


目前项目的日志收集用到了kafka,每天收集几亿条日志数据,梳理了一下kafka在高并发方面的知识,来帮助理解Kafka是如何做到超高并发(百万级)的,设计很是精妙,尤其是他的暴力输入输出美学,深受启发,并在后续项目中得到了应用。
巧用文件系统
按照kafka官网的话说,不要害怕文件系统。可能很多人一想到磁盘就会想到慢这个字,但是磁盘的性能表现好坏在于你的使用。
我们以kafka官方例子为例,在6个7200rpm SATA RAID-5 阵列的 JBOD 配置上,顺序写入性能约每秒600MB,而随机写入的性能约每秒100k,差了6000倍。可以看一下官方给出的性能图对比
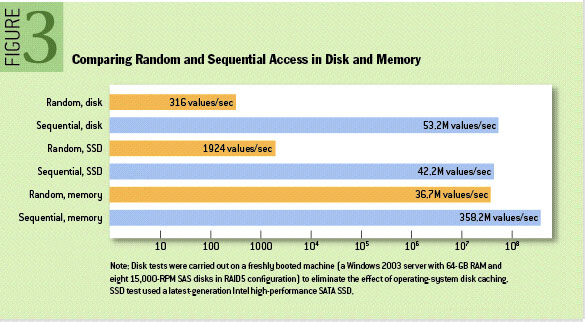
首先顺序操作磁盘免去了大量的寻道和旋转延迟,因为即将访问的扇区刚好位于上次访问的扇区后边,磁头立刻就找到了扇区。其次顺序读写是最可预测的,而且操作系统做了大量这方面的优化,操作系统提供了预读和延迟写入技术,使得可以以块整数倍的大小预取数据,并把小块写入逻辑,聚合成大块物理写入。
mmap技术应用
除了顺序操作磁盘,充分利用操作系统将空闲内存转义到磁盘缓存这个机制,及mmap技术。使用mmap技术,进程可以像操作硬盘一样操作内存,这种方式可以大幅度提升I/O性能,也能省去用户空间到内核空间的复制开销。可能有人会问,为什么程序不自己维护缓存,要交给操作系统,先不说增加了用户空间到内核空间的拷贝过程,还有一点kafka基于Java开发的,Java中对象内存开销大,堆内存的增加,GC过程会越来越繁琐和缓慢,使用页缓存,可以使程序迅速重启,缓存也可继续使用。
长时间保留消息,而不是阅后即焚。在持久化消息上,并没有使用像MySQL那样的BTree,因为BTree的操作是O(logN) 磁盘操作寻道时间可能就会达到10毫秒,开销巨大,kafka直接采用简单的读取和追加到文件上,操作为O(1),性能与数据大小分离。廉价的机器照样能跑出高性能。没有了频发的数据删除操作,相当于又进一步减小了磁盘寻道损耗,而且还能使消费端更加灵活的消费(可以重新消费之前消费过的数据)。
消息批量处理
首先思考一下,有一百条消息,分成一百次通过网络传给远端机器快,还是做好聚合,一次性传给远端机器快?如果内部网络一秒能传输10M以上的数据,如果把百万条消息压缩在在10M数据上,然后通过网络一次性传给远端,那是不是就相当于完成了百万级的TPS?
我想上边的答案非常明显,显然是批量处理更快,能更大程度的减少网络io带来的延迟。Kafka就采用了这个方式,给你的感觉像是每次在一条一条push消息,其实不然,Kafka会在内存中暂存你的消息,在适当的时机,一下子把所有消息发送出去,也就是一波消息被发走。
消息批量处理并不是只是发送的时候是批量,而是从生产者、broker到消费者一直都是这样,这个批次的消息在kafka看来好像就是一条消息一样,生产者在生产端将消息聚合,broker什么都不做,按”一个“消息存储,最后由消费者拿到消息后解开一条条消费。问题来了,都知道kafka利用offset机制实现从不同位置消费消息,如果消息批量了,我该怎么消费批量里边的某条呢?看下边的例子
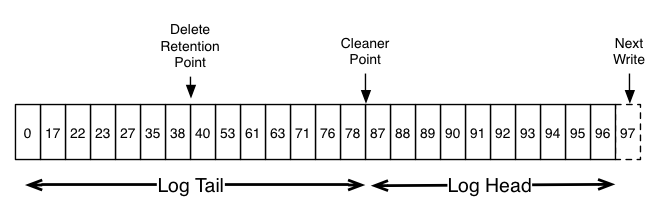
offset传36、37还是38是一样的都是拿图中38的开头的消息,消费者拿到这个集体消息后,在取出感兴趣的消息即可。
另外为了提升传输效率,kafka还做了端到端的消息压缩,生产者将批量消息压缩,broker原样保存压缩数据,最有有消费者获取后解压缩,这又进一步提升了传输效率。
总而言之,批量处理和压缩的目的就是使用相当小的cpu开销,换取高效的网路传输,解决网络带宽的瓶颈。
零拷贝
通常情况下,文件数据到套接字传输的数据路径要经过4个步骤:
- 操作系统从磁盘读取数据到内核空间缓冲区
- 应用程序从内核空间读取数据到用户空间缓冲区
- 应用程序将数据写回内核空间套接字缓冲区
- 操作系统将数据从套接字缓冲区赋值到网络发送的NIC缓冲区
这四步数据会在数据总线上来来回回被传输,而零拷贝(主要函数sendfile)解决了这个问题,只需两步
- DMA从硬盘读数据到操作系统内核读缓冲区
- 根据套接字描述服信息,直接从读缓冲区里面写入到网卡的缓冲区
这显然比通常的四步骤高效的多。想下这个场景,如果消费的足够快,页缓存和零拷贝是不是可以让消费者消费的消息几乎都是从缓存中拿到的数据,根本不用去读磁盘(数据还没来得及从缓存中失效就被消费者拉走了)。
简洁的消费者逻辑
kafka没有采用推的方式通知消费者,而是由消费者自己根据消费情况,主动拉取消息,首先服务端没有了主动推的压力,另外消费端也变的非常的灵活。如果是拉,还需要再解决一个及时性的问题,堆积的未读消息多,消费者可以一直拉,但是如果此时没有消息,如果消息到了怎么能及时让消费者能知道呢?即便消费者每隔一段时间过来拉取,照样还是存在时延,kafak为了避免这种情况,在拉取请求中设置了参数,允许消费者请求在“长轮询”中阻塞,等待数据到达。
在kafka中多个消费者构成一个消费组,这些消费者拥有消费组的共有属性,例如都能去消费消费组目标topic的消息。
在记录消费者消费到哪条消息上,更是简洁,kafka并不为每个消费者维护一个”消费进度“。在kafka中每个topic分为一组完全有序的partitions,消息落地在partitions上,每个partitions在某个时刻只能有一个消费组内的消费者去消费,每个partitions只记录消费组在本partitions的消费的topic的”消费进度“,消费者来到这个partitions,kafka只需要找到消费者所在的消费组在本partitions的”消费进度“然后给出后边消息即可。
这有很大的优势,kafka免去了复杂的消费者消费进度维护逻辑,使其变得相当简单和易于维护,而且partitions做到了单点(一个消费者)消费,免去了多点带来的问题。另外需要注意消费者数量尽量和partitions数量一致,这样每个partitions都能分到一个消费者,如果消费者多于partitions数量,就意味着有的消费者空闲,消费者少于partitions数量,就意味着有的消费者消费多个partitions。
如果想进一步提升消费速度,其中方法之一就是适当的增加partitions的数量,使得更多的消费者去消费。
