ClickHouse Keeper 主旨用于替代 Zookeeper,与ZK协议兼容,对于使用了Replicated表的场景总,ClickHouse Sever与Keeper会产生频繁的交互(Part的复制),在一般场景中,如果在增长keeper节点数后性能仍然不能增长,这种情况就考虑拆分keeper集群,使得具备相互复制的节点在同一集群下,但缺点为DDL等下发需要跑本地表(不能在跑 on cluster xxx发送所有节点)。
一、Keeper的关键性能指标
| 指标名 | 说明 |
| zk_avg_latency | 平均请求延迟 |
| zk_outstanding_requests | 排队的请求数 |
| zk_znode_count | znode数量 |
| zk_znode_incr (自定义指标) | znode增长数 |
| zk_ephemerals_count | 临时节点数 |
| zk_approximate_data_size | 数据大小 |
|
zk_open_file_descriptor_count zk_max_file_descriptor_count |
文件打开数与最大数 |
二、数据存储
在ClickHouse 使用replicated表时,则会在keeper中上报自己的part地址,其他节点则通过监听此地址,配合服务配置xml中参数,利用内部TCP通信拉取真正的数据以减轻keeper压力。
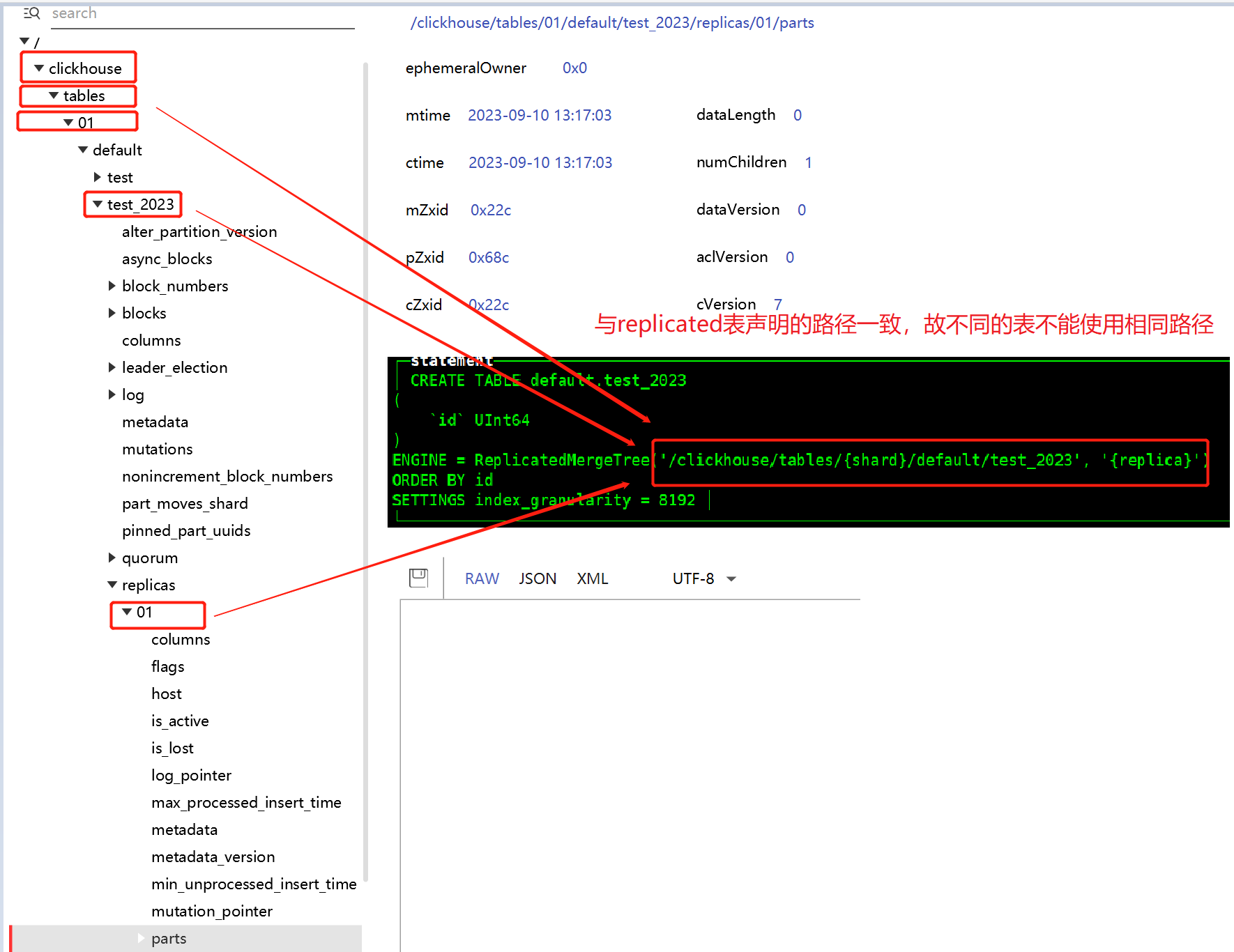
2.1 数据复制变化
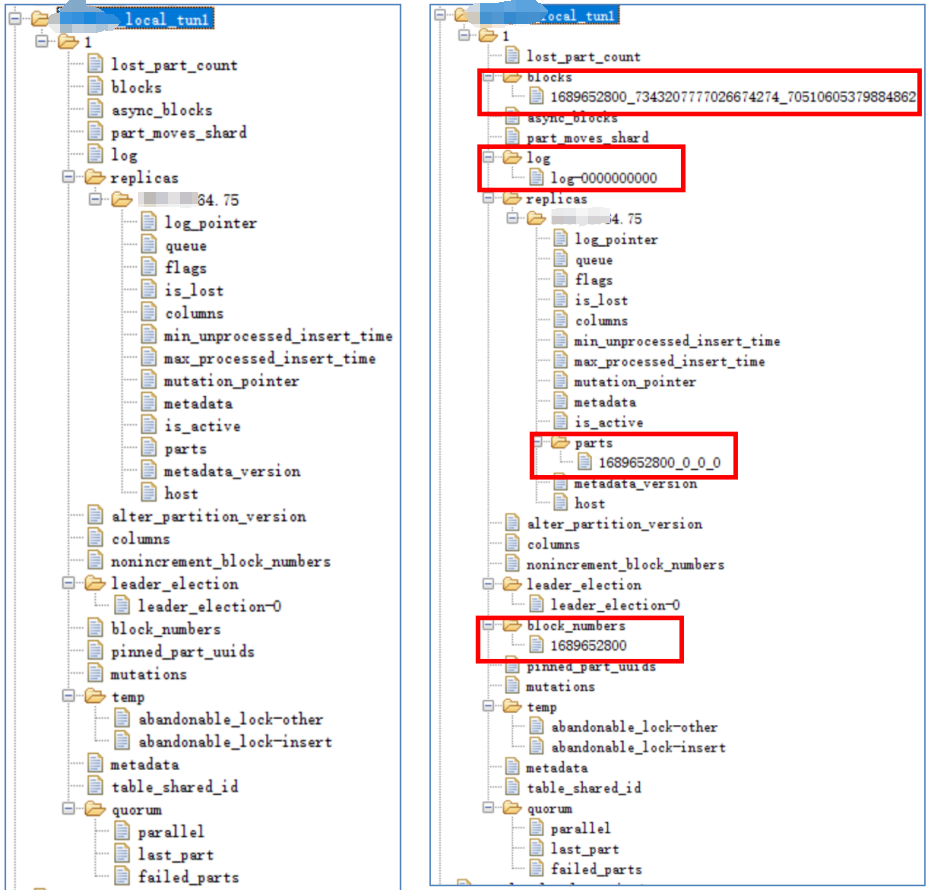
下面以往一个空的replicated表录入数据,看keeper上的数据如何变化。
