


前言:
由于对象存储主要运用于影像、多媒体等数据规模较大的场景,单个bucket的对象数量通常在千万甚至上亿规模,在对对象存储日常巡检和运维的时候,经常会遇到对象存储的索引存储池出现large objects告警,影响数据访问速度,甚至出现slow requests告警,进而导致存储集群服务异常。针对这种情况,下面我们介绍出现这种告警后的分析处理方式。
原因分析:
当对象存储单个bucket存储的对象数量过多,超过阈值后,将引发集群large omap objects告警,以对象存储索引池为例:阈值上限为 bucket_index_max_shard*osd_deep_scrub_large_omap_object_key_threshold。
如果不及时处理,将影响这个bucket的读写性能,甚至会给集群故障埋下隐患。
处理步骤:
处理思路:
向上调整osd_deep_scrub_large_omap_object_key_threshold消除告警,但是单个shard的对象数量过大时,会影响bucket的查询性能,不推荐。
增加shard数量,保持单个shard的阈值不变,通过增加shard的操作消除告警,默认shard值为16,osd_deep_scrub_large_omap_object_key_threshold默认值为20万,单个bucket不产生large omap objects告警的对象数量为320万,调整bucket_index_max_shard为128,bucket对象数量阈值变为2560万,已经满足大部分场景的需求,同是,对性能的影响很小。所以此次我们采用此方法来处理告警,方法如下:
- 先找到出现问题的pool
ceph health detail
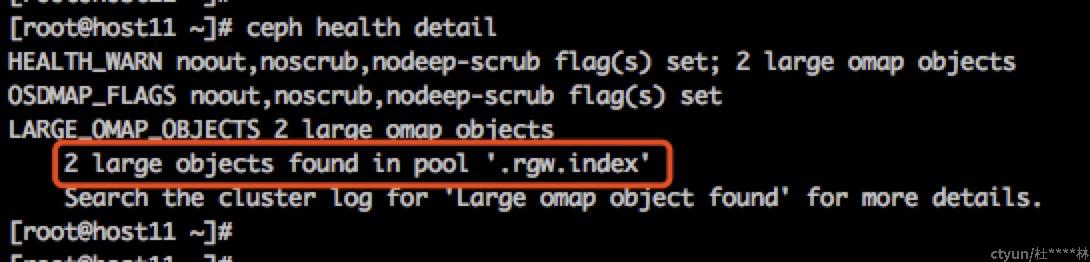
- 找到对应的PG
ceph pg ls-by-pool |awk '{print "ceph pg "$1 " query|grep num_large_omap_objects"}'|sh -x

- 找到对应的OSD
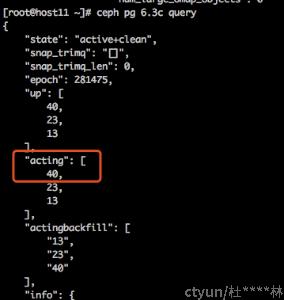
- 查看OSD日志找到bucket
zcat ceph-osd.40.log-20190614.gz |grep omap

- 根据对象ID确定bucket名称
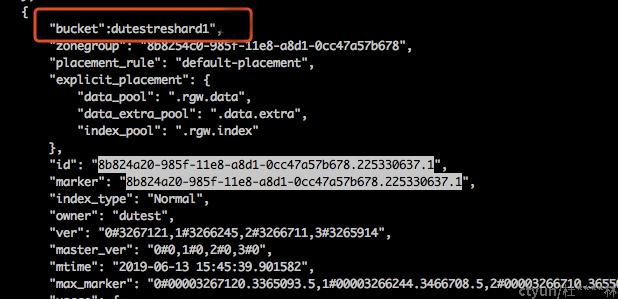
radosgw-admin bucket stats --bucket-id=8b824a20-985f-11e8-a8d1-0cc47a57b678.225330637.1 > buckets.json
有报错可以忽略,查看buckets.json,根据关键字8b824a20-985f-11e8-a8d1-0cc47a57b678.225330637.1找到bucket名
- 备份原bucket的index为本地文件
100W个对象的index大约占用1GB备份文件空间
radosgw-admin bi list --bucket=dutestreshard1 > dutestreshard1.list.backup
若后续操作出现问题,恢复index的操作为
radosgw-admin bi put --bucket= < .list.backup
- 修改zonegroup的bucket_index_max_shards
此值不宜过大不宜太小,依据集群规模和单桶对象数设计,每个shard超过20W条index就会产生告警
radosgw-admin zonegroup get > zonegroup.json
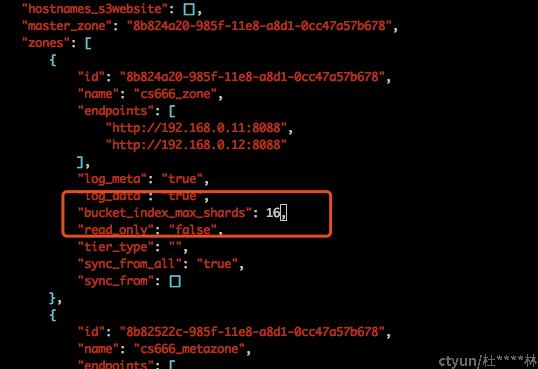
radosgw-admin zonegroup set < zonegroup.json
radosgw-admin period update --commit
- 关闭所有rgw,避免reshard操作时新数据变更
systemctl stop ceph-radosgw.target
- 执行bucket reshard操作
注意记录新老bucket id, 100W对象reshard时间约30秒
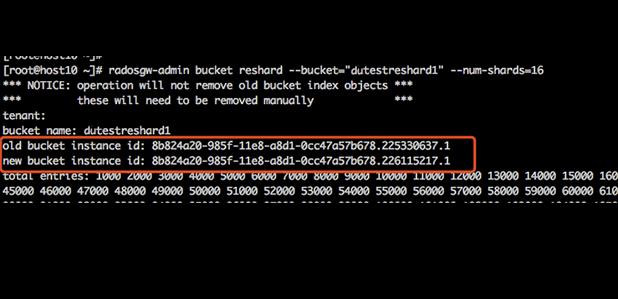
- reshard后检查,bucket id和marker信息应改变
- 启动rgw,验证数据正确性和bucket可操作性
systemctl start ceph-radosgw.target
- 删除reshard前的旧的bucket index instance,
注意此处的bucket-id为第九步的old bucket instance id,删除耗时较久,耐心等待其执行完成
radosgw-admin bi purge --bucket="dutestreshard1" --bucket-id=8b824a20-985f-11e8-a8d1-0cc47a57b678.225330637.1
总结
从以上处理步骤可以看到我们主要通过提高bucket的shard数量和单个shard的object数量,来处理large omap objects告警,单个bucket的对象数量还是存在理论上阈值,为了保持存储环境的可靠性和数据安全,在规划数据存储环境时,应该根据业务数量规模,合理规划bucket相关参数,同时,对使用业务方进行相关知识普及,引导使用者根据业务类型、数据类型、组织架构等规划不同的bucket,避免出现超大数量规模的bucket,为数据存储服务可靠、安全、高效保驾护航。
