


客户报告某资源池一台机器有3次crash,
操作系统:centos 3.10.0-957.el7.x86_64
cpu: Intel(R) Xeon(R) Gold 6132 CPU @ 2.60GHz
分析3次crash生成的vmcore文件,都发现是同一个调用栈出现问题。下面以其中一次的crash日志分析,其calltrace如图1-1所示
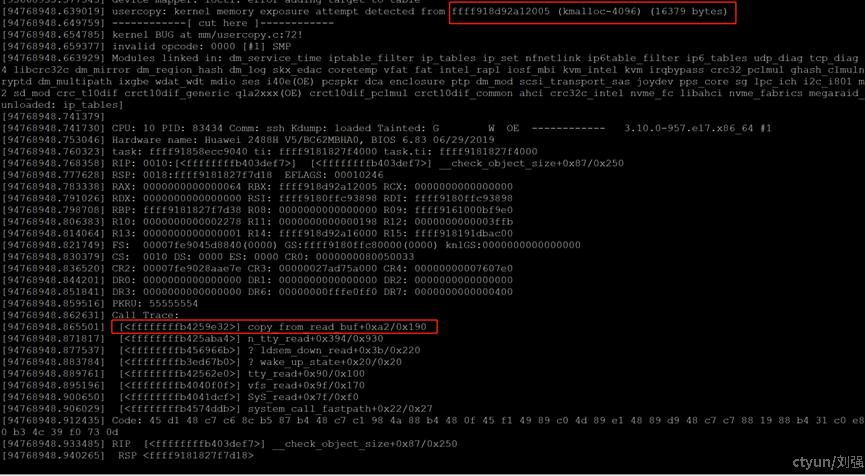
图1-1 crash 信息
查看代码,出问题位置如下:

图1-2 生成crash的代码
是通过如下函数调用实现cp 数据到用户态时出了问题。
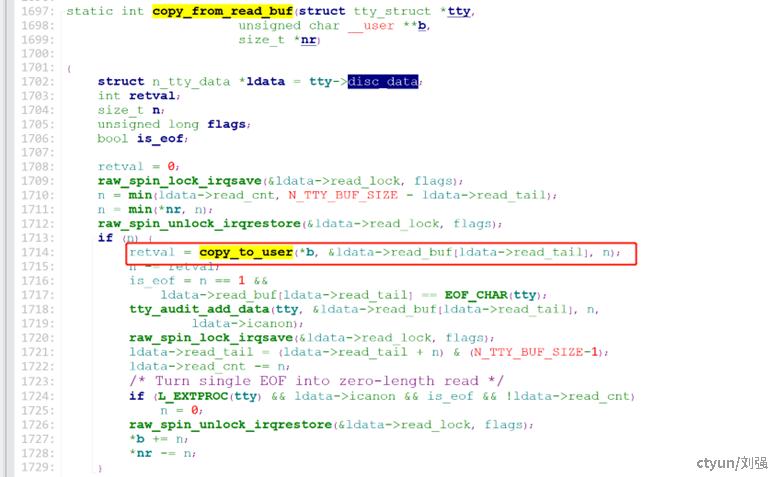
图1-3 调用crash函数的上层代码
出问题点位于往用户态拷贝对访问的数据区进行检查时,copy_to_user函数原型如下:
unsigned long
copy_to_user(void __user *to, const void *from, unsigned long n)
根据错误提示,ffff918d92a12005 对应的是一个kmalloc-4096 的slab,在未开启slab(slub)的debug的情况下,对应的size应该是4096字节,而(16379 bytes),就是我们本次需要访问的长度,对于copy_to_user的检查来说,是越界了,产生了crash。
通过分析图1-4的函数调用栈

图1-4 crash函数调用栈跟踪信息
从图1-4中得出 copy_from_read_buf的tty参数地址为0xffff918191dbe800
其tty->disc_data地址如下:

图1-5 ldata信息与代码信息

图1-6 crash时的ldata结构中的数据
从图1-6得出 ldata->read_buf = 0xffff918d92a12000
ldata->read_buf[ldata->read_tail] = 0xffff918d92a12000+5=0xffff918d92a12005和图1-1中出问题的地址一致。
从图1-4中size_t *nr为

图1-7 copy_from_read_buf函数的nr参数
16379和图1-1中读取的数据相符
n = min(ldata->read_cnt, N_TTY_BUF_SIZE - ldata->read_tail);
n = min(*nr, n);
ldata->read_cnt = -5
N_TTY_BUF_SIZE = 4096
ldata->read_tail = 5
*nr = 16379
计算出n 为16379(注意n的类型是size_t,所以-5是一个非常大的数)
这里ldata->read_buf大小是N_TTY_BUF_SIZE 为4096,
*nr是上层应用提供的缓冲区的大小,超过4096也没有问题,
这里我们注意到ldata->read_cnt = -5

