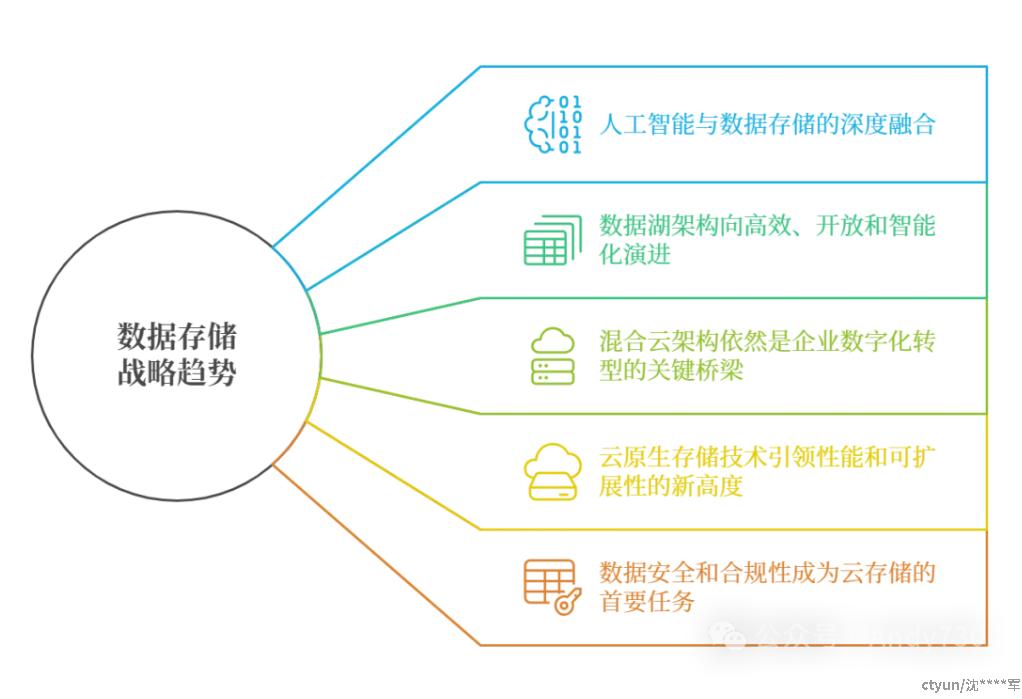
战略趋势
-
人工智能与数据存储的深度融合: AI/ML 已成为数据存储的核心应用场景,数据存储不仅是数据容器,更是支持 AI/ML 的引擎。生成式 AI 推动数据基础设施变革,强调基础模型、提示工程和多模态数据的应用;同时,AI/ML 对高性能存储提出了极高要求,以满足大规模数据处理和训练需求。
-
数据湖架构向高效、开放和智能化演进:现代数据湖以高效、开放和智能化为目标,通过增强性能、提升多区域支持能力以及采用开放表格式(OTF)优化数据查询与更新。此外,数据编目和治理功能至关重要,以确保数据湖的规模化运营和高效管理。
-
混合云架构依然是企业数字化转型的关键桥梁:混合云架构通过高效的数据迁移和同步,简化了云上与本地环境的整合,并提供强大的数据保护与灾难恢复功能,确保跨云平台的数据安全和业务连续性,从而成为数字化转型的重要支撑。
-
云原生存储技术引领性能和可扩展性的新高度: 云原生存储技术通过高性能架构支持大规模计算与存储需求,覆盖 HPC、数据库和大数据分析等场景,同时不断优化性能和成本,为用户提供弹性、可靠的存储解决方案,推动云计算发展。
-
数据安全和合规性成为云存储的首要任务: 云安全依托共享责任模型,结合多层次数据保护、细粒度访问控制等机制,提升用户数据的安全性和合规性,以防止数据泄露、勒索攻击和业务中断,为云存储提供全面的安全保障。
目录
一、 AWS 存储服务概览
STG101 - Introduction to AWS storage: Building a data foundation in the cloud
AWS的多样化存储服务,包括块存储(EBS)、对象存储(S3)、文件存储(EFS、FSx)、数据迁移(Data Sync)和数据保护(AWS Backup、Disaster Recovery)。AWS存储服务支持各类业务需求,如数据湖构建、AI/ML应用、业务关键型应用及数据保护,提供高效的数据访问和集成。客户在迁移、优化及现代化过程中,AWS存储服务发挥了关键作用,尤其是在数据保护和智能分析中。
二、 数据迁移与传输
STG204 - Accelerate & automate secure data transfers at scale with AWS DataSync
AWS DataSync 是托管的数据传输服务,用于加速和简化本地数据中心、其他云平台与 AWS 存储服务之间的数据传输。通过定制协议、并行吞吐量和自动恢复,确保数据传输的可靠性和高效性。支持多种数据源(如NFS、SMB、Google Cloud、Azure Blob、S3等)和目标(如S3、EFS、FSx),广泛应用于数据迁移、保护、归档及 AI/ML 工作负载。DataSync 还提供优化的网络压缩、带宽控制、加密和性能扩展功能。
STG215 - Build hybrid data workflows to Amazon S3 with AWS Storage Gateway
AWS Storage Gateway是混合云存储服务,提供三种网关类型:S3 File Gateway、Tape Gateway 和 Volume Gateway,用于将本地数据高效上传至Amazon S3。S3 File Gateway将本地文件系统通过NFS或SMB映射到S3,支持数据湖构建、数据库备份和冷数据归档。它通过事件驱动工作流和本地缓存提供低延迟数据访问,并与AWS服务如Amazon Athena、SageMaker等集成进行数据处理和分析。
三、 文件存储
STG202 - Network-attached storage in the cloud with Amazon FSx
Amazon FSx提供一系列完全托管的文件存储服务,旨在解决传统NAS存储的可扩展性、管理复杂性和数据迁移难题。支持四种文件系统类型:NetApp ONTAP、OpenZFS、Windows File Server和Lustre,满足不同工作负载的需求。FSx具备高性能、可扩展性、数据保护和与AWS服务的无缝集成,适用于通用文件存储、高性能数据库、虚拟机工作负载以及数据保护与灾难恢复等场景。
STG211 - What's new with file storage
Amazon EFS和FSx文件存储服务的最新功能:涵盖了性能扩展、数据保护、智能分层存储、与AWS服务集成等方面的改进。FSx for OpenZFS引入了智能分层存储,提高了成本效益和性能;FSx for Lustre通过EFA支持降低延迟并提高吞吐量;EFS增强了弹性吞吐量和数据保护功能。还增强了与Amazon S3和AWS Backup的集成,支持灾难恢复和数据分析等应用场景。
STG344 - Simple elastic file systems: A deep dive into Amazon EFS
深入探讨Amazon EFS的架构、功能和用例,重点介绍了其无服务器特性、性能模式和数据保护机制。EFS支持与AWS计算服务如EC2、Lambda、ECS和EKS的集成,提供高可用性、自动扩展和按需付费的存储服务。其性能模式包括弹性吞吐量、预置吞吐量和突发吞吐量,适用于不同的工作负载需求。数据保护功能包括跨可用区持久化存储、备份集成和异步复制,确保数据安全与恢复。EFS广泛应用于内容管理、机器学习和大数据分析等场景。
四、 对象存储
STG207 - Maximize the value of cold data with Amazon S3 Glacier storage classes
Amazon S3 Glacier存储类,专为冷数据设计,通过生命周期策略和智能分层功能优化数据存储和恢复流程。S3 Glacier包含三个存储类:Glacier Instant Retrieval(毫秒级访问)、Glacier Flexible Retrieval(分钟至小时级访问)和Glacier Deep Archive(最低成本、数小时至数天恢复时间)。演讲强调通过自动迁移冷数据至合适存储类以降低成本,并介绍了批量恢复和事件通知等优化大规模数据恢复的最佳实践。客户案例展示了如何通过这些存储类显著节省存储和恢复成本。
STG212 - What's new with Amazon S3
Amazon S3过去一年发布的30项新功能,涵盖了结构化和非结构化数据管理、性能、规模、以及安全性等方面。重点介绍了S3 Tables(基于Apache Iceberg的表格存储服务)和S3元数据功能(用于查询S3元数据),以及其他增强功能如更高的存储桶限制、S3 Express One Zone扩展、机器学习性能优化、简化的数据访问权限管理等。此外,新增的Storage Browser和与Amplify Hosting集成,进一步简化了Web应用的数据上传和管理流程。
STG302 - Dive deep on Amazon S3
Amazon S3的架构与工作机制,数据分布和去相关性策略、Shuffle Sharding算法和AWS Common Runtime(CRT)的协同作用。S3通过数据分片和纠删码实现高可用性和冗余存储,Shuffle Sharding则随机分布数据,避免热点问题并确保负载均衡。CRT库优化S3性能,通过自动重试和并行化请求,使得系统在大规模数据传输中保持高吞吐量和高韧性。
STG323 - Build and optimize a data lake on Amazon S3
如何在Amazon S3上构建和优化PB级数据湖,重点涵盖数据湖的分层架构、数据摄取、查询优化、安全治理和长期管理。通过分层存储(原始数据、处理数据、精选数据)提高数据质量和查询效率,采用Kinesis和AWS Glue等工具进行数据摄取,使用Parquet格式优化查询性能。安全方面,利用IAM、跨账户共享和数据加密实现访问控制和治理。通过生命周期策略和自动化工具优化成本和管理效率,支持如电商平台订单分析等业务场景。
STG328 - Optimizing storage performance with Amazon S3
通过优化Amazon S3的特性提升存储性能,S3 Express One Zone、AWS Common Runtime (CRT)、以及开源数据湖和机器学习框架的性能改进。优化策略包括利用高性能存储类减少延迟、通过并行化提升吞吐量、以及优化数据布局(如分区和排序)提高查询效率。针对不同工作负载(如机器学习训练、数据库查询、大文件传输)提出了具体的优化方案,强调了监控、性能瓶颈分析和请求优化在提升存储效率中的重要性。
五、 块存储
STG205 - Protect critical data with ease using Amazon EBS snapshots
如何通过Amazon EBS快照保护关键数据,重点介绍了其增量机制、加密选项、跨区域复制、快照锁等安全特性,并阐述了EBS快照在数据备份、灾难恢复及合规性方面的应用。特别强调了RISE with SAP中的EBS快照使用,确保数据安全和不可变性。还介绍了Amazon Data Lifecycle Manager (DLM) 用于自动化快照生命周期管理,并通过快照回收站功能防止意外删除。
STG213 - What's new with Amazon EBS
Amazon EBS的最新功能,包括性能提升、韧性增强和安全性强化。重点讲解了io2bx卷的架构和优势,提供高达256000 IOPS的卷级性能和42万 IOPS的实例级性能,支持高持久性和低延迟。还讨论了EBS的多可用区部署、卷状态检查、暂停IO操作等韧性特性,以及CloudWatch指标、NVMe统计信息和故障注入模拟器等性能监控工具。此外,演讲还介绍了EBS快照的灾难恢复功能,包括跨可用区和跨账户复制,以及弹性灾难恢复(EDR)技术。
STG329 - Maximizing performance for high-intensity workloads using Amazon EBS
Amazon EBS io2 Block Express (io2bx) 卷如何满足高强度工作负载的性能需求。io2bx提供高达256000 IOPS、4000 MB/s吞吐量和亚毫秒级延迟,适用于关键任务型应用。它基于Nitro系统和NVMe协议,支持跨多个可用区部署,提供99.999%的持久性。通过卷条带化、I/O合并和CloudWatch监控等方法,可以优化性能。实际应用案例包括Epic系统、SAP HANA和McAfee数据库,均展现了io2bx在性能和成本优化方面的优势。
六、 数据保护与灾难恢复
STG203 - What's new with AWS Backup
AWS Backup的最新功能,数据保护、勒索病毒防护和灾难恢复。AWS Backup通过策略驱动的管理,支持跨服务、跨账户备份,并提供逻辑隔离保险库、服务拥有密钥和还原测试功能,以应对勒索病毒威胁。新功能包括跨区域和跨账户备份、S3备份的版本还原和改进的成本计算器。实际应用案例包括Freddie Mac和Skyscanner,展示了AWS Backup在数据保护和恢复方面的应用。
STG301 - Data protection and resilience with AWS storage
AWS存储服务如何帮助企业构建数据保护与韧性策略,应对数据丢失、停机、自然灾害和勒索病毒等威胁。内容包括AWS的数据保护责任共担模型、存储服务组合(EBS、S3、EFS等)、数据保护架构(多可用区部署、备份和复制、S3和EBS数据保护)以及AWS Backup的集中式备份管理、不可变备份、还原测试和合规性功能。
STG339 - Beyond 11 9s of durability: Data protection with Amazon S3
Amazon S3如何通过设计和技术(如纠删码、Shuffle Sharding)实现11个9的持久性,并介绍了如何使用S3的功能(版本控制、复制、对象锁等)增强数据保护,防止意外删除、覆盖和勒索病毒攻击。通过跨可用区冗余、MFA删除和多区域访问点等功能,S3为数据提供高可用性与安全性。
STG409 - Building resilience against ransomware using AWS Backup
通过AWS Backup,企业可构建抵御勒索病毒的韧性数据保护体系,包括3-2-1-1策略支持、逻辑隔离保险库、策略驱动的增量与连续备份,以及自动化恢复测试;结合Amazon GuardDuty等安全服务快速检测攻击,实施分层备份、严格权限控制和定期恢复验证,确保数据完整性与业务连续性,抵御复杂攻击威胁。
