


TELEDB是中国电信集团公司打造的高可用、分布式数据库,为电信及其合作伙伴提供基于交易或订单系统的容灾级别(业务级别),解决了海量交易情况下,单个数据库的性能瓶颈。
一、TELEDB架构及原理
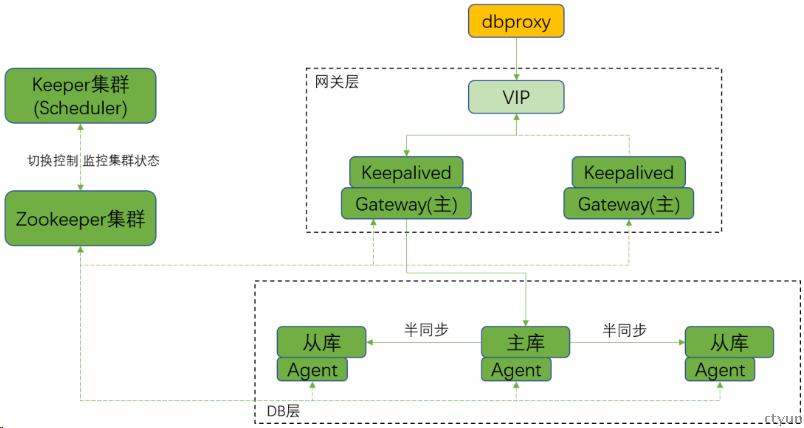
TELEDB 核心的模块包括:数据库节点(Set)、Zookeeper 组件、Agent 组件、Keeper(Scheduler)、网关层(Gateway+Keepalived)。
(1)数据库节点(Set)
由多个 MySQL5.7 数据库组成,一个数据库节点组(Set)包括:一个主节(Master)、若干备节点(Slave_n)。
(2)Zookeeper 组件
组成 Zookeeper 集群,集群用于存储 TELEDB 的关键配置信息,当配置信息有变动或修改时,第一时间发送变动或修改至数据库各个节点。Zookeeper 是由多台(3 台或 3 台以上)服务器组成了Zookeeper集群,提供高可用的服务。
(3)Agent 组件
部署在底层 DB 数据库服务器上,负责向Zookeeper 上报底层数据库的状态(是否可读写,主从复制延迟等信息),在容灾切换过程中配合 Keeper 完成整个切换过程。
(4)Keeper(Scheduler)组件
操作、配置Zookeeper 集群中配置数据的接口服务命令集,同时 Keeper 监控整个集群状态(监听Zookeeper 中由 Agent 上传上来的关于底层 DB 的状态信息),控制容灾切换流程。为了实现高可用性,Keeper 程序运行在多台机器上。
(5)网关层(Gateway+Keepalived)
Gateway监听Zookeeper中关于底层db的状态,转发数据库连接到后端db实例,实现TELEDB的读写分离功能,Keepalived 为Gateway提供VIP。
二、故障回顾
周六上午八点突然收到系统告警“[MySQL服务可用性] 计费充值中心teledb1-vip:服务IP:132.xxxxxx.xxx 无法连接“。目前IBOC对于teledb监控除了各个mysql实例外,还会监控VIP服务的可用性、读写性,一般服务不可用会伴随有实例不可用,但这次只收到服务异常告警,事情肯定没这么简单……
发生故障的是一套一主两从teledb,从TELEDB架构看,服务不可用的可能是底层实例异常,Keepalived异常,Gateway异常,原因很多。
上面提到此次服务不可用没有伴随实例不可用告警,所以我们从外层开始,重点排查Gateway和Keepalived组件,以下是排查过程:
1、测试端口连通性:

2、检查vip及gateway进程
Ip a ; vip挂载正常
ps -ef|grep gateway gateway进程运行正常
3、检查gateway日志
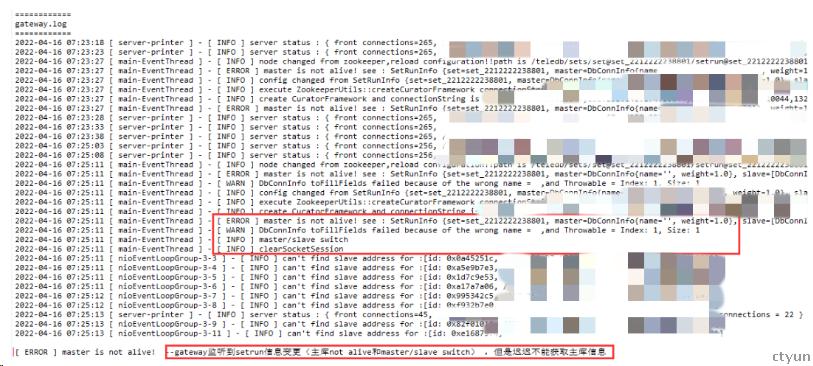
Gateway监听的setrun信息显示主库is not alive,导致转发失败服务不可用。
4、检查主库实例
zk里记录主实例异常,虽然没有实例告警,还是检查确认下,实际检查实例正常。
5、检查Agent
实例正常,但是zk里的节点状态异常,teledb实例状态信息由Agent上传,所以即使在实例正常状态下,如果Agent上报异常也会导致zk中节点状态异常,这也是引进Agent的代价。
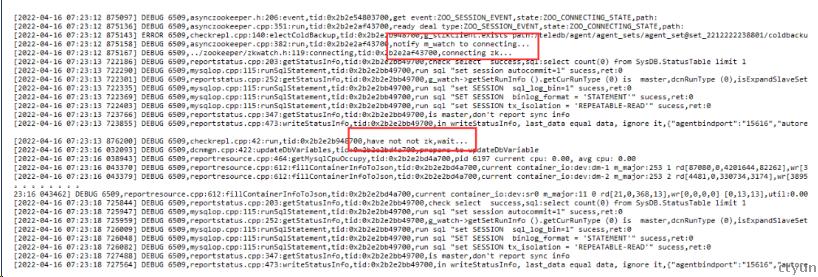
果然我们在Agent的日志查看到了异常,日志报告zk节点切换后,Agent无法上报节点信息。
6、检查keepeer日志
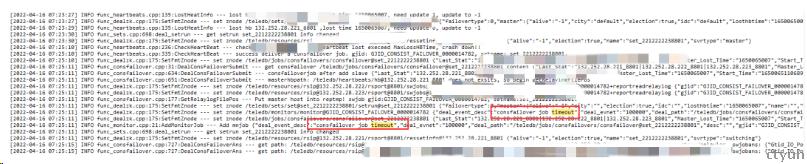
Agent无法上报会导致set状态信息租约到期,Keeper监测到主库心跳超时,将132.252.28.221_8801置为not alive,并发起主从切换,"consfailover job timeout" 这里报告主从切换超时失败。
7、检查从节点Agent日志
Keeper下发切换job,由Agent实施切换,我们进一步分析Agent日志:

日志报告relaylog不断增长。
8、TELEDB切换流程如下
(1)Keeper下发CRONSFAILOVER切换任务
(2)主Agent执行DEGRADE SWJOB
(3)从Agent执行REPORT RELAY SWJOB
(4)Keeper收到两个从库的REPORT结果,选择切换主库
(5)被选中的从库执行RELAY LOG APPLY SWJOB
(6)Keeper收到APPLY成功,设置SETRUN
(7)Agent执行重建主从
这里新主在REPORT RELAY LOG阶段,Agent检测到relay log仍在不断增长。会一直等待。这样导致整个切换过程完成不了。
检查增长binlog日志
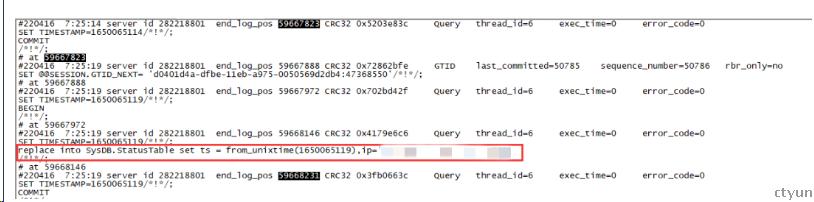
当时vip-port已经无法连接,那主库为什么存在数据变化gtid持续写入,分析增长事物gtid的binlog发现是 Agent一直在写入statustable表(用于监测主从延迟),因为此时旧主Agent无法与zk通信仍然认为自己是主,以binlog打开模式持续写入状态表,从而导致主从切换失败。
至此我们分析整个故障逻辑:zk节点抖动,主库Agent无法自动重连上报状态信息,Keeper将zk中的setrun信息置为not alive,并发起主从切换job,从节点收到主从切换任务,但是Agent检测到relay log仍在不断增长,导致整个切换过程完成不了。
三、故障反思
虽然这次故障是由于zk切换触发Agent的bug导致的,但是江苏对于Agent的监控是通过检查进程是否存活,在这次案例中监控就失效了,导致整个排查耗时较长,如果通过从zk中获取Agent状态将更为准确,这也反映了上云后我们的运维工程师对集团组件的水土不服。开源数据库产品涉及到的组件较多,平时大家要多关注系统架构原理,另外对于各个组件要加强监控,在系统异常时才能够快速准确的定位问题。
