


1. Redis基本介绍及拓展
1.1 Redis简介
Redis是完全开源免费的,遵守 BSD 协议,是一个灵活的高性能 key-value 数据结构存储,可以用来作为数据库、缓存和消息队列。
Redis相比其他 key-value 缓存产品有以下三个特点:
- Redis支持数据的持久化,可以将内存中的数据保存在磁盘中,重启的时候可以再次加载到内存使用。
- Redis不仅支持简单的 key-value 类型的数据,同时还提供 list,set,zset,hash 等数据结构的存储。
- Redis支持主从复制,即 master-slave 模式的数据备份。
1.2 Redis优势
- 高性能: Redis将所有数据集存储在内存中,可以在入门级 Linux 机器中每秒写(SET)11 万次,读(GET)1 万次。Redis 支持 Pipelining 命令,可一次发送多条命令来提高吞吐率,减少通信延迟。
- 持久化:当所有数据都存在于内存中时,可以根据自上次保存以来经过的时间和/或更新次数,使用灵活的策略将更改异步保存在磁盘上。Redis支持仅附加文件(AOF)持久化模式。
- 数据结构: Redis支持各种类型的数据结构,例如字符串、散列、集合、列表、带有范围查询的有序集、位图、超级日志和带有半径查询的地理空间索引。
- 原子操作:处理不同数据类型的 Redis操作是原子操作,因此可以安全地 SET 或 INCR 键,添加和删除集合中的元素等。
- 支持的语言: Redis支持许多语言,如 C、C++、Erlang、Go、Haskell、Java、JavaScript(js)、Lua、Objective-C、Perl、PHP、Python、R、Ruby、Rust、Scala、Smalltalk 等。
- 主/从复制: Redis遵循非常简单快速的主/从复制。配置文件中只需要一行来设置它,而 Slave 在 Amazon EC2 实例上完成 10 MM key 集的初始同步只需要 21 秒。
- 分片: Redis支持分片。与其他键值存储一样,跨多个 Redis 实例分发数据集非常容易。
- 可移植: Redis是用 C 编写的,适用于大多数 POSIX 系统,如 Linux、BSD、Mac OS X、Solaris 等。
1.3 Redis高性能原因
- 内存存储:Redis是使用内存(in-memeroy)存储,没有磁盘IO上的开销
- 单线程实现:Redis使用单个线程处理请求,避免了多个线程之间线程切换和锁资源争用的开销
- 非阻塞IO:Redis使用多路复用IO技术,在poll,epool,kqueue选择最优IO实现
- 优化的数据结构:Redis有诸多可以直接应用的优化数据结构的实现,应用层可以直接使用原生的数据结构提升性能。
1.4 Redis请求过程分析
以最常用场景缓存为例,流量从用户到Redis Server的过程如图1所示:
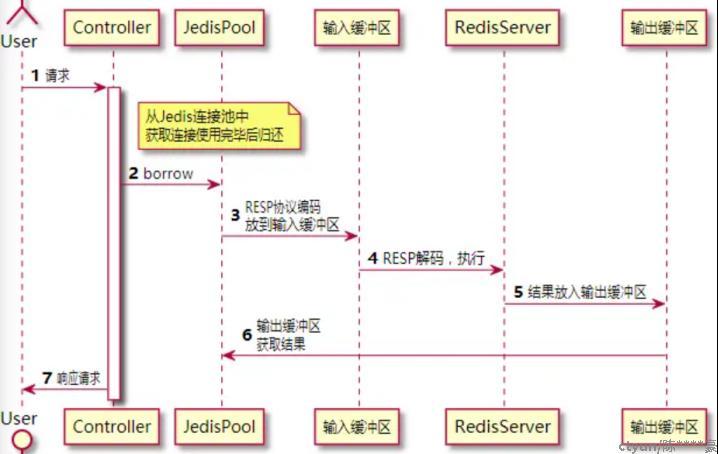
图1:Redis请求过程
- 用户访问后端服务器,调用对应的Controller
- Controller命中缓存记录,通过Jedis客户端调用Reids从缓存获取记录。
- 如果使用的Jedis连接池获取Jedis对象,从Jedis连接池获取一个Jedis连接实例。
- Jedis使用Redis序列化协议(RESP)将命令编码,放到RedisServer输入缓冲区中。
- RedisServer从输入缓冲区获取命令并执行。
- 执行结束后将执行结果放入到输出缓冲区。
- Jedis客户端从输出缓冲区获取执行结果并返回给Controller。
- Controller执行完业务逻辑相应用户的请求。
2. Redis性能影响因素
2.1硬件因素
- 高带宽,低延迟的网络:Redis的性能中网络带宽和延迟通常是最大短板。因此,需要选择高带宽,低延迟的网络。
- 大缓存快速CPU:而不是多核。这种场景下面,比较推荐Intel CPU。AMD CPU 可能只有 Intel CPU 的一半性能(通过对 Nehalem EP/Westmere EP/Sandy平台的对比)。当其他条件相当时候,CPU 就成了 Redis-benchmark 的限制因素。