图1-8 n_tty_data结构体定义
在高版本内核此结构体已经把read_cnt去掉,read_head,和read_tail定义成size_t

图1-9 高版本内核n_tty_data结构体定义
通过trace 发现正常情况下centos7.6下的tty,不会出现read_cnt为负的情况,出现负数的场景通过分析代码无法得知,社区也没有发现相关讨论。
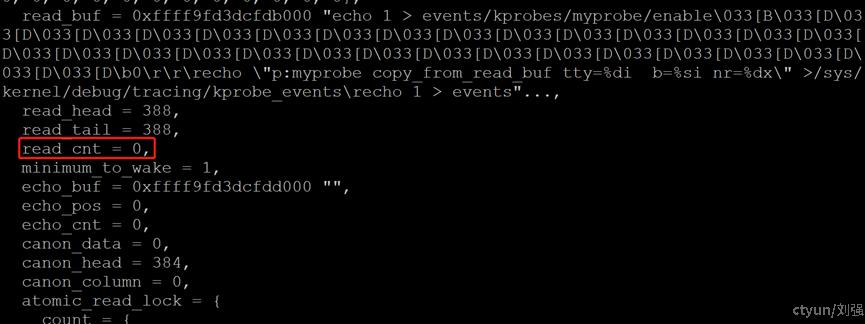
图1-10 centos 7.6正常情况下trace的read_cnt为非负数
所以只能确定此问题是tty 驱动程序的一个bug,通过查找发现upstream 相关修改的commit如图1-11所示
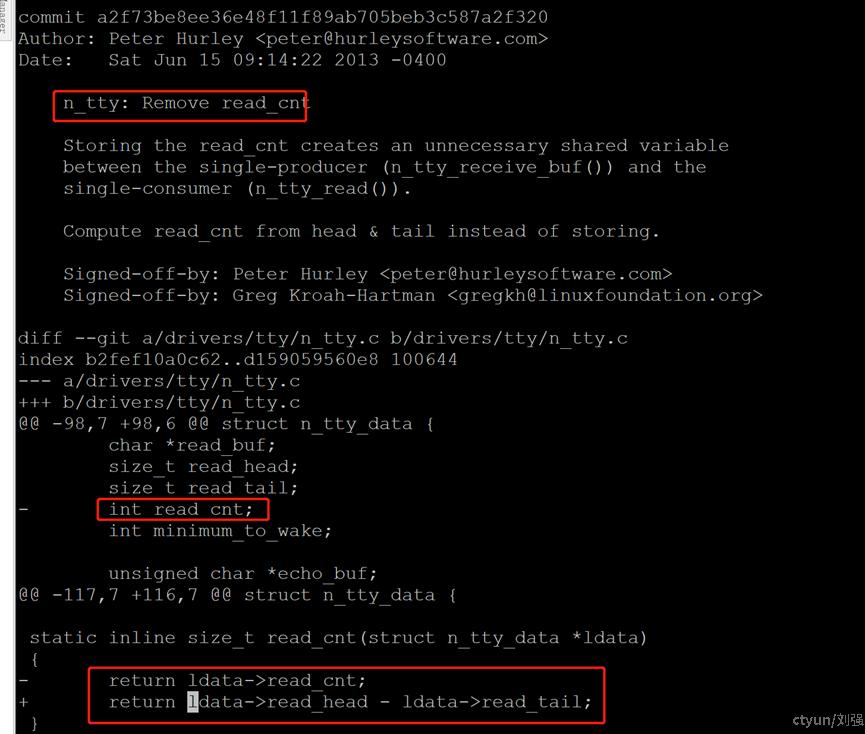
图1-11 社区修改read_cnt的commit
对应版本信息为linux 3.12,出问题系统为3.10.0-957.el7.x86_64, 低于社区3.12版本。

图1-12 社区修改read_cnt的版本信息
通过分析centos镜像中的源代码,发现Centos 3.10.0-1062.el7 linux-3.10.0-1127 linux-3.10.0-1160都已修复了此问题
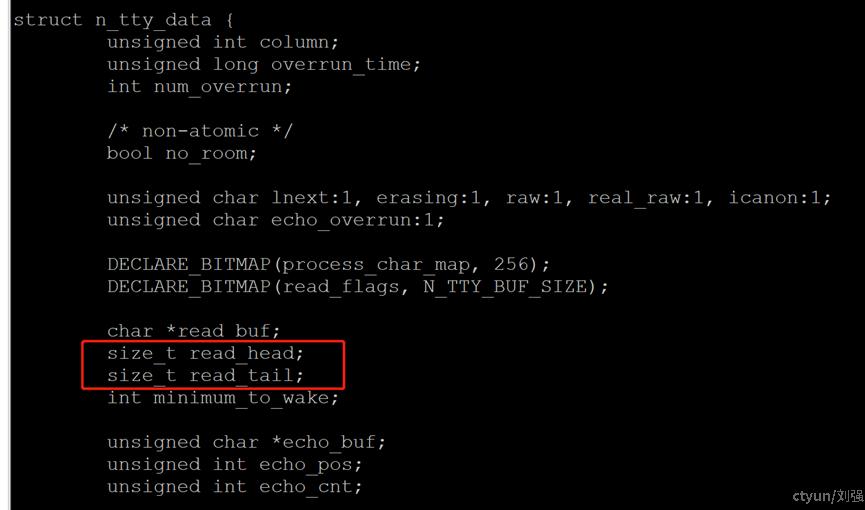
图1-13 3.10.0-1062修复此问题对应结构体
基于目前的分析和信息来说,解决此问题方法为升级系统到Centos 3.10.0-1062.el7及以上版本。
