


现象
小程序调这个接口感觉延时明显 /h5/v1/share/trip
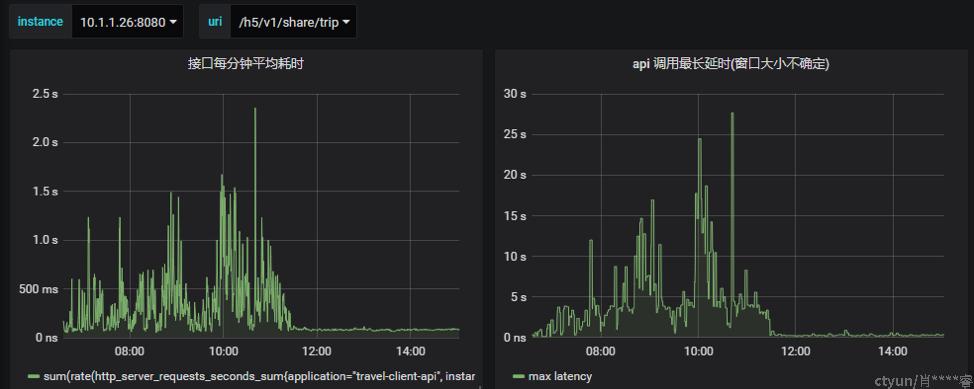
小程序统计的延时见截图 ,时间范围是一天内平均:
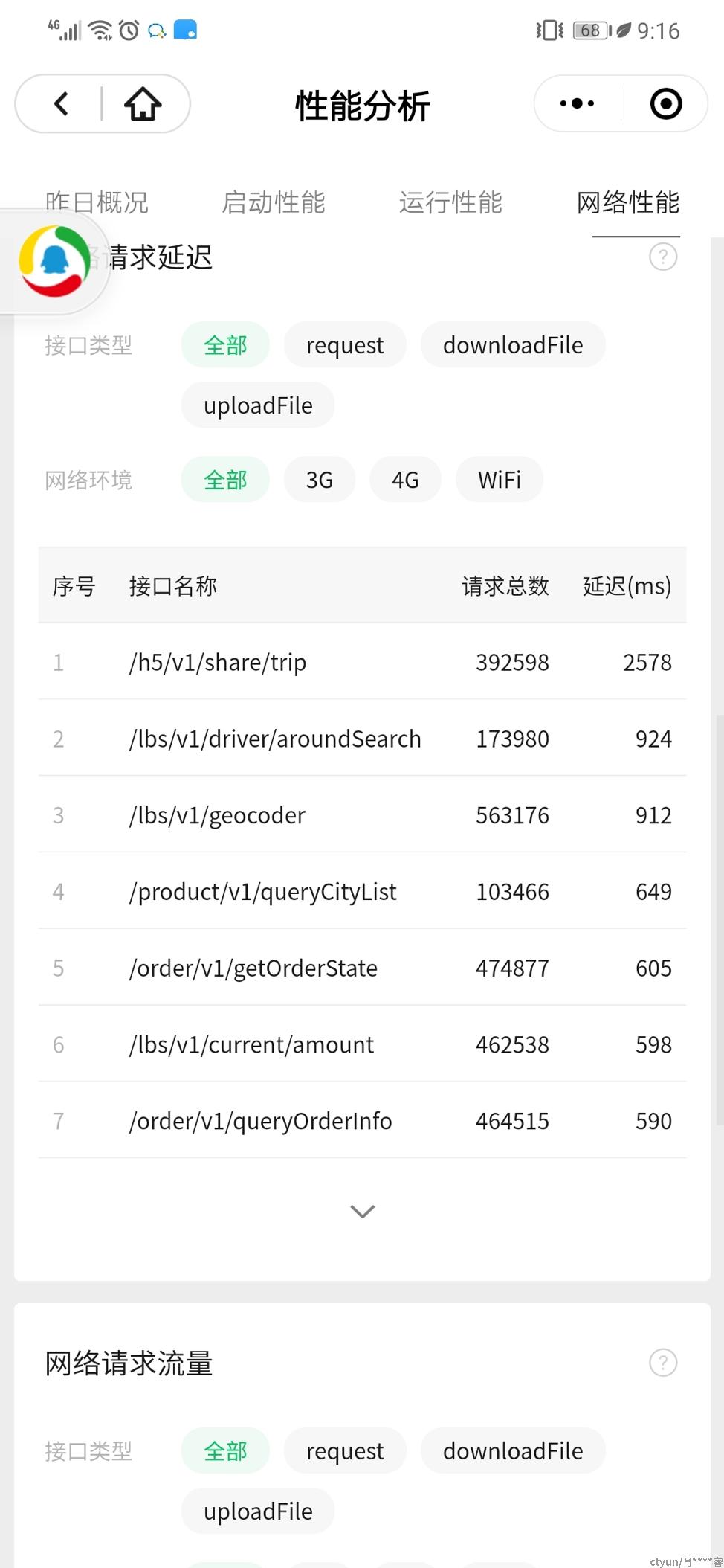
图1
后端小程序api服务的日志切面统计的耗时:
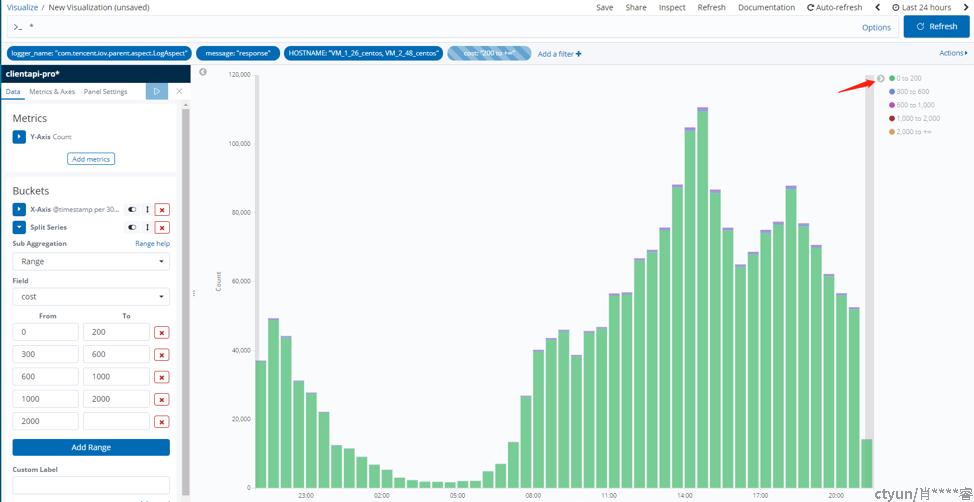
图2
后端metrix收集的服务监控
http_server_requests_seconds_sum/http_server_requests_seconds_count 与 http_server_requests_seconds_max:
即接口平均耗时和最大耗时
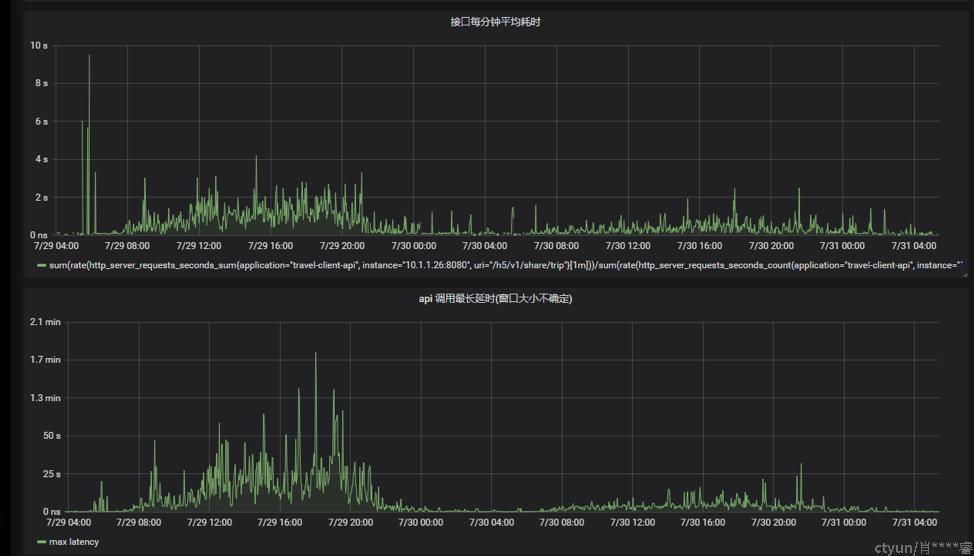
图3