七、 数据湖和AI/ML
STG201 - Build a data foundation to fuel generative AI
构建支持生成式AI的数据基础需要结合RAG和微调等方法,重点在数据发现、准备与治理,利用Amazon S3实现经济高效的对象存储,满足数据检索与处理需求;对于高吞吐量与低延迟要求的训练任务,采用Amazon FSx for Lustre优化性能;根据应用目标制定数据与存储计划,在保障安全与合规的同时实现生成式AI的高效部署。
STG208 - Data on AWS: The key to success for 3 AI innovators
三家AI创新公司如何在AWS上构建和优化数据基础设施以支持生成式AI模型。Canva使用AWS服务构建可扩展数据平台,优化数据处理和质量管理;Bria AI利用Amazon S3和FSx for Lustre进行大规模数据处理,提升效率并减少处理时间;Anthropic专注于数据安全和隐私,使用AWS的安全功能如IAM和KMS构建负责任的AI系统。
STG327 - High-performance storage for AI/ML, analytics, and HPC workloads
Amazon S3和Amazon FSx for Lustre如何为HPC、AI/ML和分析工作负载提供高效、可扩展的存储解决方案。重点讨论了这些工作负载的存储使用模式,如数据加载、检查点设置和结果存储,并分析了吞吐量、延迟和数据访问模式等关键因素对存储性能的影响。Amazon S3适用于长期存储和数据湖,而FSx for Lustre则用于需要高吞吐量和低延迟的场景,许多客户结合使用两者以优化存储性能。
STG332 - Accelerate database performance and scalability with AWS storage
如何利用Amazon EBS和Amazon FSx提升数据库性能、可扩展性和成本效益。重点介绍了EBS卷类型(如gp3、io2和io2 Block Express)及其适用场景、快照管理、数据生命周期管理和弹性卷功能,以及FSx文件系统(如NetApp ONTAP和OpenZFS)在高性能数据库中的应用,包括数据迁移、保护功能和高可用性部署。通过这些服务,企业可以优化数据库存储、提高性能、确保高可用性并降低成本。
八、 安全性和访问控制
STG304 - Amazon S3 security and access control best practices
Amazon S3安全和访问控制最佳实践,包括通过桶策略、访问点、IAM策略和Lake Formation实现精细化访问控制;利用资源控制策略、访问分析器和日志(服务器访问日志与CloudTrail)进行安全审计;以及通过S3访问点和访问授权实现更高级的权限管理。重点强调最小权限原则、版本控制、多重身份验证(MFA)、加密和自动化工具的使用,以确保数据安全性和合规性。
九、 托管文件传输
STG305 - Modernize managed file transfer with SFTP
AWS Transfer Family通过支持SFTP等多种协议、灵活的身份验证和访问控制、自动化工作流集成及与Amazon S3的无缝衔接,提供托管、安全、可扩展的文件传输解决方案;它降低了传统自建SFTP服务器的管理和安全复杂性,支持事件驱动的数据管道和智能化处理,同时简化了与外部系统及非技术用户的集成,满足现代化数据传输需求。
十、 成本优化
STG210 - AWS storage best practices for cost optimization
通过迁移到AWS存储服务并结合按需付费模式、合适的存储类型(EBS、FSx、EFS、S3)、优化工具(如GP3升级、智能分层、生命周期策略)、以及数据压缩和去重等功能,企业可显著降低存储成本,提升资源利用率,同时满足性能和扩展性需求;真实案例表明这些策略能够快速实现可量化的成本节省和高效的存储管理。
AWS存储服务列表
- Amazon S3 Glacier: 低成本归档存储,适合长期保存不常访问的数据。
- S3 Intelligent-Tiering: 自动根据数据访问模式调整存储层级,优化成本。
- S3 Express One Zone: 低延迟对象存储,适用于需要快速访问的数据。
- S3 Multi-Region Access Point: 提供多区域 S3 存储桶的统一虚拟端点访问。
- Amazon EBS io2 Block Express: 提供亚毫秒级延迟和 99.999% 持久性,适用于关键任务应用。
- Amazon EFS: 高吞吐量、可扩展的文件存储,支持快速数据恢复。
- FSx for Lustre: 针对 HPC、AI/ML 优化的高性能文件存储。
- FSx for NetApp ONTAP: 提供与 NetApp 相同的企业级文件存储功能。
- FSx for Windows File Server: 原生 Windows 文件共享功能。
- FSx for OpenZFS: 基于 OpenZFS,提供智能分层存储优化。
- AWS DataSync: 支持本地与云、跨云的数据迁移。
- AWS Backup: 逻辑隔离保险库: 增强备份分组和访问控制。 恢复测试: 定期验证还原点的有效性。
- AWS Elastic Disaster Recovery (AWS DRS): 提供快速灾难恢复,通过持续复制和实例启动支持应用恢复。
- AWS Storage Gateway: 提供本地与 AWS 云存储连接,支持文件、卷和磁带网关。
- Amazon SageMaker 与 FSx for Lustre: 提供优化的 AI/ML 数据存储和访问功能。
- AWS Glue 与 S3: 支持数据湖的 ETL 和数据处理。
- Amazon Athena 与 S3: 通过 SQL 查询分析 S3 中的数据。
- Amazon Kinesis Data Firehose 与 S3: 实时数据流传输至 S3。
STG101-Introduction to AWS storage: Building a data foundation in the cloud
本演讲从企业上云的实际需求出发,全面介绍了AWS云存储服务组合及其与其他AWS服务的集成,重点阐述了数据迁移、数据湖构建、人工智能与机器学习、数据保护和业务关键型应用程序等关键应用场景的技术实现和最佳实践。
AWS提供全面且多样化的存储服务,涵盖了块存储、对象存储、文件存储以及数据迁移和数据保护服务,能够满足企业各种规模和类型的数据存储需求。
块存储:Amazon Elastic Block Store (EBS)
对象存储:Amazon Simple Storage Service (S3)
文件存储:Amazon Elastic File System (EFS), Amazon FSx
数据保护:AWS Backup, AWS Disaster Recovery
AWS存储服务与其他AWS服务无缝集成,为分析、机器学习、高性能计算、可视化和流媒体等工作负载提供对数据的无缝访问。
典型的AWS客户上云之旅始于应用程序迁移,通常采用直接迁移的方式。
迁移完成后,客户会继续优化其应用程序,利用额外的AWS服务和创新进行现代化改造。
AWS存储服务在每个阶段都发挥着至关重要的作用,帮助客户构建强大、可扩展且经济高效的云数据基础。
超过1万家客户选择在AWS上使用Amazon S3构建数据湖。
他们选择AWS存储服务构建数据湖是因为:数据迁移是构建数据湖最困难的部分之一。将所有数据存储在S3中,客户能够利用AWS中的分析功能,无需将数据移动到AWS云的不同部分。
数据湖是AI/ML的绝佳数据基础,客户可以使用AI和ML从这些数据中获取洞察力。
许多客户将AWS用于其业务关键型应用程序,例如ERP解决方案、数据库和内容管理系统。
客户通常从直接迁移开始,然后通过利用AWS的各种存储选项来优化其应用程序,以满足不同工作负载的需求。
例如,SQL Server可以部署在Amazon EC2、Amazon RDS或容器化环境中。
虚拟化工作负载可以使用Amazon EBS或Amazon FSx来存储数据。
Amazon S3和Amazon FSx for Lustre是AI/ML工作负载的主要存储服务。
客户可以利用AWS存储服务来:构建自己的大型语言模型(LLM);使用现有的LLM并对其进行微调;执行标准的AI/ML任务,例如数据训练、预测和推理。
AWS提供多种数据保护服务,例如AWS Backup、AWS Disaster Recovery和Amazon EBS快照。
AWS Backup帮助客户集中管理和自动化数据保护,并确保备份的完整性和安全性。
STG204-使用AWS DataSync加速和自动化安全数据传输
STG204-Accelerate & automate secure data transfers at scale with AWS DataSync
本演讲深入探讨了AWS DataSync这一完全托管的数据传输服务,详细阐述了其技术架构、功能特性、应用场景和最佳实践,旨在帮助用户快速、安全、可靠地将数据迁移到AWS云端或在AWS存储服务之间进行数据传输。
AWS DataSync是一种完全托管的数据传输服务,旨在简化和加速本地数据中心、其他云平台和AWS存储服务之间的数据传输。
DataSync采用定制网络协议,通过并行吞吐量操作最大化可用带宽,并自动从网络问题中恢复,确保数据传输的可靠性。
DataSync支持多种数据源和目标,包括:本地存储:NFS、SMB;其他云平台:Google Cloud Storage、Azure Blob Storage、S3兼容的对象存储;AWS存储服务:Amazon S3、Amazon EFS、Amazon FSx。
快速响应业务工作流程:DataSync可以快速移动数据以响应业务需求,例如将基因组测序仪等仪器生成的数据快速移动到云端进行分析和处理。
数据迁移:DataSync具有多种功能,可帮助用户进行数据迁移,例如将数据从数据中心迁移到AWS、关闭存储系统或将数据移动到AWS。
数据保护:DataSync可以按计划运行以创建数据的第二个副本,通常在云中,以用于业务连续性和灾难恢复目的。
数据归档:DataSync可用于将冷数据(例如日志文件)归档到低成本存储服务,例如Amazon S3 Glacier或Glacier Deep Archive。
AI/ML工作负载:DataSync可以将数据复制到Amazon S3和Amazon FSx for Lustre,这些是支持高可扩展性和高吞吐量的关键数据存储功能,适用于AI/ML工作负载。
DataSync Agent:DataSync Agent部署在本地环境或其他云平台中,负责与AWS之外的存储进行通信。支持的部署方式:虚拟机(VMware、Hyper-V、KVM)、Amazon EC2实例;自动软件更新和修补。
连接方式:DataSync Agent可以通过以下三种方式连接到AWS DataSync服务:公共端点:通过互联网连接;私有端点(PrivateLink):通过AWS网络连接;VPC端点:通过VPC连接。
数据传输路径:本地存储到DataSync Agent;DataSync Agent到DataSync服务;DataSync服务到AWS存储服务。
网络优化:数据压缩:在数据离开源之前对其进行压缩,从而减少传输的数据量和网络成本;多线程架构:DataSync Agent使用多线程架构来扩展存储传输;带宽控制:可以限制DataSync在网络链接上消耗的带宽,确保与其他应用程序共享带宽。
数据加密:所有数据在传输过程中都使用TLS 1.3进行加密,并在存储中进行静态加密(如果适用)。
创建位置:定义如何连接到存储,包括本地、其他云平台或AWS存储服务。
创建任务:定义数据传输的源位置、目标位置和选项,例如数据验证、数据移动方式、调度、报告等。
并行任务:对于具有高带宽连接的用户,可以使用多个DataSync Agent和每个Agent一个任务来划分源数据集并并行运行任务,从而最大化带宽利用率。
多Agent任务:对于具有大量小文件的数据集,可以使用具有多个DataSync Agent的任务来增加DataSync可以使用的线程数,从而提高文件复制的并行度。