- 大对象(>10k)存储时内存和带宽显得尤其重要。但是更重要是优化大对象的存储。
- 将Redis运行在物理机器上:Redis在虚机上会变慢。虚拟化对普通操作会有额外的消耗,Redis对系统调用和网络终端不会有太多的 overhead。建议把 Redis 运行在物理机器上。
2.2使用因素:
为了减少Redis的延迟,提高Redis的性能,应注意如下几点:
- object大小影响Redis的相应速度。 以太网网数据包在 1500 bytes以下时, 将多条命令包装成pipelining(减少总的调用次数和往返时延RTT)可以大大提高效率。事实上,处理 10 bytes,100 bytes,1000 bytes的请求时候,吞吐量是差不多的,详细可以见图2。
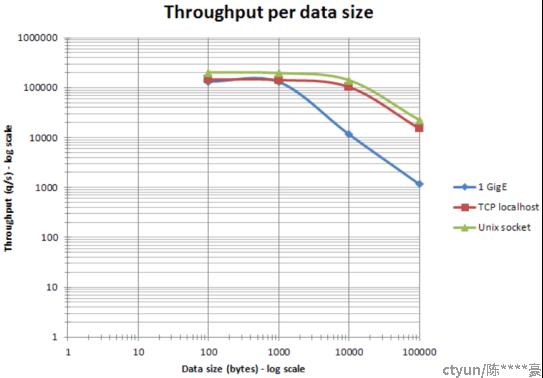
图2:数据包对QPS影响
- 当连接数上升时吞吐量会平缓下降。Redis已经在超过60000连接下面基准测试过,仍然可以维持50000q/s。一条经验法则是,30000的连接数只有100连接数的一半吞吐量,如图3所示。
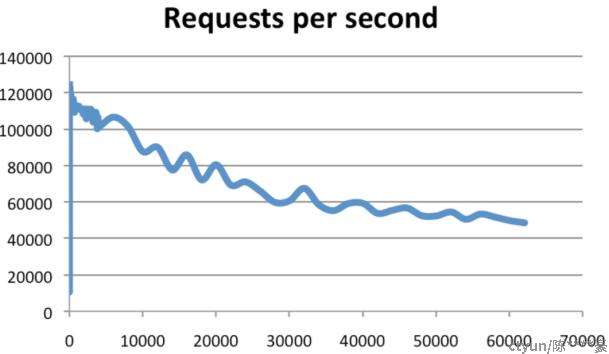
图3:客户端连接数对QPS影响
- 在多核 CPU 服务器上面,Redis的性能还依赖NUMA配置和处理器绑定位置。 最明显的影响是 Redis-benchmark会随机使用CPU内核。为了获得精准的结果, 需要使用固定处理器工具(在 Linux 上可以使用taskset或 numactl)。最有效的办法是将客户端和服务端分离到两个不同的CPU来高效使用三级缓存。
这里有一些使用4 KB数据SET的基准测试,针对三种CPU(AMD Istanbul, Intel Nehalem EX,和Intel Westmere)使用不同的配置,结果如图4。
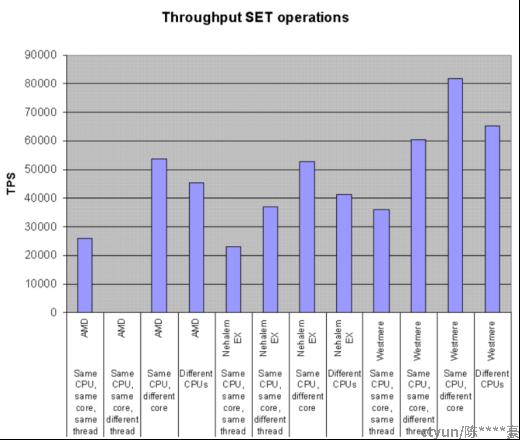
图4:多种CPU配置对QPS影响
- 避免长耗时命令的执行;
- 网络引发的延迟:在使用之应该尽量使用长连接和连接池,来避免频繁的进行创建、销毁连接的操作,当客户端进行批量数据操作时应该借助pipeline特性在一次交互中进行实现。
- 数据持久化引发的延迟:
- AOF+appednfsync always,这种方式虽然能够确保数据的安全,但每个操作都会触发一次fsync,这会明显的影响Redis的性能;
- AOF+appendfsync everysec,这种方式是比较好的这种方案,每秒执行一次;
- AOF+appendfsync no,这种方式会提供AOF持久化方案下最优的性能;
- 使用RDB持久化方案,这种方案通常会提供比AOF更高的性能,但使用时需要注意RDB策略的配置;
- 在进行持久化时,不管是RDB的快照还是AOF的Rewrite,两者都需要主进程进行fork操作,而这个操作往往伴随着高耗时,这与Redis占用的内存和CPU有关,所以要合理配置RDB快照和AOFRewrite的时机,以避免频繁的fork操作。
- swap引发的延迟:swap发生在物理内存不足或者一些进程在进行大量I/O操作时,Linux将Redis所用的内存分页迁移至swap空间,并将Redis进程进行阻塞,导致Redis出现不正常的延迟
- 数据淘汰引发的延迟:Redis有一定的数据淘汰机制,如果数据淘汰过程中某一时刻有大量key过期时,触发数据淘汰操作,这也会引发Redis的延迟,避免这种现象的方式便是将不同Key的过期时间设置错开,避免同一时间过期。
在使用Redis时为了提高Redis的性能,建议引入读写分离机制,因为Redis具有主从复制的能力,这样可以实现一主多从的架构,所以可以通过使从节点来提供对实时性要求不高的请求服务,这样可以在一定程度上降低主节点的压力。
2. Redis性能测试工具简介
性能指标:QPS
