


服务发现
首先要向某个服务器发起请求,你得先建立连接,而建立连接的前提是,你得知道IP地址和端口。这个找到服务对应的IP端口的过程,其实就是服务发现。
在HTTP中,你知道服务的域名,就可以通过DNS服务去解析得到它背后的IP地址,默认80端口。
而RPC的话,就有些区别,一般会有专门的中间服务去保存服务名和IP信息,比如consul或者etcd,甚至是redis。想要访问某个服务,就去这些中间服务去获得IP和端口信息。由于dns也是服务发现的一种,所以也有基于dns去做服务发现的组件,比如CoreDNS。
底层连接形式
以主流的HTTP1.1协议为例,其默认在建立底层TCP连接之后会一直保持这个连接(keep alive),之后的请求和响应都会复用这条连接。
而RPC协议,也跟HTTP类似,也是通过建立TCP长连接进行数据交互,但不同的地方在于,RPC协议一般还会再建个连接池,在请求量大的时候,建立多条连接放在池内,要发数据的时候就从池里取一条连接出来,用完放回去,下次再复用,可以说非常环保。
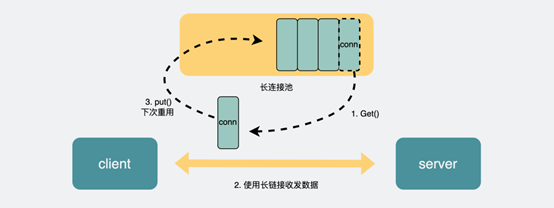
由于连接池有利于提升网络请求性能,所以不少编程语言的网络库里都会给HTTP加个连接池,比如go就是这么干的。
传输的内容
基于TCP传输的消息,说到底,无非都是消息头header和消息体body。
header是用于标记一些特殊信息,其中最重要的是消息体长度。
body则是放我们真正需要传输的内容,而这些内容只能是二进制01串,毕竟计算机只认识这玩意。所以TCP传字符串和数字都问题不大,因为字符串可以转成编码再变成01串,而数字本身也能直接转为二进制。但结构体呢,我们得想个办法将它也转为二进制01串,这样的方案现在也有很多现成的,比如json,protobuf。
这个将结构体转为二进制数组的过程就叫序列化,反过来将二进制数组复原成结构体的过程叫反序列化。
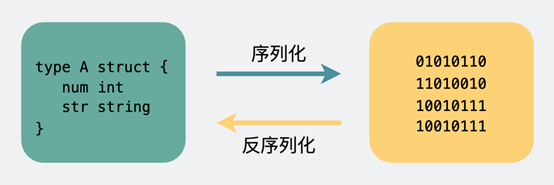
序列化和反序列化
对于主流的HTTP1.1,虽然它现在叫超文本协议,支持音频视频,但HTTP设计初是用于做网页文本展示的,所以它传的内容以字符串为主。header和body都是如此。在body这块,它使用json来序列化结构体数据。
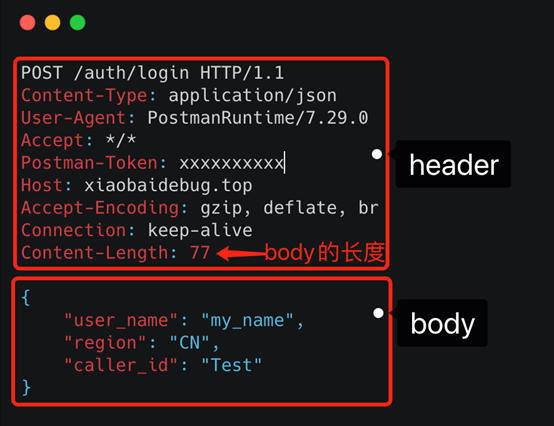
HTTP报文
可以看到这里面的内容非常多的冗余,显得非常啰嗦。最明显的,像header里的那些信息,其实如果我们约定好头部的第几位是content-type,就不需要每次都真的把"content-type"这个字段都传过来,类似的情况其实在body的json结构里也特别明显。
而RPC,因为它定制化程度更高,可以采用体积更小的protobuf或其他序列化协议去保存结构体数据,同时也不需要像HTTP那样考虑各种浏览器行为,比如302重定向跳转啥的。因此性能也会更好一些,这也是在公司内部微服务中抛弃HTTP,选择使用RPC的最主要原因。
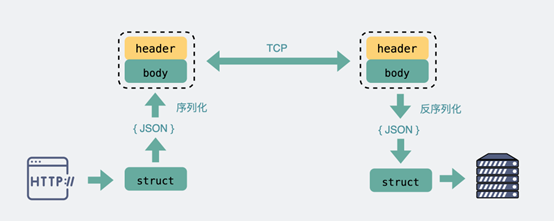
HTTP原理
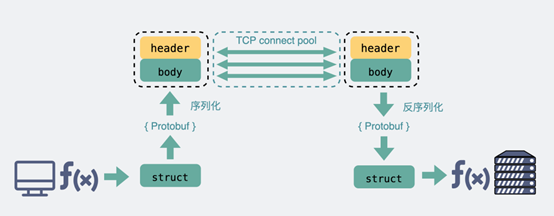
RPC原理
当然上面说的HTTP,其实特指的是现在主流使用的HTTP1.1,HTTP2在前者的基础上做了很多改进,所以性能可能比很多RPC协议还要好,甚至连gRPC底层都直接用的HTTP2。
