分数
nodeName := nodes[index].Name
s, status := f.runScorePlugin(ctx, pl, state, pod, nodeName)
// 评分失败退出函数
if !status.IsSuccess() {
err := fmt.Errorf("plugin %q failed with: %w", pl.Name(), status.AsError())
// errCh.SendErrorWithCancel()会调用cancel(),所以其他的并行的协程也会退出。
errCh.SendErrorWithCancel(err, cancel)
return
}
// 记录插件给第index个Node的分数,这就是提前为pluginToNodeScores申请内存的好处,不需要再加锁了
pluginToNodeScores[pl.Name()][index] = framework.NodeScore{
Name: nodeName,
Score: s,
}
}
})
// 如果有任何ScorePlugin出错,则返回错误状态
if err := errCh.ReceiveError(); err != nil {
klog.ErrorS(err, "Failed running Score plugins", "pod", klog.KObj(pod))
return nil, framework.AsStatus(fmt.Errorf("running Score plugins: %w", err))
}
// 并行的标准化Node分数,每个ScorePlugin对所有的Node分数标准化处理,ScorePlugin之间是并行的
parallelize.Until(ctx, len(f.scorePlugins), func(index int) {
// 判断ScorePlugin是否有扩展接口,如果没有就不用标准化分数处理了
pl := f.scorePlugins[index]
nodeScoreList := pluginToNodeScores[pl.Name()]
if pl.ScoreExtensions() == nil {
return
}
// 调用ScorePlugin的扩展接口标准化所有Node的分数
status := f.runScoreExtension(ctx, pl, state, pod, nodeScoreList)
if !status.IsSuccess() {
err := fmt.Errorf("plugin %q failed with: %w", pl.Name(), status.AsError())
errCh.SendErrorWithCancel(err, cancel)
return
}
})
// 如果有任何ScorePlugin出错,则返回错误状态
if err := errCh.ReceiveError(); err != nil {
klog.ErrorS(err, "Failed running Normalize on Score plugins", "pod", klog.KObj(pod))
return nil, framework.AsStatus(fmt.Errorf("running Normalize on Score plugins: %w", err))
}
// 并行的在Node标准化分数基础上乘以权重
parallelize.Until(ctx, len(f.scorePlugins), func(index int) {
pl := f.scorePlugins[index]
// 获取插件的权重以及所有Node的标准化分数
weight := f.pluginNameToWeightMap[pl.Name()]
nodeScoreList := pluginToNodeScores[pl.Name()]
// 遍历Node标准化分数
for i, nodeScore := range nodeScoreList {
// 如果Node标准化分数超过[0, 100]范围,则返回错误
if nodeScore.Score > framework.MaxNodeScore || nodeScore.Score < framework.MinNodeScore {
err := fmt.Errorf("plugin %q returns an invalid score %v, it should in the range of [%v, %v] after normalizing", pl.Name(), nodeScore.Score, framework.MinNodeScore, framework.MaxNodeScore)
errCh.SendErrorWithCancel(err, cancel)
return
}
// Node分数就是标准化分数乘以插件的权重
nodeScoreList[i].Score = nodeScore.Score * int64(weight)
}
})
// 如果有任何ScorePlugin的标准化分数超出范围,则返回错误状态
if err := errCh.ReceiveError(); err != nil {
klog.ErrorS(err, "Failed applying score defaultWeights on Score plugins", "pod", klog.KObj(pod))
return nil, framework.AsStatus(fmt.Errorf("applying score defaultWeights on Score plugins: %w", err))
}
// 返回每个ScorePlugin对所有Node的评分,并且已经乘上了插件对应的权重
return pluginToNodeScores, nil
}
// runScorePlugin()调用一个ScorePlugin计算Node的分数,单独封装一个函数就是为了记录metrics。
func (f *frameworkImpl) runScorePlugin(ctx context.Context, pl framework.ScorePlugin, state *framework.CycleState, pod *v1.Pod, nodeName string) (int64, *framework.Status) {
if !state.ShouldRecordPluginMetrics() {
return pl.Score(ctx, state, pod, nodeName)
}
startTime := time.Now()
s, status := pl.Score(ctx, state, pod, nodeName)
f.metricsRecorder.observePluginDurationAsync(score, pl.Name(), status, metrics.SinceInSeconds(startTime))
return s, status
}
RunBindPlugins
为什么是RunBindPlugins?因为有的BindPlugin会返回Skip状态,源码链接:https://github.com/kubernetes/kubernetes/blob/release-1.20/pkg/scheduler/framework/runtime/framework.go#L762
func (f *frameworkImpl) RunBindPlugins(ctx context.Context, state *framework.CycleState, pod *v1.Pod, nodeName string) (status *framework.Status) {
startTime := time.Now()
defer func() {
metrics.FrameworkExtensionPointDuration.WithLabelValues(bind, status.Code().String(), f.profileName).Observe(metrics.SinceInSeconds(startTime))
}()
// 没有BindPlugin,等同于所有的BindPlugin都返回了Skip状态。理论上不会出现这种情况,因为在Framework构造函数做了相关校验。
if len(f.bindPlugins) == 0 {
return framework.NewStatus(framework.Skip, "")
}
// 遍历BindPlugin
for _, bp := range f.bindPlugins {
// 执行插件的绑定接口
status = f.runBindPlugin(ctx, bp, state, pod, nodeName)
// 如果返回Skip状态,则忽略这个插件。也就是说BindPlugin可以根据Pod选择是否执行绑定。
// 虽然当前只有DefaultBinder一种实现,笔者猜测:设计者认为有的绑定可能比较复杂,交给特定的插件绑定。
if status != nil && status.Code() == framework.Skip {
continue
}
// 如果绑定失败则返回错误状态
if !status.IsSuccess() {
err := status.AsError()
klog.ErrorS(err, "Failed running Bind plugin", "plugin", bp.Name(), "pod", klog.KObj(pod))
return framework.AsStatus(fmt.Errorf("running Bind plugin %q: %w", bp.Name(), err))
}
return status
}
return status
}
// runBindPlugin()执行一个插件的绑定操作,单独封装一个函数就是为了记录metrics。
func (f *frameworkImpl) runBindPlugin(ctx context.Context, bp framework.BindPlugin, state *framework.CycleState, pod *v1.Pod, nodeName string) *framework.Status {
if !state.ShouldRecordPluginMetrics() {
return bp.Bind(ctx, state, pod, nodeName)
}
startTime := time.Now()
status := bp.Bind(ctx, state, pod, nodeName)
f.metricsRecorder.observePluginDurationAsync(bind, bp.Name(), status, metrics.SinceInSeconds(startTime))
return status
}
总结
- Profile和Framework是一一对应的,kube-scheduler会为一个Profile创建一个Framework,可以通过设置Pod.Spec.SchedulerName选择Framework执行调度;
- Framework将调度一个Pod分为调度周期和绑定周期,每个Pod的调度周期是串行的,但是绑定周期可能是并行的;
- Framework定义了扩展点的概念,并且为每个扩展定定义了接口,即XxxPlugin;
- Framework为每个扩展点定义了一个入口,RunXxxPlugins,Framework会按照Profile配置的插件顺序依次调用插件;
- Framework插件定义了句柄和抢占句柄,为插件实现特定的功能提供接口;