测试工具:Redis-benchmark(主流性能测试工具,Redis自带的,无需专门安装)、YCSB、memtier_benchmark
Redis-benchmark工具用来模拟N个客户端同时发出M个请求,其用法如下:
|
Usage: Redis-benchmark [-h <host>] [-p <port>] [-c <clients>] [-n <requests]> [-k <boolean>]
-h <hostname> Server hostname (default 127.0.0.1) -p <port> Server port (default 6379) -s <socket> Server socket (overrides host and port) -a <password> Password for Redis Auth -c <clients> Number of parallel connections (default 50) -n <requests> Total number of requests (default 100000) -d <size> Data size of SET/GET value in bytes (default 2) -dbnum <db> SELECT the specified db number (default 0) -k <boolean> 1=keep alive 0=reconnect (default 1) -r <keyspacelen> Use random keys for SET/GET/INCR, random values for SADD.Using this option the benchmark will expand the string __rand_int__inside an argument with a 12 digits number in the specified range from 0 to keyspacelen-1. The substitution changes every time a command is executed. Default tests use this to hit random keys in the specified range. -P <numreq> Pipeline <numreq> requests. Default 1 (no pipeline). -q Quiet. Just show query/sec values --csv Output in CSV format -l Loop. Run the tests forever -t <tests> Only run the comma separated list of tests. The test names are the same as the ones produced as output. -I Idle mode. Just open N idle connections and wait. |
3. Redis性能测试实践
4.1测试说明
Redis版本:Redis-4.0.11-11.ctl2.x86_64
虚机规格:4C8G
测试侧重点:
比较默认条件下,与开启pipeline、设置cpu亲和性、键值随机情况下的QPS对比,以及客户端连接数、数据包大小对QPS的影响。
其它说明:
- 宿主机无负载
- 绑定cpu是指,Redis-server和Redis-cli绑定在不同的物理核上
- 测试前,确保宿主机cpu频率固定
- 测试时延的时候每次测试时长为30s;实际上只需要几秒钟,虚机中Redis的时延已变得稳定,因此,30s的时长是足够的。
4.2测试步骤
- 默认情况下,云主机中RedisQPS测试:
- 开启Pipeline情况下,云主机中RedisQPS测试:
- for i in {1..5}
- do
- echo "....run the ${i} round,pipline is 16...."
