1. 环境准备
1.1 环境信息
软件环境 :Windows 10 家庭版(要求 windows 10系统以上版本)
显卡信息 :NVIDIA GeForce RTX 3060 Ti 8G
1.2 NVIDIA显卡和CUDA安装
第一步,鼠标右键,找到英伟达显卡选项,然后点击进入
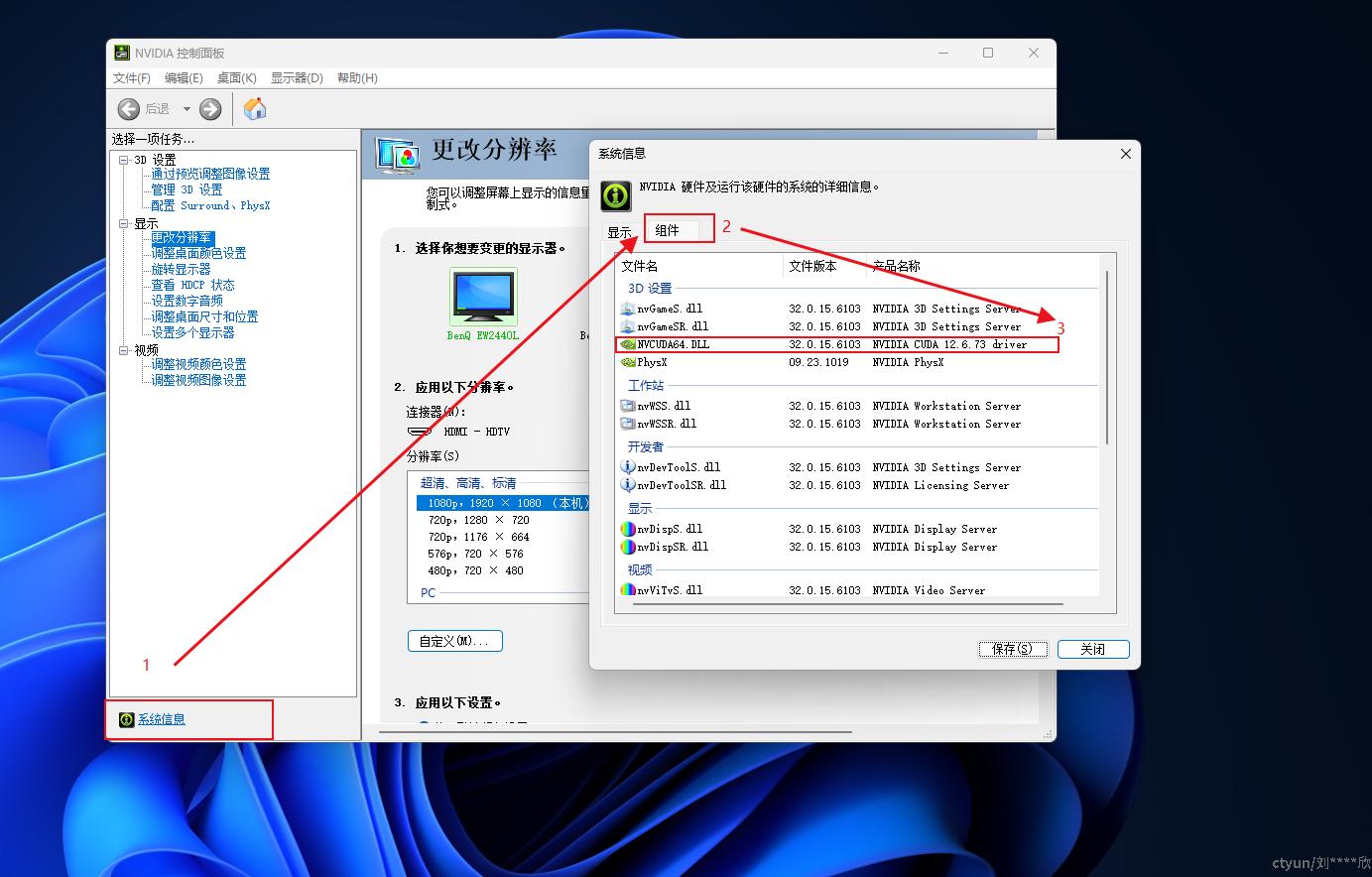
第二步,从【系统信息】->【组件】页面找到CUDA版本信息
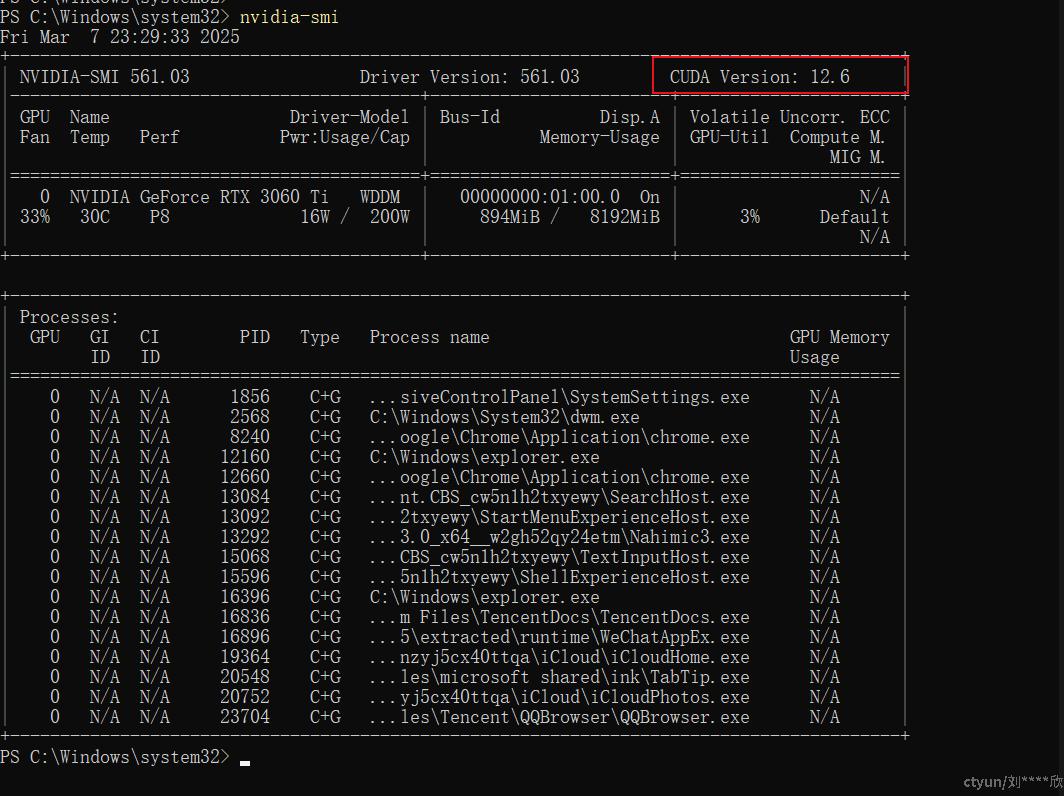
也可以通过执行 nvidia-smi 命令查看CUDA版本
第三步,登录英伟达官网下载对应的CUDA版本,这里需要下载的是12.6版本,英伟达官网CUDA版本下载页面如下:
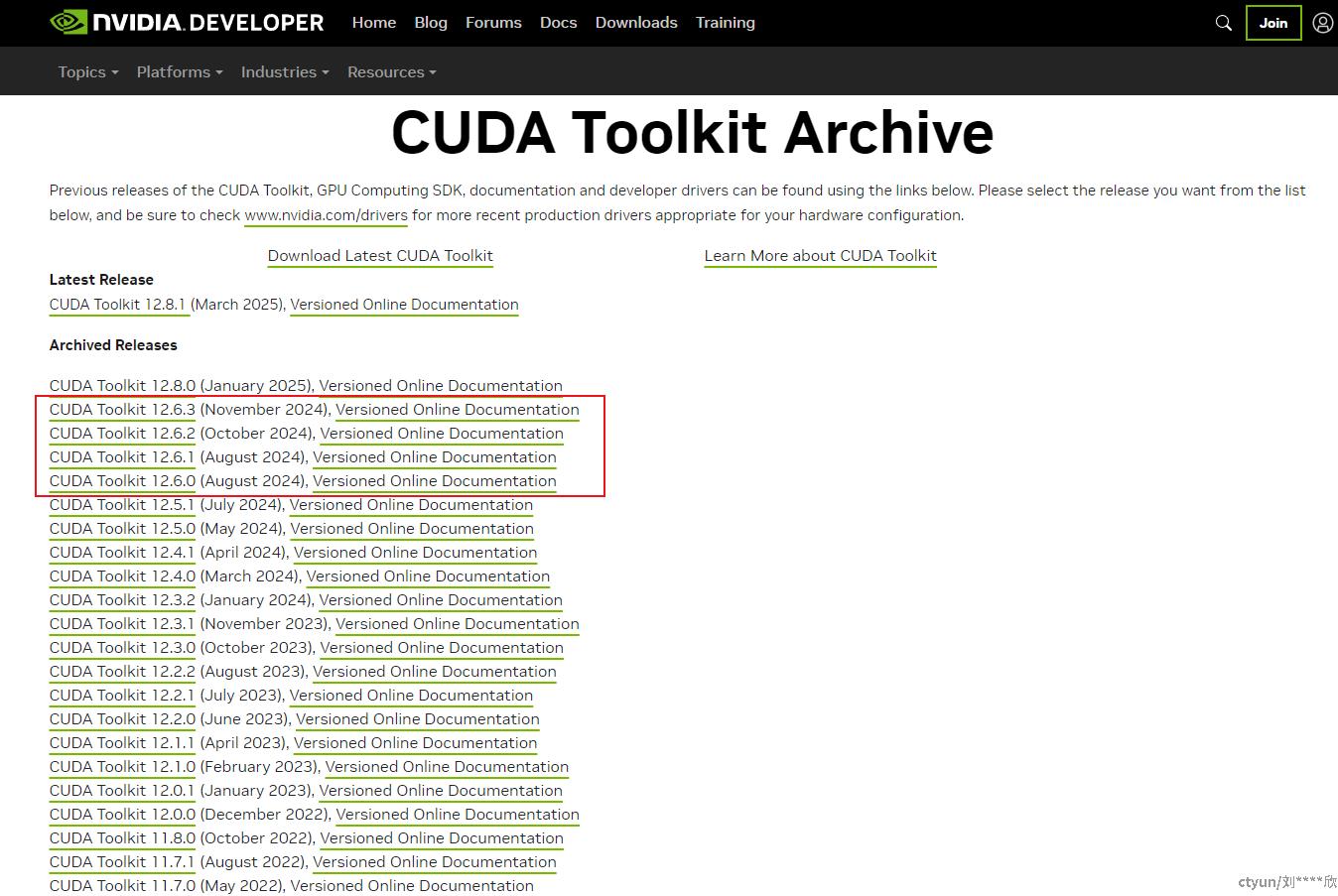
