


在天翼云GPU云主机上使用 Ollama 运行 DeepSeek R1 7B 模型是一个高效且便捷的方式。Ollama 是一个专为本地运行大语言模型(LLMs)而设计的工具,支持多种模型格式,并提供了简单易用的命令行接口。以下是详细的步骤指南,帮助你在天翼云GPU云主机上成功运行 DeepSeek R1 7B 模型。
准备工作
-
天翼云GPU云主机
确保你已经创建了一台天翼云GPU云主机(推荐使用GPU型云主机规格,本文中使用了GPU计算加速性pi7规格pi7.4xlarge.4 规格),并在云镜像市场中选择预置了DeepSeek R1模型的DeepSeek-Ubuntu22.04镜像,如下图所示: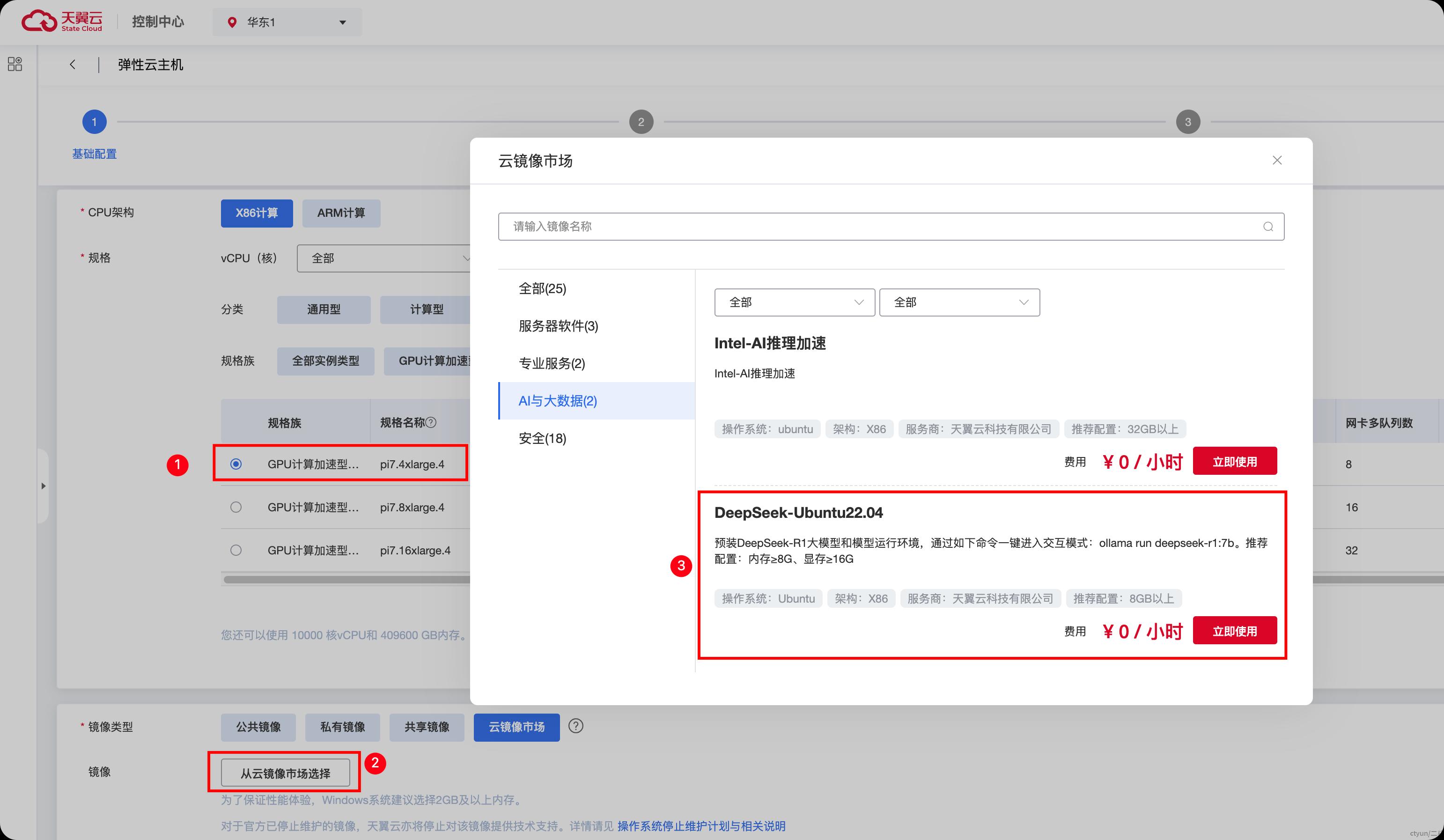
Ollama 支持多GPU 加速,但通常建议使用单个 strong-scaling GPU(即单卡)进行推理。
-
检查NVIDIA驱动和CUDA
Ollama 依赖于GPU加速,因此需要启用并配置 CUDA,GPU型云主机通常会默认安装驱动及CUDA:# 查看 CUDA 版本 nvcc --version # 检查 GPU 是否可用 nvidia-smi