- /usr/bin/Redis-cli flushall
- /usr/bin/Redis-benchmark -P 16 -q -t set,get,incr,lpop,lpush >> Redisout
- done
- 键值随机情况下,云主机中RedisQPS测试:
- for i in {1..5}
- do
- echo "....run the ${i}..."
- /usr/bin/Redis-cli flushall
- /usr/bin/Redis-benchmark -r 10000 -q -t set,get,incr,lpop,lpush >> Redisout
- done
- 设置cpu亲和性情况下,云主机中RedisQPS测试:
- pid=$(ps -ef | grep Redis| awk 'NR==1 {print $2}')
- taskset -cp 0,1 ${pid}
- for i in {1..5}
- do
- echo "....run the ${i}..."
- /usr/bin/Redis-cli flushall
- numactl --physcpubind=2,3 --membind=0 /usr/bin/Redis-benchmark -q -t set,get,incr,lpop,lpush >> Redisout
- done
- 云主机中客户端连接数对RedisQPS的影响:
- pid=$(ps -ef | grep Redis| awk 'NR==1 {print $2}')
- taskset -cp 0,1 ${pid}
- clients=(100 500 1000 2000 3000 4000 5000 6000 7000 8000 9000 10000)
- for c in ${clients[*]}
- do
- echo "....client is ${c}...."
- /usr/bin/Redis-cli flushall
- numactl --physcpubind=2,3 --membind=0 /usr/bin/Redis-benchmark -c ${c} -q -t set,get,incr,lpop,lpush >> Redisout
- done
- 云主机中数据包大小对RedisQPS的影响:
- pid=$(ps -ef | grep Redis| awk 'NR==1 {print $2}')
- taskset -cp 0,1 ${pid}
- for d in $(seq 100 3000 30000)
- do
- echo "....data size is ${d}...."
- /usr/bin/Redis-cli flushall
- numactl --physcpubind=2,3 --membind=0 /usr/bin/Redis-benchmark -d ${d} -q -t set,get,incr,lpop,lpush >> Redisout
- done
5.Redis性能测试结果分析
- 默认情况与开启流水线对比:
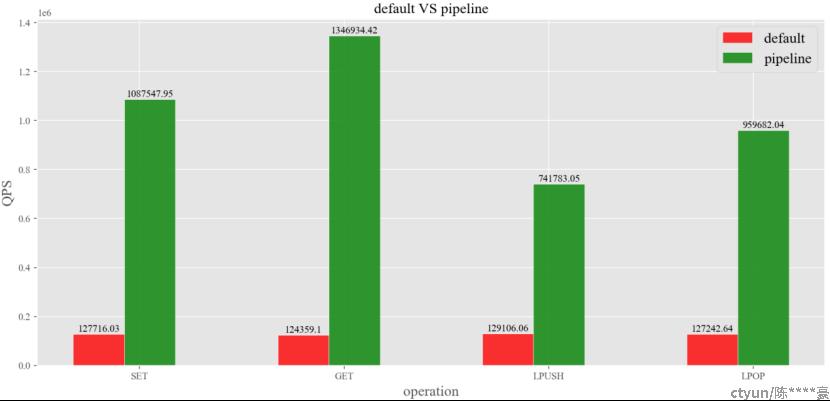
图5:default VS pipeline
由图5可知,相比于默认情况下,开启pipeline后,SET、GET、LPUSH、LPOP四种操作的QPS依次提升了8.5、 10.8、 5.7、 7.5倍,由此可见,开启pipeline可以极大提升QPS。
- 默认情况与设置cpu亲和性对比:
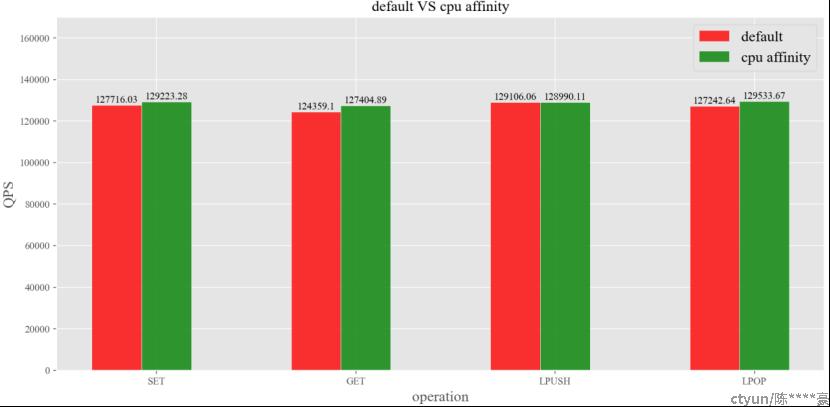
图6:default VS cpu affinity
由图6可知,相比于默认情况下,设置cpu亲和性后,SET、GET、LPUSH、LPOP四种操作的QPS依次提升了1.18%、 2.45%、 -0.09%、1.80%。由此可见,设置cpu亲和性后,Redis的性能略胜一筹。
- 默认情况与键值随机对比:
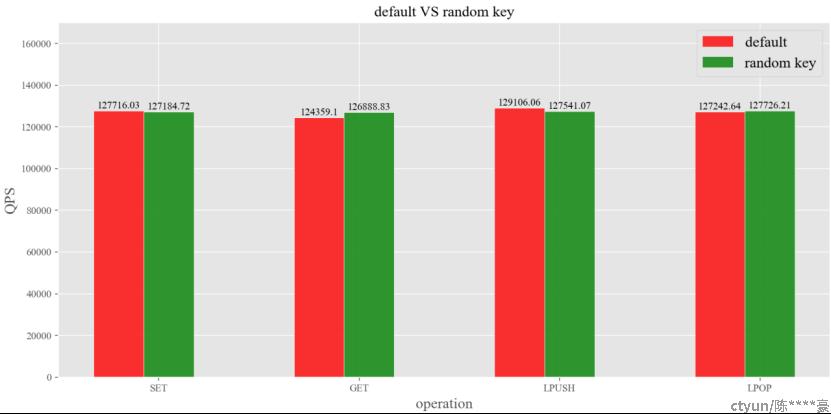
图7:default VS random key
由图7可知,相比于默认情况下,键值随机情况下,SET、GET、LPUSH、LPOP四种操作的QPS依次提升了-0.42%、 2.03%、 -1.21%、 0.38%。由此可见,键值随机情况下,对Redis的性能影响不大,然而本次实验键值随机范围为10000以内,QPS和随即范围的关系有待进一步确认,时间关系,本次仅探究到这一步。
- 数据包大小对QPS的影响:
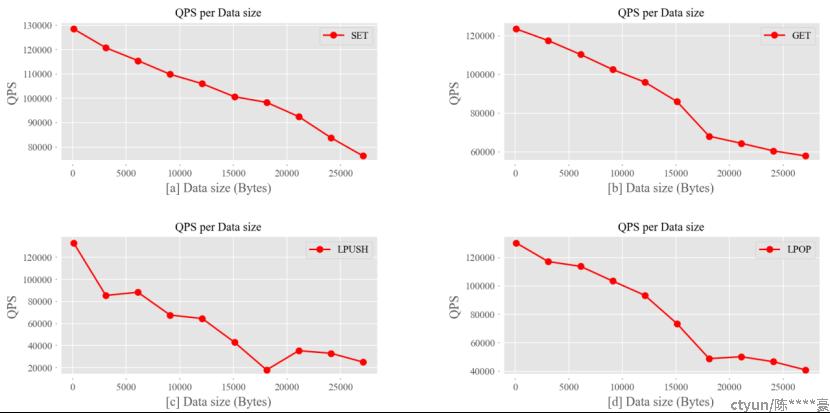
图8:数据包大小对QPS影响