详细数据传输指标:提供详细的指标,例如文件数量、数据量和传输速度,并支持将指标发送到Amazon CloudWatch和Amazon S3。
清单:用户可以预先生成要传输的文件列表,从而加快后续数据传输的速度。
增强模式任务:提供更高的可扩展性和性能,并支持并行文件传输,与基本模式任务相比,显著提高了数据传输速度。
STG215-使用AWS Storage Gateway构建到Amazon S3的混合数据工作流
STG215-Build hybrid data workflows to Amazon S3 with AWS Storage Gateway
本演讲深入讲解了AWS Storage Gateway的三种网关类型,重点介绍了S3 File Gateway在构建混合数据工作流中的应用,并通过实际案例展示了如何利用S3 File Gateway将本地数据安全、高效地上传到Amazon S3,进而利用AWS云服务进行数据分析、机器学习等处理,实现数据价值最大化。
2.1 AWS Storage Gateway概述
AWS Storage Gateway是一种混合云存储服务,它将本地应用程序连接到AWS云存储,为本地应用程序提供低延迟访问几乎无限量的云存储。
Storage Gateway作为虚拟机部署在本地数据中心或虚拟化环境中,靠近应用程序服务器。
Storage Gateway支持多种虚拟化平台,包括VMware、Hyper-V和Linux KVM。
S3 File Gateway:将本地文件以对象的形式存储到Amazon S3,支持通过NFS和SMB协议访问。
Tape Gateway:虚拟化物理磁带库,将备份数据存储到Amazon S3 Glacier或Amazon S3 Glacier Deep Archive。
Volume Gateway:创建基于块的卷,将数据存储到Amazon EBS或Amazon S3,支持将整个数据集或特定卷归档到Amazon S3。
S3 File Gateway将本地文件系统(NFS或SMB)映射到Amazon S3存储桶,将文件转换为对象存储。
文件写入时,首先写入本地缓存磁盘,客户端立即收到确认。
随后,网关将数据异步上传到Amazon S3,小文件几乎实时上传,大文件上传速度取决于带宽和其他因素。
数据湖和数据处理工作流:将本地数据上传到Amazon S3,构建数据湖。利用AWS云服务(如Amazon Athena、Amazon SageMaker)进行数据分析和处理。
数据库备份:将Oracle、SAP、Microsoft等数据库备份存储到Amazon S3。利用S3生命周期策略将备份数据迁移到低成本存储层,实现长期保留。
冷数据归档:将不常访问的数据(如视频文件)归档到Amazon S3,降低本地存储成本。
文件上传事件通知:每个文件上传到Amazon S3时,网关都会向Amazon EventBridge发送通知,触发后续数据处理工作流。
工作文件集通知:当一组文件完成上传到Amazon S3时,网关会向Amazon EventBridge发送通知,确保所有数据都已上传,再进行处理。
数据加密:所有数据在传输过程中和静态存储时都进行加密。
Amazon EventBridge:接收事件通知。
AWS Step Functions:编排工作流。
Amazon EC2、AWS Lambda、AWS Batch:执行计算任务。
Amazon SageMaker:机器学习模型训练。
Exact Sciences是一家医疗保健和生命科学公司,利用S3 File Gateway将远程实验室站点的数据上传到Amazon S3。
他们使用S3 File Gateway替换了本地存储系统,降低了物理占用空间,并快速将数据传输到云端。
他们构建了自己的数据管理系统,利用AWS服务对S3中的数据进行处理和分析。
他们使用事件驱动的架构,在数据上传完成后自动触发数据处理任务。
虚拟机:VMware、Hyper-V、Linux KVM
AWS Data Sync:用于在本地和AWS存储服务之间传输大型数据集。
AWS Transfer Family:用于通过SFTP、FTPS、FTP和AS2协议安全地传输文件。
STG202-基于Amazon FSx在云中运行NAS
STG202-Network-attached storage in the cloud with Amazon FSx
本演讲详细介绍了Amazon FSx系列服务,涵盖了其优势、适用场景、功能特性、部署方式、成本优化以及实际客户案例,旨在帮助用户快速、高效地将文件数据迁移到AWS云端并实现NAS存储的现代化管理。
随着HPC、数据分析、AI和ML等应用场景的兴起,企业数据量呈指数级增长,对文件数据的访问需求也越来越高。
可扩展性受限:硬件设备的扩展能力有限,无法满足快速增长的数据存储需求。
管理复杂性高:需要专业的IT人员进行部署、配置、维护和升级,增加了管理成本和复杂性。
数据迁移难度大:将数据从本地NAS系统迁移到云端通常需要进行重新架构、重新认证和重新培训,过程繁琐且成本高昂。
Amazon FSx是一系列完全托管的文件存储服务,旨在解决传统NAS存储面临的挑战。
完全托管:AWS负责底层基础设施的管理,包括硬件、软件、操作系统和安全补丁,用户无需进行任何维护工作。
高性能和可扩展性:FSx提供多种性能级别和存储容量选项,可以根据用户需求进行扩展,满足各种工作负载需求。
与AWS服务集成:FSx与其他AWS服务无缝集成,例如Amazon EC2、Amazon S3、AWS Lambda、Amazon SageMaker等,方便用户构建完整的云解决方案。
成本效益:FSx提供多种定价模式,用户可以根据实际使用情况选择最经济高效的方案。
安全性:FSx提供多种安全功能,例如数据加密、访问控制和安全审计,保护用户数据安全。
Amazon FSx for NetApp ONTAP:提供与本地NetApp ONTAP文件系统完全兼容的功能和API,方便用户将现有NetApp工作负载迁移到AWS云端。
Amazon FSx for OpenZFS:提供基于开源OpenZFS文件系统的完全托管服务,适用于各种工作负载,包括高性能计算、机器学习和媒体处理。
Amazon FSx for Windows File Server:提供与Windows Server完全兼容的文件共享和数据管理功能,适用于Windows应用程序和用户。
Amazon FSx for Lustre:提供高性能、并行文件系统,专为高性能计算、机器学习和媒体处理等需要高吞吐量和低延迟的应用程序而设计。
通用文件存储:为部门共享、用户主目录和应用程序共享提供集中管理的文件存储服务。
高性能数据库:为Oracle RAC、SQL Server Failover Cluster Instance和SAP HANA等数据库工作负载提供高性能、低延迟的存储服务。
虚拟机工作负载:为VMware环境提供高性能、可扩展的存储服务。
数据保护和灾难恢复:将本地数据备份到AWS云端,或在不同AWS区域之间复制数据,实现数据保护和灾难恢复。
数据管理:支持数据压缩、重复数据删除、快照、克隆、复制等功能,方便用户进行数据管理和保护。
性能扩展:支持横向扩展和纵向扩展,用户可以根据需求添加或删除文件服务器节点,或调整单个节点的性能配置,满足不同工作负载需求。
成本优化:支持多种存储层级,例如SSD和HDD,用户可以根据数据访问频率选择合适的存储层级,降低存储成本。
数据保护:支持多可用区部署,数据同步复制到多个可用区,确保数据高可用性。
Scale-Out架构:支持多HA对架构,每个HA对可以服务客户端流量,提高性能可扩展性。
智能分层:为FSx for OpenZFS提供新的存储层级,根据数据访问模式自动将数据在不同层级之间移动,降低存储成本。
弹性结构适配器(EFA)支持:FSx for Lustre支持EFA,提供更低的延迟和更高的吞吐量,适用于高性能计算和机器学习等工作负载。
John Holland Group:一家澳大利亚建筑公司,使用Amazon FSx for NetApp ONTAP构建通用文件存储服务,为其分布式团队提供安全、可靠的文件共享平台。
Change Healthcare:一家医疗保健技术公司,使用Amazon FSx for Windows File Server将其关键任务系统迁移到AWS云端,实现了高性能、高可用性和低成本。
eHealth NSW:一家澳大利亚医疗保健机构,使用Amazon FSx for NetApp ONTAP构建PACS影像存储库,存储和管理大量的医学影像数据。
Marriott International:一家全球酒店集团,使用Amazon FSx for NetApp ONTAP将其本地NetApp文件系统迁移到AWS云端,简化了数据管理,并提高了数据保护能力。
Adobe:一家软件公司,使用Amazon FSx for Lustre和Amazon S3构建混合存储解决方案,为其机器学习模型训练和数据分析提供高性能和可扩展的存储服务。
STG211-What's new with file storage
本演讲重点介绍了Amazon EFS和Amazon FSx文件存储服务在数据管理、性能扩展、数据保护以及与其他AWS服务集成方面的最新功能和改进,旨在帮助用户更有效地管理文件数据并将其应用于现代云应用程序。
AWS提供三种主要的文件存储服务以满足不同的使用场景:
Amazon FSx:完全托管的NAS服务,提供与主流文件系统(NetApp ONTAP、OpenZFS、Windows File Server和Lustre)兼容的存储服务,适用于用户共享、企业应用程序、高性能计算、AI/ML以及数据保护等场景。
Amazon FSx for Lustre:基于Lustre文件系统的高性能、并行文件存储服务,专为高吞吐量和低延迟的计算密集型工作负载设计。
Amazon EFS:无服务器弹性文件存储服务,可根据需求自动扩展和缩减,适用于云原生应用程序和开发人员,提供简单易用的云文件共享服务。
2.2 Amazon FSx和Amazon EFS面临的挑战
数据规模的快速增长,用户需要更有效地管理数据并控制成本。
云原生存储服务(例如Amazon S3、Amazon EFS和Amazon DynamoDB)的优势,例如弹性存储、按需付费和与其他AWS服务集成,对传统文件存储服务提出了挑战。
2.3 Amazon FSx for OpenZFS智能分层存储类
数据自动在频繁访问层、不频繁访问层和存档即时访问层之间进行分层。
用户可以将更广泛的工作负载和数据集(包括最大规模的数据集)迁移到云端。
新的存储类包括三个层级:频繁访问、不频繁访问和存档即时访问。
文件系统元数据存储在SSD上,以实现低延迟元数据操作。
Amazon FSx for Lustre弹性结构适配器(EFA)支持:
通过启用EFA支持,FSx for Lustre可以提供更低的延迟和更高的吞吐量。
EFA是一种基于定制协议的网络技术,不依赖于TCP,可提供更低的延迟和更高的吞吐量。
EFA支持所有EC2实例上的网络接口卡(NIC)绕过操作系统内核,直接与网络硬件通信,从而降低延迟并提高性能。
Amazon FSx for OpenZFS高可用性(HA)配置的同步复制:
支持使用多达10Gbps的专用链路进行跨区域复制。
用户可以在不同AWS区域之间复制数据以实现灾难恢复。
支持文件系统的吞吐量根据工作负载需求自动扩展和缩减。
Amazon FSx for OpenZFS快照功能:
用户可以创建文件系统的快照,并将其用于数据恢复或创建新的文件系统。
用户可以在同一区域或不同区域内创建文件系统的副本。
通过将数据复制到另一个AWS区域,可以提高数据安全性并满足合规性要求。
Amazon FSx for Lustre与Amazon S3集成:
用户可以通过FSx for Lustre文件系统访问存储在Amazon S3中的数据。
数据仓库:将Amazon S3作为数据湖,并将FSx for Lustre作为高性能缓存层。
数据导出:将Amazon S3作为数据导出目标,并将FSx for Lustre作为数据处理层。
用户可以使用AWS Backup服务备份和恢复EFS文件系统。
壳牌公司:使用Amazon FSx for Lustre和Amazon S3构建混合存储解决方案,用于机器学习模型训练和数据分析。