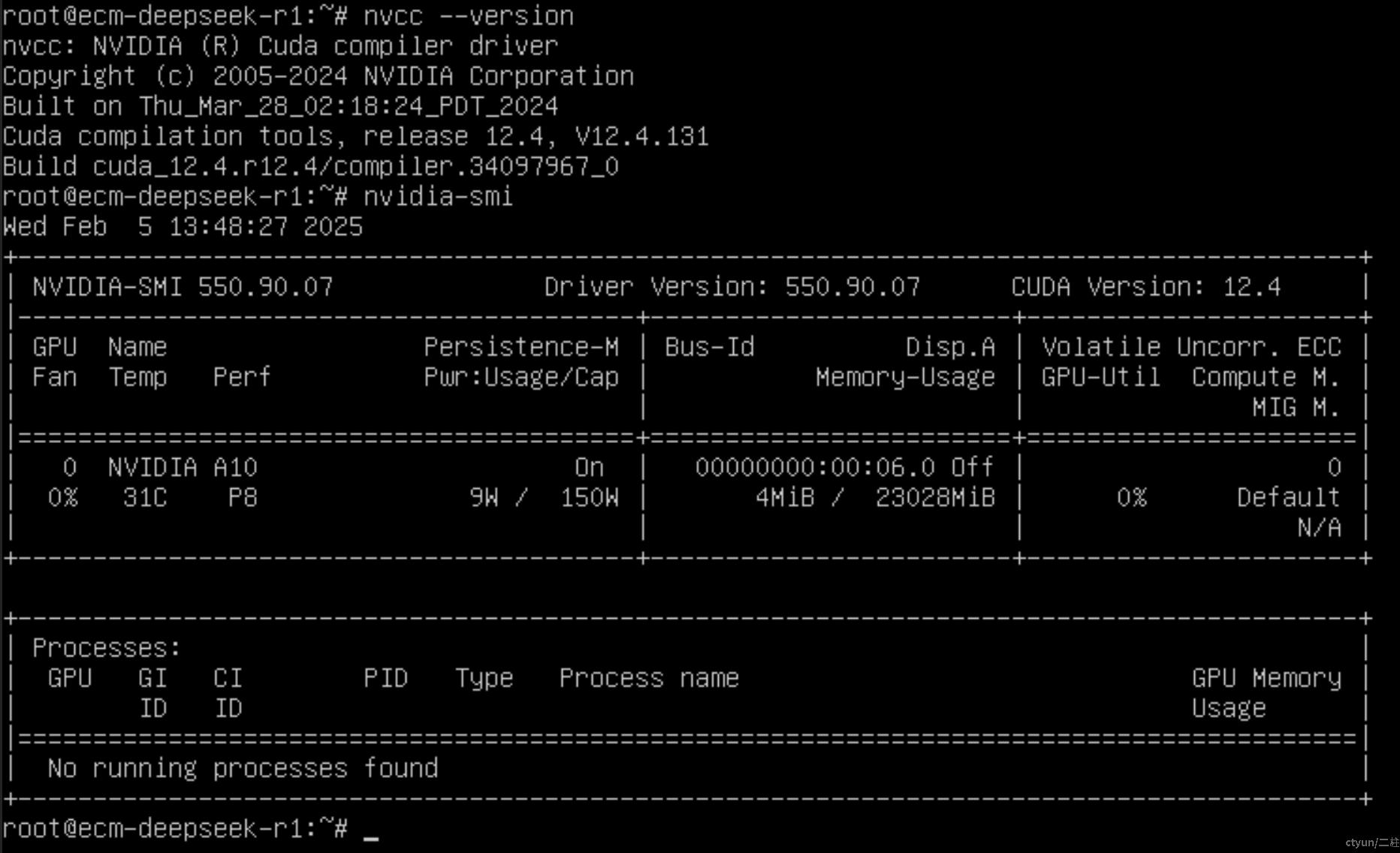
与 DeepSeek R1 7B 交互
由于我们使用了预置了DeepSeek R1 7B模型的DeepSeek-Ubuntu22.04镜像,所以安装ollama和运行DeepSeek R1 7B模型的过程可以省略,预装DeepSeek-R1大模型和模型运行环境,通过如下命令一键进入交互模式:ollama run deepseek-r1:7b 直接就可以在开通的GPU云主机内部玩转DeepSeek R1模型,后面的安装和运行过程仅供参考:
ollama run deepseek-r1:7b

确保 Ollama 使用 GPU 进行推理。可以通过以下命令检查 GPU 是否被正确调用:
nvidia-smi
如果 GPU 未被使用,检查 CUDA 和 Ollama 的配置。
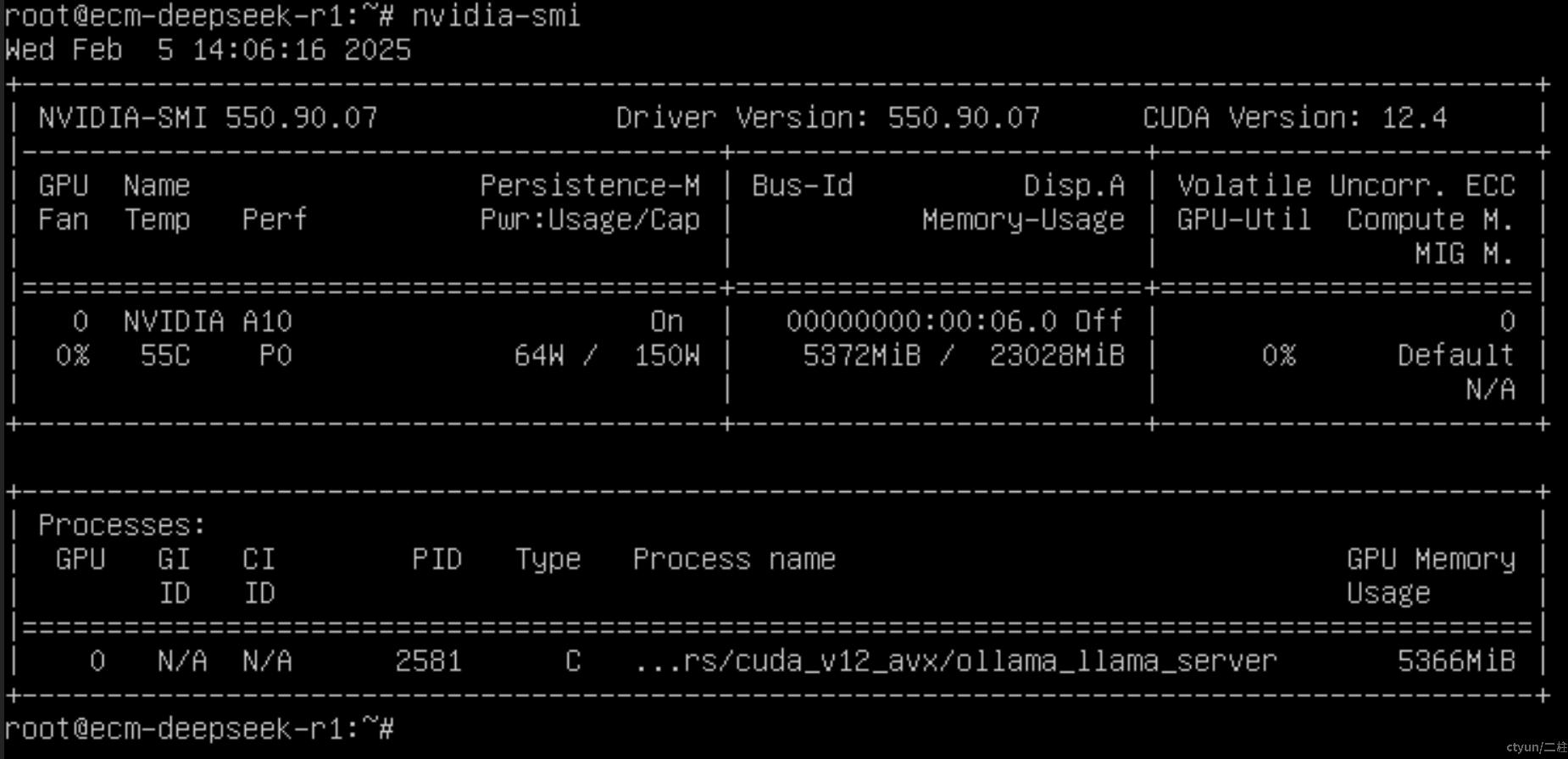
可以看到ollama运行大概消耗GPU内存5366MiB。
安装 Ollama
-
下载 Ollama
访问 Ollama 的官方 GitHub 仓库(https://github.com/ollama/ollama),下载适用于 Linux 的二进制文件:
wget https://github.com/ollama/ollama/releases/download/v0.1.0/ollama-linux-amd64 chmod +x ollama-linux-amd64 sudo mv ollama-linux-amd64 /usr/local/bin/ollama -
启动 Ollama 服务
运行以下命令启动 Ollama 服务:ollama serve
下载并运行 DeepSeek R1 7B 模型
-
下载 DeepSeek R1 7B 模型
Ollama 支持多种模型格式。你可以通过以下步骤下载 DeepSeek R1 7B 模型:- 如果 DeepSeek R1 7B 已经支持 Ollama 格式,可以直接使用以下命令下载:
ollama pull deepseek-r1-7b - 如果模型尚未支持 Ollama 格式,可以将模型转换为 Ollama 支持的格式(如 GGML 或 GGUF),然后加载。
- 如果 DeepSeek R1 7B 已经支持 Ollama 格式,可以直接使用以下命令下载:
-
运行模型
下载完成后,使用以下命令运行 DeepSeek R1 7B 模型:ollama run deepseek-r1-7b此时,你可以通过命令行与模型交互,输入文本并获取模型的生成结果。
优化与部署
-
微调模型(可选)
如果需要针对特定任务微调 DeepSeek R1 7B 模型,可以使用 Hugging Face 或 PyTorch 进行微调,然后将微调后的模型转换为 Ollama 支持的格式。 -
部署为服务
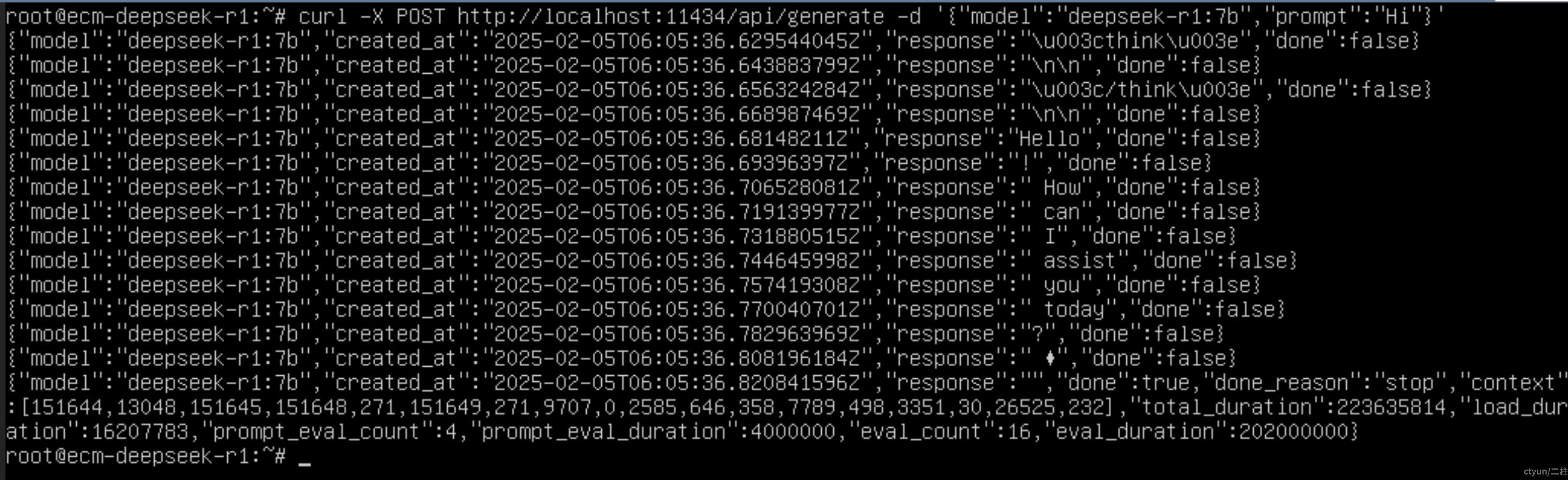
你可以将 Ollama 部署为后台服务,以便通过 API 调用模型:ollama serve &然后通过 HTTP 请求与模型交互:
curl -X POST http://localhost:11434/api/generate -d '{ "model": "deepseek-r1-7b", "prompt": "Hi" }'
总结
通过 Ollama,你可以轻松在天翼云GPU云主机上运行 DeepSeek R1 7B 模型,并享受高效的推理体验。无论是用于开发、测试还是生产部署,Ollama 都提供了一个简单而强大的工具链,还可以非常方便的加载其他大模型,快来尝试吧!