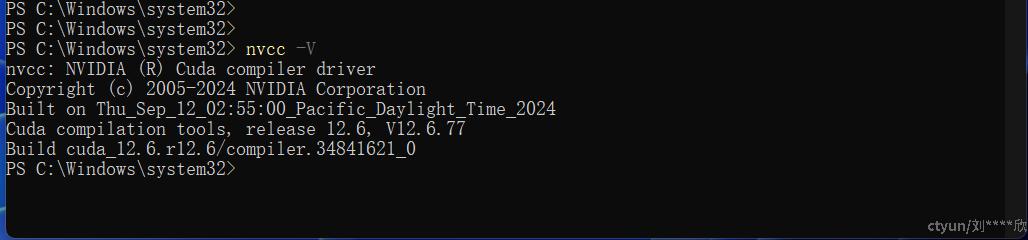
发现CUDA12.6版本一共有4个小版本,需要把它们全下载下来,依次安装。如果安装成功,则执行nvcc -V,如果执行如下图所示,则表示CUDA安装成功
1.3 在系统中给CUDA配置系统变量
点击鼠标右键,打开【个性化】->【系统】->【系统信息】->【高级系统设置】
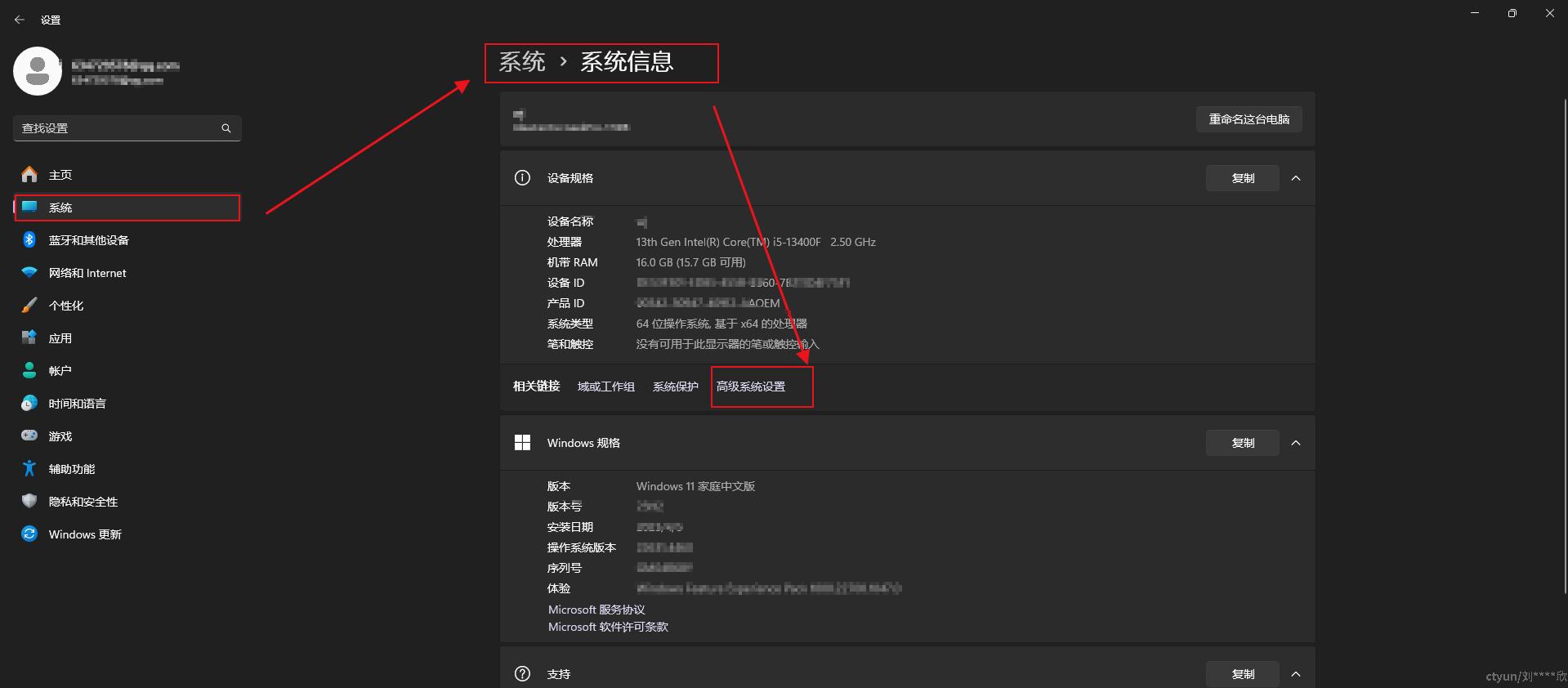
然后打开【高级】->【环境变量】->【系统变量】中【新建】变量,然后把CUDA组件相关信息添加到其中。如下图
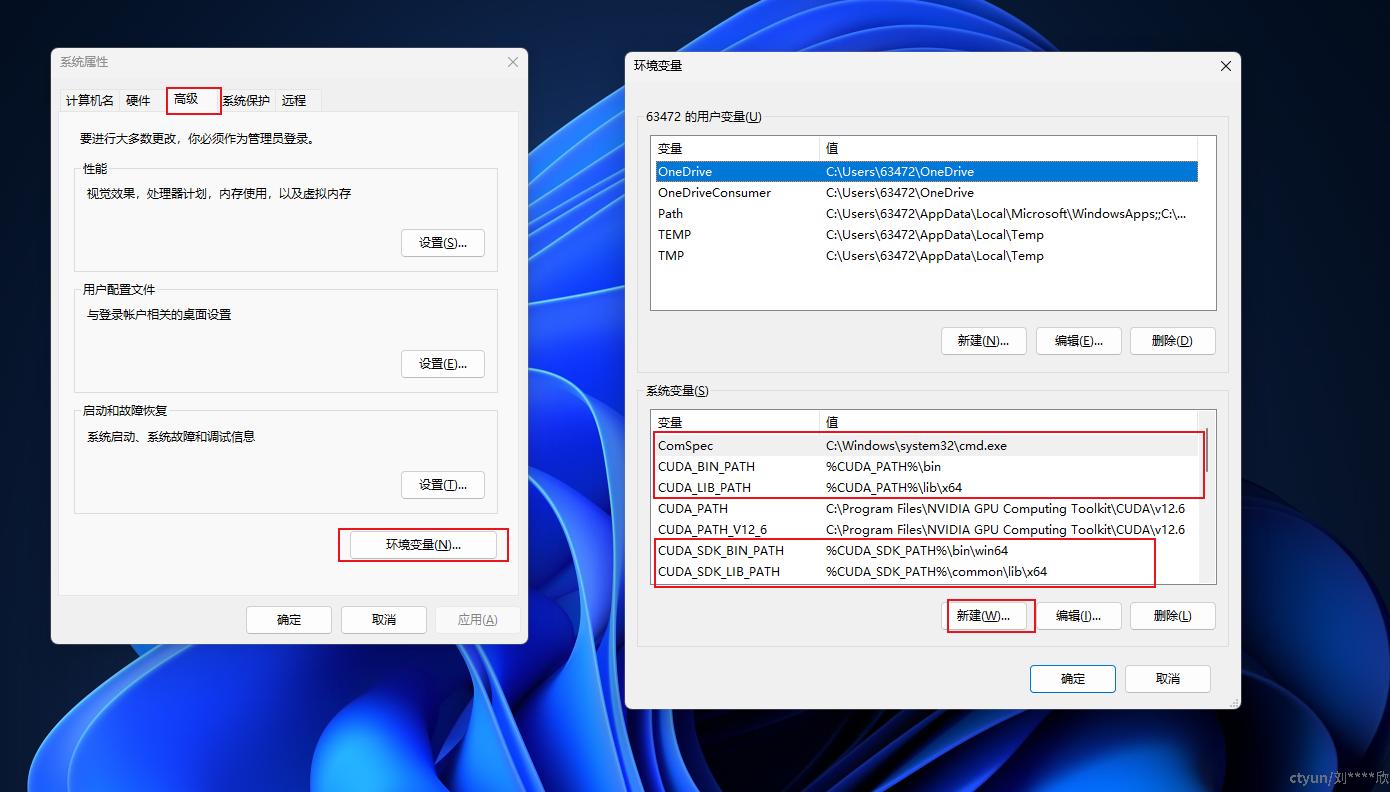
CUDA环境变量如下:
CUDA_SDK_PATH = C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v12.6
CUDA_LIB_PATH = %CUDA_PATH%\lib\x64
CUDA_BIN_PATH = %CUDA_PATH%\bin
CUDA_SDK_BIN_PATH = %CUDA_SDK_PATH%\bin\win64
CUDA_SDK_LIB_PATH = %CUDA_SDK_PATH%\common\lib\x64
2. 安装 Ollama
下载 Ollama :访问 Ollama 官方网站 ,点击 “Download” 按钮,选择 Windows 版本的安装包进行下载。
安装 Ollama :下载完成后,双击安装包 OllamaSetup.exe,按照安装向导的提示进行安装。你可以选择默认安装路径,也可以自定义安装路径。
验证安装 :安装完成后,可以在开始菜单中找到 Ollama 图标,或者在命令提示符中输入 ollama --version,若显示版本号,则说明安装成功。
3. 下载并运行 Qwen 7B 模型
3.1 下载Qwen 7B模型
启动CMD或者PowerShell,准备运行ollama命令
下载模型 :在命令提示符中输入以下命令下载 Qwen 7B 模型:
ollama pull qwen2.5:7b-instruct
3.2运行Qwen 7B模型
启动CMD或者PowerShell,准备运行ollama命令
运行模型 :下载完成后,使用以下命令运行模型:
ollama run qwen2.5:7b-instruct
3.3 检查Qwen 7B模型是否使用GPU运行