拜耳公司:使用Amazon FSx for Lustre进行基因组分析。
STG344-简单弹性文件系统:Amazon EFS深入探讨
STG344-Simple elastic file systems: A deep dive into Amazon EFS
本演讲深入探讨了Amazon EFS的架构、功能和用例,重点介绍了EFS的无服务器特性、性能模式、数据保护机制以及与其他AWS服务的集成。演讲通过实际演示展示了如何创建EFS文件系统并将其挂载到Amazon EC2、AWS Lambda等计算服务上,并演示了EFS在高并发分析工作负载下的性能表现。
定义:Amazon EFS是一种完全托管的弹性文件存储服务,为各种应用程序提供简单的文件存储和共享。
弹性:根据需要自动扩展和缩减存储容量,支持PB级数据存储。
计算服务:EFS与所有AWS计算服务兼容,包括Amazon EC2、AWS Lambda、Amazon ECS、Amazon EKS等。
可用作容器的持久卷,实现状态化容器、快速恢复和应用程序扩展。
其他AWS服务:EFS集成了AWS IAM、AWS KMS、AWS CloudWatch、AWS CloudTrail、AWS DataSync和AWS Backup等服务。
使用CloudWatch和CloudTrail进行监控和审计。
弹性吞吐量(ET):默认模式,根据工作负载需求自动扩展性能,适用于大多数工作负载。
预置吞吐量(PT):为文件系统设置固定的吞吐量,适用于具有可预测吞吐量需求的工作负载。
突发吞吐量(BT):适用于具有低平均吞吐量但偶尔需要高吞吐量的文件系统,按突发信用额度计费。
弹性吞吐量模式:利用多租户架构,根据需要自动扩展性能。
EFS文件系统策略:使用预读和缓存策略优化数据访问性能。
数据持久性:数据写入操作在被确认之前,会跨三个可用区进行持久化存储,确保数据持久性。
可用区弹性:EFS文件系统可以承受单个可用区的完全丢失,同时在其他可用区继续提供服务。
AWS Backup集成:使用AWS Backup对EFS文件系统进行备份,提供额外的安全保障。
EFS复制功能:在同一区域或不同区域内创建EFS文件系统的副本。
支持异步复制,提供分钟级的恢复时间目标(RTO)和恢复点目标(RPO)。
支持复制回退功能,支持切换主文件系统和副本文件系统之间的复制方向。
数据加密:使用EFS挂载助手启用传输中加密和静态加密。
大数据分析:为分析工作负载提供高性能、可扩展的存储。
使用AWS Lambda函数从EFS文件系统读取数据。
STG207-使用Amazon S3 Glacier存储类最大化冷数据的价值
STG207-Maximize the value of cold data with Amazon S3 Glacier storage classes
本演讲详细介绍了Amazon S3 Glacier存储类,重点讲解了冷数据的定义、应用场景以及如何利用S3 Glacier存储类降低存储成本、优化数据恢复流程。演讲还结合实际案例,展示了如何通过S3生命周期策略和智能分层功能,将数据自动迁移到合适的存储类,从而在保证数据可用性的同时最大限度地降低成本。
数据保存:长期保存具有潜在价值的数据,例如媒体文件、历史数据等。
合规性:为了满足法律法规或行业规范,需要长期保存特定类型的数据。
成本优化:将冷数据迁移到低成本的存储类,可以显著降低存储成本。
S3 Glacier存储类是专为冷数据设计的低成本存储解决方案。
Glacier Instant Retrieval:提供毫秒级访问速度,适用于需要快速访问的冷数据,例如医疗影像、用户生成内容等。
Glacier Flexible Retrieval:提供分钟到小时级别的访问速度,适用于需要灵活检索的冷数据,例如备份、日志等。
Glacier Deep Archive:提供最低的存储成本,但访问速度较慢(可能需要数小时甚至数天),适用于长期保存且很少访问的数据,例如合规性数据。
S3生命周期策略:可以根据数据的访问模式和生命周期,自动将数据迁移到合适的存储类。
例如,可以设置规则,将30天未访问的数据迁移到Glacier Instant Retrieval,将90天未访问的数据迁移到Glacier Flexible Retrieval。
S3智能分层:可以自动监控数据的访问模式,并将数据在不同的存储类之间进行自动分层,无需手动管理。
智能分层包括频繁访问层、不频繁访问层、存档即时访问层、存档访问层和深度存档访问层。
可以根据需要启用或禁用存档访问层和深度存档访问层。
从Glacier Flexible Retrieval和Glacier Deep Archive恢复数据需要执行以下步骤:
发起恢复请求:选择合适的恢复类型(批量检索、标准检索、快速检索)以及恢复时间。
检查恢复完成状态:可以通过API或控制台查看恢复进度。
访问恢复后的数据:恢复后的数据会存储在S3标准存储类中,可以通过S3 API进行访问。
批量操作:可以使用批量操作同时恢复大量对象,提高效率。
事件通知:可以配置事件通知,在恢复完成后自动触发后续操作。
Canva:通过将冷数据迁移到Glacier Instant Retrieval和Glacier Flexible Retrieval,每月节省了300万美元的存储成本。
NASCAR:将第二天不再使用的比赛视频直接迁移到Glacier Instant Retrieval,节省了大量存储成本。
Deluxe:使用批量操作恢复数据,将恢复时间从数小时缩短到数分钟。
使用S3生命周期策略或智能分层功能自动管理数据迁移。
对于大规模数据恢复,使用批量操作和事件通知功能提高效率。
STG212-What's new with Amazon S3
本演讲全面介绍了Amazon S3在过去一年中发布的30项新功能,涵盖了结构化数据、非结构化数据、规模、性能和安全等方面。演讲重点讲解了S3 Tables和S3元数据表两项重要功能,并通过实际案例和演示,展示了新功能如何帮助用户更好地管理、优化和保护数据。
Amazon S3 Tables:一项完全托管的Apache Iceberg表格服务,简化了在S3上存储和查询结构化数据的过程。
高性能:通过利用S3底层索引,实现更高的初始TPS,提升查询性能。
安全性:表格作为S3中的一级资源,简化了安全策略的设置。
成本优化:根据用户设置的策略自动进行存储成本优化。
S3元数据功能(预览阶段):提供了一种查询S3元数据的新方法,通过创建元数据日志表,用户可以使用简单的SQL命令查询S3元数据。
用例:例如,查询日志表可以识别存储桶中所有AI生成的视频。
更高的存储桶限制:S3现在支持每个账户创建1万个存储桶,满足多租户应用的需求。
条件请求:引入了Put If Absent和Put If Match条件请求,简化了分布式应用程序的数据持久性管理。
解决的问题:避免了多个客户端同时写入数据导致的数据覆盖问题。
新的校验和算法:支持SHA-256和SHA-1校验和算法,增强了数据完整性保护。
S3 Express One Zone扩展:新增了三个区域支持(爱尔兰、俄亥俄州和孟买),并增加了与其他AWS服务的集成。
新功能:支持追加数据功能,支持向现有对象追加数据。
Mount Point for Amazon S3:增加了增量上传功能,并支持AWS Dedicated Local Zones中的目录存储桶。
缓存选项:扩展了缓存选项,包括与S3 Express One Zone配合使用的高性能共享读取缓存。
S3 Connector for PyTorch:增加了对PyTorch Lightning和TensorFlow的支持,进一步提升了机器学习训练性能。
简化403错误排查:S3现在提供更详细的错误信息,帮助用户快速解决访问被拒绝的问题。
S3 Access Grants扩展:增加了对SageMaker、Redshift、Glue ETL和Boto3的支持,简化了数据访问权限管理。
新的API用于列出用户权限:方便用户查看特定用户对S3数据集的访问权限。
Storage Browser:一个AWS Amplify JavaScript和React库,简化了Web应用程序中的数据上传和管理。
与Amplify Hosting集成:用户可以通过S3控制台将S3存储桶连接到Amplify托管的网站,简化静态网站托管流程。
与Transfer Family Web Apps集成:用户可以使用S3 Access Grants创建简单的Web应用程序,方便非技术用户访问数据。
使用Mount Point for Amazon S3将S3存储桶挂载到EC2实例,并演示增量上传功能。
使用S3 Connector for PyTorch运行PyTorch训练作业,展示其性能优势。
使用Storage Browser在Web应用程序中上传和管理数据。
将S3存储桶连接到Amplify托管的网站,展示静态网站托管流程。
STG302-Dive deep on Amazon S3
本演讲由Amazon S3工程团队领导者主讲,深入探讨了Amazon S3的内部工作机制,揭示了构建大规模存储系统的工程原理,并解释了这些原理如何使各种规模的用户受益。演讲重点关注S3的数据分布和去相关性策略,以及Shuffle Sharding算法和AWS Common Runtime(CRT)如何协同工作,以实现高性能、高可用性和高韧性。
硬件基础设施:Amazon S3构建于大规模的服务器和硬盘集群之上,这些硬件分布在全球多个区域和可用区,确保数据冗余存储和高可用性。
软件架构:S3软件架构采用分层设计,包括前端系统、对象索引、数据存储等多个模块。
前端系统:负责处理用户请求、身份验证、授权和请求路由等功能。
对象索引:存储对象元数据,例如对象名称、大小、存储类、版本信息等。
数据分片:当用户上传对象到S3时,系统会将对象拆分成多个数据块(称为shard)。
纠删码:S3使用纠删码算法将数据shard冗余存储到多个硬盘驱动器上。
这种机制可以容忍一定数量的硬盘故障,确保数据高可用性和持久性。
2.3 Shuffle Sharding和去相关性
Shuffle Sharding:一种数据放置算法,用于将数据shard随机分布到整个存储集群中。
目标是将不同对象的数据shard分散存储,避免热点问题,确保工作负载的均衡分布。
去相关性:S3系统的设计原则,旨在将不同资源(例如网络、计算、存储)之间的依赖关系降至最低。
这种设计可以避免单点故障,提高系统整体的韧性和稳定性。
2.4 AWS Common Runtime(CRT)
功能:实现了S3的最佳实践,例如重试机制、请求自动并行化等。
优势:帮助用户从S3获得更高的吞吐量,单个主机可实现数百Gbps的吞吐量。
与Shuffle Sharding的协同:CRT利用Shuffle Sharding算法,选择最佳的存储节点进行数据读写操作,进一步提升性能和韧性。
STG323-在Amazon S3上构建和优化数据湖
STG323-Build and optimize a data lake on Amazon S3
本演讲以虚构的Forever Ecommerce公司为例,讲解了如何使用Amazon S3构建和优化PB级数据湖。演讲重点介绍了数据湖的分层架构、数据摄取、查询优化、安全治理以及长期管理等方面的最佳实践。
分层存储:将数据湖划分为原始数据层、处理数据层和精选数据层,以提高数据质量和查询效率。
原始数据层:存储来自各个业务系统的原始数据,例如点击流数据、订单数据、日志文件等。关键考虑因素:文件结构、分区策略、存储类别选择。
处理数据层:对原始数据进行清洗、转换和聚合,并以结构化格式存储,例如Parquet。关键考虑因素:数据格式选择、表结构设计、数据质量监控。
精选数据层:存储高度聚合和优化后的数据,用于特定业务场景,例如BI报表、机器学习模型训练等。关键考虑因素:数据访问模式、查询性能优化、数据安全性。
数据源:电商平台、订单系统、点击流数据、日志文件等。
数据摄取工具:Amazon Kinesis Data Firehose、AWS Glue等。
数据分区:根据查询模式对数据进行分区,例如按日期、产品类别、用户ID等进行分区。
文件格式:选择Parquet等列式存储格式,以提高查询效率。
排序策略:对数据进行排序,以减少查询时需要扫描的数据量。
访问控制:使用AWS IAM策略精细控制数据访问权限。
跨账户共享:将数据存储在单独的账户中,并使用跨账户共享策略控制访问权限。
数据治理和发现:使用AWS Glue Data Catalog建立数据目录,并使用标签和元数据标记数据。