即每新增一个partition,则znode增加3个,分别为: blocks(默认保留最近100个)、log、parts。
(12小时会增加1次block_numbers,和表的partition by有关)
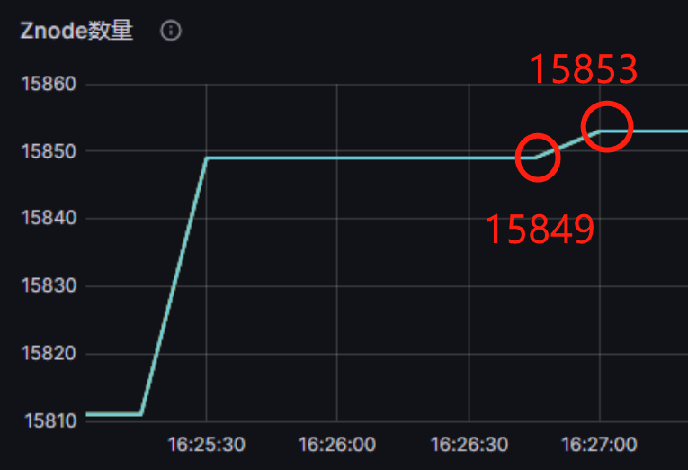
假设每秒钟2500张表都写入,则每秒生成2500 * 3 = 7500 个znode。如果znode数量增长速率不可控,merge赶不上的情况下,会出现too many parts等异常情况。
2.2 znode压力情况评估
每创建一张分布表,使用双副本情况下,在1个shard里面则有52个基础znode。
则2500张表的 znode数量 = 2500 * 52 * shard数量。
如果是4个节点2个shard,则znode数量为:26万。
目前尚无资料显示总共znode数量最大多少,控制在一千万内比较合适,与内存消耗有关。