把Qwen 7B运行起来后,问大模型一个问题,然后通过 ollama ps 命令查看,如果本地模型使用GPU进行计算,那么PROCESSOR下将显示GPU,如下图

3.4 访问Qwen 7B模型
访问模型 :运行模型后,你可以通过命令提示符与模型进行交互,或者在浏览器中通过localhost加端口号11434的方式访问
web页面显示 ‘Ollama is running ,则表示ollama已启动。
使用 WebUI 与模型进行交互。
4. 安装并使用 Open-WebUI访问大模型
4.1. 安装docker for windows
docker for windows安装包地址可在官网获取
4.2. 下载安装open_webui CPU docker镜像
docker pull ghcr.io/open-webui/open-webui:main
4.3. 启动docker for open-webui
docker run -d -p 4000:8080 --add-host=host.docker.internal:host-gateway -v open-webui:/app/backend/data --name open-webui-cpu --restart always ghcr.io/open-webui/open-webui:main
4.4. 登录并使用Open-WebUI来进行问答
我们使用localhost 加端口号4000登录上,数据创建好管理员后即可进入下面的界面
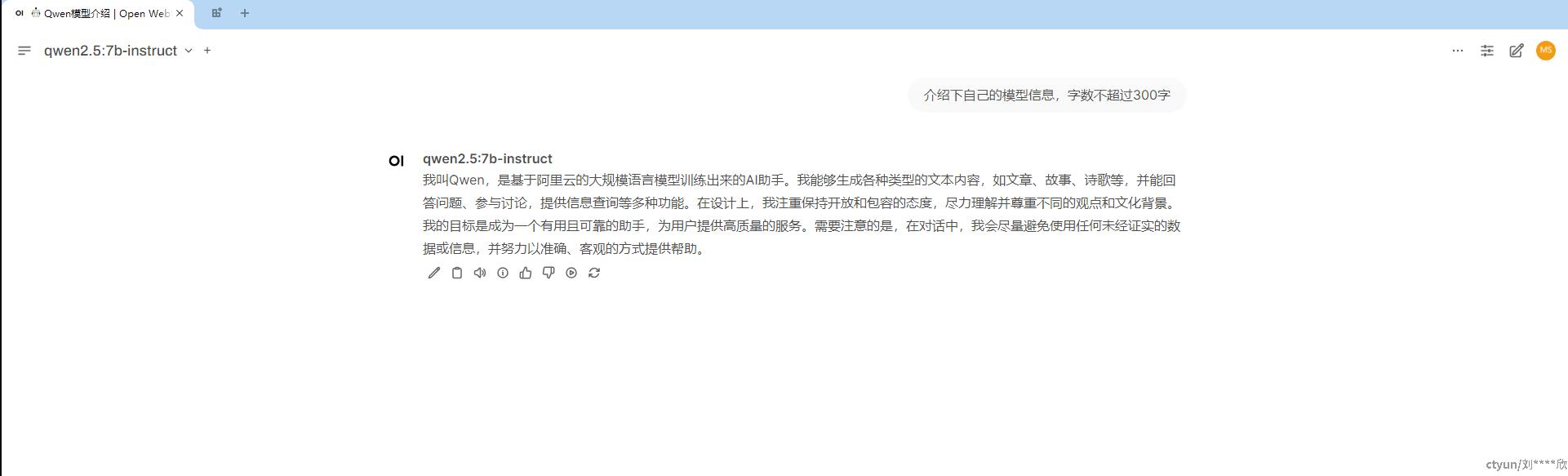
例如我们让Qwen 7B模型介绍下自己,效果如下