数据加密:使用S3提供的加密功能或自带密钥加密数据。
指标收集:收集来自S3、AWS Glue、Amazon EMR、Amazon Athena等服务的指标,以监控数据湖的运行状况和性能。
成本优化:使用S3存储类别管理和生命周期策略优化存储成本。
自动化:使用AWS Lambda和AWS Step Functions等服务自动化数据湖管理任务。
Forever Ecommerce公司:演示了如何使用S3构建和优化数据湖,以支持订单收集和点击流分析等业务场景。
STG328-Optimizing storage performance with Amazon S3
本演讲探讨了如何利用Amazon S3的特性和最新功能来优化存储性能,从而提升应用程序的速度和效率。演讲重点关注以下方面:
Amazon S3的最新性能改进,例如S3 Express One Zone存储类、AWS Common Runtime (CRT)库以及针对开源数据湖和机器学习框架的优化
针对不同工作负载场景的性能优化策略,包括机器学习训练、数据库查询和大文件传输
计算资源利用率:存储性能直接影响计算资源的利用率。存储性能越高,数据读取和写入速度越快,计算资源的闲置时间就越短,从而降低TCO。
应用程序响应速度:对于时延敏感型应用,例如图像和视频服务,存储性能决定了用户体验。快速的存储访问可以缩短响应时间,提升用户满意度。
数据处理效率:对于高吞吐量应用,例如ETL作业和机器学习训练,存储性能决定了数据处理的速度。高吞吐量的存储系统可以加速数据管道,缩短处理时间。
监控工具:使用Amazon CloudWatch、Amazon S3 Storage Lens和Amazon S3 Server Access Logs等工具监控存储性能指标,例如请求延迟、吞吐量和错误率。
性能分析:分析监控数据,识别性能瓶颈,例如高延迟请求、低吞吐量操作或频繁的错误。
优化策略:根据瓶颈类型采取相应的优化策略,例如增加并行请求数量、优化请求大小、调整存储类别或使用缓存机制。
Amazon S3 Express One Zone:一种高性能存储类,提供个位数毫秒级的访问延迟,适用于频繁访问的数据集。
优势:性能提升10倍,请求成本降低50%,可扩展至每分钟数百万个请求。
适用场景:机器学习训练、交互式分析、媒体内容创建等。
AWS Common Runtime (CRT):一个低级软件库,用于与S3进行交互,实现了S3的最佳实践,例如重试机制和请求自动并行化。
优势:帮助用户从S3获得更高的吞吐量,单个主机可实现数百Gbps的吞吐量。
Mount Point for Amazon S3:一个开源文件客户端,用户可以将S3存储桶挂载到计算实例上,像访问本地文件系统一样访问S3对象。
优势:简化S3对象访问,提供高吞吐量性能,支持S3 Express One Zone和AWS Dedicated Local Zones等功能。
开源数据湖优化:针对Apache Iceberg和Apache Spark等开源数据湖框架的性能优化,包括优化Parquet文件格式、数据分区和请求并行化策略。
机器学习框架优化:针对PyTorch和TensorFlow等机器学习框架的性能优化,包括提供S3数据连接器、优化数据读取和写入操作以及支持分布式检查点功能。
机器学习训练:使用Amazon S3 Express One Zone存储训练数据集,利用S3数据连接器加速数据读取和写入,使用分布式检查点功能提高容错能力。
数据库查询:使用Parquet文件格式存储数据,优化数据分区和排序策略,利用S3 Select功能只读取必要的数据列,使用Amazon Athena等查询引擎加速查询执行。
大文件传输:增加并行请求数量,优化请求大小,使用AWS DataSync等工具加速数据传输。
选择合适的存储类别:根据数据访问模式选择合适的S3存储类别,例如S3 Standard、S3 Intelligent-Tiering或S3 Express One Zone。
优化数据布局:使用数据分区、排序和文件格式优化来提高数据读取效率。
利用并行化:通过增加并行请求数量和使用多线程或多进程来提高数据传输和处理速度。
优化请求大小:选择合适的请求大小,以平衡请求开销和数据传输效率。
使用缓存机制:使用Mount Point for Amazon S3的缓存功能或Amazon ElastiCache等服务来缓存经常访问的数据。
STG205-使用Amazon EBS快照轻松保护关键数据
STG205-Protect critical data with ease using Amazon EBS snapshots
本演讲深入讲解了Amazon EBS快照的功能、优势和使用场景,以及如何利用快照实现数据保护、备份和灾难恢复。演讲重点介绍了快照的增量机制、加密选项、跨区域复制、快照锁以及与其他AWS服务(如AWS Backup和Amazon Data Lifecycle Manager)的集成。此外,还分享了SAP公司如何利用EBS快照保护其RISE with SAP平台上数万个SAP系统的数据完整性和合规性。
定义:EBS快照是EBS卷的时间点副本,包含还原卷到创建快照时状态所需的所有数据。
增量机制:快照仅存储自上次快照以来更改的数据块,从而提高创建速度并降低存储成本。
数据加载:从快照创建卷时,数据在后台加载,用户可以立即开始使用卷。
用途:备份和灾难恢复;刷新、扩展和数据移交工作流;备份数据中心数据并还原到云端;为第三方自动化和编排解决方案提供基础。
加密:EBS通过与AWS Key Management Service (KMS)集成,提供256位加密,确保卷和快照中的静态数据以及传输中的数据都得到加密。
跨区域和跨账户复制:用户可以将快照复制到其他区域或账户,以满足灾难恢复、数据扩展和测试需求。
基于时间的快照复制:用户可以指定快照复制的持续时间(15分钟到48小时),以满足特定的恢复点目标(RPO)。
快照共享:用户可以选择私下共享快照给特定账户或公开共享,但通常不建议公开共享。
阻止公开共享:用户可以在账户级别阻止所有公开共享或阻止新的公开共享,以增强安全性。
快照锁:用户可以使用快照锁功能防止快照被删除,以满足数据不可变性和合规性要求。
RISE with SAP:一种将SAP应用程序迁移到AWS云端的托管服务。
数据保护挑战:确保数据安全、不可变以及防止勒索病毒攻击。
EBS快照优势:增量快照机制缩短备份和恢复时间;区域存储提供数据冗余和可用性;存储层快照机制对应用程序性能影响最小;使用KMS密钥加密提高数据安全性;快照锁功能实现数据不可变性和勒索病毒防护。
架构和工作流程:使用Lambda函数进行生命周期管理;支持排除特定卷以优化成本;跨一致性快照确保数据一致性;使用快速快照还原(FSR)功能加速数据恢复;通过标签管理已分离的卷。
2.4 Amazon Data Lifecycle Manager (DLM)
策略类型:单卷快照策略;多卷崩溃一致性快照策略;EBS支持的Amazon系统映像(AMI)策略。
应用一致性快照:与AWS Systems Manager集成,为MySQL、PostgreSQL、Windows应用程序和SAP HANA创建应用一致性快照,以加快数据库恢复速度。
成本效益:创建和管理策略免费,用户仅需支付EBS快照的存储费用。
规则类型:账户级别规则,保护区域内所有快照和AMI;基于标签的规则,保护特定快照和AMI。
排除标签:用户可以从账户级别规则中排除特定快照和AMI。
STG213-What's new with Amazon EBS
Amazon EBS的最新功能和架构改进,重点关注性能提升、韧性增强和安全性强化等方面。演讲内容包括:
EBS性能的演进历程,从早期共享带宽和有限IOPS到如今的专用带宽和高达42万 IOPS的实例级性能;IO2 Block Express (io2bx)卷的架构和优势,包括高性能、高持久性、大容量和NVMe支持;EBS io2bx卷的韧性特性,例如多可用区部署、EBS卷状态检查和EBS暂停IO操作;EBS io2bx卷的性能监控工具,包括CloudWatch指标、EBS NVMe统计信息和故障注入模拟器;降低EBS io2bx卷延迟的最新技术,包括使用io_uring异步IO库和优化存储服务器软件;EBS快照的灾难恢复功能,包括跨可用区和跨账户复制快照,以及使用弹性灾难恢复(EDR)实现半同步复制。
网络连接持久性存储:EBS为EC2实例提供网络连接的块存储,具有持久性和独立生命周期。
分布式存储系统:EBS服务器架构不断演进,提供各种卷类型以满足不同的性能、持久性和成本需求。
核心价值主张:EBS的核心价值主张是高性能、高可靠性和安全性。
早期限制:早期EBS受限于共享带宽和低IOPS,每卷仅支持100IOPS,且带宽与网络流量共享。
持续改进:EBS性能不断提升,目前io2bx卷可提供高达256,000 IOPS的卷级性能和高达42万 IOPS的实例级性能,并使用专用EBS带宽。
2.3 IO2 Block Express (io2bx)卷
架构:io2bx基于Nitro系统,利用NVMe协议提供高性能和低延迟。
优势:高性能:高达256,000 IOPS(卷)/42万 IOPS(实例);高持久性:99.999%持久性;大容量:高达64TB;低延迟:亚毫秒级延迟;NVMe支持。
多可用区部署:io2bx支持跨三个可用区部署,增强数据冗余和可用性。
EBS卷状态检查:EC2中的EBS卷状态检查功能简化了卷状态监控,无需逐个检查卷。
EBS暂停IO操作:用户可以暂停卷IO操作,方便进行维护和故障排除。
CloudWatch指标:提供卷级性能指标,例如IOPS、吞吐量和延迟。
EBS NVMe统计信息:提供更细粒度的性能数据,包括总操作数、读写操作数、字节数和时间戳。
故障注入模拟器:用户可以模拟卷不可用场景,测试应用程序的韧性和恢复能力。
io_uring:一种Linux内核异步IO库,可降低系统调用开销,提升IO性能。
优化存储服务器软件:EBS团队不断优化存储服务器软件,减少数据路径上的延迟。
EBS快照:EBS快照是EBS卷的时间点副本,存储在Amazon S3中,具有11个9的持久性。
跨可用区和跨账户复制:用户可以将快照复制到其他区域或账户,以满足灾难恢复和数据迁移需求。
弹性灾难恢复(EDR):EDR提供半同步复制功能,将数据复制到另一个区域,实现更低的RPO。
STG329-使用Amazon EBS最大限度地提高高强度工作负载的性能
STG329-Maximizing performance for high-intensity workloads using Amazon EBS
本演讲重点讲解了Amazon EBS io2 Block Express (io2bx)卷如何满足高强度工作负载对高IOPS、高吞吐量和低延迟的苛刻要求。演讲内容涵盖io2bx的性能优势、架构设计、实际应用案例以及性能优化和监控技巧。
2.1 Amazon EBS和io2 Block Express概述
EBS存储:EBS为EC2实例提供网络连接的块存储,具有持久性、高可用性和高性能的特点,适用于各种工作负载。
EBS卷类型:EBS提供多种基于SSD和HDD的卷类型,包括通用型(GP3)、高IOPS型(io2)以及io2 Block Express (io2bx)。
io2 Block Express (io2bx):io2bx是EBS家族中性能最高的卷类型,专为关键任务型高强度工作负载设计,提供亚毫秒级延迟和99.999%的持久性。
2.2 io2 Block Express的性能优势
高IOPS:io2bx每卷提供高达256,000 IOPS,通过卷条带化,每实例可实现高达42万 IOPS。
高吞吐量:io2bx每卷提供高达4,000 MB/s的吞吐量,通过卷条带化可进一步提升。
低延迟:io2bx持续提供亚毫秒级延迟,即使在99.9%的情况下也能保持极低的尾部延迟。
高持久性:io2bx提供99.999%的持久性,最大程度减少应用程序停机时间。
2.3 io2 Block Express架构和设计
Nitro系统:io2bx基于Amazon EC2 Nitro系统,该系统卸载了存储虚拟化任务,释放了CPU资源并提高了性能。
NVMe协议:io2bx利用NVMe协议提供高性能和低延迟。
多可用区部署:io2bx支持跨三个可用区部署,增强数据冗余和可用性。
卷条带化:用户可以使用RAID 0或LVM将多个io2bx卷条带化,以获得更高的性能,但需要注意条带化会降低系统的有效持久性。