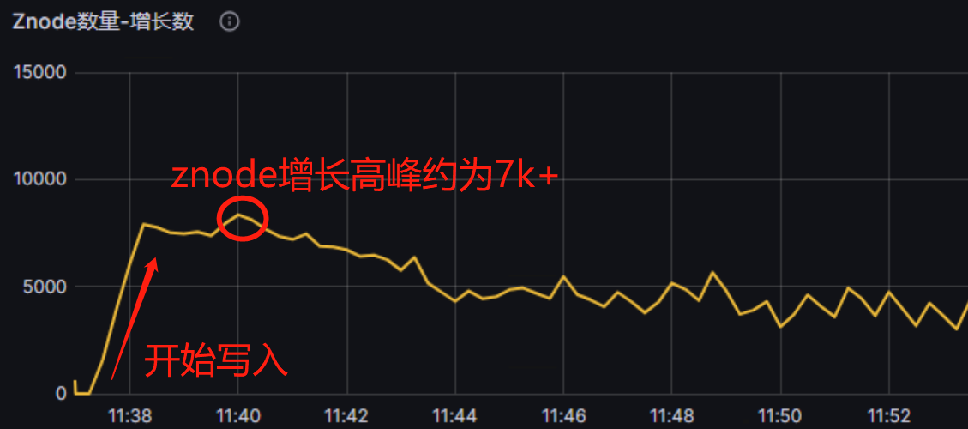
三、压力测试
| 测试目的 | 验证大量分表情况下keeper的压力极限(v23.5.3.24) |
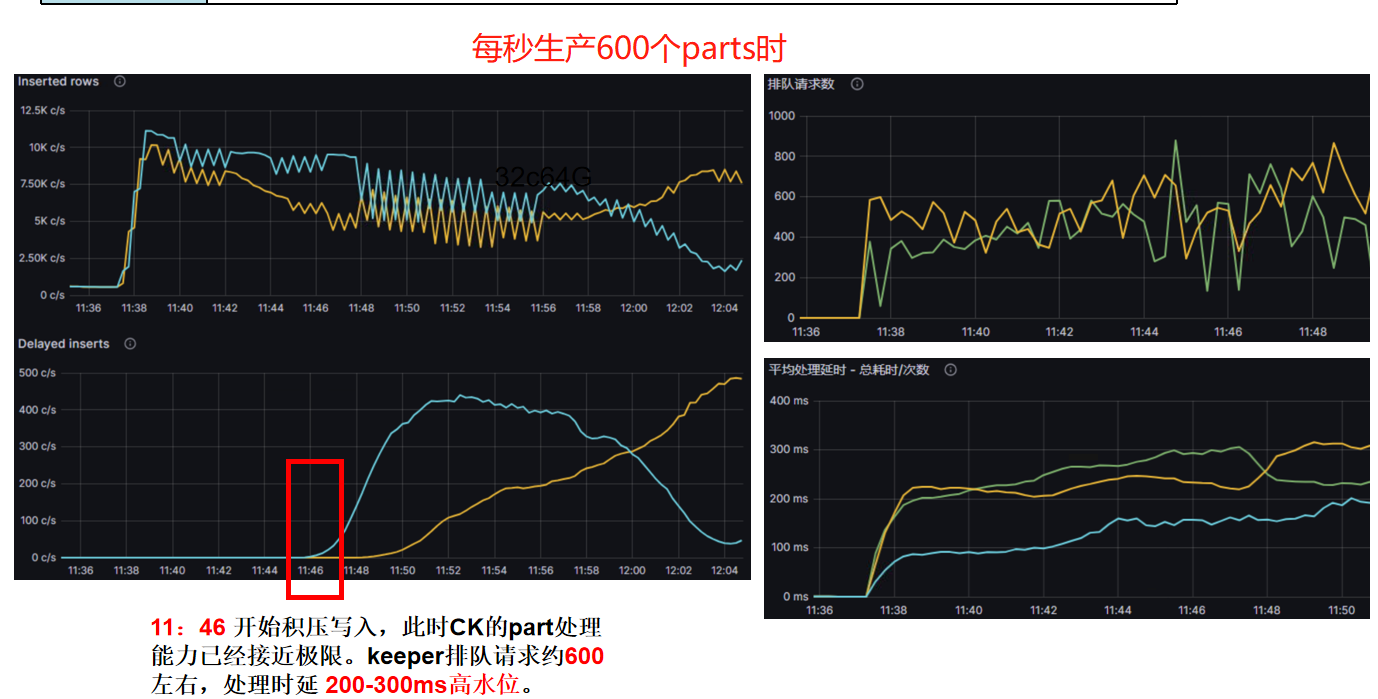
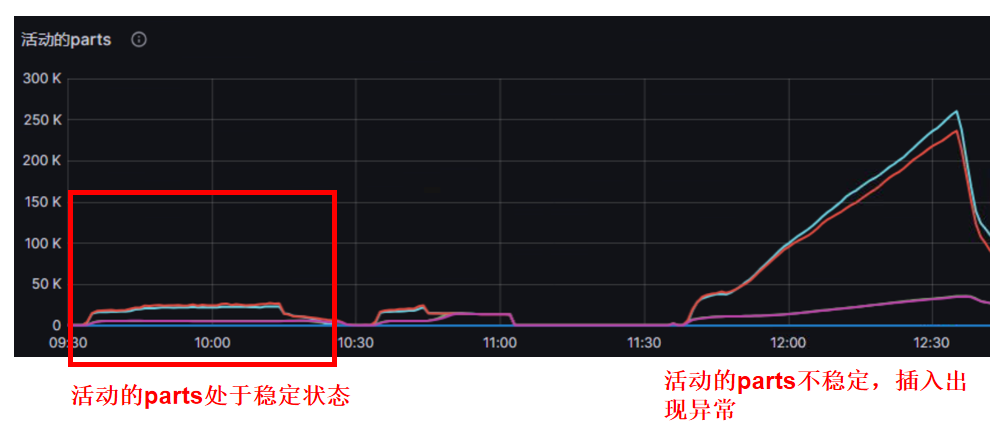
| 测试方法与环境 | 并发录入2500张表,尽量产生可能多的part和znode。场景基于keeper和ck一起部署,3节点32c64G情况下的结果 |
| 结论 | 2shard 2replicate情况下,单个shard处理每秒约600个part生成时崩溃(即600个分表同时刻写入),keeper已经处于积压、高时延状态。在单shard处理约 300 个part生成时,处于稳定状态。 |