成功运行后,通过 ollama ps 命令查看模型使用GPU情况,如下

5. 下载并运行DeepSeek-R1模型
下载DeepSeek-R1的8B,14B,32B大模型,启动CMD或者PowerShell,并运行下面命令如下
5.1. 下载deepseek-r1:8b
ollama pull deepseek-r1:8b
5.2. 下载deepseek-r1:14b
ollama pull deepseek-r1:14b
5.3. 下载deepseek-r1:32b
ollama pull deepseek-r1:32b
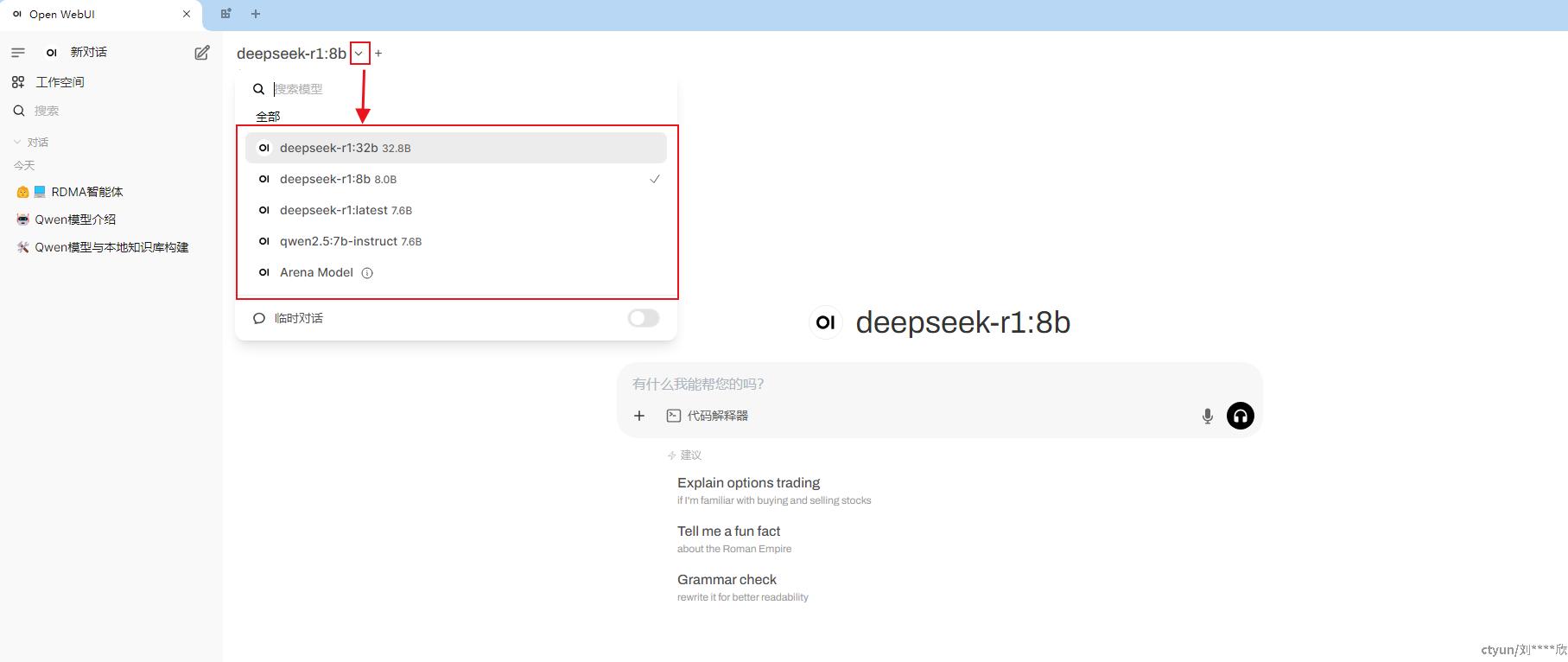
5.4. 在Open-WebUI界面切换大模型
点击下图的箭头,即可看到所有可用的大模型,鼠标选择对应的模型即可。