由图8可知,虽然LPUSH、LPOP有一定的波动,但就总体趋势而言,四种操作的QPS都将随着数据包变大而下降。同时,数据包大小对LPUSH和LPOP操作的性能影响更大,当数据包大小为20000Bytes时,性能近似为峰值的三分之一。
- 客户端连接数对QPS的影响:
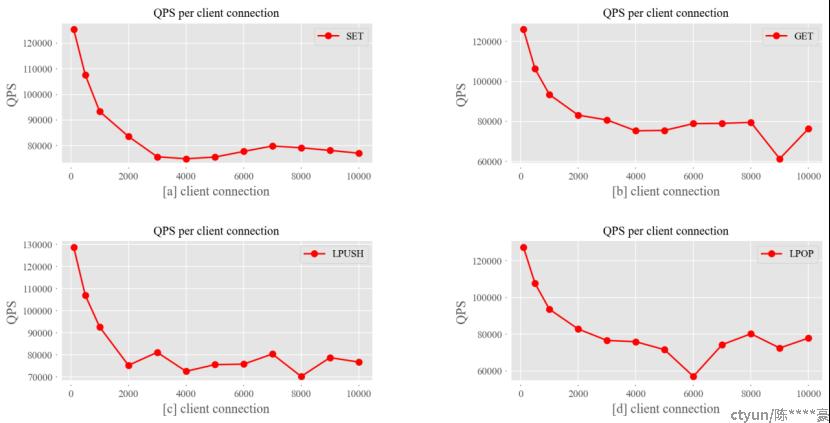
图9:客户端连接数对QPS影响
由图9可知,随着客户端连接数增大至2000左右,四种操作的QPS都会急剧下降,依次降低了33.34%、34.00%、41.56%、35.00%;当客户端连接数大于2000时,QPS在小幅度波动基础上缓慢下降。
6.总结
本次主要简单介绍Redis特性以及云主机中Redis性能测试方法,主要对比了开启pipeline、cpu亲和性、随机键值、客户端连接数、数据包大小对Redis性能的影响,通过实验,可以得出如下结论:
- 开启pipeline可以提升5-10倍的QPS;在注重高QPS的应用中,开启pipeline是一个有效手段;
- 设置cpu亲和性可以提升2%左右的QPS;实际上,在我们自研Hypervisor的项目中,设置cpu亲和性确实能够带来一定的性能提升;此外,在要求时延尽可能低的情境中,绑定cpu是一个有效方法;
- 数据包大小对QPS有很大的影响;QPS随着数据包的增大而变小,不同操作受到的影响程度有所区别。因此,在实际应用中,数据包大小是一个很重要的考量因素;
- 客户端连接数对QPS有很大影响;在连接数由几十增加到几百、上千的情况下,QPS会急剧下降,当客户端连接数进一步增加时,QPS会在小幅度波动中缓慢下降。连接数增加意味着建立连接的时间变长,直至难以接受;连接数同时还受系统限制(如文件句柄限制),哪怕解除限制,继续增加连接数会导致Redis服务端崩溃;因此,在实际应用Redis时,客户端连接数是一个很重要的考量因素。
实际上,影响Redis性能的因素还有很多,如key淘汰策略、数据持久化方式、Redis单机版和集群等部署方式差异等,并且Redis的性能指标还有时延、内存碎片率等,由于时间关系,本次测试仅在单机环境中针对QPS予以展开。
7.参考
https://www.Redis.com.cn/Redis-intro.html
https://Redis.io/topics/benchmarks
https://Redis.io/topics/Rediscli