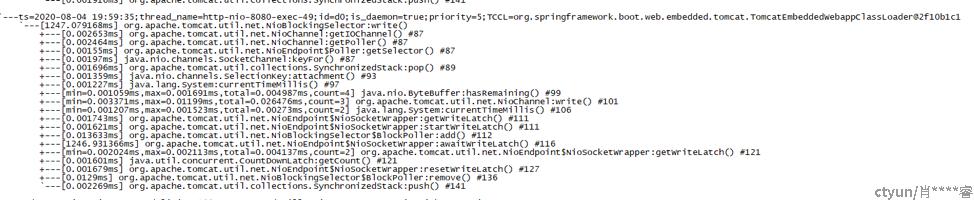
抽一个traceId去看调用链:
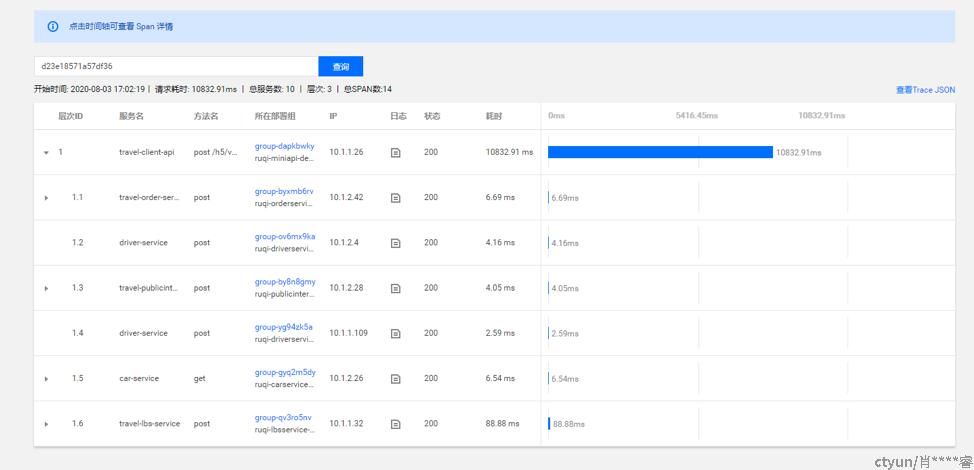
图4
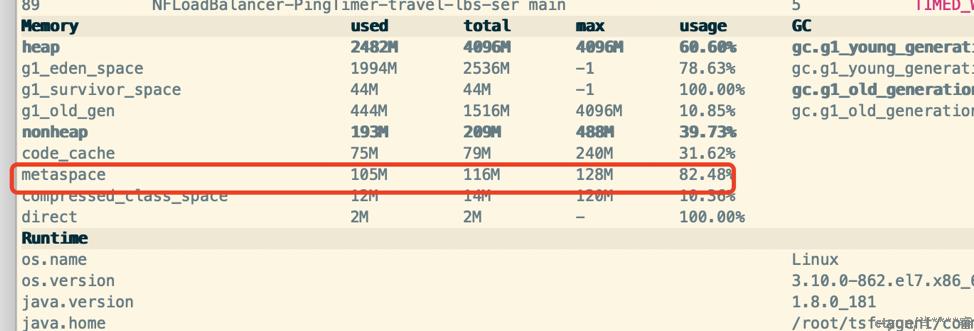
图5
排查过程
图1小程序给的统计来看,share trip接口的平均耗时非常突出。
图2日志切面统计的耗时,绝大多数调用都在200ms内,日志切面覆盖的范围包括controller层以及api服务调用其他各服务的耗时。说明其他服务没问题,业务处理的代码也没问题。
图3是spring boot自带的统计上报,不太确定其范围,不过可以看出服务内的耗时已经很高。
图4的调用链看,在小程序api内耗时很高,而且是其他服务都早已返回。
图5的机器jvm的metaspace有点高。
另外,查看kibana上的日志发现,慢调用的trip接口返回的报文非常大。约200KB以上。