2.4 io2 Block Express应用案例
Epic系统:医疗保健软件供应商Epic的系统对IOPS要求极高,io2bx帮助Epic客户实现了高达7,500万TPS的性能,并扩展了其数据库。
SAP HANA:io2bx帮助SAP HANA客户实现了63%的性能提升,并利用EBS快照功能确保了数据一致性。
McAfee数据库:McAfee将其关键任务数据库迁移到io2bx后,延迟降低了80%,吞吐量提高了75%,成本降低了40%。
2.5 io2 Block Express性能优化和监控
选择合适的卷类型:对于大多数工作负载,GP3是一个不错的选择,但对于关键任务型高强度工作负载,io2bx提供最佳性能。
卷条带化:使用卷条带化可以提高性能,但需要注意有效持久性的降低。
I/O合并:EBS的I/O合并功能可以将连续的小I/O合并成一个后端操作,提高吞吐量并降低IOPS消耗。
CloudWatch指标:CloudWatch提供EBS卷的平均读写延迟指标,帮助用户监控性能。
EBS NVMe统计信息:EBS NVMe统计信息提供更细粒度的性能数据,包括IOPS节流时间和吞吐量节流时间。
EBS卷状态检查:EC2中的EBS卷状态检查功能简化了卷状态监控。
STG203-What's new with AWS Backup
AWS Backup的最新功能和应用,重点关注如何利用AWS Backup构建数据保护策略,应对勒索病毒威胁以及实现灾难恢复。演讲内容包括:
AWS Backup的核心功能和优势,例如策略驱动的备份管理、跨服务和跨账户备份、备份的不可变性和还原测试;AWS Backup如何应对勒索病毒威胁,包括使用逻辑隔离保险库(Logically Air-gapped Vault)、服务拥有密钥(Service-Owned Key)和还原测试功能;AWS Backup的实际应用案例,例如Freddie Mac和Skyscanner如何使用AWS Backup实现数据保护和灾难恢复;AWS Backup的最新功能,例如跨区域和跨账户备份、S3备份还原所有版本、成本计算器改进。
策略驱动的备份服务:AWS Backup是一种完全托管的策略驱动的备份服务,用户可以集中管理和自动化数据保护。
简化备份管理:用户可以根据数据保护需求定义备份策略,AWS Backup自动执行备份、复制和还原操作。
广泛的服务支持:AWS Backup支持多种AWS服务,包括计算、存储、数据库和应用程序。
混合云支持:AWS Backup还支持VMware和SAP等混合云工作负载。
逻辑隔离保险库(Logically Air-gapped Vault):这是一种新型的AWS Backup保险库,提供逻辑隔离和不可变性,防止勒索病毒攻击。
强制合规模式:逻辑隔离保险库默认启用合规模式,确保备份的不可变性。
服务拥有密钥(Service-Owned Key):AWS Backup服务拥有密钥,消除了客户管理密钥的单点故障风险。
还原测试:用户可以使用AWS Backup的还原测试功能,定期测试备份的可恢复性,确保数据在需要时可用。
第三方集成:AWS Backup支持与第三方安全解决方案集成,例如勒索病毒扫描和恶意软件扫描。
Freddie Mac:Freddie Mac使用AWS Backup增强其数据保护策略,通过跨区域逻辑隔离保险库和合规锁实现备份的不可变性,并构建“洁净室”环境验证数据恢复能力。
Skyscanner:Skyscanner使用AWS Backup构建集中式备份解决方案,利用标签选择资源进行备份,并使用AWS CDK自动化备份配置和管理。
跨区域和跨账户备份:AWS Backup扩展了跨区域和跨账户备份功能,支持更多资源类型。
S3备份还原所有版本:AWS Backup现在支持还原S3备份的所有版本,满足用户更细粒度的恢复需求。
成本计算器改进:AWS Backup成本计算器得到改进,帮助用户更准确地预测备份成本。
STG301-Data protection and resilience with AWS storage
本演讲深入探讨了AWS存储服务如何帮助企业构建多层次的数据保护和韧性策略,以应对数据丢失、意外停机、自然灾害和勒索病毒攻击等威胁。演讲内容涵盖AWS数据保护责任共担模型、AWS存储服务组合、数据保护和灾难恢复架构模式以及AWS Backup的应用和优势。
AWS负责云平台的韧性:AWS负责维护其基础设施(包括区域、可用区、边缘站点)的高可用性,确保计算、存储、数据库、网络和其他硬件服务具有冗余性和容错能力。例如,AWS负责确保Amazon S3的11个9的持久性,这意味着存储在S3中的对象不会丢失或损坏。
客户负责云中应用程序的韧性:客户负责设计和实施其应用程序的数据保护和灾难恢复策略,确保应用程序能够应对各种故障和威胁。例如,客户需要配置S3版本控制、复制、对象锁定和生命周期策略,以保护其数据免受意外删除、覆盖和勒索病毒攻击。
块存储:Amazon Elastic Block Store (EBS)为EC2实例提供持久性块存储,支持多种卷类型以满足不同的性能需求。
对象存储:Amazon S3提供可扩展、持久且经济高效的对象存储,适用于各种用例,包括数据湖、备份和归档。Amazon S3 Glacier提供低成本的归档存储,适用于不常访问的数据。
文件存储:Amazon Elastic File System (EFS)提供完全托管的弹性文件存储,适用于各种应用程序,包括Web服务器和容器化应用程序。Amazon FSx提供适用于Windows和Linux工作负载的高性能文件存储。Amazon File Cache提供缓存功能,加速对本地存储的数据访问。
多可用区部署:AWS区域包含多个可用区,这些可用区在地理位置上相互隔离,但通过低延迟网络连接。通过跨多个可用区部署应用程序和数据,可以提高应用程序的可用性和容错能力。
备份和恢复:备份是数据保护的基本策略,AWS Backup提供集中式、策略驱动的备份管理平台,支持多种AWS服务,包括计算、存储、数据库和应用程序。AWS Backup还可以帮助客户实现备份的不可变性、策略化保留和还原测试,以增强数据安全性和可恢复性。
复制:复制是一种实时数据保护机制,通过将数据复制到另一个位置来确保数据可用性。AWS提供多种复制选项,包括S3复制、EBS快照复制和数据库复制。复制可以用于灾难恢复、数据迁移和跨区域数据共享等场景。
S3数据保护:尽管Amazon S3提供11个9的持久性,但客户仍然需要采取措施来保护其数据免受意外删除、覆盖和勒索病毒攻击。建议使用S3版本控制、复制、对象锁定和生命周期策略来构建多层次的S3数据保护策略。
EC2和EBS数据保护:建议使用EBS快照来备份EC2实例的EBS卷。EBS快照存储在S3中,具有11个9的持久性。为了增强数据保护,建议将EBS快照复制到另一个账户或区域。
集中式备份管理:AWS Backup提供集中式备份管理平台,简化了跨多个AWS服务的备份管理。
策略驱动的备份:用户可以定义备份策略,指定要备份的资源、备份频率、保留期和目标位置。
不可变备份:AWS Backup支持逻辑隔离保险库,确保备份的不可变性,防止勒索病毒攻击。
还原测试:AWS Backup提供还原测试功能,帮助用户验证备份的可恢复性。
合规性和审计:AWS Backup提供合规性和审计报告,帮助用户满足法规遵从性要求。
STG339-超越11个9的持久性:使用Amazon S3进行数据保护
STG339-Beyond 11 9s of durability: Data protection with Amazon S3
本演讲探讨了Amazon S3如何通过其架构设计实现11个9的持久性,并介绍了如何使用S3的功能来增强数据保护,以防止意外删除、覆盖和勒索病毒攻击。演讲涵盖了S3的内部机制,如纠删码和Shuffle Sharding,以及S3版本控制、复制和对象锁等数据保护功能。
11个9的持久性:Amazon S3的设计目标是实现11个9的持久性,这意味着存储在S3中的对象极不可能丢失或损坏。S3通过多种机制来实现持久性,包括数据冗余存储、数据完整性校验和故障恢复机制。
跨可用区冗余:S3将数据存储在多个可用区(AZ),每个可用区都是地理位置上相互隔离的数据中心。当一个可用区发生故障时,S3可以从其他可用区恢复数据,从而确保数据的可用性。
纠删码:S3使用纠删码技术将对象分成多个分片,并将这些分片存储在多个驱动器上。即使多个驱动器发生故障,S3也可以使用剩余的分片重建对象。
Shuffle Sharding:S3使用Shuffle Sharding技术将对象随机分布到不同的驱动器上,以分散负载并提高性能。
意外删除和覆盖:即使S3具有高度的持久性,意外删除和覆盖仍然是数据丢失的主要原因。
勒索病毒攻击:勒索病毒攻击对数据安全构成重大威胁,攻击者可能会加密数据并要求赎金才能解密。
数据保护策略:为了应对这些挑战,S3提供了多种数据保护功能,包括版本控制、复制和对象锁。
S3版本控制:版本控制用户可以保留对象的多个版本,以便在意外删除或覆盖时恢复到之前的版本。
S3复制:复制用户可以将对象复制到其他S3存储桶,以便在发生区域性故障时进行灾难恢复或跨区域数据共享。
S3对象锁:对象锁用户可以使对象不可变,防止删除或覆盖,这对于满足合规性要求和防范勒索病毒攻击至关重要。对象锁有两种模式:合规模式和治理模式。合规模式提供最高级别的保护,一旦设置,任何人都无法更改或删除对象,即使是存储桶所有者也不行。
多重身份验证(MFA)删除:MFA删除要求用户在删除对象或更改存储桶版本控制状态时提供额外的身份验证因素。
条件写入:S3支持条件写入,用户可以根据特定条件进行写入操作,例如仅当对象不存在时才写入对象。这有助于防止意外覆盖现有对象。
S3复制:S3复制可用于创建数据的多个副本,并将这些副本存储在不同的区域。这有助于确保在发生区域性故障时数据的可用性。
S3多区域访问点:S3多区域访问点提供了一个全局端点,可用于访问存储在不同区域的S3存储桶中的数据。应用程序可以使用多区域访问点来路由请求到最近的区域副本,从而提高性能。
启用版本控制:默认情况下为所有S3存储桶启用版本控制。
使用对象锁:对于不可变数据,使用对象锁来防止意外或恶意删除。
实施最小权限原则:仅授予用户访问其所需数据的权限。
使用S3复制进行灾难恢复:将数据复制到不同的区域,以便在发生区域性故障时进行恢复。
STG409-使用AWS Backup构建针对勒索病毒的韧性
STG409-Building resilience against ransomware using AWS Backup
本演讲针对勒索病毒攻击日益严峻的形势,详细介绍了如何利用AWS Backup服务构建多层次的数据保护和恢复策略,以最大程度地减少勒索病毒攻击带来的损失。演讲内容涵盖勒索病毒威胁形势分析、备份策略制定、AWS Backup功能特性、恢复策略实施以及最佳实践案例分享。
勒索病毒攻击日益复杂化,攻击者不仅加密数据,还窃取敏感信息,并威胁公开或出售以索取更高赎金。企业需要制定完善的防御策略,不仅要保护数据安全,还要确保业务连续性。AWS调查显示,超过90%的客户认为数据保护至关重要,而近60%的客户经历过数据丢失事件,其中勒索病毒攻击是最常见的原因之一。
备份是勒索病毒防御的最后一道防线,可确保在数据被加密或删除后进行恢复。攻击者通常会试图删除或破坏备份,因此需要采取措施保护备份安全。3-2-1-1备份策略:创建3份数据副本,将2份副本存储在不同的存储介质上,将1份副本存储在异地,并对1份副本进行不可变保护。
集中式备份管理:提供跨多个AWS服务的统一备份管理平台,简化备份策略配置和操作。
策略驱动:支持基于策略的备份计划,可根据数据类型、合规性要求和恢复目标自定义备份频率、保留期限和存储位置。
增量备份和连续备份:支持增量备份和连续备份,最大程度地减少备份数据量和备份窗口,降低存储成本和对生产环境的影响。
逻辑隔离保险库:支持将备份存储在逻辑隔离的保险库中,该保险库使用AWS自有的密钥进行加密,并限制用户访问权限,有效防止勒索病毒攻击和恶意删除。
恢复测试:提供自动化恢复测试功能,定期验证备份的可恢复性,确保在需要时能够快速可靠地恢复数据。
审计和合规性:与AWS Audit Manager和AWS Config集成,提供详细的备份活动日志和合规性报告,帮助企业满足法规遵从性要求。
快速检测和隔离:利用Amazon GuardDuty和AWS Security Hub等安全服务快速检测和隔离勒索病毒攻击,防止攻击扩散。