有一些疑点:
如果是http线程阻塞,应该所有的接口慢的机会均等。
部署机器内存和CPU不高。jvm的metaspace有点高。metaspace配置过低,max只有128M。
报文大就慢,可能是序列化慢,或者是网络拥堵。
初步怀疑metaspace问题,本着先抢通后抢修原则,且网络出事概率远低于其他可能,先加metaspace,扩容机器。
原来小程序api有2个机器,配置都是4核16G,启动参数中jvm堆内存是4G,metaspace是128M。
先加了2台机器8核16G,然后老机器未调整配置,启动参数改为堆内存8G,metaspace 1G。两个操作大概间隔了半个小时。观察发现加机器效果比较明显,老机器调参数没有明显再改善了。
好了,充钱变强之后暂时扛住了,然后我们开始定位问题,
为了避免以后再次踩坑。
而且奇怪的是,生产上还是有零星的慢调用,10s以上的那种。
首先尝试postman直接调用服务,大报文的情况,看能否复现问题。
运气不错,复现了,猜想是对的,跟大报文直接相关。
到机器上用arthas跟踪线程,从spring mvc的 dopost接口开始,滤除cost>3s的,逐层下钻。
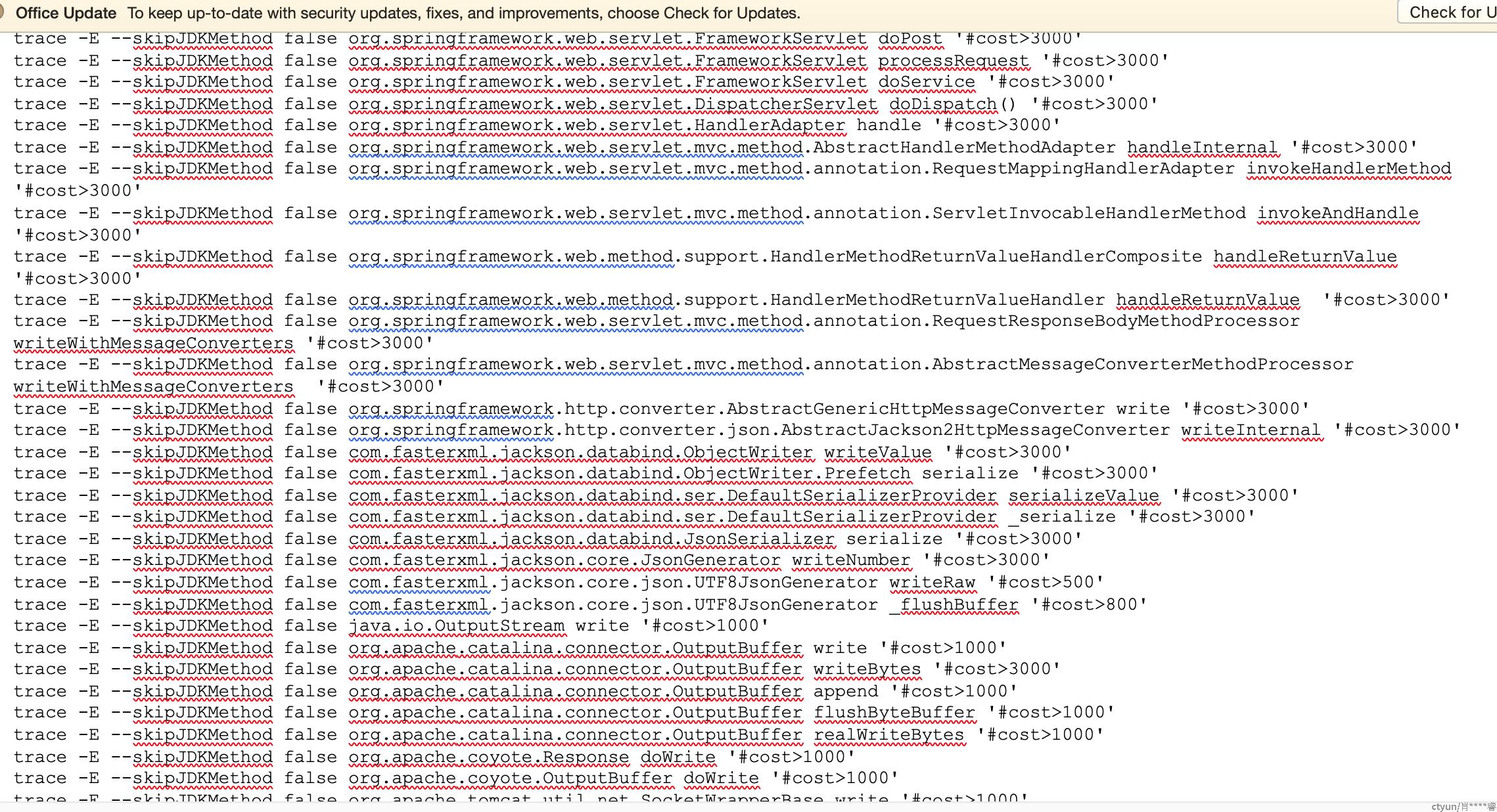
中途遇到json序列化方法慢(16行附近),以为找到了问题,后面逐渐深入,发现是IO,最后不得不怀疑网络。
尝试绕过域名,直接postman调阿里云服务器,发现直连机器调用非常快,持续稳定在300ms左右。
并且在测试环境上稳定复现。用jmeter尝试多次调用,依然稳定复现,在同时并发调用下,走域名经过负载均衡,100%慢。

好了,现在可以怀疑是网络问题了,而且我们有证据。
得出初步结论:小程序4台部署机,其中2台的公网带宽只有1M。

马上冲钱,带宽加到10M,马上稳了。
从下图的监控看,share trip接口几乎一瞬间恢复宁静。
所以当时新加两台机器之所以管用,是因为加的机器是10M带宽的,且分摊走了流量。
结论
真的是网络问题。
服务经过负载均衡走到外网,需要买带宽。就是下图箭头标注出的这个。

如何解决
1.开源
首先检查一下机器的带宽配置,如果是1M的就果断加。
如果到了限制带宽,所有接口都会不同程度变慢。
查看节点流量监控可以看当前节点的公网出流量。
2.节流
可以在服务上配置压缩http返回体,也试了一下可以解决问题。
server.compression.enabled=true
它的副作用是耗CPU,如果服务本身CPU很闲的话(大多数是的),就可以尽情压榨它。
它还有一些别的参数,比如超过多少字节才压缩之类的,没怎么研究就不写在这里了。
注意:
- 方案2是可选的。
- 云上服务之间的调用是走内网的,不需要这个带宽。所以只有通过公网暴露出去的服务才要关注
- 无论如何,网络都是最后怀疑的对象,不要动摇这个原则