安全恢复:从逻辑隔离的备份中恢复数据,确保恢复的数据没有被感染。
测试和验证:定期测试恢复流程,确保在需要时能够快速有效地恢复业务运营。
备份策略制定:根据数据重要性和恢复目标制定分层备份策略,对关键数据进行更频繁的备份和更长的保留期限。
逻辑隔离:利用AWS Backup的逻辑隔离保险库功能保护备份安全,防止勒索病毒攻击和恶意删除。
权限控制:实施最小权限原则,限制对备份数据的访问权限,防止未经授权的访问和操作。
监控和告警:配置监控和告警机制,及时发现备份失败或异常活动,并采取相应措施。
恢复测试:定期进行恢复测试,验证备份的可恢复性和恢复流程的有效性。
STG201-Build a data foundation to fuel generative AI
本演讲重点介绍了如何构建和管理可扩展、经济高效的数据基础设施,以支持生成式AI应用。演讲涵盖了生成式AI的不同方法,包括检索增强生成(RAG)和微调,以及数据发现、数据准备和数据治理等关键数据注意事项。此外,还探讨了不同存储选项(如Amazon S3和Amazon FSx for Lustre)的优缺点,以及它们如何满足生成式AI工作负载的特定需求。
检索增强生成(RAG):RAG是一种利用现有基础模型生成新内容的方法,通过使用组织数据定制模型输出,无需重新训练模型。
首先,创建一个包含组织数据的知识库,该知识库将用于引导基础模型。当用户提出查询时,将知识库发送到基础模型以构建模型的输出。AWS提供了构建RAG工作流的工具,例如Amazon Bedrock,它用户可以使用Amazon S3存储桶或其他数据源创建知识库。
微调:微调涉及调整现有基础模型以适应特定任务或领域。需要高质量的标记数据来进行微调。AWS提供了用于微调的工具,例如Amazon Bedrock和Amazon SageMaker Canvas。微调过程可以通过调整模型的超参数(例如学习率和批大小)进行定制。
数据发现:确定相关数据源和数据格式对于生成式AI应用至关重要。数据源可以包括内部数据(例如公司文档和支持日志)、公共数据集以及从许可内容生成器购买的数据。数据格式因所使用的模型和所需的输出而异,包括文本、图像、音频和视频。
数据准备:并非所有数据都适合直接用于基础模型,可能需要进行预处理。文本数据预处理步骤包括识别数据源、清理和标记数据、将文本标记化为单词或子词,以及创建嵌入并将它们存储在向量数据库中。Amazon Bedrock知识库简化了数据准备过程,通过安全地将基础模型连接到专有数据源,并使用适当的信息补充提示来构建和引导模型的输出。
数据治理:数据治理对于确保数据安全和合规性至关重要。数据权限用于控制对数据的访问,确保只有授权用户和服务才能访问敏感信息。使用Amazon S3作为专有数据源可以提供强大的审计、合规性和安全功能。
存储接口:生成式AI应用需要不同的存储接口,包括块存储、对象存储和文件存储。
Amazon S3:S3是一个经济高效的对象存储服务,适用于存储各种数据,包括热数据和冷数据。S3提供了多种存储类,可以根据数据的访问模式优化成本。S3提供了高度可扩展的性能,适用于数据检索和处理。S3与许多关键的AI/ML工作流集成。
Amazon FSx for Lustre:Lustre是一个高性能文件系统,适用于需要高吞吐量和低延迟的生成式AI工作负载,例如从头开始训练基础模型。Lustre提供对几乎所有ML库的访问,这有助于完全优化GPU资源。Lustre提供了数十GB/s的吞吐量给GPU实例,总共数百GB/s的吞吐量。Lustre提供了一个直观的协作环境,包括与Amazon S3存储桶连接和同步数据的能力。
选择方法:RAG适用于构建现有基础模型,而微调适用于定制现有模型以执行特定任务。继续预训练或从头开始训练模型可以实现对特定领域或任务的更准确结果。
构建数据计划:数据计划应包括识别数据源、评估数据质量以及建立数据治理策略。
构建存储计划:选择正确的存储解决方案对于优化成本和性能至关重要。对于构建现有基础模型,Amazon S3提供了经济高效的存储。对于从头开始训练基础模型,Amazon FSx for Lustre提供了高性能存储。
STG208-AWS上的数据:三位AI创新者的成功关键
STG208-Data on AWS: The key to success for 3 AI innovators
本演讲邀请了三位来自不同领域的AI创新企业,分享了他们在AWS上构建和管理可扩展且经济高效的数据基础设施,以训练生成式AI模型的经验。演讲内容涵盖了他们的架构方法、设计模式和优化性能的最佳实践,例如扩展到高水平的聚合吞吐量,管理大型数据集的元数据目录以及负责任地存储AI生成的内容。
2.1 Canva:构建可扩展的数据平台以实现高效数据处理
Canva面临着管理海量图像和用户数据的挑战,为了实现高效的数据处理,他们构建了可扩展的数据平台,并利用AWS服务优化数据处理流程。
数据摄取:使用Amazon S3和Amazon Kinesis等服务收集和存储原始数据。
数据处理:利用Amazon EMR和Apache Spark等工具对数据进行清理、转换和聚合。
数据服务:将处理后的数据存储在Amazon S3和Amazon DynamoDB等服务中,以便于访问和分析。
Canva通过构建平台来加速数据科学家的工作,例如用于内容审核的审核平台和用于管理机器学习数据集的ML数据集平台。Canva重视数据质量,通过数据验证和数据清理流程确保数据质量,并建立了数据治理机制以确保数据安全和合规性。
2.2 Bria AI:利用Amazon S3进行大规模数据处理和优化
Bria AI使用Amazon S3作为其AI助手“Claw”的数据处理基础,管理超过200PB的数据集。
为了提高数据处理效率,Bria AI采用了多种AWS存储服务,包括:
Amazon S3:用于存储原始数据和处理后的数据。
Amazon FSx for Lustre:提供高性能文件存储,加速数据读取和写入速度。
Amazon EBS:提供块存储,用于存储临时数据。
Bria AI通过优化数据去重流程,将原本需要4-5天的处理时间缩短至1-2天。
2.3 Anthropic:构建负责任的AI系统,关注数据安全和隐私
Anthropic致力于构建安全、可靠且负责任的AI系统,并将数据安全和隐私作为首要任务。
Anthropic利用AWS服务构建安全的数据基础设施,例如:
Amazon S3:用于存储和管理数据,并利用S3的安全功能保护数据安全。
AWS IAM:用于管理用户访问权限,确保只有授权用户才能访问敏感数据。
AWS KMS:用于加密数据,防止未经授权的访问。
STG327-用于AI/ML、分析和HPC工作负载的高性能存储
STG327-High-performance storage for AI/ML, analytics, and HPC workloads
本演讲深入探讨了Amazon S3和Amazon FSx for Lustre如何为HPC、AI/ML和分析工作负载提供高性能、可扩展且经济高效的存储解决方案。演讲重点介绍了这些工作负载的存储使用模式,包括数据加载、检查点设置和结果存储,并分析了影响存储性能的关键因素,如吞吐量、延迟和数据访问模式。演讲还通过实际案例展示了如何利用Amazon S3和Amazon FSx for Lustre优化存储性能并满足不同工作负载的需求。
高性能工作负载是指需要快速访问海量数据集的应用程序或进程,通常需要并行访问和低延迟。
这些工作负载包括AI/ML模型训练、高频交易算法、风险分析和实时媒体内容生成。
高性能工作负载对存储解决方案提出了更高的要求,需要持续创新以满足其性能需求。
高性能工作负载通常使用文件存储和对象存储解决方案。
数据加载:将数据加载到计算和GPU实例中,可以通过将数据复制到本地存储或直接从共享存储解决方案流式传输数据来实现。
检查点设置:定期保存模型训练或模拟的中间状态,以便在发生故障时可以恢复。
结果存储:存储最终模型、模拟结果或分析输出,通常存储在持久存储中以供将来使用。
存储性能对高性能工作负载的效率至关重要,存储瓶颈会导致计算资源闲置,从而增加成本。
数据访问模式:顺序访问或随机访问,以及读取和写入操作的比例。
吞吐量:每秒可以读取或写入存储的字节数,以GB/s或TB/s来衡量。
Amazon S3是一种可扩展、持久且经济高效的对象存储服务,适用于存储各种数据,包括热数据和冷数据。
S3提供了多种存储类别,可以根据数据访问模式优化成本。
对于数据湖,推荐使用S3通用存储桶或S3 Express One Zone目录存储桶。
S3 Express One Zone提供了更低的延迟,适用于需要频繁访问相同对象的场景,例如机器学习训练和交互式分析。
ClickHouse是一个开源的列式数据库管理系统,专为实时分析而设计,它利用S3存储数据,并通过S3 Select功能优化查询性能。
2.5 Amazon FSx for Lustre的优势和用例
Amazon FSx for Lustre是一种高性能文件系统,适用于需要高吞吐量和低延迟的工作负载,例如机器学习训练和高性能计算。
Lustre提供了对几乎所有机器学习库的访问,可以充分利用GPU资源。
Lustre可以为GPU实例提供数十GB/s的吞吐量,总吞吐量可达数百GB/s。
Lustre提供了一个直观的协作环境,可以与Amazon S3存储桶连接和同步数据。
对于需要低延迟的场景,FSx for Lustre比直接从S3读取数据更快,因为它将数据缓存在内存中。
2.6 将Amazon S3和Amazon FSx for Lustre结合使用
许多客户将Amazon S3和Amazon FSx for Lustre结合使用,以满足其高性能工作负载的需求。
一种常见的模式是将S3用于长期存储训练数据和模型输出,而将FSx for Lustre用于高性能数据访问,以加速训练运行时间。
STG332-使用AWS存储加速数据库性能和可扩展性
STG332-Accelerate database performance and scalability with AWS storage
本演讲深入探讨了如何利用Amazon Elastic Block Store(EBS)和Amazon FSx等AWS存储服务来提升数据库性能、可扩展性和成本效益。演讲重点介绍了不同EBS卷类型和FSx文件系统的特点和适用场景,以及如何利用快照、克隆和高可用性功能创建敏捷的开发和测试环境,加速迭代并确保在中断事件期间无缝运行数据库。
企业将数据库迁移到AWS的速度越来越快,以降低成本、加快创新并专注于应用程序开发。
自我管理型存储支持企业根据自身需求定制数据库环境,例如选择特定的操作系统、处理器类型或集成到特定工作流程中。
对于希望利用AWS云优势并可能集成云分析或数据湖功能的企业而言,自我管理型存储提供了灵活性和控制力。
通用型SSD(gp3):适用于大多数数据库工作负载,提供均衡的IOPS和吞吐量性能。它是预配置Amazon RDS实例的默认EBS卷类型。
预配置IOPS SSD(io2):适用于需要高IOPS和低延迟的数据库工作负载,例如OLTP数据库。
io2 Block Express:专为要求最苛刻的IO密集型高性能应用程序设计,提供一致的亚毫秒级延迟性能。适用于SAP HANA、Oracle、Microsoft SQL Server、MySQL等数据库。
快照管理:快照可用于复制、备份和灾难恢复,提供数据库的数据保护功能。
数据生命周期管理(DLM):可用于自动管理快照,优化存储成本并简化操作。
弹性卷:支持在不中断数据库运行的情况下修改卷大小、类型或性能,将性能与存储大小分离。
多重连接:io2 Block Express支持多重连接,支持多个EC2实例同时访问相同的卷,适用于需要高可用性和数据共享的数据库部署。
性能指标:EBS提供详细的性能指标,例如IOPS、吞吐量和延迟,可用于监控数据库性能并识别瓶颈。
Amazon FSx for NetApp ONTAP:提供与NetApp ONTAP相同的功能,适用于需要企业级功能(如数据去重和压缩)的数据库工作负载。
Amazon FSx for OpenZFS:提供高性能和低延迟,适用于对性能要求苛刻的数据库工作负载,例如AMD的OpenZFS部署案例。
复制:对于支持复制的存储服务(如ONTAP和OpenZFS),可以使用复制将数据迁移到FSx。
AWS DataSync:适用于不支持复制的存储服务的数据库数据迁移。
SnapMirror:FSx for NetApp ONTAP支持SnapMirror,可用于跨区域或本地和AWS之间的数据保护和复制。
高可用性:FSx文件系统支持多可用区部署,提供数据库的高可用性和数据冗余。
数据压缩和去重:FSx for NetApp ONTAP支持数据压缩和去重,可减少存储空间使用并降低成本。
STG304-Amazon S3安全性和访问控制最佳实践
STG304-Amazon S3 security and access control best practices
本演讲讲解了Amazon S3的安全机制和访问控制策略,并详细介绍了如何通过配置桶策略、访问点策略、IAM策略、S3访问授权、Lake Formation等功能实现精细化的数据访问管理,以及如何利用资源控制策略、访问分析器、服务器访问日志和AWS CloudTrail日志进行安全审计和监控。
默认安全配置:新创建的S3桶默认启用以下安全配置:
默认加密:所有新对象都使用AWS SSE-S3(由S3管理的服务器端加密)进行加密。
阻止公共访问:默认情况下阻止所有公共访问,防止公共访问配置错误。
禁用ACL:默认情况下禁用访问控制列表(ACL),鼓励使用IAM进行访问控制。
IAM用户和角色是主体,可以使用其凭证对AWS API(包括S3 API)进行签名请求。
资源(如S3桶)和主体(如IAM角色)都有附加的策略,用于定义其权限。
策略可以是允许策略(授予访问权限)或拒绝策略(拒绝访问权限)。
Action:指定允许或拒绝的操作,例如s3:GetObject。
Resource:指定策略适用的资源,例如特定的S3桶或对象。
Condition:可以添加条件来限制访问,例如基于请求来源IP地址或时间的条件。
可以使用桶策略授予其他AWS账户对S3桶的访问权限。
可以使用Principal元素指定允许访问的账户ID。
对于使用AWS Organizations的企业,可以使用PrincipalOrgID允许来自同一组织的所有账户访问。
拒绝策略可用于建立数据边界,拒绝来自意外来源的访问。
可以拒绝来自非VPC和非本地数据中心的请求,同时使用条件语句允许AWS服务访问。
对于使用AWS Organizations的企业,可以使用RCP为S3桶设置最大可用权限。
RCP可以应用于现有和未来的所有桶,简化安全管理和审计。
提供了一个仪表板,用于显示具有公共访问权限的桶以及与外部实体共享的桶。
分析访问点策略、桶策略和ACL,以识别潜在的安全风险。
服务器访问日志和AWS CloudTrail日志:
启用服务器访问日志和CloudTrail日志可以跟踪对S3数据的访问。
CloudTrail提供了更全面的审计信息,建议优先使用CloudTrail进行审计。
为S3桶提供替代端点,每个访问点都有自己的IAM策略。
可以为不同的数据文件夹创建不同的访问点,并将权限委托给访问点级别。
可以使用S3访问点策略更精细地控制数据访问,并绕过S3桶策略的大小限制。
支持将S3访问权限直接链接到身份提供程序(如Okta或Active Directory)。
简化了对S3数据集的权限管理,尤其是在用户加入或离开企业时。
提供了精细的访问控制,可以授予用户对特定前缀(文件夹)的读、写或列出权限。
支持可信身份传播,用户的身份信息会传递到S3,方便审计和监控。
为AWS Glue数据目录提供权限系统,用于管理对结构化数据的访问。
支持对表、列和行进行精细的访问控制,例如基于单元格级别的访问控制。
简化了数据湖的安全管理,并提供了集中式的权限管理机制。
最小权限原则:仅授予主体完成其任务所需的最低权限。
使用拒绝策略建立数据边界:拒绝来自意外来源的访问请求。
启用多重身份验证(MFA):为敏感操作添加额外的安全层。
使用AWS KMS加密数据:控制对加密密钥的访问。
定期审计访问权限:使用访问分析器、服务器访问日志和CloudTrail日志监控数据访问模式。
利用自动化工具:使用AWS Organizations和RCP简化安全管理。
STG305-使用SFTP实现托管文件传输的现代化
STG305-Modernize managed file transfer with SFTP
如何利用AWS Transfer Family服务通过SFTP协议构建安全、高可用且可扩展的托管文件传输方案,以替代传统的自建SFTP服务器,从而降低管理成本和安全风险,并提高数据传输效率和可视化程度。演讲重点阐述了Transfer Family的核心功能,包括多种协议支持、灵活的身份验证和访问控制机制、自动化工作流程和事件驱动架构集成、以及与Amazon S3数据湖的无缝衔接。
降低管理负担:使用AWS托管服务可以免除维护SFTP服务器基础设施的负担,包括硬件维护、软件更新、安全补丁和24/7运行保障。
提高安全性:Transfer Family提供多种安全功能,包括数据加密、静态IP地址、VPC端点、安全组、IAM身份验证和CloudTrail审计日志记录,确保数据传输安全合规。
增强可扩展性:Transfer Family可以根据业务需求自动扩展,无需手动配置和管理服务器容量,支持高并发连接和海量数据传输。
简化集成:Transfer Family可以与其他AWS服务无缝集成,例如Amazon S3、AWS Step Functions、Amazon EventBridge和AWS Lambda,构建自动化数据流水线和事件驱动架构。
降低成本:Transfer Family采用按使用量付费的模式,无需预先投资硬件和软件,可以根据实际需求灵活调整成本。
2.2 AWS Transfer Family概述
支持多种协议:SFTP, FTPS, FTP, AS2以及HTTPS(通过Web Apps实现)
灵活的身份验证:支持IAM用户、AWS Directory Service、自定义Lambda函数以及身份中心集成
精细的访问控制:可以使用IAM策略、安全组、VPC端点和IP白名单限制访问
自动化工作流程:提供内置工作流程和EventBridge集成,实现文件处理自动化
数据湖集成:可以将数据直接传输到Amazon S3,构建数据湖和分析平台
Re:gion One:利用Transfer Family构建内部文件传输服务,支持数千名内部和外部用户安全地上传和下载TB级数据。
FINRA:使用Transfer Family将数据直接上传到Amazon S3数据湖,简化数据分析流程。
新加坡政府:使用Transfer Family收集电动汽车充电数据,并利用AWS Step Functions和Amazon EMR进行分析,以优化充电站部署策略。
事件驱动架构:Transfer Family与Amazon EventBridge集成,在文件上传、下载等事件发生时触发事件,并调用其他AWS服务进行处理,例如Step Functions、Lambda、SQS、SNS等,实现自动化工作流程和数据分析。
上下文感知事件:事件包含丰富的上下文信息,例如文件上传者、时间戳、IP地址、协议类型等,可以根据这些信息进行精细化的数据处理和分析。
安全合规:Transfer Family服务器满足HIPAA和PCI等行业合规性标准,确保数据传输安全可靠。
协议支持:SFTP, FTPS, AS2, HTTPS(通过Web Apps实现)
网络安全:支持VPC端点、安全组和IP白名单限制访问
SSH密钥:使用Transfer Family托管用户
密码验证:集成AWS Directory Service或自定义Lambda函数
Web Apps:使用身份中心和S3访问授权,为非技术用户提供简单易用的Web界面
托管工作流:提供预定义的简单工作流程,例如文件复制、加密/解密、标签添加、删除等,也可以使用Lambda函数进行自定义步骤。
EventBridge集成:支持更灵活的事件驱动工作流程,可以使用Step Functions协调多个AWS服务进行复杂的数据处理和分析。
SFTP连接器:提供完全托管的SFTP客户端,可以从外部SFTP服务器下载或上传文件,并与EventBridge集成,实现自动化工作流程。
静态IP地址:支持为连接器分配静态IP地址,方便与外部系统集成。
标准化安全策略:提供预定义的安全策略,提高与外部服务器的兼容性。
API支持:提供API用于列出文件、检查传输状态等操作,方便与其他系统集成。
面向非技术用户:提供简单易用的Web界面,支持非技术用户通过浏览器上传和下载文件。
身份中心集成:使用身份中心进行用户身份验证,并使用S3访问授权进行访问控制。
完全托管:无需管理服务器基础设施,AWS负责维护高可用性和安全性。
可定制品牌:可以自定义Web界面外观,与企业品牌保持一致。
STG210-AWS storage best practices for cost optimization
本演讲深入探讨了AWS存储服务的成本优化策略,包括从本地迁移到云端的成本优势、为不同工作负载选择合适的存储服务,以及利用AWS工具持续监控和优化存储基础设施。演讲详细介绍了Amazon EBS、Amazon FSX、Amazon EFS和Amazon S3四种主要存储服务的特点、适用场景以及成本优化技巧,并提供了真实客户案例和最佳实践建议。
消除过度配置:本地存储通常需要预留额外的容量以应对未来增长,导致资源闲置和成本浪费。AWS存储服务按需付费,只收取实际使用的存储空间费用,避免了过度配置问题。
减少RAID开销和格式化损失:本地存储需要配置RAID阵列以提高数据可靠性,并进行格式化才能使用,这些操作会占用额外的存储空间。AWS存储服务由AWS管理,无需用户配置RAID和格式化,节省了存储空间。
利用AWS原生工具进行优化:AWS提供多种原生工具,例如压缩和去重,可以进一步降低存储成本。
弹性扩展和按需付费:AWS存储服务可以根据业务需求弹性扩展,无需预先投资硬件和软件。按使用量付费的模式可以帮助用户根据实际需求灵活调整成本。
Amazon EBS:高性能块存储,适用于关系型数据库、NoSQL数据库、大数据分析和企业应用等对性能敏感的工作负载。
Amazon FSX:全托管文件存储服务,提供多种文件系统类型(例如Windows文件服务器、NetApp ONTAP、OpenZFS和Lustre),适用于各种文件共享和高性能计算工作负载。
Amazon EFS:云原生弹性文件存储服务,支持多实例共享、数据持久化和高并发访问,适用于DevOps、机器学习和容器化应用等场景。
Amazon S3:对象存储,具有高可扩展性、持久性和成本效益,适用于数据湖、备份和恢复、移动应用以及AI/ML应用等各种场景。
从GP2迁移到GP3:GP3提供更高的性价比,每GB每月成本比GP2低20%。
使用弹性卷:弹性卷用户可以动态调整卷大小、类型和性能,无需中断操作,确保只为所需资源付费。
使用快照归档:将不再访问的EBS卷快照迁移到快照归档,可以降低存储成本。
利用原生工具(例如压缩和去重)最大限度地提高存储效率。
对于NetApp ONTAP,使用数据分层,将不常访问的数据存储在容量池中,可以节省高达88%的存储成本。
考虑使用FSX for OpenZFS,它比传统NAS部署的成本低20%。
使用新的FSX智能分层存储类,该存储类基于Amazon S3智能分层存储类,提供完全弹性存储和自动成本优化。
为工作负载选择合适的存储类:对于频繁访问的数据,使用EFS Standard;对于不常访问的数据,使用EFS Infrequent Access或EFS Archive。
配置生命周期管理策略:自动将数据在不同存储类之间移动,优化存储成本。
选择最佳吞吐量模式:对于需要最高性能的工作负载,使用预配置吞吐量模式;对于弹性需求的工作负载,使用弹性吞吐量模式。
选择合适的存储类:根据数据访问频率、对象大小和数据保留要求选择最佳存储类。
利用S3智能分层:对于未知或不断变化的访问模式,S3智能分层可以自动管理存储架构,将数据移动到较冷的访问层,优化存储成本。
利用生命周期策略:对于已知的访问模式,使用生命周期策略将数据转换到较冷的存储类或过期数据,节省成本。
使用S3 Storage Lens:获取对存储桶、策略、访问模式和对象大小的更深入了解,以便做出更明智的数据驱动决策并节省存储成本。
T-Mobile:从本地迁移到Amazon S3,解决了扩展和性能挑战,并降低了存储成本。
Illumina:使用S3智能分层和生命周期策略,三个月内将存储成本降低了60%。
Upstox:使用S3 Storage Lens高级指标和AWS服务,每年节省超过100万美元的存储成本。



